https://ift.tt/aHGzrYj A New Era of Massively Parallel Simulation A Practical Tutorial Using ElegantRL Photo by Jason Yuen on Unsplash...
A New Era of Massively Parallel Simulation
A Practical Tutorial Using ElegantRL

A recent breakthough in reinforcement learning is that GPU-accelerated simulator such as NVIDIA’s Isaac Gym enables massively parallel simulation. It runs thousands of parallel environments on a workstation GPU and expedites the data collection process 2~3 orders of magnitude.
This article by Steven Li and Xiao-Yang Liu explains the recent breakthrough of massively parallel simulation. It also goes through a practical tutorial using ElegantRL, a cloud-native open-source reinforcement learning (RL) library, on how to train a robot to solve Isaac Gym benchmark tasks in 10 minutes and how to build your own parallel simulator from scratch.
GitHub - AI4Finance-Foundation/ElegantRL: Cloud-native Deep Reinforcement Learning. 🔥
What is GPU-accelerated Simulation?
Similarly to most data-driven methods, reinforcement learning (RL) is data-hungry — a relatively simple task may require millions of transitions, while learning complex behaviors might need substantially more.
A natural and straightforward way to speed up the data collection process is to have multiple environments and let the agent interact with them in parallel. Previous to the GPU-accelerated simulator, people using CPU-based simulators like MuJoCo and PyBullet often need a CPU cluster to achieve this. For example, OpenAI used almost 30,000 CPU cores (920 worker machines with 32 cores each) to train a robot to solve the Rubik’s Cube [1]. Such an enormous computing requirement is unacceptable for most researchers and practitioners!
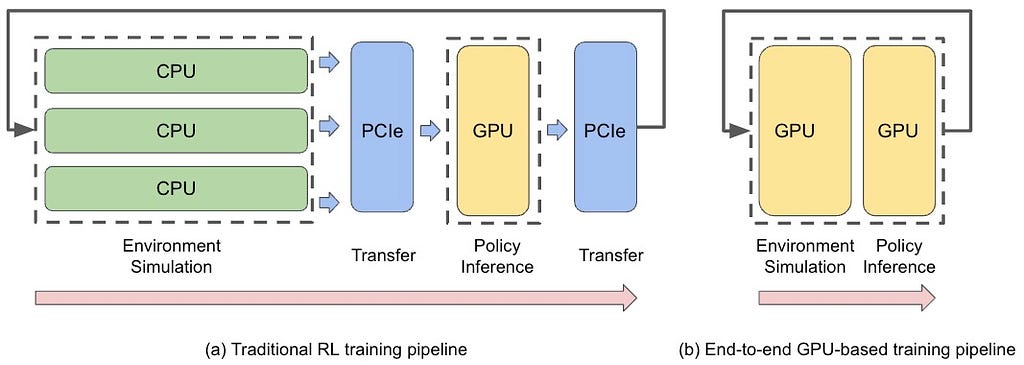
Fortunately, the multi-core GPU is naturally suitable for highly parallel simulation, and a recent breakthrough is the release of Isaac Gym [2] by NVIDIA, which is an end-to-end GPU-accelerated robotics simulation platform. Running simulation on GPU has several advantages:
- allows running tens of thousands of environments simultaneously using one single GPU,
- speedups each environment forward step, including physics simulation, state and rewards computation, etc.,
- avoids transferring the data between CPUs and GPUs back and forth since the neural network inference and training are co-located on GPUs.
Isaac Gym Benchmark Environments for Robotics
Isaac Gym provides a diverse set of robotic benchmark tasks from locomotions to manipulations. To successfully train a robot using RL, we show how to use the massively parallel library ElegantRL.
Now, ElegantRL fully supports Isaac Gym environments. In the following six robotic tasks, we demonstrate the performance of three commonly used deep RL algorithms, PPO [3], DDPG [4], and SAC [5], implemented in ElegantRL. Note that we use various numbers of parallel environments across tasks from 4,096 to 16,384 environments.

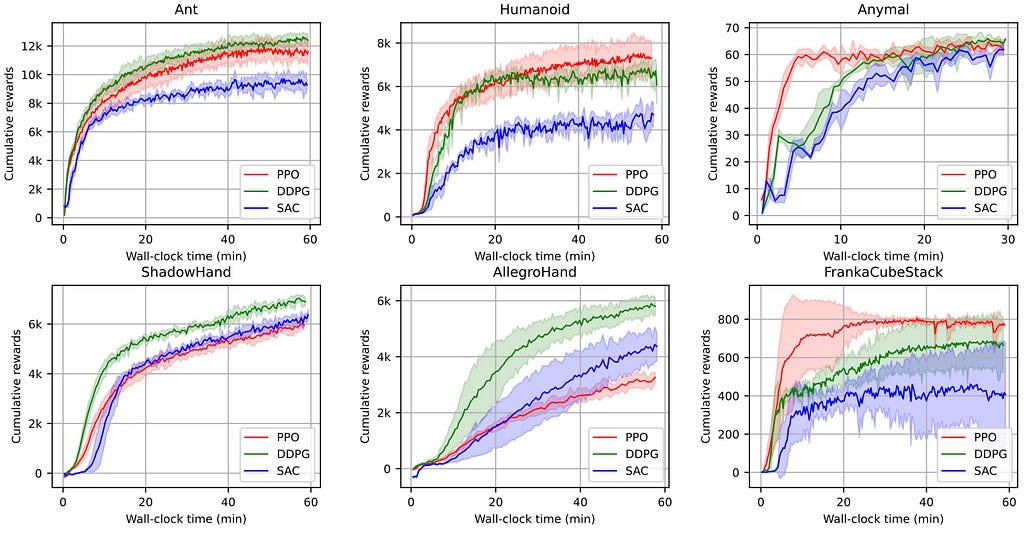
In contrast to the previous Rubik’s Cube example that requires a CPU cluster and needs months to train, we can solve a similar re-orientation task of shadow hand in 30 minutes!
Build Your Own Simulator from Scratch
Is it possible to build my own GPU-based simulator like Isaac Gym? The answer is Yes! In this tutorial, we provide two examples of combinatorial optimization problems: graph max cut and traveling salesman problem (TSP).
A traditional RL environment mainly consists of three functions:
- init(): defines the key variables of an environment, such as state space and action space.
- step(): takes an action as input, runs one timestep of the environment’s dynamics, and returns the next state, reward, and done signal.
- reset(): resets the environment and returns the initial state.
A massively parallel environment has similar functions but receives and returns a batch of states, actions, and rewards. Consider the max cut problem: Given a graph G = (V, E), where V is the set of nodes and E is the set of edges, find a subset S ⊆ V that maximizes the weight of the cut-set
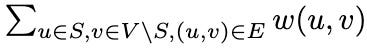
where w is the adjacency symmetric matrix that stores the weight between each node pair. Therefore, with N nodes,
- state space: the adjacency symmetric matrix with size N × N and the current cut-set with size N
- action space: the cut-set with size N
- reward function: the sum of the weight of the cut-set
Step 1: generate the adjacency symmetric matrix and compute the reward:
def generate_adjacency_symmetric_matrix(self, sparsity): # sparsity for binary
upper_triangle = torch.mul(torch.rand(self.N, self.N).triu(diagonal=1), (torch.rand(self.N, self.N) < sparsity).int().triu(diagonal=1))
adjacency_matrix = upper_triangle + upper_triangle.transpose(-1, -2)
return adjacency_matrix # num_env x self.N x self.N
def get_cut_value(self, adjacency_matrix, configuration):
return torch.mul(torch.matmul(configuration.reshape(self.N, 1), (1 - configuration.reshape(-1, self.N, 1)).transpose(-1, -2)), adjacency_matrix).flatten().sum(dim=-1)
Step 2: Use vmap to execute functions in batch
In this tutorial, we use PyTorch’s vmap function to achieve parallel computation on GPU. The vmap function is a vectorizing map that takes a function as an input and returns its vectorized version. Therefore, our GPU-based max cut environment can be implemented as follows:
import torch
import functorch
import numpy as np
class MaxcutEnv():
def __init__(self, N = 20, num_env=4096, device=torch.device("cuda:0"), episode_length=6):
self.N = N
self.state_dim = self.N * self.N + self.N # adjacency mat + configuration
self.basis_vectors, _ = torch.linalg.qr(torch.randn(self.N * self.N, self.N * self.N, dtype=torch.float))
self.num_env = num_env
self.device = device
self.sparsity = 0.005
self.episode_length = episode_length
self.get_cut_value_tensor = functorch.vmap(self.get_cut_value, in_dims=(0, 0))
self.generate_adjacency_symmetric_matrix_tensor = functorch.vmap(self.generate_adjacency_symmetric_matrix, in_dims=0)
def reset(self, if_test=False, test_adjacency_matrix=None):
if if_test:
self.adjacency_matrix = test_adjacency_matrix.to(self.device)
else:
self.adjacency_matrix = self.generate_adjacency_symmetric_matrix_batch(if_binary=False, sparsity=self.sparsity).to(self.device)
self.configuration = torch.rand(self.adjacency_matrix.shape[0], self.N).to(self.device).to(self.device)
self.num_steps = 0
return self.adjacency_matrix, self.configuration
def step(self, configuration):
self.configuration = configuration # num_env x N x 1
self.reward = self.get_cut_value_tensor(self.adjacency_matrix, self.configuration)
self.num_steps +=1
self.done = True if self.num_steps >= self.episode_length else False
return (self.adjacency_matrix, self.configuration.detach()), self.reward, self.done
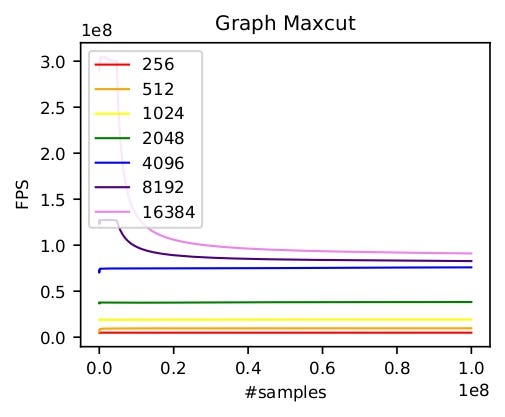
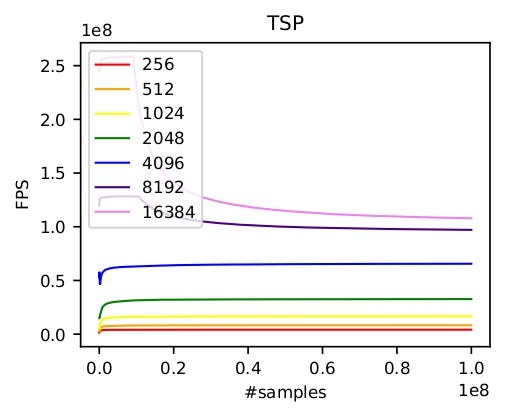
We can also similarly implement the TSP problem. As shown below, we test the frames per second (FPS) of our GPU-based environments on one A100 GPU. At first, on both tasks, the FPS increases linearly as more parallel environments are used. However, GPU utilization actually limits the number of parallel environments. Once the GPU utilization reaches the maximum, the speedup brought by more parallel environments will decrease significantly. This happens around 8,192 environments in max cut and 16,384 environments in TSP. Thus, the optimal performance of GPU-based environments highly depends on the GPU type and the complexity of the task.
In the end, we provide the source codes of the max cut problem and TSP problem.
Conclusion
Massively parallel simulation has a huge potential in data-driven methods. It not only can speed up the data collection process and accelerate the workflow but also provides new opportunities for studying the generalization and exploration issues. E.g., one intelligent agent can simply interact with thousands of environments where each environment contains different objects, to learn a robust policy, or can leverage different exploration strategies for different environments, to obtain diverse data. Thus, how to effectively utilize this wonderful tool still remains a challenge!
Hopefully, this article can provide some insights for you. If you are interested in more, please follow our open-source community and repo and join us in slack!
Reference
[1] Akkaya, Ilge, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, Alex Paino et al. Solving rubik’s cube with a robot hand. arXiv preprint arXiv:1910.07113, 2019.
[2] Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac Gym: High performance GPU-based physics simulation for robot learning. NeurIPS, Special Track on Datasets and Benchmarks, 2021.
[3] J. Schulman, F. Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. ArXiv, abs/1707.06347, 2017.
[4] Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. International Conference on Machine Learning, 2018.
[5] Tuomas Haarnoja, Aurick Zhou, P. Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. International Conference on Machine Learning, 2018.
A New Era of Massively Parallel Simulation: A Practical Tutorial Using ElegantRL was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium
https://towardsdatascience.com/a-new-era-of-massively-parallel-simulation-a-practical-tutorial-using-elegantrl-5ebc483c3385?source=rss----7f60cf5620c9---4
via RiYo Analytics






No comments