https://ift.tt/T20pOiD DeepSpeed Deep Dive — Model Implementations for Inference (MII) A closer look at the latest open-source library fro...
DeepSpeed Deep Dive — Model Implementations for Inference (MII)
A closer look at the latest open-source library from DeepSpeed

What is this about?
The DeepSpeed team has recently released a new open-source library called Model Implementation for Inference (MII), aimed towards making low-latency, low-cost inference of powerful models not only feasible but also easily accessible. You can read all about it in their blog post.
When I started exploring the MII library I realised there were many references to other DeepSpeed technologies, such as ZeRO-Inference and DeepSpeed-Inference. Therefore the aim of this blog post is not so much recapping DeepSpeed’s blog post, I think the team is doing a great job describing the technology and potential benefits. Instead I will aim to explain some of the underlying technologies and the associated terminology and point out a few ‘gotchas’ that I had when diving deeper into the MII library. It’s basically the blog post I wish I would have had four weeks ago when I started diving into this library 😅
Why is this important?
Not a week goes by in which a new, exciting AI model is being released. At the time of writing this blog post (17 Nov 2022) the AI model of this week is Meta’s Galactica model. Many of these large models are open-source (BLOOM, OPT) and accessible to everyone — in theory. The challenge, of course, is that these models are so large that customers struggle to deploy them. And when they do manage to deploy them, they face challenges around inference latency and cost.
DeepSpeed has done a lot in the past few years to overcome these challlenges and now consolidate their efforts into one library, DeepSpeed-MII. Their aim is to enable low-latency, low-cost inference of powerful models not only feasible but also easily accessible. And just last week on 9 Nov 2022 they announced that they were able to generate images with Stable Diffusion under one second per image. Efforts like these will democratise access to these models and eventually allow everyone to run these models 🤗
DeepSpeed Terminology
The first thing to note is that DeepSpeed-MII is actually a collection of existing DeepSpeed technologies, in particular DeepSpeed-Inference and ZeRO-Inference. When I started learning more about DeepSpeed’s libraries I got a bit confused so I want to first give an overview of all the termiologies you might encounter when working with DeepSpeed:
ZeRO-Inference: Was introduced in Sep 2022 as a successor to ZeRO-Infinity (from April 2021)— it adapts and optimises ZeRO-Infinity techniques for model inference on GPUs by hosting the model weights in CPU or NVMe memory, thus hosting no weights in GPU:

DeepSpeed-Inference: Introduced in March 2021. This technique has no relation with the ZeRO technology and therefore does not focus on hosting large models that would not fit into GPU memory. Instead it introduces several features to efficiently serve transformer-based PyTorch models, such as inference-customized kernels. You can read more about it in their blog post.
So, to summarise:
- ZeRO-Inference is designed for inference applications that require GPU acceleration but lack sufficient GPU memory to host the model. Also, ZeRO-Inference is optimized for inference applications that are throughput-oriented and allow large batch sizes.
- DeepSpeed-Inference, on the other hand, fits the entire model into GPU memory (possibly using multiple GPUs) and is more suitable for inference applications that are latency sensitive or have small batch sizes.
DeepSpeed MII incorporates both technologies into one framework. However, as described above, they serve different purposes and therefore cannot be used together:

Code deep dive
In this section we will glance at MII’s code to extract some useful information. The library is still young (current version is 0.0.3) and some things are not fully documented just yet. In the code snippet above, for example, we have seen that MII incorporates both, DeepSpeed-Inference and ZeRO-Inference.
Another useful bit of information is that MII aims to make life easier for users. Based on model type, model size, batch size, and available hardware resources, MII automatically applies the appropriate set of system optimisations from DeepSpeed-Inference to minimise latency and maximize throughput.
For example if we wanted to run an Eleuther model, it will choose an appropriate set of configuration values:
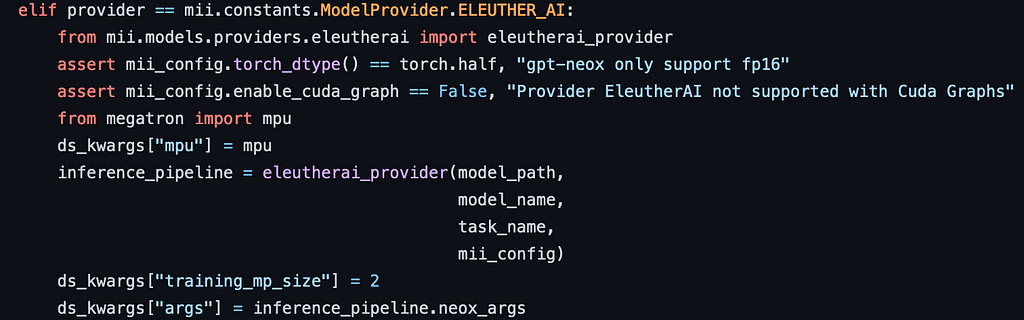
Eventually, the code for optimising and accelerating the models is identical to the code we’d use if we were using DeepSpeed-Inference on its own:
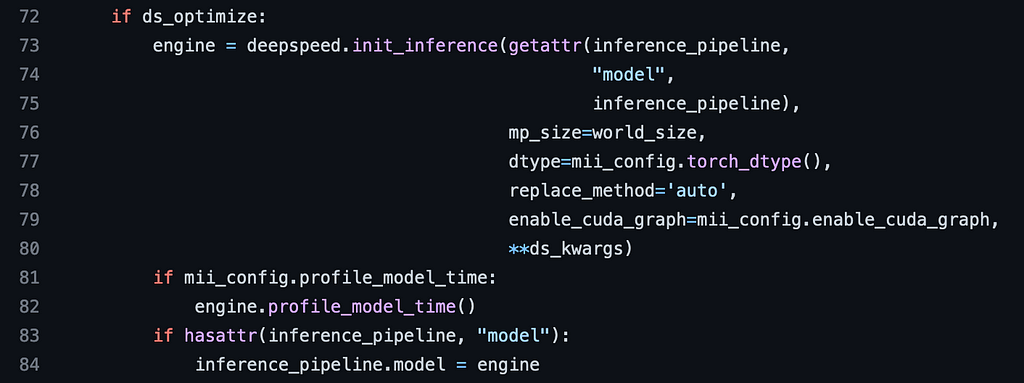
This is great to know — it means that we don’t want to host our model via a gRPC service we can still get the same efficiencies by just using DeepSpeed-Inference. In the future I would love if we could choose within MII to use the optimisation with or without gRPC, though.
Time for some hands-on experiments
To make sure it is the case that MII and DeepSpeed-Inference provide the same acceleration we can run a few tests: We can first run a text generation task without DeepSpeed acceleration at all, and then compare how latency changes when using DeepSpeed-Inference and MII.
We will use the BLOOM-560M model for this experiment on an instance equipped with an T4 (16 GB GPU memory). According to the MII blog post we should see the following gains when using the MII-Public option:
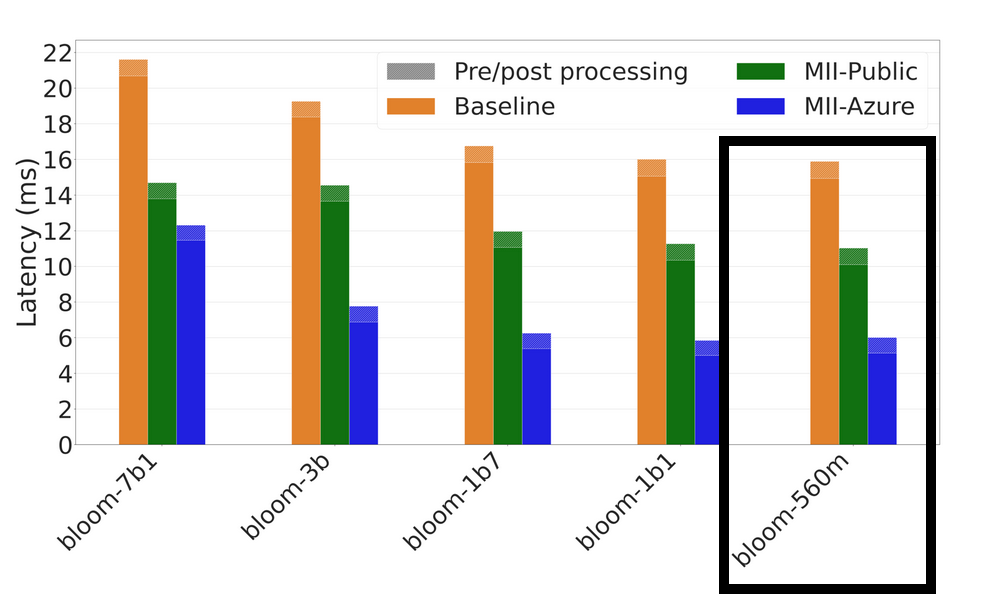
The code for these tests can be found in this GitHub repo.
Baseline — Hugging Face Pipeline without DeepSpeed
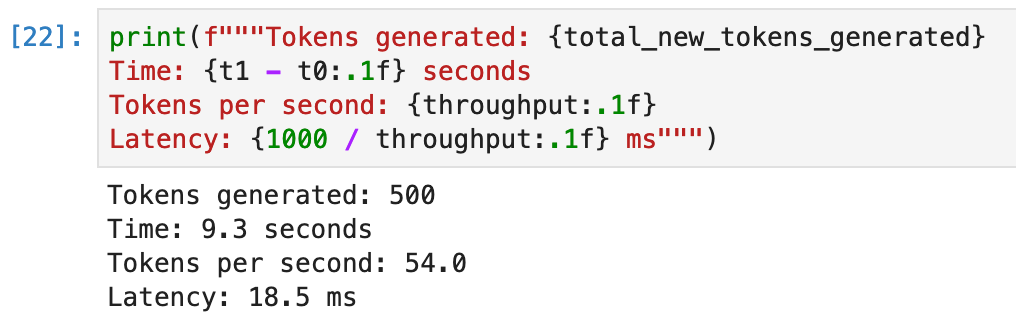
We can get a baseline by running a standard Hugging Face Pipeline with the BLOOM-560M model.
We see that the results are roughly in line with the expectations from the MII blog post:
DeepSpeed-Inference
Now we can run the same test just using the DeepSpeed-Inference framework. To do that we set up the same Hugging Face Pipeline we did above and then just replace the underlying model with the optimised DeepSpeed model:
Once the pipeline is ready we can run the same tests as above and see a significant improvement of 4 milliseconds:
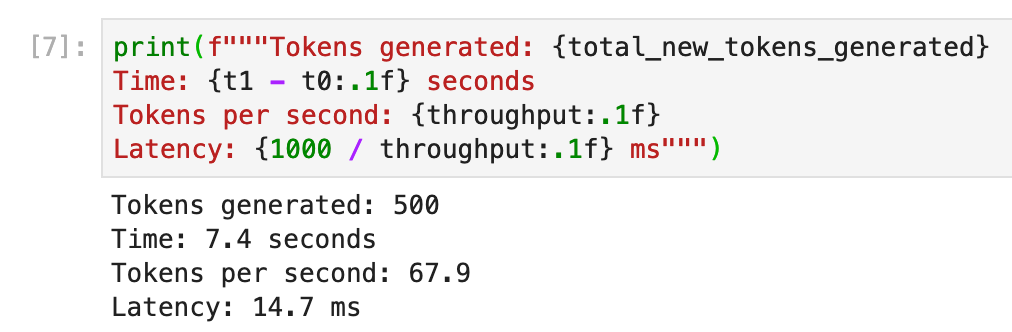
MII
Setting up the MII inference engine is also very easy, we can just follow the instructions in the MII GitHub repo:
Once we have the generator up and running we can again generate new tokens and measure the time it takes to generate them. The result of the generator is a proto MultiString object, probably stemming from the fact that we are interacting with a gRPC server. I’m sure there are good ways to parse this reply, but I will do it quick and dirty here via a bit of Regex magic:
Now we calculate the same metrics and see the results:
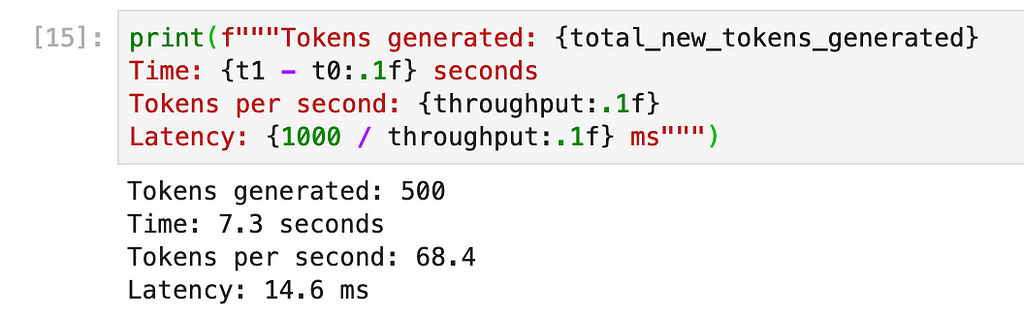
We do see the exact same speed-up (4 milliseconds) as we did with DeepSpeed-Inference, just as expected 🤗
Conclusion
I’m really excited about this initiative. I believe that democratising access to large models like BLOOM, OPT, and others will be one of the main challenges in 2023 and MII is a great project to tackle this challenge. It is still a very young library (created in Oct 2022, current version is 0.0.3). But it seems the library is active and the community is using and testing it and raising GitHub issues. Hopefully over time we will se this library grow and improve — I will definitely try to do my part 😊
DeepSpeed Deep Dive — Model Implementations for Inference (MII) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/deepspeed-deep-dive-model-implementations-for-inference-mii-b02aa5d5e7f7?source=rss----7f60cf5620c9---4
via RiYo Analytics






No comments