https://ift.tt/0d96BxD A comparative analysis Photo by Vishal Bansal on Unsplash Data science is widely used today to create Digital Tw...
A comparative analysis

Data science is widely used today to create Digital Twins — which are digital counterparts of real world physical systems or processes that can be used for simulation, prediction of behavior to inputs, monitoring, maintenance, planning etc. While such Digital Twins are commonly visible in everyday applications such as cognitive customer service bots, in this article, I would be comparing the Data Science techniques used for modeling two different types of Twins by illustrating with examples of each from industry.
The two widely used Data Science areas for Digital Twins discussed in this article are as follows:
a) Diagnostic and Predictive Analytics: Given a range of inputs, the Twin should be able to diagnose the causes or predict the future behavior of the system. IoT based machine learning models is what is used to create smart machines and plants whereby the inputs from sensors are analyzed in real time to diagnose, predict and thereby prevent future problems and failures before they occur.
b) Prescriptive Analytics: This is where an entire network is simulated to identify an optimal or feasible solution from a very large set of candidates, given a set of variables and constraints to be adhered to, usually with the objective of maximizing stated business goals, such as throughput, utilization, output etc. These Optimization problems are widely used for supply chain planning and scheduling, such as when a logistics provider creates a schedule for its resources (vehicles, personnel) to maximize on-time delivery, or a manufacturer creates a schedule for optimal utilization of machines and operators to achieve maximum OTIF deliveries. The Data Science technique used here is Constrained Mathematical Optimization, using powerful solvers to solve complex decision-driven problems.
To summarize, ML models predict likely outcomes for a given set of input features based on history, and Optimization models helps you decide that should a predicted outcome(s) happen, how should you plan to address/mitigate/take advantage of it, given that your business has several possibly competing objectives which you can choose to pursue with the limited resources at your disposal.
These two areas of Data Science, while sharing some tools such as python libraries, deploy data scientists with quite different skillsets and generally require different ways of thinking and modeling the business problem. So, lets try to understand and compare the approaches involved, so data scientists experienced in one field can understand, cross-leverage skills and techniques that may be applicable to the other.
Abstraction of the Digital Twin model
For the purposes of this comparison, let us consider a ML based Twin of a Production Root Cause Analysis (RCA) process, whose purpose is to diagnose the root cause of a deficiency or anomaly found in the finished product or during the manufacturing process. This would aid the line managers to troubleshoot the most likely root causes based on the predictions of the tool, identify the problem definitively and implement the CAPA (Corrective & Preventive actions), quickly and without expending much manual effort going through all the machine maintenance records, operator history, process SOPs, inputs from IoT sensors etc. The goal being to minimize machine downtime, loss of production and enhance resource utilization.
Technically, this can be thought of as a multi-class classification problem, where given a deficiency, the model is trying to predict the probabilities of each of a set of possible root cause labels, say machine related, operator related, process instructions related, raw material related or something else, and within these Level 1 categories, granular reasons such as machine calibration, machine maintenance, operator skill, operator training etc. Although the optimal solutions to this case require evaluation of several complex ML models, for the purposes of this article, let’s assume that this is a Multinomial Logistic Regression problem (reasons will be evident in the next sections).
And for comparison, consider an Optimization Twin of a Production planning process, which generates a schedule, that tries to maximize Objectives such as output or revenue, given the machines, operators, process steps, durations, raw material arrival schedule, expiry dates and many more. An automated schedule like this helps organizations quickly realign their resources to respond to emerging opportunities from markets (such as a drug demand due to COVID-19), or minimize impact of unforeseen events such as recent supply chain bottlenecks by altering their raw material, suppliers, logistics providers and customer/market portfolio mix.
At the basic level of modeling any business problem, there are the following factors to developing such Digital Twins:
A. Input features or dimensions
B. Input data — values of these dimensions
C. Rules for transformation of inputs to the output
D. Output or Objective
Let’s analyze and compare these factors in a little more depth for ML and Constrained Optimization models:
A. Input features: These are data dimensions in the system, both for ML and Optimization. For a ML model trying to diagnose problems in a production process, the features to be considered could be IoT inputs, machine maintenance history, operator skill and training, raw material quality, the SOP followed etc.
Similarly, in Constrained Optimization, the equipment availability, operator availability, raw material availability, working hours, productivity, skill are typical features that are needed to draw up an optimal production schedule
B. Input data — this is where both the approaches use the feature values in significantly different ways. A ML model expects a good volume of historical data for training. However, before the data is supplied to the model, a significant effort related to data preparation, curation, normalization is usually needed. It is to be noted that the history is a record of events that actually occurred (for instance, machine breakdown, or operator skill issue that resulted in a output deficiency), but is usually not a combination of every possible value that these features can take. In other words, the transaction history contains more records of frequently occurring scenarios, lesser of some others, and maybe very few of rarely occurring ones. And the goal of training the model is that it should be able to learn the relationships between the features and the output label(s), and predict accurate labels even for feature values or combinations that were few or did not exist in the training data.
On the other hand, for Optimization, the feature values are typically retained as their actual values, for instance, day number, batches, deadlines, raw material availability by date, maintenance schedule, changeover times of machines, process steps, operator skill etc. The key difference with an ML model is that the input data processing would entail generating every possible valid combination of the master data feature values (for eg; day, skill, machine, operator, process type), into index tables, that can form part of a feasible solution. An example would be Step 1 of the process is executed by Operator A with a skill level S1, using machine M1, on day 1 of the week, or Step 1 is executed by Operator B with skill level S2 using machine M1 on day 2.. and so on for every possible combination of operator, machine, skill level, day etc without consideration if any of these combinations actually occurred in the past . This will result in very large input data record sets, that are supplied to the Optimization engine. The goal of the Optimization model is to pick certain combination of feature values that adhere to stated Constraints, while maximizing (or minimizing) an Objective equation.
C. Rules for transformation of inputs to the output(s): This is also an area of significant difference in the two approaches. While both ML and Optimization models are based on advanced mathematics, it typically would require more effort to mathematically model and program a complex business problem adequately in Optimization as compared to ML, as will be evident in the following sections.
And the reason is that in ML, using one of the libraries such as scikit-learn, frameworks such as Pytorch or Tensorflow or any of the Cloud providers’ ML/Deep learning models, the rules for transforming inputs to output are left for the model to find, including loss correction to derive the optimal rules (weights, biases, activation functions etc.). The primary responsibility of the data scientist is to ensure the quality and integrity of the input features and their values.
This is not the case for Optimization where the rules as to how the inputs interact with one another and get transformed to the output(s) have to be written using detailed equations, which then are supplied to a solver such as Gurobi, CPLEX to find an optimal or feasible solution. Moreover, formulating business problems into mathematical equations requires deep domain knowledge of the interrelationships within the process being modeled and close cooperation of data scientist with the business analyst.
Let us illustrate this point with the following figure of the Logistic Regression model for the Problem RCA application:
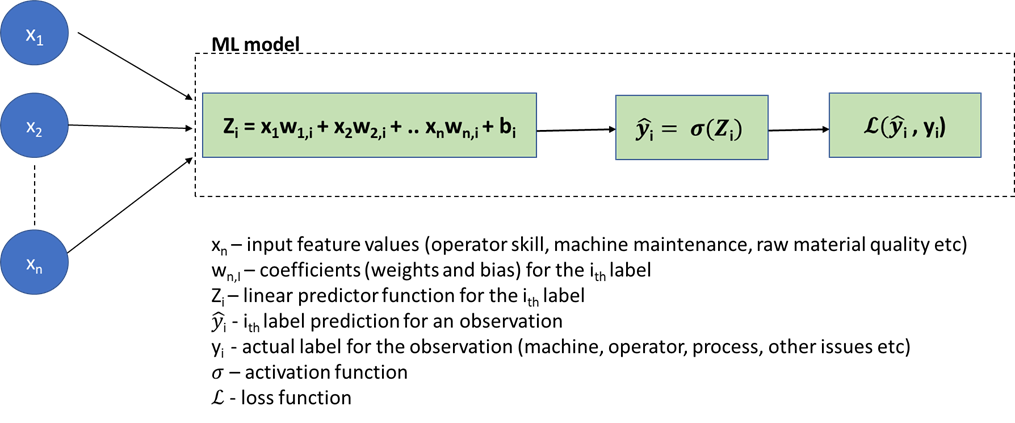
Note that in this case, the rules for generating the outcome (Zᵢ) from inputs are left to the model to derive, and the data scientist usually is occupied with visualizing the prediction accuracy using well-defined metrics of confusion matrix, RMSE etc.
Contrast this to how Optimization generates the Production schedule:
i) The first step is to define the business rules (Constraints) that encapsulate the planning process. Here is a sample for the Production planning example:
First we define some Input variables (a few of which can be decision variables, which are used to drive Objective):
Bᵦ,ₚ,ᵢ — Binary variable denoting if the batch β(in the batches table) of product p(in the products table) is scheduled on day i
Oₒ,ₚ,ᵢ – Binary variable denoting if operator at index o (in the Operators table), is scheduled to work on a batch of product p on day i
Mₘ,ₚ,ᵢ — Binary variable denoting if machine at index m (in the Machines table), is scheduled to work on a batch of product p on day i
And a few Coefficients
TOₒ,ₚ — Time taken by an operator o for a batch of product p
TMₘ,ₚ — Time taken by a machine m for a batch of product p
OAvₒ,ᵢ — Availability hours of Operator at index o on day i
MAvₘ,ᵢ — Availability hours of Machine at index m on day i
In this case, a few of the Constraints (rules) can be as follows:
a) A particular batch can be started only once in the schedule
For each batch of each product, where Bt is the total number of batches, Pr total number of products and D the number of days in the schedule:
b) A product can only be started once in a day, on only one operator or machine
For each day for each product, where Op is the set of all Operators and Mc is the set of all Machines:
c) The total time taken by batches (across all products) should not exceed the available hours of the operator and the machine on that day
For each day for each operator,
For each day for each machine,
d) If an operator(s) works on a batch of a product in the first 5 days of the schedule, then all the other batches of the same product is necessarily assigned to the same operator(s). This could be to maintain continuity and productivity of an operator.
For each day d (from 6th day onwards) for each operator and each product:
The above is a small subset of the hundreds of constraints that need to be written in a program to formulate the business rules for an actual production scheduling scenario into mathematical equations. Note that these constraints are linear equations (or more specifically, mixed integer equations). However, the complexity difference with the Logistic Regression ML model is obvious.
ii) Once the constraints are defined, the Output Objective needs to be defined. This is a crucial step and could be a complex process, as is explained in the next section.
iii) Finally, the input decision variables, constraints and objective are sent to the Solver to get a solution (schedule).
A figure to depict Optimization based Twin is as follows:
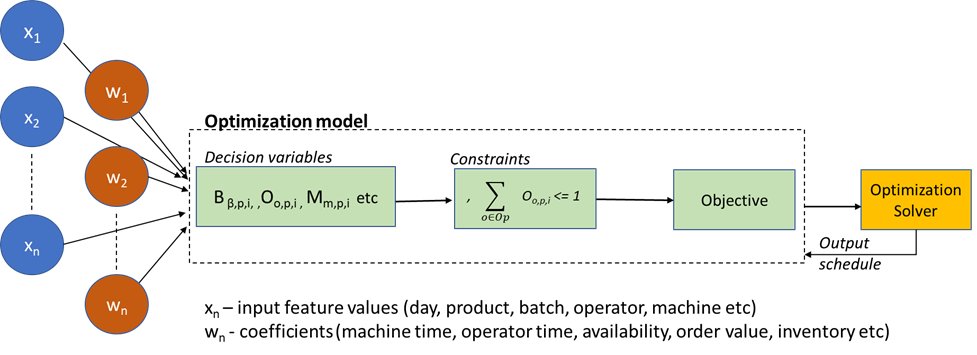
D. Output or Objective
For a ML model, the output and the metrics to measure the veracity of it are quite well established based on the type of problem (classification, regression, clustering). While I will not delve into these in this article, given the huge amount of information already available, it is worth noting that there is a high level of automation available to evaluate outputs of various models, such as the those by the leading CSPs (AWS Sagemaker, Azure ML etc.)
It is more challenging to evaluate if an Optimization model is generating the correct output. Optimization models work by trying to maximize or minimize a calculated expression known as Objective. As with Constraints, the Objective is left to the data scientist to design based on what the business is trying to achieve. This is done by attaching bonus and penalties to the decision variables, the sum of which the optimizer tries to maximize. For real-world problems, it takes several iterations to find the right weightages to the different objectives such that a good balance between sometimes contradictory objectives can be found.
To illustrate for the production scheduling example, two such Objectives could be:
a) The schedule should be front-loaded; batches should be scheduled as soon as possible, and any capacity left in the schedule should be at the end of the schedule. For this, we can attach a day penalty to a batch which increases progressively for each elapsed day in the schedule.
b) On the other hand, we also want to group batches of same product such that the resources (operators and machines) are optimally utilized, provided that the batches meet the delivery deadline, and the group does not exceed machine capacity for a run. Therefore, we define a Batch_group_bonus which provides a significantly higher bonus (hence the exponential in the expression below) if batches are scheduled in larger groups than small ones. It is to be noted that this can sometimes work at cross purposes to the previous objective as some batches which could have been started today would be started along with some more batches that are available a few days later, potentially leaving some underutilized resources earlier in the schedule.
The actual implementation would require a batch group decision variable due to how Solvers’ work, but this conveys the concept.
The Solver would maximize the Objective = Batch_group_bonus + Day_penalty
Which of the above two constituents of the Objective has more influence on a given day of the schedule depends on the weightages W₁, W₂ as well as the day of the schedule, since day penalty will grow progressively large in the later part of the schedule (higher i value). If the day penalty becomes larger than the Batch_group_bonus at some point, the Solver will find it prudent to not schedule a batch and thereby, incur zero penalty that to schedule and incur a net negative penalty, hence maximizing the Objective, even though there is resource capacity left in the schedule. Such issues are for the Data Scientist to troubleshoot and solve.
Relative Effort of a ML vs Optimization project
Based on the above discussion, it can be surmised that in general, an Optimization project will take more effort than a ML project. Optimization requires significant more data science work at almost every stage of the development process. To summarize:
a) Input data processing: In both ML and Optimization, this is done by the Data Scientist. ML data processing requires selection of relevant features, standardization, discretization etc. For unstructured data such as text, it could include NLP based methods such as feature extraction, tokenization etc. There are a wide range of libraries available in many languages for statistical analysis of features as well as for dimensionality reduction methods such as PCA.
In Optimization, every business and schedule has nuances which need to be brought into the model. Optimization problems don’t deal with historical data, rather formulating every possible data variation and combination of identified features into indexes on which the decision variables and constraints have to be based. While different than a ML, the data processing requires extensive development work.
b) Model development: As explained above, the model formulation for Optimization requires significant effort from data scientist and business analyst to formulate the constraints and objective. The Solver runs Mathematical algorithms, and while it is tasked with solving hundreds, possibly thousands of equations simultaneously to find a solution, it has no business context.
In ML, model training is highly automated, and algorithms come packaged as open source library APIs, or those by the Cloud Service Providers. Highly complex, pre-trained, neural network models simplify the training task to only the last few layers, based on business specific data. Tools such as AWS Sagemaker Autopilot or Azure AutoML, even automate the entire process of input data processing, feature selection, training and evaluation of different models and output generation.
c) Testing and Output processing: In ML, output from the model can be utilized with minimal processing. It is usually quite interpretable (as probabilities of different labels, for instance), although some effort may be required to bring in additional aspects such as explainability of the result. There is also effort that may be needed for output and error visualization, but these are not much as compared to the Input processing.
Here too, Optimization problems require iterative manual testing and validation by the trained eye of the planning expert to evaluate the schedule. While the Solver tries to maximize the Objective, that itself usually has little meaning from the perspective of the schedule quality. Unlike ML, it cannot be said that the Objective value being above or below a threshold comprises a correct or incorrect schedule. When a schedule is found to not meeting the business objectives, the issue could be with the Constraints, decision variables or the Objective function, and needs careful analysis to find the cause of an anomaly in a large and complex schedule.
Also, to be considered is the development required to interpret the output of the Solver into human readable format. The Solver inputs decision variables, which are index values of actual physical entities in the schedule, for instance, batch group index, batch priority index, operator and machine index, and returns which ones that have been selected. A reverse processing needs to be done to convert these index values from respective dataframes into a coherent schedule that can be visually presented and analyzed by an expert
d) And finally, even during operational phase, a ML model consumes much less compute and time to generate a prediction for an observation compared to the training phase. However, a schedule is built every time from scratch, and needs the same resources for every run.
Following figure is a rough illustration of the relative effort by phases of ML and Optimization projects:
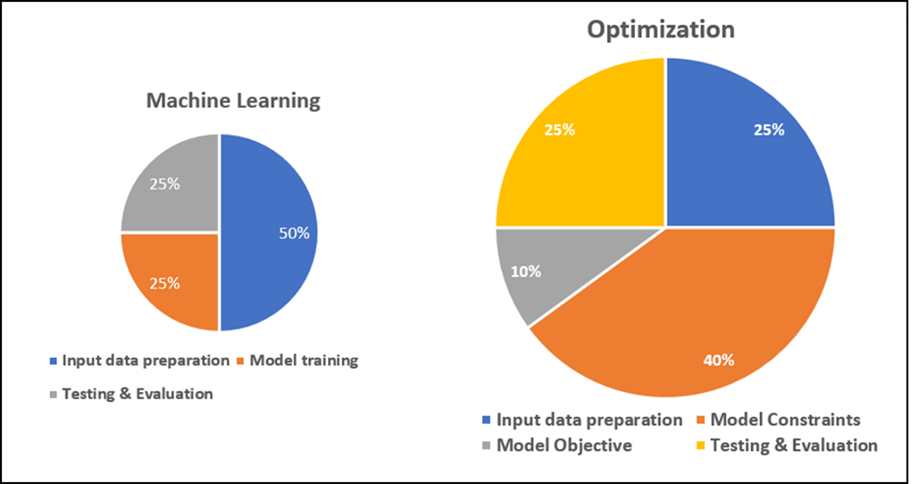
Can ML and Optimization work together?
Machine Learning and Optimization solve complementary problems for an enterprise and therefore co-exist where the output of ML models feed the Optimization and vice versa. AI/ML applications such as IoT enabled predictive maintenance and fault detection, remote maintenance with AR/VR and the Production process RCA mentioned here form part of a manufacturers’ Connected Factory strategy.
Optimization applications form the basis for Supply Chain planning, and can be thought of as Connecting Business Strategy to Operations. They help the organization respond and plan for unforeseen events. For instance, if there is a problem detected in a line, the RCA tool will help the line managers to narrow the probable causes quickly and implement necessary actions. This may however, sometimes result in unplanned machine downtime or operator reassignment. And therefore, may necessitate re-generating the production schedule with the available reduced capacity.
Can some techniques of ML be applied to Optimization and vice versa ?
It is possible to apply learnings from ML projects to Optimization and vice versa. As an example, the Objective function which is critical to Optimization output is sometimes not as well defined by business for mathematical modeling as the Constraints, which are rules that must be adhered to, and therefore usually well known. To illustrate, the business objectives could be as follows:
a) Batches should be scheduled as early as possible, in the order of priority while adhering to the delivery deadline
b) Schedule should be front-loaded; with as few gaps and underutilization of resources as possible
c) Batches should be grouped together to utilize capacities efficiently
d) Operators with a higher skill level for high value products should preferably be assigned such batches.
Some of these can be competing priorities that need to be balanced appropriately, which result in the data scientist writing a complex mix of influencing factors (bonus and penalties), usually by trial-and-error that seem to work for the most common planning scenarios, but are sometimes difficult to understand logically and maintain when defects arise. And because the Optimization Solver is a third-party product whose code is not available to the data scientist building the model to debug, it is not possible to see what values certain bonus and penalties are taking at any specific point during the schedule generation that is making it behave the way it is, which makes it important to write cogent Objective expressions.
It therefore helps to adopt normalization of the bonus and penalties that is a widely used ML practice. Normalized values can then be scaled in a controlled manner, using configuration parameters or otherwise, to control the influence of each factor, how they relate to each other as well as to the preceding and succeeding values within each factor.
Conclusion
Machine learning and Optimization are both highly mathematical methods that solve different sets of problems in organizations and in our daily lives. They are used to deploy Digital Twins of physical equipment, process or networks. While both types of applications follow similar high-level development stages, ML projects can take advantage of a high level of automation available in libraries and Cloud native algorithms, whereas Optimization requires a close collaboration of business and data scientist to model complex planning processes adequately. In general, Optimization projects require more development effort and are resource intensive. Both ML and Optimization tools work in synergy in an enterprise and both techniques are useful for a data scientist to learn.
All images unless otherwise noted are by the author.
Digital Twin Modeling Using Machine Learning and Constrained Optimization was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/j4i0RWb
via RiYo Analytics








No comments