https://ift.tt/zMRGPmf Have recent advances in AI blurred the line between machine learning and traditional search indexes? Introduction ...
Have recent advances in AI blurred the line between machine learning and traditional search indexes?
Introduction
Engineers learn about databases and how to make them efficiently queryable; data scientists learn about how to build statistical models and how to make their predictions more accurate…never the twain shall meet. The goal of this post is to challenge that notion, particularly in the context of some interesting properties of LLMs, and view both along a continuum of data structures and algorithms used to query a population of data.
A database index allows you to deterministically search a dataset using an input key; a machine learning model searches a general population (of which it’s seen part of) based on input features. Furthermore, massive leaps in AI and LLMs have upturned some basic assumptions about how flexible a machine learning model can be, while still maintaining the ability to generalize to a population. And from the scale at which these models operate, search-engine-like use cases have emerged, lending real-world and legal stakes to the seemingly abstract connection between databases and machine learning (see the recent class action law-suit against Microsoft).
Space for time
A database index is a data structure that allows you to efficiently traverse a large dataset; it trades time (that you would wait looking for an item) for space (with which you store additional information about how to find that item). A standard tree-based index allows you to zip down its branches in log(N) time as opposed to scanning the original table in N time. These short cuts are fundamentally directional: given the value of this primary or secondary key, where should I move in order to hit the closest target in my dataset? Simple enough.
Database indexes as overfit machine learning models
Supervised machine learning models also constitute structures on top of datasets, with the goal of generalizing beyond the data in the original set. Instead of being used to find, they’re used to infer or predict. We can think about these models as being generalizations of indexes: instead of find the matching element in your sample based on the features provided, it predicts or infers the closest element in the population.
Supervised machine learning models are traditionally smaller and more rigid than database indexes, because, again, their goal is to generalize beyond the data available, trade variance for bias. If you didn’t need to generalize beyond the data you have available, you would just use a database index! (This is actually something that a lot of businesses eager to jump into data science fail to think about.)
With this mental model in mind, a database index is just a totally overfit supervised model: it can’t generalize at all beyond the data its seen, but it does a great job of finding you any y in the sample given X… all variance no bias.
Beyond the bias-variance tradeoff… double descent
So we can think of an ML model as an index on the population data, but, in traditional statistical modeling, you have to trade enough variance for bias that, functionally, it looks absolutely nothing like an index and this analogy is just fun thought experiment for a blog post.
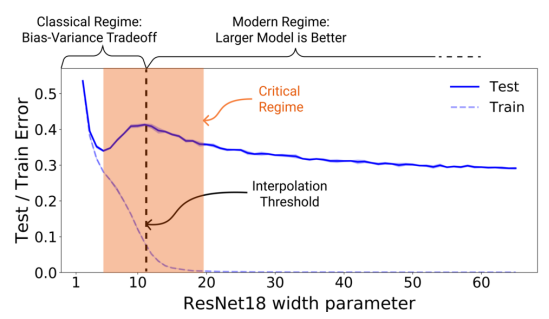
How much further does this analogy take us if you didn’t have to make this tradeoff? For cutting edge deep neural networks, this tradeoff does not always exist. According to OpenAI’s research, under certain conditions, “overfitting” a model (or continuing to train far past the point on the tradeoff curve tradition statistics recommends) improves performance on the test data. The model only becomes better and better past the interpolation threshold. It’s not fully understood why the model does this, as once the training error is zero is the objective function provides no obvious “incentive” for the model to become better. But let me try to offer one intuition…
A plausible explanation is statistical: a neural network is a universal function approximator and there are many more “good” models (read those that can effectively interpolate) than “bad” models (those that speciously fit the training data and perform poorly in real life). Furthermore, over-parameterized models are more flexible, capable of generating more model candidates for a particular training set than an effectively smaller model (i.e. fewer fit parameters). Therefore as the solution space gets bigger with the number of non-zero model parameters, it becomes more likely that a “good” model will be selected.
Implications of large language models as search engines
When you run a Google image search, the engine returns a subset of the indexed images most likely to match your key words. When you input a prompt into DALLE 2, a diffusion process iteratively works towards an image that maximizes the probability of the input words based on the caption-image pairs seen at training time. The original paper notes that “to scale up to 12-billion parameters, we created a dataset of a similar scale to JFT-300M (Sun et al., 2017) by collecting 250 million text-images pairs from the internet.”
A Google search and a DALLE 2 prompt, in this light, don’t look that different. Leaving aside the algorithmic differences, the core difference in user experience is that DALLE 2 is capable of zero-shot image generation, whereas a Google search can only return what it’s seen before. Github copilot, powered by GPT-3, operates in a similar manner against open source code, generating snippets of “novel” code from a massively parameterized model.
Can a writer armed with DALLE 2 generate novel captions for their comic book that look suspiciously like something out of the Marvel universe? I’m not a lawyer, but, if I were to argue against that right, I’d use the analogy between database indexes and machine learning. Machine learning is just one of many ways to encode information about a data set. Until recently, it looked nothing like a traditional database. But now the scale and sophistication, ironically, reveal the through-line.
Double Descent and ML Models as Generalized Database Indexes was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/double-descent-and-ml-models-as-generalized-database-indexes-5d3b1db49b5b?source=rss----7f60cf5620c9---4
via RiYo Analytics







No comments