https://ift.tt/9l75VEY Use Iceberg API with DuckDB to optimize analytics queries on massive Iceberg tables in your cloud storage Photo by...
Use Iceberg API with DuckDB to optimize analytics queries on massive Iceberg tables in your cloud storage

1. Intro
Apache Iceberg is mostly known for making it possible for popular query engines, such as Spark, Dremio and Trino, to reliably query and manipulate records in huge tables stored in data lakes, and to do so in scale while ensuring safe concurrent reads and writes. As such, it addresses some of the major concerns that characterize modern data-lake platforms, such as data integrity, performance, maintenance, and cost.
Much of what enables Iceberg’s magic is the way it efficiently organizes the table’s metadata, as well as tracking its data files, their statistics, and their version history. This is also what makes queries on Iceberg tables much faster and involving less data scan. Queries on tables that do not use or save file-level metadata (e.g., Hive) typically involve costly list and scan operations, just to figure out the relevant data files over which the query needs to run. In contrast, when the data that we need in order to satisfy a query lies in a specific set of files, then Iceberg’s can in principle tell us this immediately without even scanning a single data file.
Iceberg is a table format, but it’s also a library that exposes a powerful API and set of procedures that implement its main functionality. Iceberg’s API enables query engines to take advantage of its robust metadata structure and run queries that scan less files and avoid expensive list operations.
However, not all use cases necessarily require or justify the heavy lifting of query engines, such as Spark or Trino, which might not always be available. Luckily, we don’t have to use a hefty compute engine to take advantage of the functionality exposed by Iceberg’s API. Any application that can deal with parquet files can use Iceberg tables and its API in order to query more efficiently. The purpose of this short and hands-on post is to demonstrate how.
DuckDB is a popular in-process database that, among other features, excels in reading and running SQL queries over parquet files. Therefore, it gives cloud data applications an important functionality that can make them more robust and less dependent on hefty query engines. Yet, its ability to handle large volumes of data is limited, mostly by the memory size of the machine or process that runs it. That’s exactly where Iceberg API kicks in.
This post will proceed as follows: Section 2 shows and explains the relevant use case and how Iceberg API + DuckDB can address it efficiently. Next, Section 3 demonstrates how to work with Iceberg API and Section 4 adds DuckDB in to the picture. Section 5 explains how both play out together and address the problem stated above. Section 6 concludes.
(I should point out at the outset that I mostly use Scala in the code examples though it relies on Iceberg’s Java API and can be easily ported)
2. The problem (and solution) in a nutshell
We have a massive iceberg table that is partitioned by date, and contains event data streamed from our customers. Each event is identified by a field named account_id, contains a bunch of counters, and an event_type field. Because most data consumers typically add the account_id to their WHERE clause, we decided to sort the files in each partition by account_id ( this is an important bit here. I will explain more shortly).
The requirement is to create a service that will tell us how many events a given customer had over a specific day. The service will receive a certain date as a parameter, as well as an account id, and will return an aggregation by event_type (in JSON format). In short, the service needs to run something like the following query:
SELECT date, account_id, event_type, count(*) as events
FROM customer_events
WHERE date = date '2022-01-02' AND account_id = '2500'
GROUP BY 1,2,3
Sounds simple enough? well, not necessarily. This service will have to answer dozens of requests per day for something like 100 customers out of 10K. Therefore, it makes sense to run this on demand or only when the data of the specific customer is needed. Such use case doesn’t seem to justify spinning a Spark or Trino cluster, but yet the data it has to scan seems quite massive. Even if we know the required partition, list-ing and scanning trough the partition is likely to be memory and compute intense.
This is where Iceberg API shines. If the table is partitioned by date and files are sorted by customer_id (as in the picture below) then the table’s metadata would show that rather than scanning the whole partition and its files, there is just one data file that the query above actually needs to scan — data file #2 (WHERE date=2022-01-02 AND account_id=2500). Indeed, running this query against an Iceberg table would result in a scan of just this file, and that is what Iceberg API will tell us.
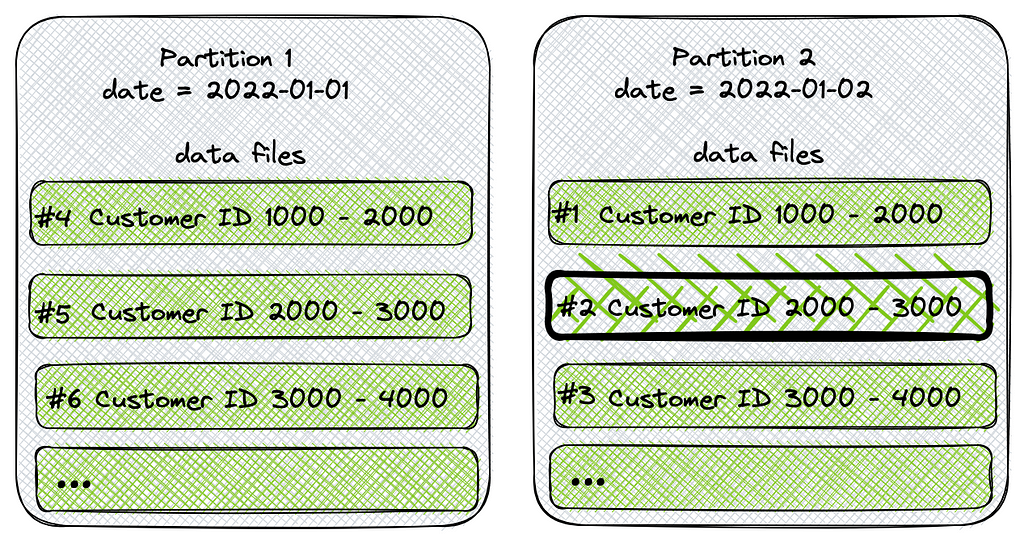
Assuming that each data file weighs around 250MB, then the query and scan operations of a single file seem much more feasible for data applications to process.
As for the way we are going to run these queries over the parquet files, I have already mentioned that we are going to use the increasingly popular DuckDB, due to its ability to efficiently run SQL queries over parquet files laying in S3, in addition to the ease in which it can be embedded in data applications.
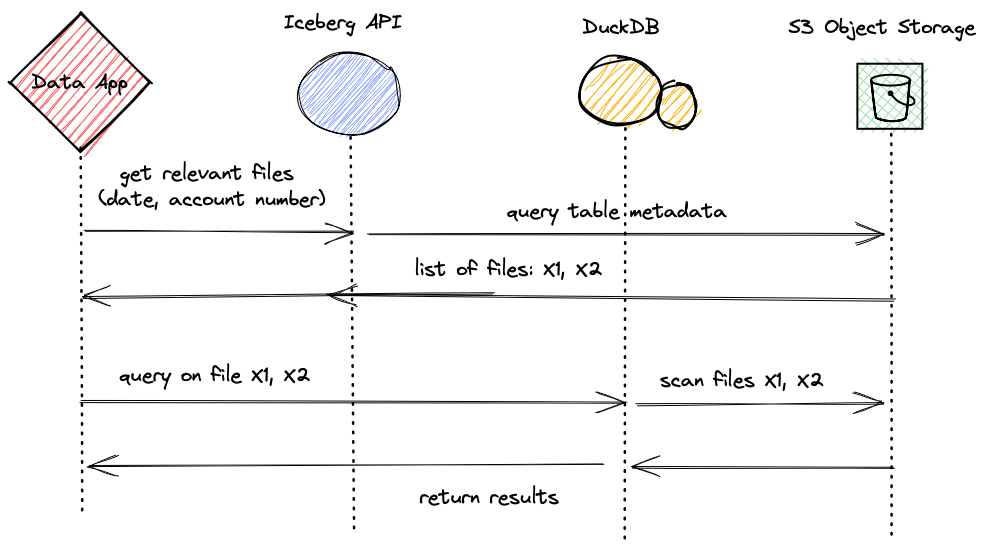
So now we can conclude the flow of our service (see diagram below): the service will be invoked with a date variable and an account_id. Next, we call Iceberg API to query the table’s metadata for data files that are relevant to our query. Finally, after we get the list of files, we create and execute a DuckDB query statement that will also format the result set in JSON (a neat DuckDB feature) and return them to the caller.
3. Filtering using Iceberg API
If you need a good intro to Iceberg API, then feel free to check some of the links at the bottom of the post, though I believe that the code is simple enough even if you know very little about Iceberg.
The first thing we do is create a filtering Expression object that Iceberg will use in order to query the table metadata for the files that contain data that match our filter. You can chain expressions, as well as combine them as I did below.
val partitionPredicate = Expressions.and(
Expressions.equal("date", "2022-11-05"),
Expressions.equal("accountID", "0012345000"))
Next, we create a Catalog object which is the entry point for Iceberg’s API. We use AWS Glue as our catalog, but you can also use JDBC and Hadoop catalogs as well. (Note that for this to work you need AWS credentials in your env or path). The second function in the code block below simply returns an Iceberg table object that will be used to invoke the required operations, and the last function executes a table scan procedures with the optional variable of an Expression object that we have defined above. It is this last function that will essentially tell us, on the basis of Iceberg’s metadata, which files are relevant for the query.
private def getGlueCatalog(): Try[GlueCatalog] = Try{
val catalog = new GlueCatalog
val props = Map(
CatalogProperties.CATALOG_IMPL -> classOf[GlueCatalog].getName,
CatalogProperties.WAREHOUSE_LOCATION -> "s3://Doesnt_Matter_In_This_Context",
CatalogProperties.FILE_IO_IMPL -> classOf[S3FileIO].getName
).asJava
catalog.initialize("myCatalog", props)
catalog
}
private def getIcebergTableByName(namespace: String, tableName: String, catalog: GlueCatalog): Try[Table] =
Try{
val tableID = TableIdentifier.of(namespace, tableName)
catalog.loadTable(tableID)
}
private def scanTableWithPartitionPredicate(table:Table, partitionPredicate:Expression):Try[TableScan] =
Try(table.newScan.filter(partitionPredicate))
After we created an Iceberg Catalog, loaded our Table, and executed a new scan with a filtering Expression, Iceberg returns a TableScan object. The TableScan object will hopefully contain a list of the planned data files that answer our filtering expression. The function below simply extracts the file names from the table scan and chain them in a long string that will allow us to query for them using DuckDB.
private def getDataFilesLocations(tableScan:TableScan): Try[String] = Try {
// chain all files to scan in a single string => "'file1', 'file2'"
tableScan.planFiles().asScala
.map(f => "'" + f.file.path.toString + "'")
.mkString(",")
}
This sums up our service’s usage of the Iceberg API. We start with a Catalog, and using an Expression filter initiate a table-scan that uses our table’s metadata to determine the files that are relevant to our query.
4. Querying with DuckDB
DuckDB is an increasingly popular in-process OLAP database that excels in running aggregate queries on a variety of data sources. DuckDB differs from similar products (such as SQLite) in the performance it offers to OLAP queries, as well as in the flexibility it provides. In short, it is essentially an in-process mini-DWH that enables us to run aggregation-heavy queries on relatively large datasets.
However, some datasets are just too large for the kind of machines or pods we have available or that we want to use. And, that’s exactly what makes the combination of DuckDB with Iceberg a very powerful one — with Iceberg API we can run queries on much less data in much less time.
DuckDB allows querying parquet files using the keyword parquet_scan() which can be used in a query like this:
SELECT date, account_id, event_type, count(*) as events
FROM parquet_scan([ <FILES_LIST>])
WHERE date = date '2022-01-02' AND account_id = '2500'
GROUP BY 1,2,3
So, after getting the list of data files using Iceberg’s API, we can simply replace the string “<FILES_LIST>” in the query above with the list of files that we received from Iceberg, and execute the query on the filtered files.
As the code block below shows, we start by initializing DuckDB in-memory. Because we want to work with tables in S3 then we first need to install and load the httpfs module (together with the parquet module that should already be loaded by default). Modules are loaded in DuckDB by executing statements, which also include variable setters, that we use here to set AWS credentials. The second function in the code below simply injects the list of files in the query, as we saw above, and the last function executes the statement.
private def initDuckDBConnection: Try[Connection] = Try {
val con = DriverManager.getConnection("jdbc:duckdb:")
val init_statement =
s"""
|INSTALL httpfs;
|LOAD httpfs;
|SET s3_region='eu-west-1';
|SET s3_access_key_id='${sys.env.get("AWS_ACCESS_KEY_ID").get}';
|SET s3_secret_access_key='${sys.env.get("AWS_SECRET_ACCESS_KEY").get}';
|SET s3_session_token='${sys.env.get("AWS_SESSION_TOKEN").get}';
|""".stripMargin
con.createStatement().execute(init_statement)
con
}
private def formatQuery(query:String, dataFilesStr:String):Try[String] = Try {
query.replaceAll("<FILES_LIST>", dataFilesStr)
}
private def executQuery(connection: Connection, query:String):Try[ResultSet] = Try{
connection.createStatement.executeQuery(query)
}
That settles the core of our service on the query side. After we get the list files, we just need to make sure DuckDB is properly initialized, format the query and execute it.
5. Putting it all together
As mentioned earlier, the processing logic of our service involves 2 main stages that unfold in 7 steps detailed in the code block below (Scala’s for comprehension actually makes this pretty straightforward).
val queryStatement = """
|SELECT row_to_json(resultsDF)
|FROM (
| SELECT date, account_id, event_type, count(*) as events
| FROM parquet_scan([ <FILES_LIST>])
| WHERE acc_id = '2500' AND date = '2022-01-01'
| GROUP BY 1,2,3
|) resultsDF
|""".stripMargin
val filterExpr = Expressions.and(
Expressions.equal("date", "2022-11-05"),
Expressions.equal("accountID", "0012345000"))
val jsonDataRows = for {
catalog <- getGlueCatalog
table <- getIcebergTableByName("db_name", "table_name", catalog)
tableScan <- scanTableWithPartitionPredicate(table, filterExpr)
dataFilesString <- getDataFilesLocations(tableScan)
queryStatement <- formatQuery(query, dataFilesString)
dbConnection <- initDuckDBConnection
resultSet <- executQuery(dbConnection, queryStatement)
} yield resultSet.toStringList
Iceberg API is first used to obtain table reference and execute a table scan that fetches the names and locations of the data files that contain the date we are interested in, as well as the customer_id. Once we get the filtered list of files and their locations in S3, we chain them in a long string and inject it into to the query. Finally, the query is executed only on the relevant files using DuckDB and the results are obtained.
As you can see, the query template above is wrapped in a row_to_json function that transforms the result set into a JSON document, which is what we wanted to achieve.
6. Conclusion
Apache Iceberg is quickly becoming a standard for metadata management and organization of massive data lake tables. Therefore, it is not surprising that popular query engines, such as Impala, Spark, and Trino, as well as public cloud providers, were fast to announce their support in the Iceberg table format and API.
The purpose of this post was to demonstrate a powerful way in which data applications can take advantage of the benefits offered by Iceberg tables independently of a hefty query engine. It showed how we can use Iceberg’s API together with DuckDB in order to create light weight though powerful data applications that can run efficient queries on massive tables. We saw that by using the API exposed by Iceberg, we can essentially create an “optimized” query, which only scans the files relevant for the query. The ease in which DuckDB can be used to run queries over parquet files stored in cloud storage makes the combination of the two an extremely powerful one, and highlights the potential in the Iceberg table format and its features.
The full source code is available here
I Hope this will be useful !
* Resources
A very good intro to Iceberg can be found here and here
Some more focused information about the Java API can be found here
** All images, unless otherwise noted, are by the author
Boost Your Cloud Data Applications with DuckDB and Iceberg API was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/boost-your-cloud-data-applications-with-duckdb-and-iceberg-api-67677666fbd3?source=rss----7f60cf5620c9---4
via RiYo Analytics







ليست هناك تعليقات