https://ift.tt/2rQmfDh From input transformation to grid search with scikit-learn “One Pipeline to rule them all, One Pipeline to find the...
From input transformation to grid search with scikit-learn
“One Pipeline to rule them all, One Pipeline to find them, One Pipeline to bring them all and in the brightness fit them.”

When we look at the “Table of Contents” of a machine learning book on the market (i.e. Ǵeron, 2019), we see that after getting the data and visualizing it to gain insights, broadly, there are steps such as data cleaning, transforming and handling data attributes, scaling features, training and then fine-tuning a model. Data scientists’ beloved module, scikit-learn, has an amazing functionality (class) to handle these steps in a streamlined way: Pipeline.
Whilst exploring the best use of Pipelines online, I’ve come across great implementations. Luvsandorj nicely explained what they are (2020) and showed how one can customize a simpler one (2022). Ǵeron (2019, p.71–72) gave an example of writing our “own custom transformer for tasks such as custom clean-up operations or combining specific attributes”. Miles (2021) showed how one can run a grid search with a pipeline with one classifier. On the other hand, Batista (2018) presented how one can include lots of classifiers in a grid search without a pipeline.
Introduction
In this post, I will combine these sources together to come up with the ultimate ML pipeline that can handle the majority of the ML tasks such as (i) feature cleaning, (ii) handling missing values, (iii) scaling and encoding features, (iv) dimensionality reduction and (v) running many classifiers with different combinations of parameters (grid search) as the following diagram presents.
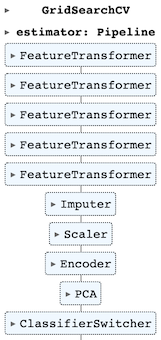
Table of Contents
III- Setting Grid Search Parameters
IV- Building and Fitting Pipeline
I-Libraries and Data Set
For simplicity purposes, let’s use the Titanic data set, which can easily be loaded from the seaborn library.
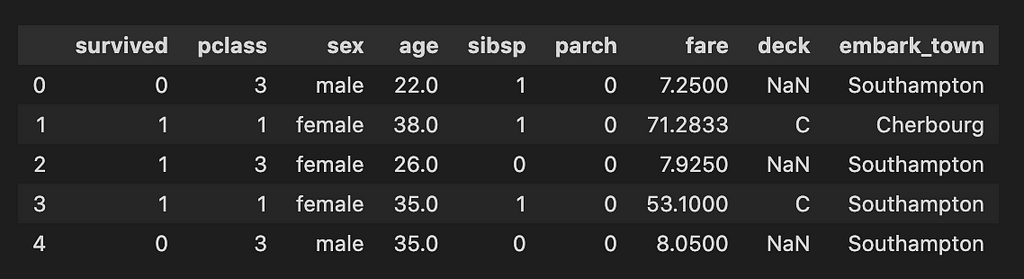
II-Setting Classes
We need to create the following classes for this process:
- “FeatureTransformer” to manipulate pandas dataframes, columns. For instance, although it has no impact on the model, I added a “strlowercase” parameter which can be applied on a (list of) column(s) to transform data. (inspired by Ǵeron, 2019, p.71–72)
- “Imputer” to handle missing values (similar to sklearn’s SimpleImputer class)
- “Scaler” to handle missing values (similar to sklearn’s StandardScaler class)
- “Encoder” to encode (categorical or ordinal) features (inspired by Luvsandorj, 2022)
- “ClassifierSwitcher” to switch between classifiers in the grid search step. (inspired by Miles, 2021)
III- Setting Grid Search Parameters
We create two dictionaries (inspired by Batista, 2018):
1- models_for_gridsearch = Classifier names as keys, classifier objects as values
2- params_for_models = Classifier names as keys, classifier hyper parameters as:
- Either empty dictionaries (such as LogisticRegression row meaning classifier will be used with default parameters) or
- Dictionaries with list(s) (KNeighboursClassifier or RandomForestClassifier row)
- List of dictionaries (such as SVC row)
Note: I commented out other classifier objects for simplicity purposes.
We aim to create a list of dictionaries that have the classifier and parameter choice which then will be used in the grid search.
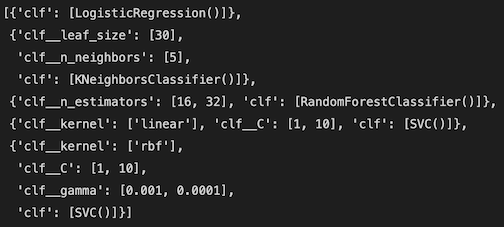
IV- Building and Fitting Pipeline
We have created the classes we need for our pipeline. It’s time to use them in an order and fit it.
We have a pipeline that
- Assigns data types to our columns,
- Does basic data transformations for some of the columns
- Imputes missing values for the numerical columns and scales them
- Encodes categorical columns,
- Reduces dimensions,
- Passes classifiers once fed.
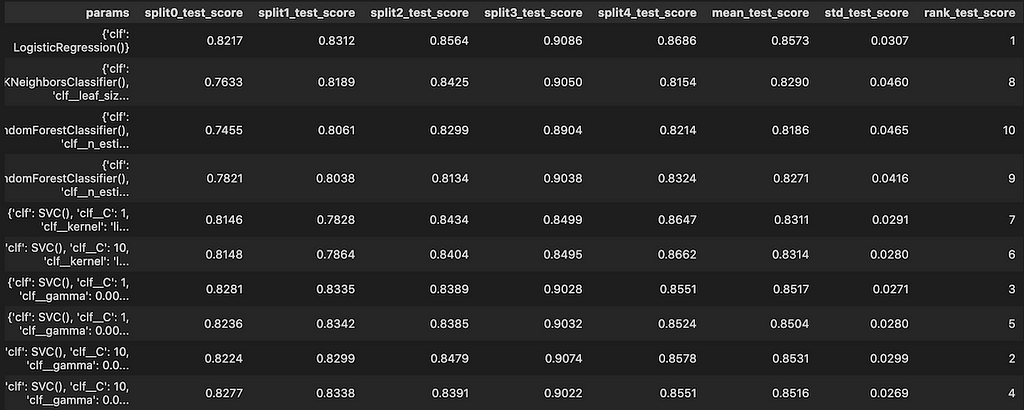
After splitting the data into training, and test sets, we feed this pipeline into the GridSearchCV alongside the grid search pipeline parameters to find the best scoring model and fit it to our train set.
Best parameters: {‘clf’: LogisticRegression()}
Best score: 0.8573
V- Calculating Scores
We can use the fitted pipeline (pipeline_gridsearch) to calculate scores or find probabilities of each instance belonging to our target status.
Train ROC-AUC: 0.8649
Test ROC-AUC: 0.8281
One can see that the embark town values are lower case due to our FeatureTransformer step. After all, it was to demonstrate that we can transform our feature within the pipeline.
Conclusion
Customizing sklearn classes in a way that can (i) transform and pre-process our features, (ii) fit multiple ML models for a variety of hyperparameters, is helpful to increase readability of our code and have a better control over the ML steps. Even though this method requires sequential computing (please see image below) as opposed to the parallelization that multiple pipeline methods could offer, despite that marginal time loss, building one pipeline alone would be more beneficial in an environment where we need to loop through many conditions, parameters, pre-processing steps to see their impact on the model.
References
- Ǵeron, A. (2019). Hands-on machine learning with Scikit-Learn, Keras and TensorFlow: concepts, tools, and techniques to build intelligent systems (2nd ed.). O’Reilly.
- Luvsandorj, Z 2020, ‘Pipeline, ColumnTransformer and FeatureUnion explained’, Towards Data Science, 29 Sep, accessed 21 Oct 2022, <https://towardsdatascience.com/pipeline-columntransformer-and-featureunion-explained-f5491f815f>
- Luvsandorj, Z 2022, ‘From ML Model to ML Pipeline’, Towards Data Science, 2 May, accessed 21 Oct 2022, <https://towardsdatascience.com/from-ml-model-to-ml-pipeline-9f95c32c6512>
- Miles, J 2021, ‘Getting the Most out of scikit-learn Pipelines’, Towards Data Science, 29 Jul, accessed 21 Oct 2022, <https://towardsdatascience.com/getting-the-most-out-of-scikit-learn-pipelines-c2afc4410f1a>
- Batista, D 2018, ‘Hyperparameter optimization across multiple models in scikit-learn, personal blog, 23 Feb, accessed 21 Oct 2022, <https://www.davidsbatista.net/blog/2018/02/23/model_optimization/>
- Waskom, M. L., (2021). seaborn: statistical data visualization. Journal of Open Source Software, 6(60), 3021, https://doi.org/10.21105/joss.03021
Crafting One Pipeline for Machine Learning Steps was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/OCh1GSQ
via RiYo Analytics







ليست هناك تعليقات