https://ift.tt/ekFNd8H Facebook SQL Interview Question Walkthrough — Popular Posts Our series of interview question walk-throughs marches ...
Facebook SQL Interview Question Walkthrough — Popular Posts
Our series of interview question walk-throughs marches on! Today we’ll be dealing with the advanced Meta/Facebook SQL interview question.

Meta/Facebook is all about data, and this data is created by you. What you like, comment and post as a user is collected and analyzed on a regular basis.
This analysis is represented in the interview question we’ll show you today. To make the explanations even easier, we made a video:
Meta/Facebook SQL Interview Question
The question asks you the following.
Here’s the link to the question if you want to follow along with me.
Your task is to identify the popular posts, which are defined as those viewed for over 5 seconds. For all the popular posts, you need to find the post ID and the total viewing time in seconds to pass this interview question.
The requirement seems easy, but there’s a reason this question is categorized as hard. We recommend that you tackle this, and all other coding interview questions, by applying this simple but efficient framework.
If you do, you’ll save yourself from making rash — and mostly wrong — decisions by not seeing all the traps that await you on the way to solving the question.
Solution Approach Framework to Solve Meta/Facebook (And All Others) SQL Interview Questions

The framework consists of three steps. We used this framework, with some variations to it, in many articles.
These are the steps we’ll apply when solving the example interview question.
- Exploring the dataset
- Writing out the approach
- Coding the solution
First, understand the dataset. What tables you’re given, and do you need all of them? How can the tables be joined? What are the tables’ columns, and data types, what does the data show, and how is it represented in the tables? These are all questions this step will help you answer.
Then think of how you will approach coding, the logical building blocks of your code, and what functions you’ll use. If you haven’t already, this is a must-step for engaging the interviewer. Talk with them and create a dialogue to verify if your logic is correct.
Finally, you can start coding your solution!
1. Exploring the Dataset
The question gives you tables user_sessions and post_views.
The user_sessions table has columns with the following data types.

You can assume the column session_id to be the table’s primary key. All other columns give you supporting info about the particular session.
When analyzing datasets, think about the narrative of how the columns and tables were created. That way, you’ll better understand the dataset in front of you. It also gives you an excellent opportunity to engage the interviewer, ask questions and clarify your assumptions. We always advise you to think out loud in the interviews. It might feel a little awkward initially, but you’ll soon get used to it when you see how efficient it is.
The narrative for this table could be formed like this. Each session ID is continuous and unique to a user and platform combination. If a user logs off and logs back in, that will create a new session ID. What if the user switches from laptop to mobile? This will be recorded as two separate sessions.
From that, you could expect to see duplicate user IDs and user_id/platform combinations.
The second table has the following schema.
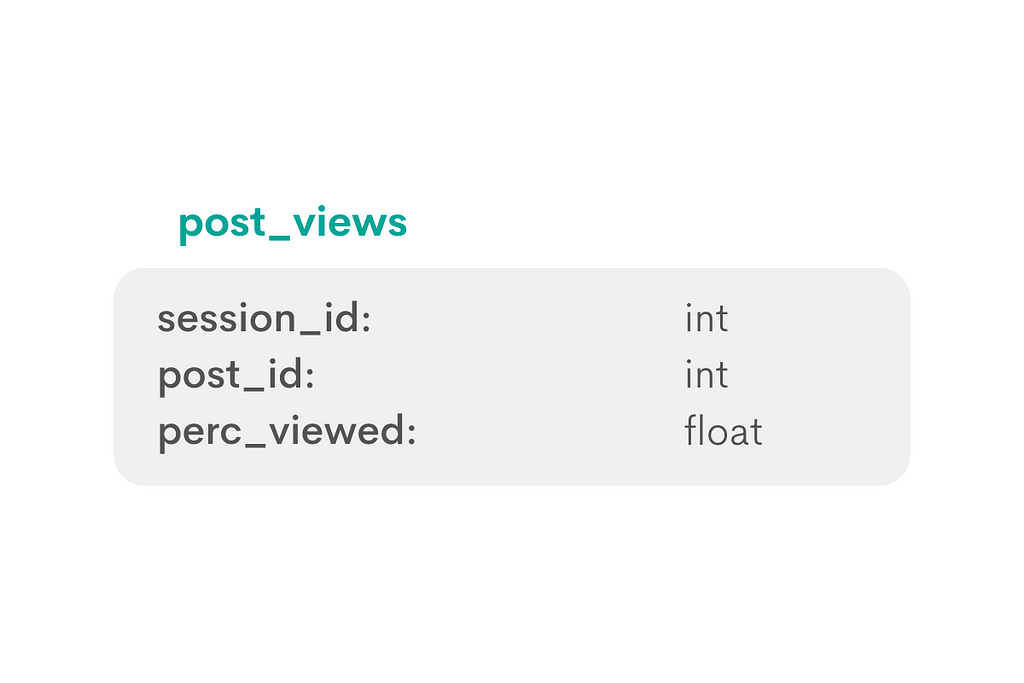
The column session_id is the same as in the first table, so it’s fair to assume that it is a foreign key for this table. The tables can be joined using this common column.
One important thing to know is how the data in the column perc_viewed is represented. Is 10% shown as 10.0 or 0.1? You can make an assumption or ask the interviewer.
The preview confirms how the percentage is shown.
Table: post_views
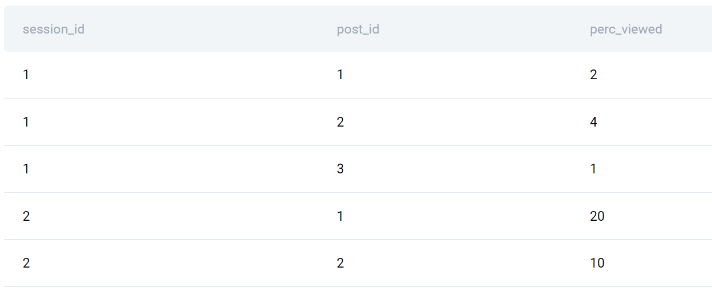
To continue the narrative, several posts can be viewed in a single session. Therefore, expect multiple session IDs in the above table.
Also, there will be multiple post IDs because posts can be viewed multiple times in different sessions.
2. Writing Out the Approach
When thinking about the approach, think about what the output should look like. Then, identify what data you need and how you need to manipulate it to get the required output.
For this question, the output will have two columns: post_id and total_viewtime.
1. Calculate the session duration
Duration is the difference between the session end time and start time, which you can find in the table user_sessions.
The functions EXTRACT() and EPOCH are a great combination to get the session duration in seconds.
2. Calculate the posts’ viewing times in each session
The post-viewing time can be calculated using the following formula.

PercentViewed is the percentage of the session spent viewing the post. This is represented by the column perc_viewed from the table post_views.
Also, the previous calculation has to be turned into a subquery and JOINed with this one.
3. Calculate the total viewing time for each post across all sessions
This calculation requires summing the PostViewingTime using the SUM() aggregate function.
To get the values on the post level, you need to group data by the column post_id.
4. Filter only the popular posts
Remember that the question defines popular posts as those with a viewing time higher than 5 seconds.
Since you’ll filter data after the aggregation, use HAVING instead of WHERE.
3. Coding the Solution
Let’s now use the outlined steps to write an SQL solution.
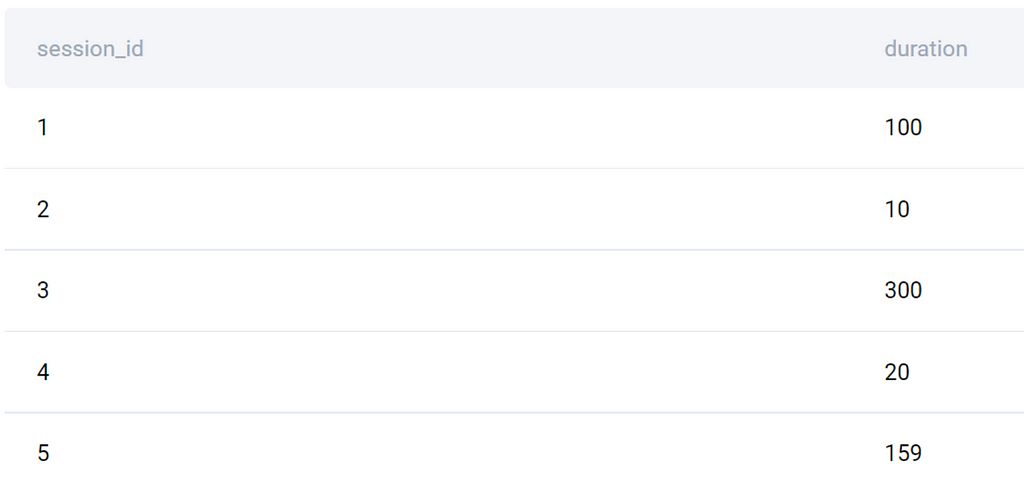
1. Calculate the session duration
SELECT session_id,
EXTRACT(EPOCH FROM session_endtime) - EXTRACT(EPOCH FROM session_starttime) AS duration
FROM user_sessions;
The command EXTRACT(EPOCH FROM column_name) returns a Unix Timestamp or a Unix Epoch Time. It is the number of seconds that have elapsed since 00:00:00 Thursday, 1 January 1970, Coordinated Universal Time (UTC).
On its own, this command isn’t very helpful for this analysis. However, once the deduction comes into the game, things get different. Subtracting two such values in seconds is the equivalent of getting the time difference between two datetime values in seconds. Guess what? This is exactly what you need to solve this problem.
Running the above code returns the following output.
You might think there’s a more straightforward way to do the same thing. For example, by directly subtracting the end and start time.
SELECT session_id,
(session_endtime - session_starttime) AS duration
FROM user_sessions;
Yes, it’s true; it’ll get you the same values and output — albeit only on the surface. When directly subtracting two dates, you’re creating an interval datatype as a result instead of a float or an integer.
We’ll also show you how to use this approach to get to the solution.
2. Calculate the posts’ viewing times in each session
In this step, add the SELECT statement that calculates the posts’ viewing time, and JOIN it with the previous query.
SELECT post_id,
duration * (perc_viewed/100)::float AS seconds_viewed
FROM post_views p
JOIN
(SELECT session_id,
EXTRACT(EPOCH FROM session_endtime) - EXTRACT(EPOCH FROM session_starttime) AS duration
FROM user_sessions) s ON s.session_id = p.session_id;
The query will output this data.

Our assumptions about data are proven to be right here. There are multiple entries for each post, each one representing a view for a separate session.
3. Calculate the total viewing time for each post across all sessions
To get the total viewing time for every post across all sessions, you need to aggregate the result at the post_id level and SUM() the total viewing time.
SELECT post_id,
SUM(duration * (perc_viewed/100)::float) AS total_viewtime
FROM post_views p
JOIN
(SELECT session_id,
EXTRACT(EPOCH FROM session_endtime) - EXTRACT(EPOCH FROM session_starttime) AS duration
FROM user_sessions) s ON p.session_id = s.session_id
GROUP BY post_id;
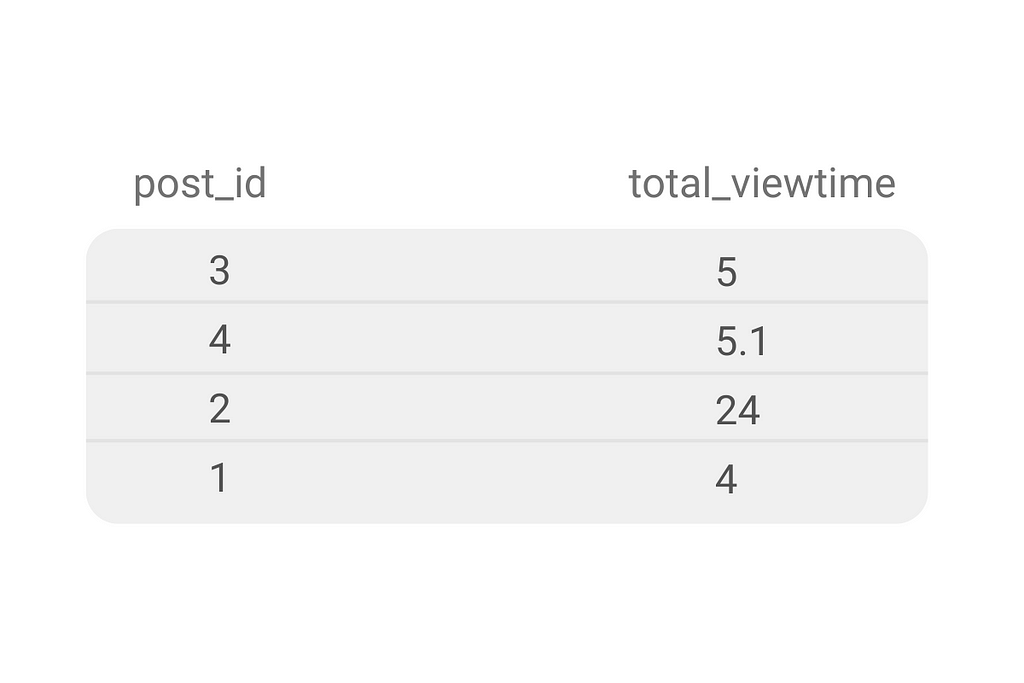
In this result, you get the unique posts and their total viewing time. In the final step, you’ll have to filter data to show only the popular posts.
4. Filter only the popular posts
To get the final output, you need to use the HAVING clause. You couldn’t use WHERE because you need the filter to be applied after the aggregation. You probably know that already, but it’s worth reminding yourself: WHERE filters data before, while HAVING filters it after the aggregation.
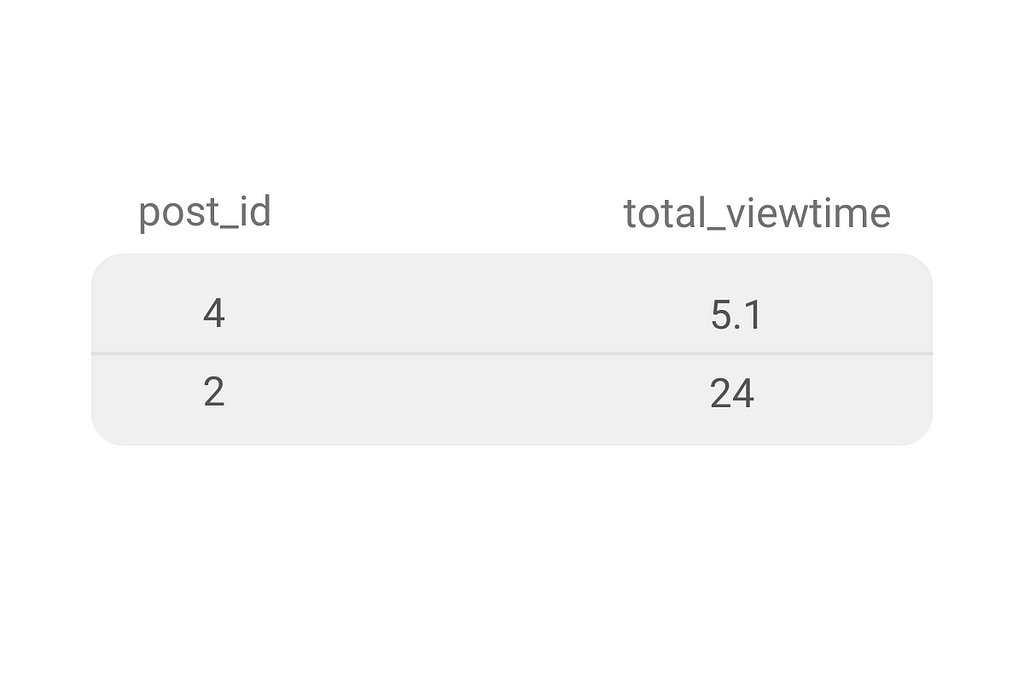
The output shows two popular posts with their respective total viewing time.
Alternative Solution
Remember when we said the dates could be subtracted directly? Let’s try and see would that approach gives the correct answer to this question.
SELECT post_id,
SUM(duration * (perc_viewed/100)::float) AS total_viewtime
FROM post_views p
JOIN
(SELECT session_id,
(session_endtime - session_starttime) AS duration
FROM user_sessions) s ON p.session_id = s.session_id
GROUP BY post_id
HAVING SUM(duration * (perc_viewed/100)::float) > 5;
Nope, it returns an error!

The error occurs because SUM(duration * (perc_viewed/100)::float) outputs an interval, and we’re comparing it to an integer.
However, it doesn’t mean we can’t make this approach work! The solution is rather easy; you have to convert the integer into an interval, like this.
SELECT post_id,
SUM(duration * (perc_viewed/100)::float) AS total_viewtime
FROM post_views p
JOIN
(SELECT session_id,
(session_endtime - session_starttime) AS duration
FROM user_sessions) s ON p.session_id = s.session_id
GROUP BY 1
HAVING SUM(duration * (perc_viewed/100)::float) > 5 * '1 sec'::interval;
This slight amendment to a code gives you the question solution.
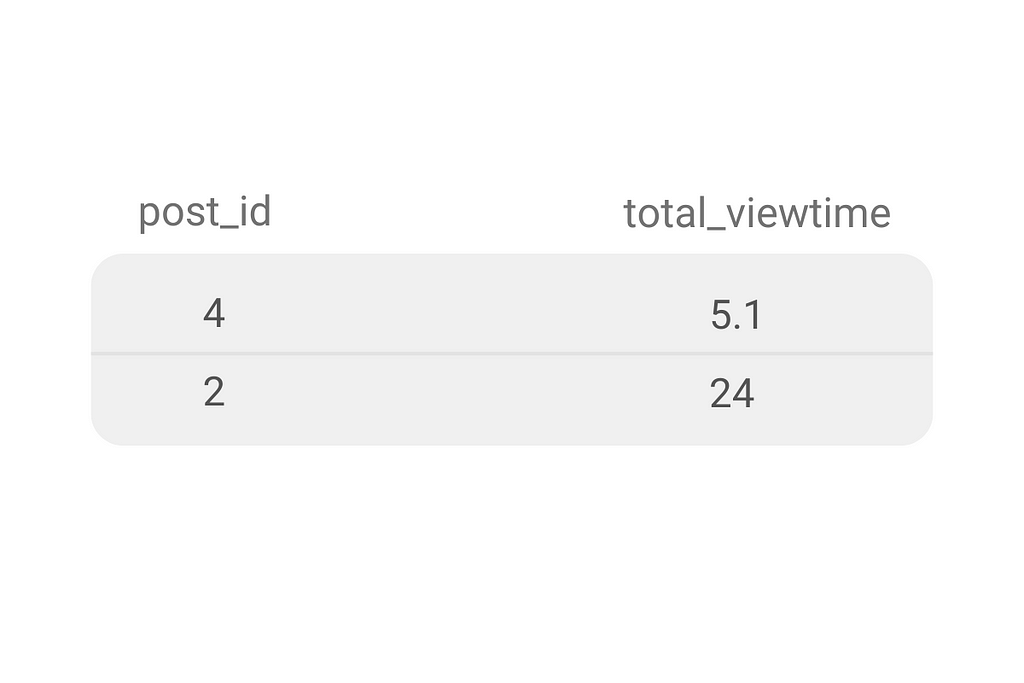
Optimizations
One of the questions you’ll get asked at most interviews is to optimize your code. Take a look at the solution and think about what can be optimized.
What comes to mind is making the code more readable by using the Common Table Expression or CTE.
Here’s what the optimized solution would look like.
WITH temp AS
(SELECT session_id,
EXTRACT(EPOCH FROM session_endtime) - EXTRACT(EPOCH FROM session_starttime) AS duration
FROM user_sessions)
SELECT post_id,
SUM(duration * (perc_viewed/100)::float) AS total_viewtime
FROM post_views p
JOIN temp ON p.session_id = temp.session_id
GROUP BY post_id
HAVING SUM(duration * (perc_viewed/100)::float) > 5;
Conclusion
It wasn’t that hard, was it?
We categorized this question as a hard-level problem because it requires knowledge of various technical concepts, such as JOINs, aggregations, filters, datetime data, and subqueries.
If you’re comfortable with these concepts, you shouldn’t have trouble finding a solution. Equally important is to know your data and to anticipate different data formats that could change your code and make it work or not.
All you need now is some practice. Check out posts like “Facebook SQL Interview Questions” and “Facebook Data Scientist Interview Questions” to practice more real world interview questions.
Facebook SQL Interview Question Walkthrough — Popular Posts was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/Q6Zoxf1
via RiYo Analytics








No comments