https://ift.tt/4snUxDJ Precision and Recall elaborated with sample situations Photo by Afif Kusuma on Unsplash · Introduction · Preci...
Precision and Recall elaborated with sample situations

· Introduction
· Precision and Recall
· Precision
∘ Understanding the Precision Mindset
· Recall
∘ Understanding the Recall Mindset
· Precision vs Recall
· Conclusion
Introduction
Utilizing the right set of evaluation metrics to estimate the performance of a data-driven classification model holds immense importance in building and delivering a reliable machine learning solution/product.
As the name suggests, classification models are a category of machine learning algorithms specifically designed to predict the correct class for a given input.
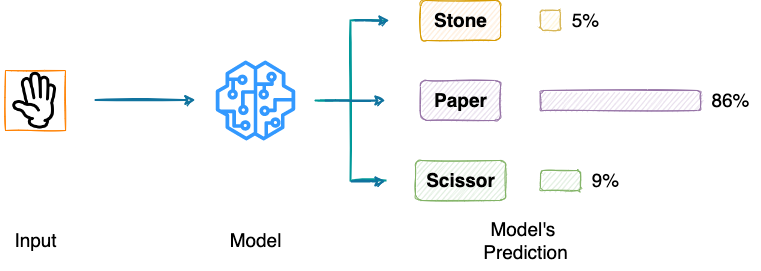
Right off the bat, the first performance metric you would see almost every machine learning engineer using to evaluate their model’s labeling performance is “Accuracy” — the percentage of correct predictions made by the model.

The simple computation and interpretability make Accuracy one of the most commonly used performance metrics.
However, in practice, Accuracy is usually notorious for hiding essential bits of information about the model’s performance.
This gets especially challenging in situations of imbalanced data, wherein the data is primarily skewed towards a particular class. Examples include fraud detection, spam classification, etc.
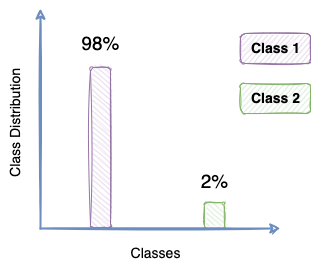
In such cases, blindly predicting the majority class, as in the figure above, leads to an accuracy of 98% — even though the model has not learned anything from the data.
However, such a naive classifier holds no applicability to the problem at hand — suggesting the need for a better performance metric.
Introducing Precision and Recall!
Precision and Recall
Both Precision and Recall are two of the most popularly used classification metrics in estimating the performance of Classification-based Machine Learning models — especially with imbalanced data.
In the case of imbalanced data, it is primarily the minority class that is of utmost interest to us that we wish to model and is treated as the problem we intend to solve.
In this regard, a prediction in favor of the minority class is often referred to as a POSITIVE prediction, and that in favor of the majority class is called a NEGATIVE prediction.
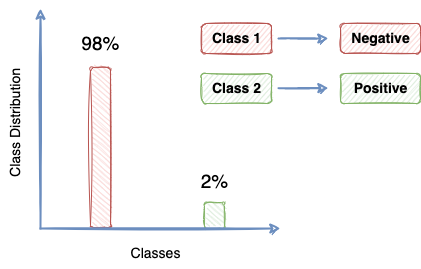
A popular cross-tabulation of the model’s predictions with the ground truth labels is illustrated in the diagram below:
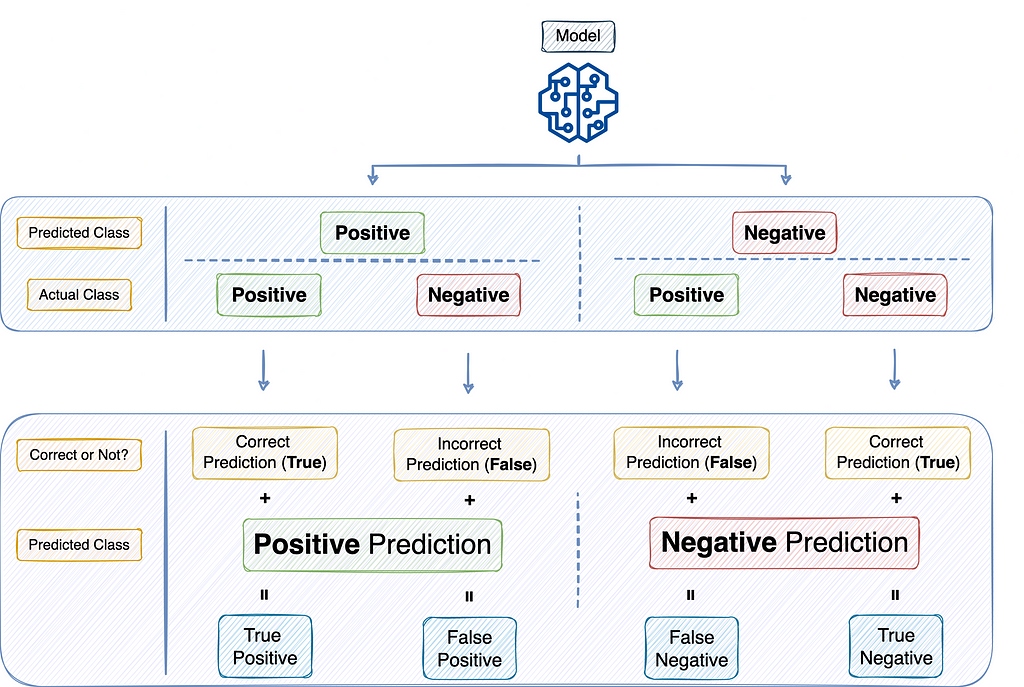
Let’s understand Precision first.
Precision
Precision answers the following question:
What proportion of positive predictions were actually correct?
From the pool of all positive predictions made by the system, Precision finds the fraction of those that, in reality, were actually positive.
For example, in the case of an email spam classifier, if the system classified 10 emails as spam (predicted as positive), but only 5 were actually spam (actual positives), then the Precision is 50%.

A point to note here is that Precision, as a metric, only focuses on those samples (or data points) that the ML system predicted as positive.
Therefore, it ignores all the actual positives classified as negative by the model.
You may also define Precision as the model’s accuracy on all its positive predictions.

So to summarize, Precision is the fraction of actual positives among the positives that the ML system found.
Understanding the Precision Mindset
When you are following a precision mindset, what you are essentially conveying to the model is that don’t waste my time by yielding false positives in an attempt to find every positive thing out there.
Rather, whatever positive predictions you return should actually be positive.
In other words, here, you are at peace even if the model missed some actual positives and classified them as negative as long as the positive predictions are actually positive.
However, what makes you furious is the presence of positive predictions that actually were negative.
Revisiting the email example again, if you are targeting high Precision, you are okay if an actual spam email gets classified as non-spam (actual positive predicted as negative).
However, what you cannot tolerate is a non-spam email being tagged as spam.
Considering the mathematical formula above, a way to increase Precision is by having as low “False Positives” as possible. That is, having the least number of positive predictions that actually weren’t positive.
Recall
Recall answers the following question:
What proportion of actual positives was identified correctly by the model?
From the pool of all actual positives, Recall finds the fractions of those that the model classified as positive.
As an example of an email spam classifier (again), if there were 10 spam emails (actual positives) in the entire dataset and the model classified 7 of them as spam (predicted as positive), the Recall is 70%.

A point to note here is that Recall, as a metric, only focuses on those samples (or data points) that were actual positives in the dataset.

In simple words, you may also define Recall as the model’s accuracy on all the positive examples in the dataset.
Understanding the Recall Mindset
While following a Recall mindset, what you are essentially conveying to the model is to capture all the positive examples from the dataset.
In other words, here, you are at peace even if the model classifies some examples as positive that were originally negative as long as it correctly classifies all the positive samples from the dataset.
However, what makes you furious is the misclassification of positive examples in the dataset.
Revisiting the email example, if you are targeting high Recall instead of Precision, you are okay if a non-spam email gets classified as spam as long as all the actual spam emails are caught.
However, what you cannot tolerate is missing any actual spam email.
Considering the mathematical formula above, a way to increase Recall is by having as low “False Negatives” as possible. That is, having the least number of negative predictions that actually were positive.
Precision vs Recall
To summarize:
- A system with high Precision might leave out some actual positives, but what it intends to return is high accuracy on the positive class.
- On the other hand, a system with high Recall might give you numerous misclassifications of actual negatives, but it almost always will correctly classify the actual positives from the dataset.
Which one to choose is a tough decision and entirely depends on the problem you are using machine learning for.
Generally speaking, optimizing Precision typically reduces Recall and vice versa. Therefore, many applications consider a metric derived from both Precision and Recall (called the F-score) to measure the performance of a machine learning situation.
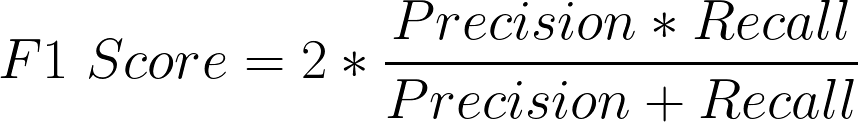
Below, let’s consider some sample situations to decide which metric among Precision and Recall you should prefer and why.
Situation 1
Say you are building a course recommender system. The idea is to recommend courses to students based on their profiles.
A student’s time is crucial; thus, you don’t want to waste their valuable time recommending courses that they may not like or are irrelevant to them.
What would you optimize? Precision or Recall?
Answer:
In my opinion, Precision is what you should prefer optimizing for. It is okay not to recommend good courses.
However, what your system recommends should be very high quality as students should not spend time watching courses that are irrelevant to them.
Situation 2
Next, assume that you want to shortlist candidates for a job opening and see if they should be selected for an interview. As your organization is looking for talented candidates, you don’t want to miss out on a candidate that can be a potential hire.
What would you optimize for now? Precision or Recall?
Answer:
Having inexperienced or irrelevant candidates won’t hurt as long as you catch all the relevant and talented ones.
Therefore, Recall is the metric you should optimize for. If you instead optimize for Precision, there is a possibility of excluding talented candidates, which is not desired.
Situation 3 (Courtesy: Cassie Kozyrkov)
Say you are a thief and you have broken into a house. You aim to rob money, jewelry, and everything else you think is “valuable.”
When robbing, are you in a Precision mindset or a Recall Mindset?
Post your answer in the responses!
Situation 4
We all have played Among Us, haven’t we?
If not, the aim is to identify the imposter within a group of players.
Would you play this game with a Precision Mindset or a Recall Mindset?
Let me know in the responses!
Conclusion
The choice between Precision and Recall can be highly subjective and it entirely depends on the application you are building — while considering what’s valuable to your business/personal use case.
Choose Precision if you want the results to be of high quality, and you accept missing out on some good items.
Choose Recall if you want all the good results, but at the same time, you don’t mind any misclassifications sitting as imposters in the good results.
Choose both (F-measure) if both are valuable to your business problem. Alternatively, choose from the other widely-used performance metrics or devise one for your own problem.
Thanks for reading!
✉️ Sign-up to my Email list to never miss another article on data science guides, tricks and tips, Machine Learning, SQL, Python, and more. Medium will deliver my next articles right to your inbox.

The Mindset Technique to Understand Precision and Recall Like Never Before was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/OE7AFN4
via RiYo Analytics








No comments