https://ift.tt/Xu9AbKw Understanding Outliers in Text Data with Transformers, cleanlab, and Topic Modeling An open-source python workflow ...
Understanding Outliers in Text Data with Transformers, cleanlab, and Topic Modeling
An open-source python workflow to audit text datasets

Many text corpora contain heterogeneous documents, some of which may be anomalous and worth understanding more. For deployed ML systems, in particular, we may want to automatically flag test documents that do not stem from the same distribution as their training data and understand emerging themes within these new documents that were absent from the training data.
I recently joined Cleanlab as a ML engineer and am excited to share the many ways our open-source library (freely available under AGPL-v3 license) can be used in various workflows to understand and improve datasets.
This post demonstrates how to find and analyze anomalous texts in large NLP corpora via a workflow based on open-source Python packages: Transformers, cleanlab, pytorch, UMAP, and a c-TF-IDF implementation from BERTopic. We use Transformers to obtain good representations of the raw text, cleanlab to identify outliers in this representation space, and UMAP + c-TF-IDF to better understand these anomalies.
We will use the MultiNLI dataset on the Hugging Face Hub, a natural language inference dataset commonly used to train language understanding models.
- The dataset contains multiple pairs of sentences (premise, hypothesis) that have been labelled whether the premise entails the hypothesis ("entailment") or not ("contradiction"). A neutral label is also included ("neutral").
- The corpus is split into a single training set and two validation sets.
- The training set is sourced from 5 different genres: [fiction, government, slate, telephone, travel].
- The matched validation set is sourced from genres that match those in the the training set
- The other validation set, also referred to as the mismatched validation set, is sourced from other genres not present in the training data: [nineeleven, facetoface, letters, oup, verbatim].
- More information about the corpus can be found here.
The steps in this post can be applied with your own word/sentence embedding models and any dataset containing multiple sources of text.
Too Long; Didn’t Run (the code)
Here’s our general workflow for detecting outliers from multiple text sources and finding new topics within them:
- Load and preprocess text datasets from the Hugging Face Hub to create PyTorch datasets.
- Apply pretrained sentence embedding model to create vector embeddings from the text.
— Here we utilize a bi-encoder based on a siamese neural network from the SentenceTransformers library. - Use the cleanlab library to find outlier texts in the training data.
- Find outlier examples in the validation data that don’t come from the data distribution in the training set.
— This would be analogous to looking for anomalies in new data sources/feeds. - Select a threshold for deciding whether to consider an example an outlier or not.
- Cluster the selected outlier examples to find anomalous genres/sources of text.
- Identify topics within the anomalous genres/sources.
Our main goal is to find out-of-distribution examples in a dataset, paying more attention to new genres/domains/sources. In the case of the MultiNLI dataset, only 1 out of the following 4 examples are considered anomalous with these methods. (Can you guess which?)

It will turn out that the most likely outliers identified by our method come from the genres in the mismatched validation set, as is to be expected.
Many of these outlier examples form clusters based on their respective genres, which can be used to find out-of-distribution topics in the data.
Let’s get coding!
The remainder of this article will demonstrate how we implement our strategy, with fully runnable code! Here’s a link to a notebook where you can run the same code: link
Install dependencies
You can install all the required packages by running:
!pip install cleanlab datasets hdbscan matplotlib nltk sklearn torch tqdm transformers umap-learn
Next, we’ll import the necessary packages, set logging level to ‘ERROR’ and set some RNG seeds for reproducibility.
Preprocess datasets
The MultiNLI dataset can be fetched from the Hugging Face Hub via its datasets api. The only preprocessing we perform is removing unused columns/features from the datasets. Note that for this post we're not looking at the entailment labels (label) in the dataset. Rather we are simply trying to automatically identify out of distribution examples based only on their text.
For evaluating our outlier detection algorithm, we consider all examples from the mismatched validation set to be out-of-distribution examples. We’ll still use the matched validation set to find naturally occurring outlier examples. Our algorithms also do not require the genre information, this is only used for evaluation purposes.
To get some idea of the data format, we’ll take a look at a few examples from each dataset.
Training data
Genres: ['fiction' 'government' 'slate' 'telephone' 'travel']

Validation matched data
Genres: ['fiction' 'government' 'slate' 'telephone' 'travel']

Validation mismatched data
Genres: ['facetoface' 'letters' 'nineeleven' 'oup' 'verbatim']

Transform NLI data into vector embeddings
We’ll use pretrained SentenceTransformer models to embed the sentence pairs in the MultiNLI dataset.
One way to train sentence encoders from NLI data (including MultiNLI) is to add a 3-way softmax classifier on top of a Siamese BERT-Network like the one shown below.
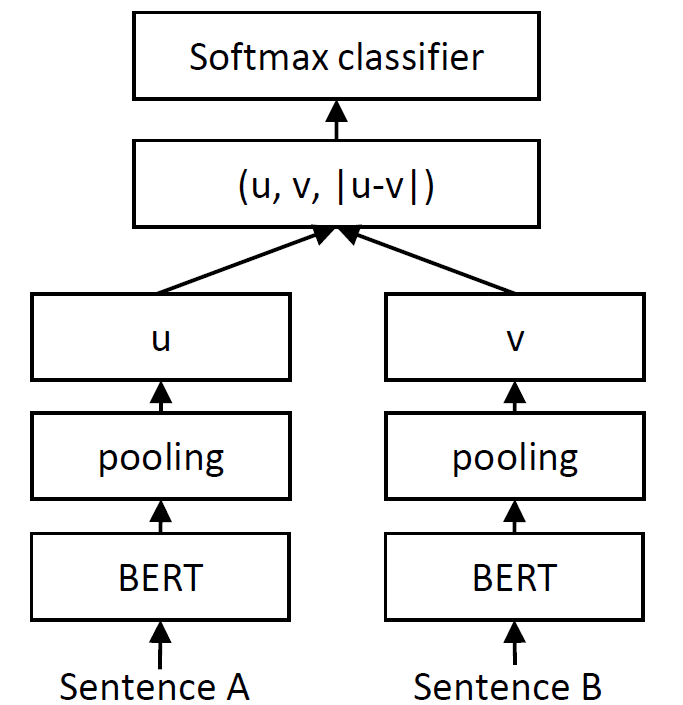
We will use outputs of the (u, v, | u — v |)-layer from such a network as a single vector embedding for each sentence pair. This is preferable to concatenating the sentence pairs into single strings as it would increase the risk of truncating the model inputs and losing information (particularly from the hypothesis).
For the next step, you have to choose a pretrained tokenizer+model from the Hugging Face Hub that will provide the token embeddings to the pooling layer of the network.
This is done by providing the name of the model on the Hub.
Find outliers in the datasets with cleanlab
We can find outliers in the training data with cleanlab’s OutOfDistribution class. This fits a nearest neighbor estimator to the training data (in feature space) and returns an outlier score for each example based on its average distance from its K nearest neighbors.
# Get outlier scores for each of the training data feature embeddings
ood = OutOfDistribution()
train_outlier_scores = ood.fit_score(features=train_embeddings)
We can look at the top outliers in the training data.

Next, we use the fitted nearest neighbor estimator to get outlier scores for the validation data, both the matched and mismatched validation sets.
# Get outlier scores for each of the feature embeddings in the *combined* validation set
test_feature_embeddings = np.concatenate([val_matched_embeddings, val_mismatched_embeddings], axis=0)
test_outlier_scores = ood.score(features=test_feature_embeddings)
First, we look at the top outliers in the validation data.
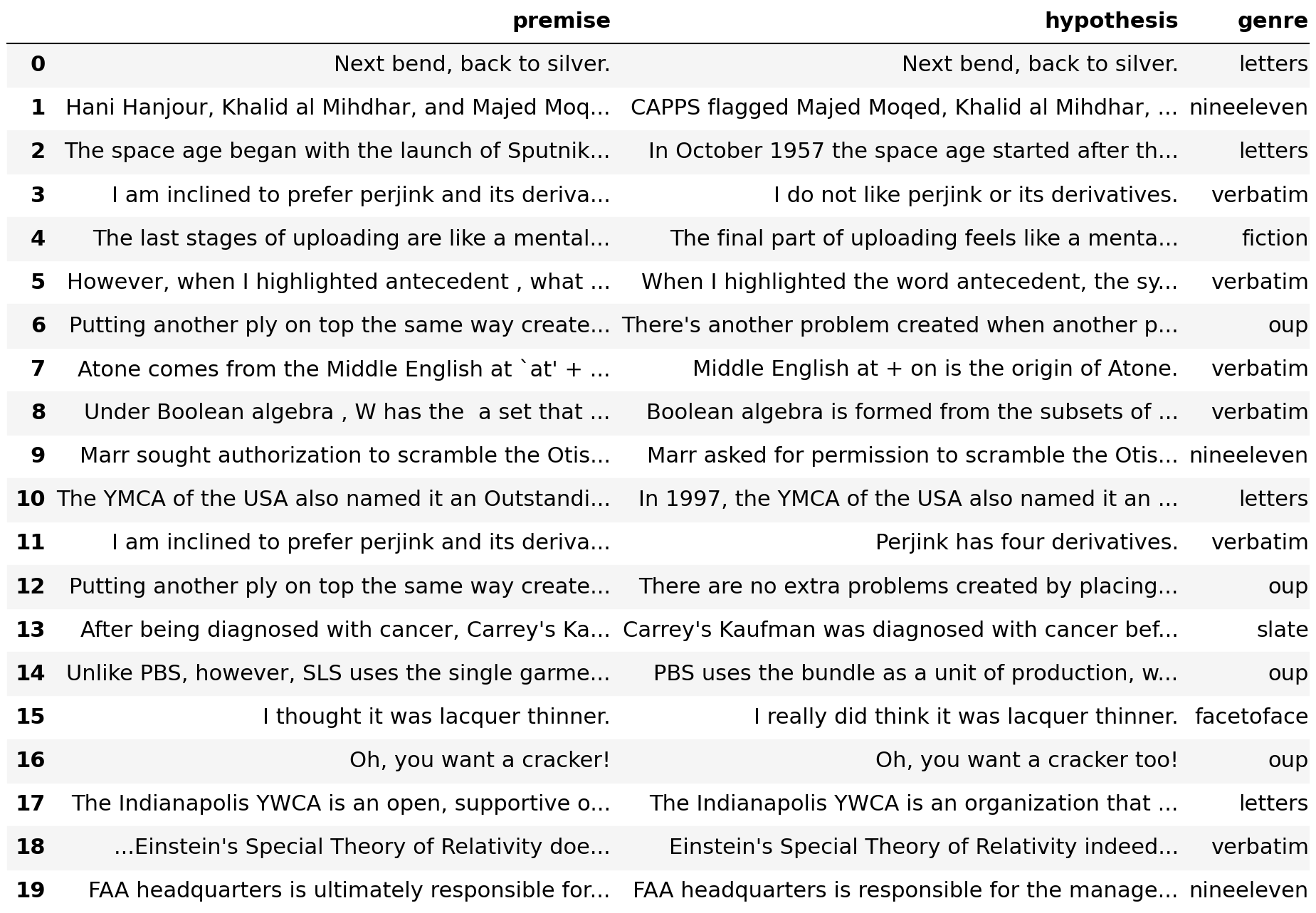
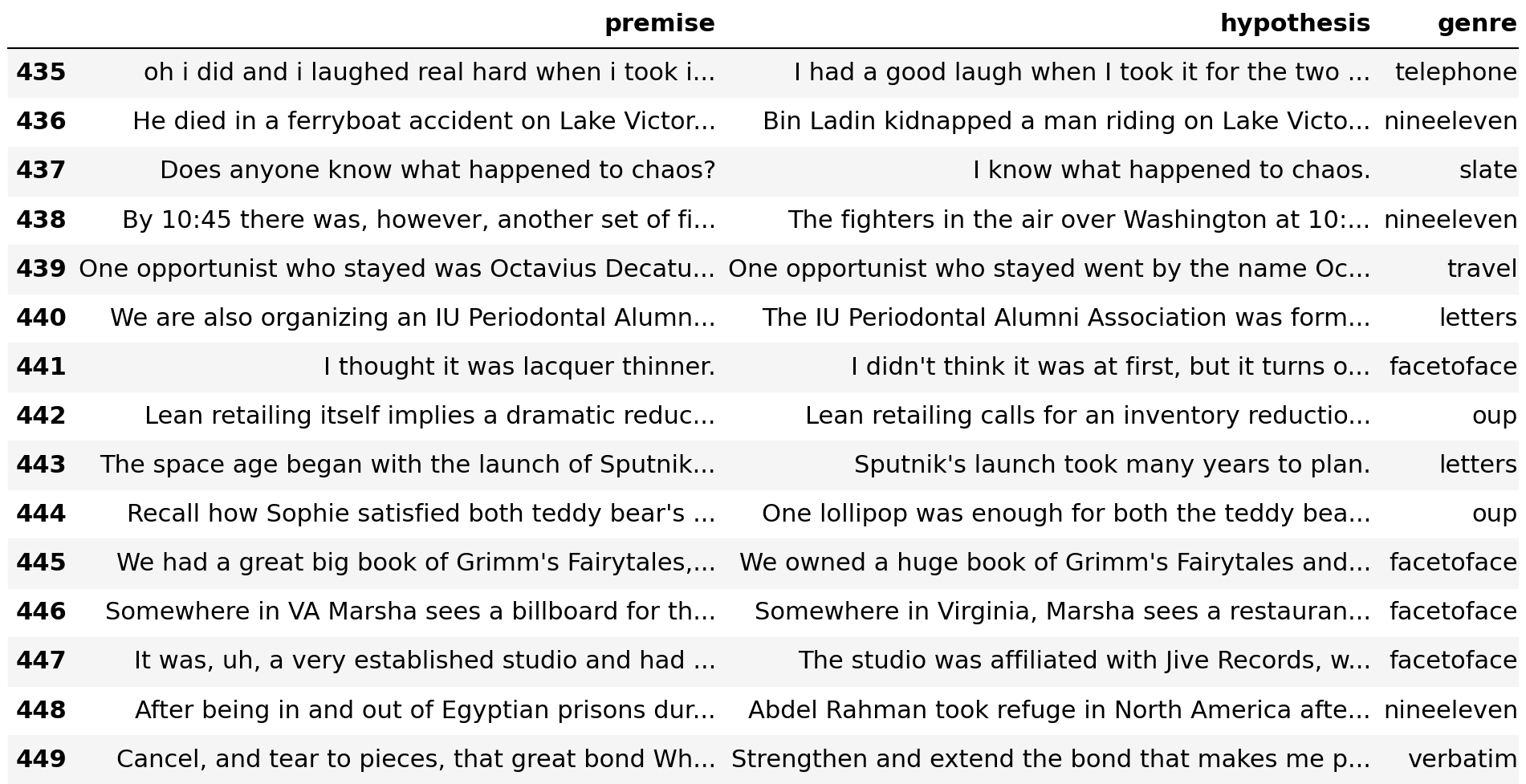
Although the combined validation set is balanced with respect to matched and mismatched genres, most of the examples with high outlier scores are from the mismatched validation set ([nineeleven, facetoface, letters, oup, verbatim]).
Compare this with examples at the other end of the spectrum that are considered unlikely to be outliers.
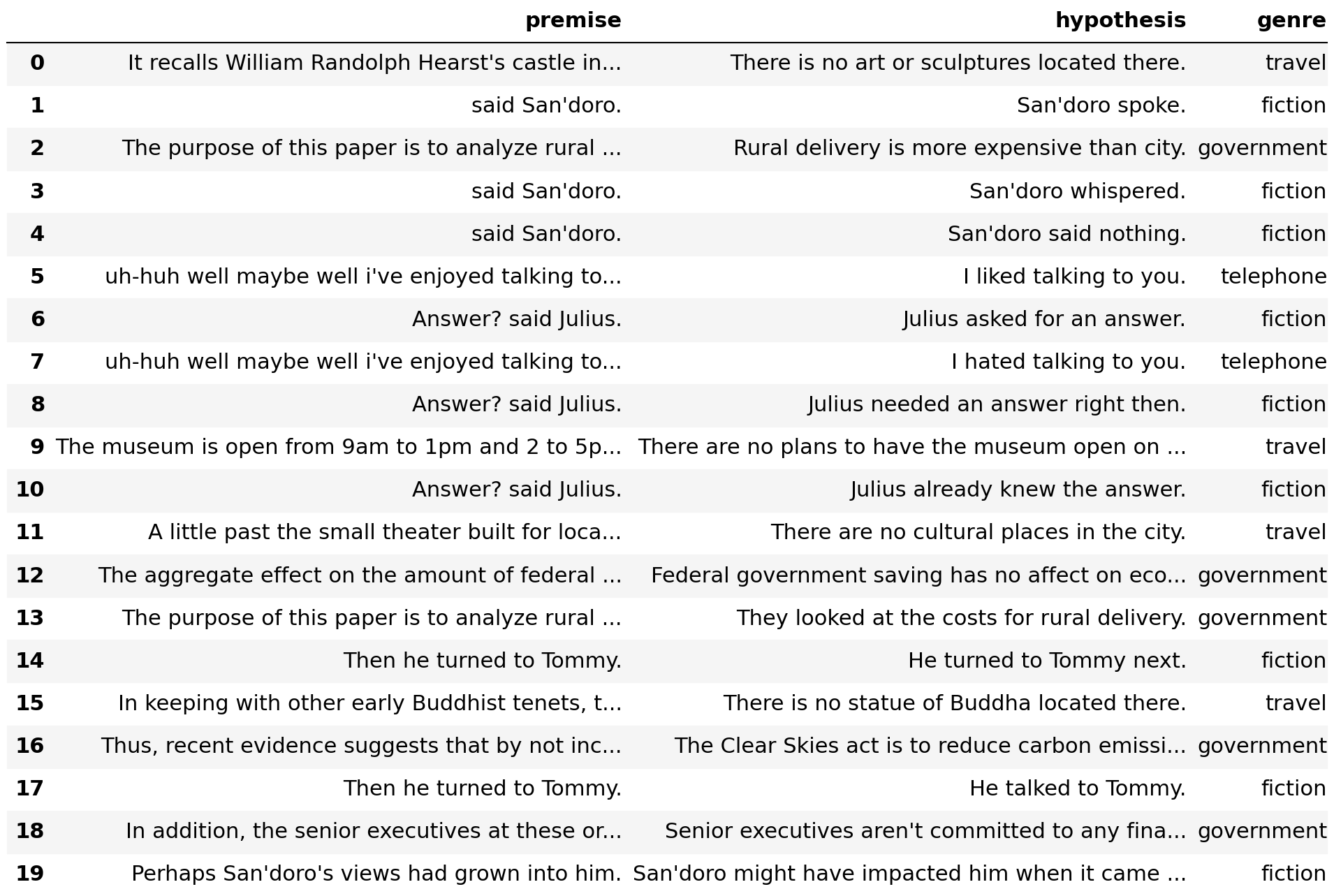
These examples are only from 4 of the 5 genres in the matched validation set ([fiction, government, telephone, travel]). The only exception is the slate genre, but the first example appears much further down this list.
Evaluate outlier scores
Realistically, if we already knew that the mismatched dataset contained different genres from those in the training set, we could do the outlier detection on each genre separately.
- I.e. detect outlier sentence pairs from nineeleven, then outliers from facetoface, etc.
To keep things brief for now, let’s consider outlier examples from the combined validation set.
We can set a threshold to decide what examples in the combined validation set are outliers. We’ll be conservative and use the 2.5-th percentile of the outlier score distribution in the training data as the threshold. This threshold is used to select examples from the combined validation set as outliers.
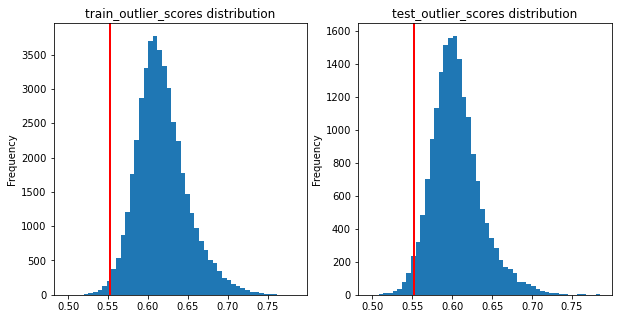
This will result in a few false positives, as can be seen below.
Cluster outliers
Let’s assume that we don’t know the content of the genres from the mismatched dataset. We can try clustering the outliers from the validation set to see if we can get a better idea about the mismatched genres.
With this assumption, it would make sense to use a density based clustering algorithm like HDBSCAN which can handle noise in the selected outlier examples. Unfortunately, it doesn’t perform well on high dimensional data. We’ll use UMAP to reduce the dimensionality of the data. For visualization purposes, we’ll reduce the dimensionality to 2 dimensions, but you may benefit from a slightly higher dimensionality if you expect some overlapping clusters.
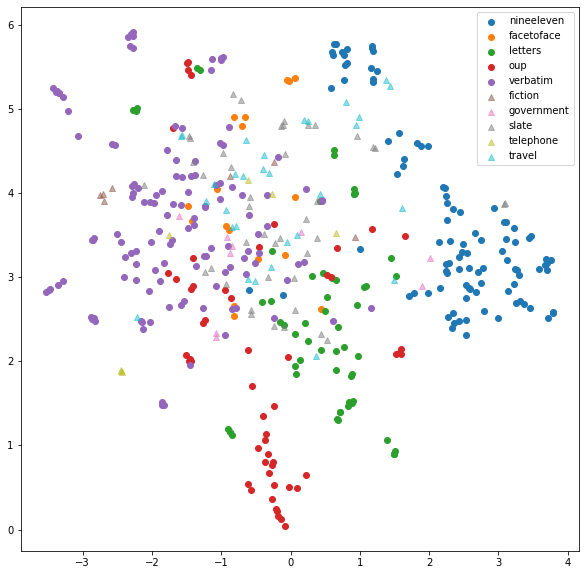
At a quick glance, we see that the mismatched genres tend to cluster together. Only facetoface overlaps with verbatim and the majority of the matched genres. Our best bet would be to look for small local clusters to see how a single genre contains multiple topics. We'll have to set a relatively small minimum cluster size and allow more localized clusters. This is done by lowering the min_cluster_size and min_samples parameters in the HDBSCAN algorithm.
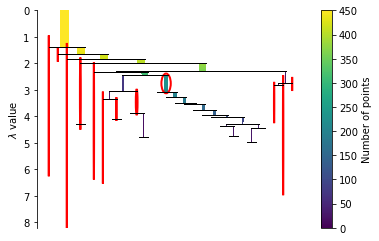
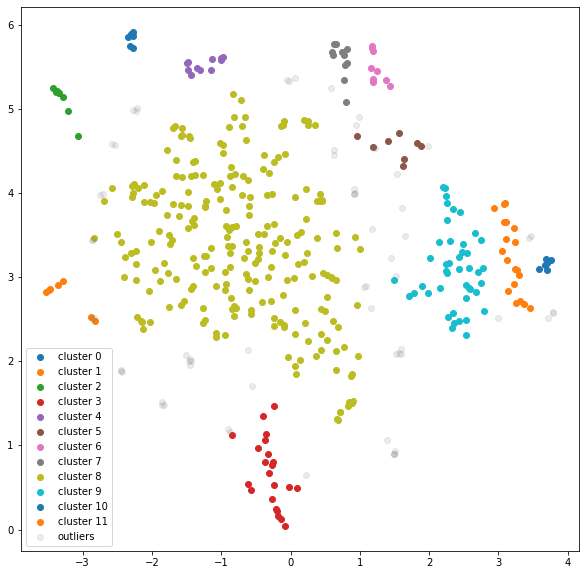
The clusters on the edges are relatively pure based on visual inspection, i.e. the majority of the points in each cluster are from the same genre.
The main exceptions are the:
- Violet cluster consisting of 3 genres.
- Yellow-green cluster in the center with multiple overlapping genres.
— This suggests that verbatim is an "in-distribution" topic. This is not useful for testing NLI models.
— This can be removed in some cases.
Most of the “pure” verbatim clusters might be too small to be insightful, but the larger nineeleven and oup clusters are promising.
Finding Topics with c-TF-IDF
A useful way of extracting topics from clusters of dense sentence/document embeddings is with c-TF-IDF. A nice article by James Briggs provides a clear implementation of c-TF-IDF for pre-computed embeddings and clusters. We reuse parts of that implementation below. To keep things simple, we use unigrams to extract topics.
Looking at the words with the top c-TF-IDF scores in each cluster should give us some idea of this cluster’s main topic.
Topic class 0: ['barrel', 'firearm', 'ramrod', 'patch', 'monkey', 'ball', 'wood']
Topic class 1: ['prefer', 'perjinkety', 'nicety', 'perjinkity', 'duende', 'perjink', 'derivatives']
Topic class 2: ['flamable', 'inflammable', 'trucks', 'onomatoplazia', 'substituted', 'delaney', 'examples']
Topic class 3: ['industry', 'retailer', 'lean', 'bundle', 'inventory', 'production', 'marker']
Topic class 4: ['muskrat', 'another', 'baby', 'version', 'muscat', 'lollipop', 'ramble']
Topic class 5: ['mihdhar', 'moqed', 'khalid', 'majed', 'hanjour', 'hani', 'al']
Topic class 6: ['abu', 'king', 'farouk', 'training', 'afghanistan', 'ubaidah', 'banshiri']
Topic class 7: ['agreed', 'ladins', 'war', 'efforts', 'turabi', 'bin', 'ladin']
Topic class 8: ['water', 'two', 'first', 'word', 'words', 'english', 'one']
Topic class 9: ['hazmi', 'fighters', 'boston', 'center', 'aircraft', 'command', 'hijacking']
Topic class 10: ['referred', 'tried', 'controller', 'york', 'united', 'crew', 'transponder']
Topic class 11: ['turned', 'shootdown', 'center', 'information', 'neads', 'united', 'american']
Outliers: ['cracker', 'atom', 'iupui', 'penney', 'american', 'bangers', 'controller']
Let’s visualize the clustered embeddings with their associated topics (left). For comparison, we’ll visualize the same embeddings with their original genres as labels (right).
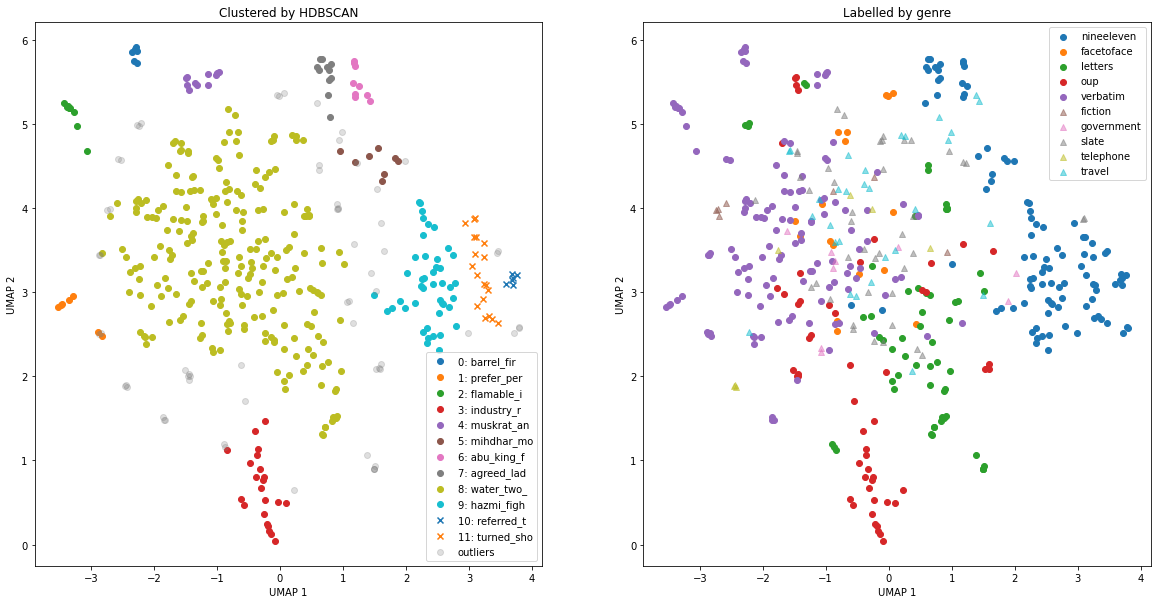
In the nineeleven genre, several topics stick out, some on US airline flights and others on middle eastern leaders. One topic is discovered in the oup genre, which appears to be about textiles. The remaining genres overlap too much to obtain meaningful topics. One way to handle the overlapping clusters is to redo the previous clustering exclusively on those points, e.g. by removing nineeleven from the analysis and recursively repeat this process as needed.
Conclusion
This analysis demonstrated how to identify and understand outliers in text data. The required methods are all available and easy to use in open-source Python libraries, and you should be able to apply the same code demonstrated here to your own text datasets.
The key takeaway is to encode your text examples with models that give high-quality embeddings and apply an outlier detection algorithm to these embeddings to select only rare/unusual examples for your topic modeling step.
You may be interested in the BERTopic package which can be used to: embed text via a BERT Transformer, reduce its dimensionality via UMAP, cluster via HDBSCAN, and identify topics in each cluster via c-TF-IDF.
I hope identifying and understanding outliers helps you ensure better quality data and ML performance in your own applications. You might choose to either omit such examples from your dataset, or to expand your data collection to obtain better coverage of such cases (if they seem relevant).
All images unless otherwise noted are by the author.
References
[1] A. Williams, N. Nangia and S. Bowman, A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference (2018), In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122, New Orleans, Louisiana. Association for Computational Linguistics.
[2] N. Reimers and I. Gurevych, Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (2019), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing
[3] C. Northcutt and J. Mueller, cleanlab 2.1 adds Multi-Annotator Analysis and Outlier Detection: toward a broad framework for Data-Centric AI (2022), Cleanlab
[4] J. Kuan and J. Mueller, Back to the Basics: Revisiting Out-of-Distribution Detection Baselines (2022), ICML Workshop on Principles of Distribution Shift 2022
[5] J. Briggs, Advanced Topic Modeling with BERTopic (2022), Pinecone
[6] M. Grootendorst, BERTopic: Neural topic modeling with a class-based TF-IDF procedure (2022), arXiv preprint arXiv:2203.05794
Understanding Outliers in Text Data with Transformers, Cleanlab, and Topic Modeling was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/D79HZV1
via RiYo Analytics







ليست هناك تعليقات