https://ift.tt/pQJ3bOT Stream Processing and Data Analysis with ksqlDB Extracting answers from data using the power of streaming ETL pipel...
Stream Processing and Data Analysis with ksqlDB
Extracting answers from data using the power of streaming ETL pipelines — a full tutorial using a real dataset

Introduction
Data Streaming is a hot topic in today’s data engineering world. If you are reading data-related posts on Medium or looking for a job on LinkedIn, it has probably crossed you somehow. It mainly appears in the form of job requisites like Kafka, Flink, Spark, or other complex tools geared toward Big Data applications.
These tools are used by major companies to empower their data processing capabilities. Recently, I’ve been experiencing the reality of IT in the Brazilian public sector, so I’ve been thinking not only about how data streaming can help companies but also society (directly).
As always, I think there is no better way to learn these tools and validate my ideas than trying a real (or almost that) project. In this post, we will explore the use of ksqlDB (a Kafka-related tool) to ease the data analysis of road accidents, using real data from the Brazillian Federal Highway Police (Polícia Rodoviária Federal, literal translation).
We’ll be building a data pipeline inspired by the Medallion Architecture to allow an incremental (and possibly real-time) analysis of accident data.
We aim to learn more about data streaming, Kafka, and ksqlDB.
I hope you enjoy it!
The problem
The Brazillian Federal Highway Police (PRF in short), as the name suggests, is our police responsible for guarding the highways. It yearly collects and releases data from traffic accidents (CC BY-ND 3.0 License), with information about the victims (age, gender, condition), weather conditions, hour and place, causes, and effects.
I got to know this dataset in an undergraduate course, and I think it is really useful to learn about ETL because it is simultaneously very rich in information and very problematic in formatting. It has a lot of missing values, inconsistent types, inconsistent columns, non-standardized values, typos, and so on.
Now, suppose that the government is trying to create better accident prevention policies but, for that, they need to answer the following questions:
- How many people are involved in accidents each month?
- What are the counts and percent of unhurt, lightly injured, strongly injured, and dead each month?
- What are the percentages of people involved in accidents of each gender in each month?
- The death rate of each accidents type
Unfortunately, they cannot wait until the release of the yearly report, so we need to set up an incremental report that communicates with their internal database and updates the results shown in the dashboards as soon as new accidents are added to the system.
However, the data inserted in the system is not necessarily perfect and may share the same problems as the released datasets, so we also need to clean and transform the records to make them useful in the final report.
And that’s where ksqlDB comes in.
Disclaimer: Besides using real data from the Brazilian government, the described situation is fictional, used to learn about ksqlDB in practice with a cool goal in mind.
Apache Kafka and ksqlDB
“Apache Kafka is an open-source distributed event streaming platform”, in short, a tool used to send and receive messages. In Kafka, we have a structure of topics, containing messages (literally just a string of bytes) written by a producer and read by a consumer.
It is one of the most important tools for data streaming, especially in the Big Data context, because it can easily handle millions of messages with high throughput. It is used by companies like Uber and Netflix to improve their data processing capabilities allowing, for example, real-time data analysis and machine learning.
“ksqlDB is a database purpose-built for stream processing applications on top of Apache Kafka”. Is a tool from the Kafka ecosystem that allows us to treat Kafka topics just like traditional tables from relational databases, and make SQL-like queries over them.
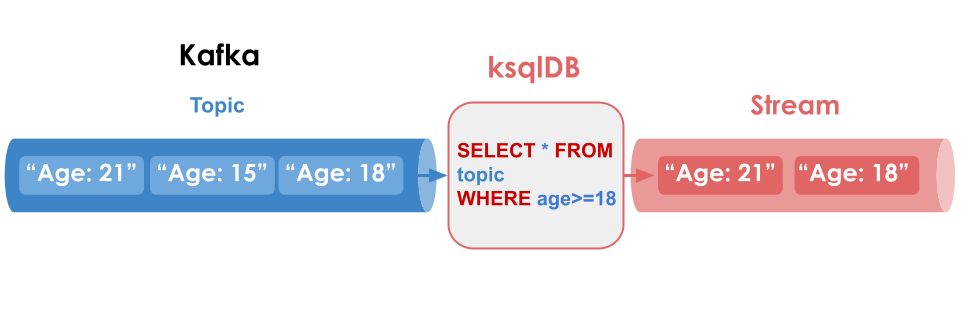
ksqlDB’s storage is based on two main structures — Streams and Tables. Streams are just like normal Kafka topics, immutable append-only collections, i.e. an ever-growing list of messages. Streams can be used to represent historical sequences of events, like transactions in a bank.
Tables, on the other hand, are mutable collections that represent the current state/snapshot of a group. For that, they use the concept of primary keys. When receiving messages, a table will only store the latest values for a given key.
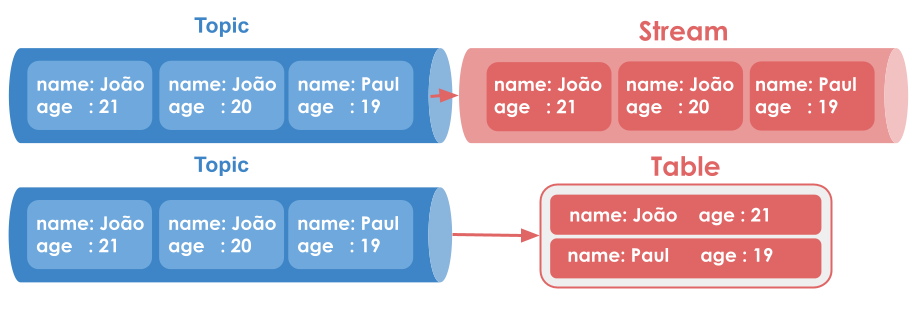
Besides their differences, STREAMS and TABLES are based on the same Kafka’s basic topic structure.
As mentioned before, ksqlDB is fully based on SQL and, unless you’re doing something very special, no programming language is needed. Because of this, if you already have experience with SQL, you can easily migrate from a usual relational environment to a streaming environment without much overhead.
It’s important to note that similar behavior can be achieved by the use of other tools, like Apache Spark or even with manually-coded consumers, but I think that ksqlDb has a simple and beginner-friendly interface.
ksqlDB is not Open Source, it is owned by Confluent Inc. (know more about its license here), but this tutorial can be completed with the free standalone version.
At the moment of writing, the author has no affiliation with Confluent Inc. (ksqlDB’s owner), and the opinions expressed here are mostly personal.
The implementation
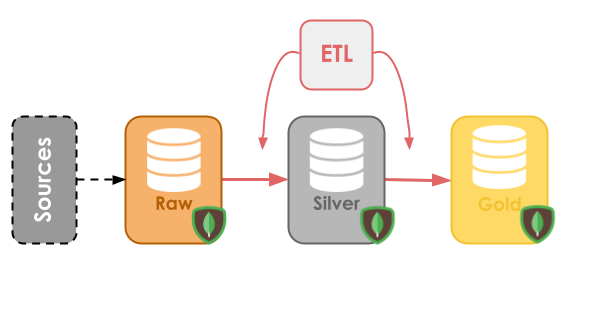
The main idea of this project is to use ksqlDB to create a streaming ETL pipeline. The pipeline will be based on the Medallion Architecture, which divides the data into gradually more refined states, categorized into bronze, silver, and gold.
In short, the bronze layer stores the raw data, the silver layer stores the cleaned data, and the gold layer stores the enriched and aggregated data. We’ll be using MongoDB for long-time storage.
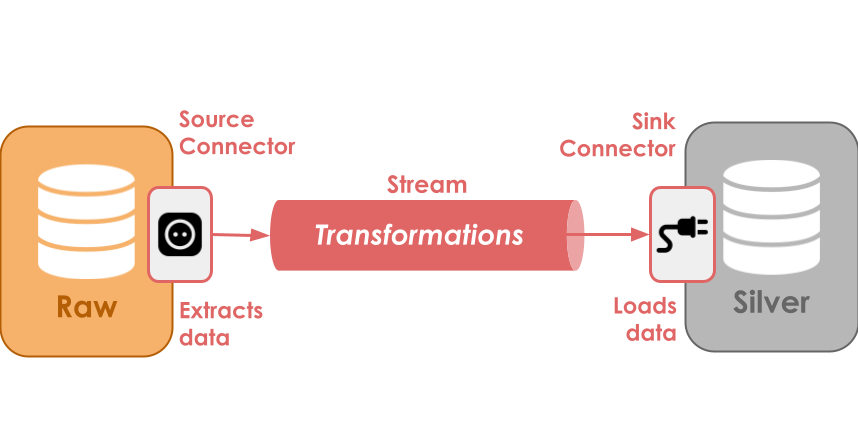
Besides streams and tables, we’ll also be using database connectors to move the data between layers. These connectors are responsible for moving records from a database (MongoDB in this case) to Kafka topics (in a process called Change Data Capture) and vice versa.
The original data used in this post can be originally found in CSV format at the link. Beforehand, I already transformed the data from 2015–2020 into a parquet file, to reduce its size and improve reading time, this file will be available at the GitHub repository.
Setting up the environment
This project environment is based on the docker files that can be found on this official ksqlDB tutorial.
What you need:
- Docker and Docker compose
- MongoDB sink and source connectors for Kafka — Debezium MongoDB CDC Source Connector and the MongoDB connector (sink).
- (Optional) Python 3.8+ with. Used to insert entries in MongoDB
The downloaded connectors must be put in the folder /plugins, in the same path as the docker-compose file.

Then, the containers can be started normally with docker-compose up.
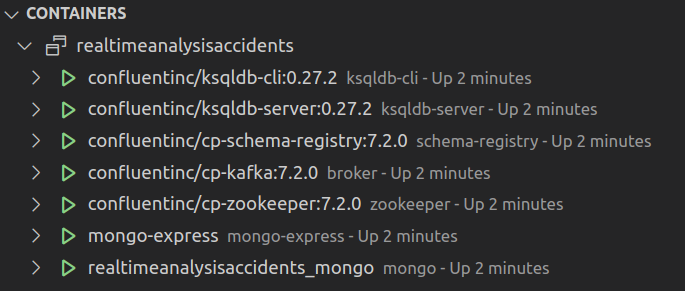
After that, connect to the MongoDB shell with the command mongo -u mongo -p mongo inside the container and start the database with rs.initiate().
If problems occur with the MongoDB connector during the execution, deeply orientation can be found at the tutorial link and in the references.
Bronze Layer — Extracting the raw data
The bronze layer stores the raw data extracted from the transactional environment, without any transformation or cleaning, just a ctrl+c ctrl+v process. In our case, this layer should extract information from the database where the accidents are originally registered.
For simplicity, we’ll create the records directly on the bronze layer.
This layer will be represented by a MongoDB collection named accidents_bronze inside the accidents database
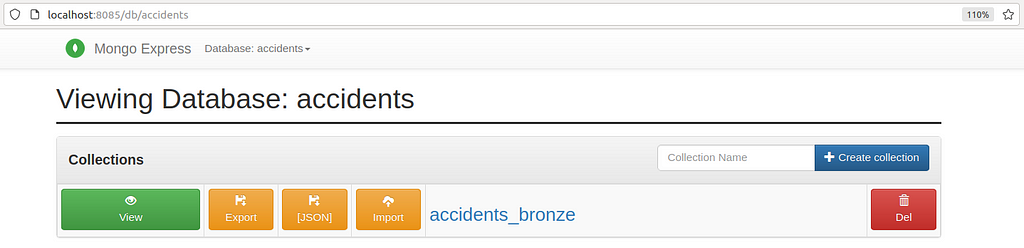
To move the records from MongoDB to ksqlDB, we need to configure a source connector. This connector is responsible for watching the collection and streaming every change detected (insertions, deletions, and updates) in the form of structured messages (in AVRO or JSON) to a Kafka topic.
To start, connect to the ksqlDB server instance via the ksqlDB-client using docker exec.
docker exec -it ksqldb-cli ksql http://ksqldb-server:8088
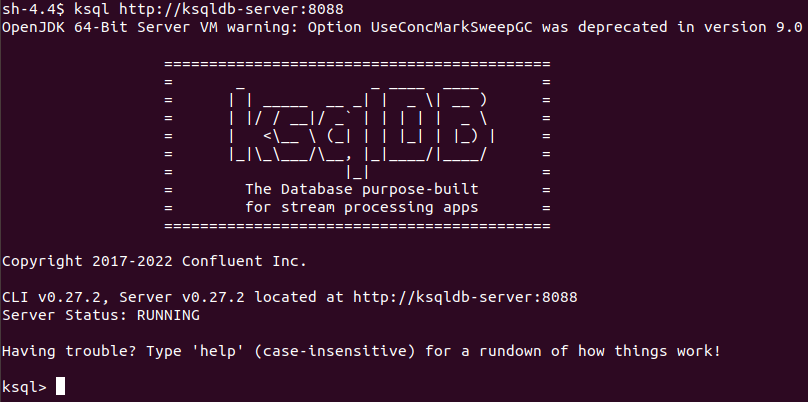
If everything goes well, you should see a big KSQLDB on your screen with a ‘RUNNING’ message. This is the ksqlDB client interface, from where we interact with the server to define our streams, tables, connectors, and queries.
Before continuing, we need to run the following command
SET 'auto.offset.reset' = 'earliest';
This ensures that all the defined queries will start from the earliest point in each topic.
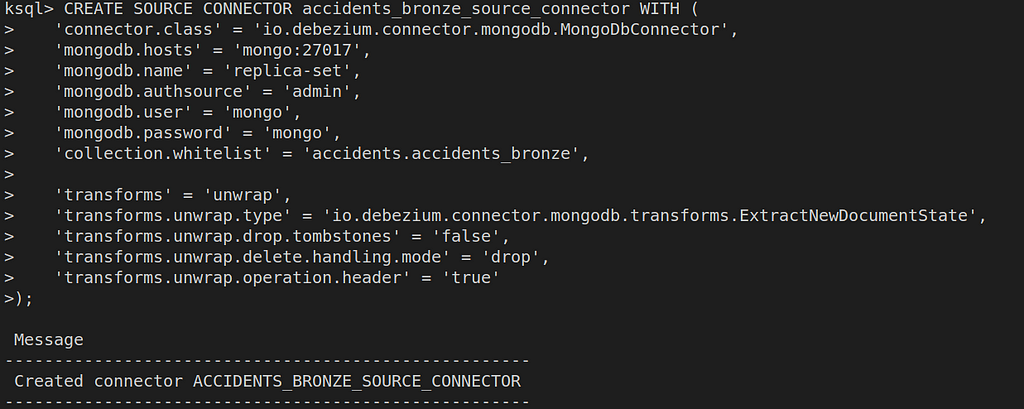
Then, creating a connector is just a matter of describing some configurations.
The command opens with the CREATE SOURCE CONNECTOR clause, followed by the connector name and configurations. The WITH clause specifies the configurations used.
First, the connector.class is defined. This is the connector itself, the Java class that implements its logic. We’ll be using the Debezium MongoDB connector, which was included in the plugins folder earlier.
Second, we pass the MongoDB address (host + name) and credentials (login + password).
Then, we define which collections in our database will be watched.
Finally, the transforms parameter specifies a simplification in the messages produced by the Debezium connector and the errors.tolerance defines the connector behavior for messages that produce errors (the default behavior is to halt the execution).
With the connector created, let’s execute a DESCRIBE CONNECTOR query to see its current status. Any errors that occur in its execution should be prompted here.
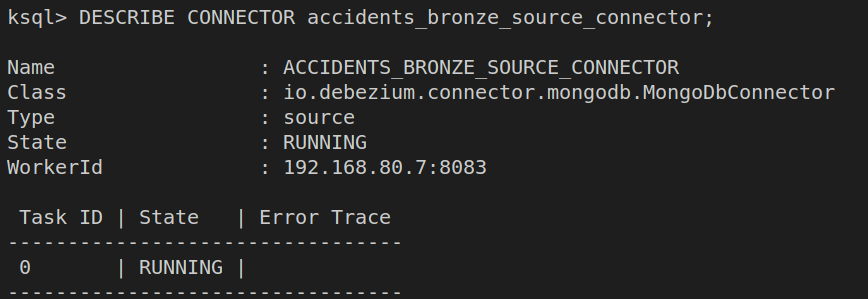
Now that our connector is running, it will start streaming all the changes in the accidents_bronze collection to the topic
replica-set.accidents.accidents_bronze.
ksqlDB is not able to process Kafka topics directly, so we need to define a STREAM using it.
Defining a STREAM in ksqlDB is almost equal to creating a table in SQL. You need to pass a name, a list of columns with their respective types, and some configurations in the WITH clause.
In our case, we need to configure which topic will feed our stream. Because of that, the column’s names and types should match the fields in the original topic messages.

See the command below.
You don’t need to include ALL the original fields like I did above.

Just a recap of what we’ve done so far:
1. We configured a MongoDB Source connector to stream the changes in the collection accidents_bronze in the form of structured messages
2. Using the automatically created replica-set.accidents.accidents_bronze topic, we defined a STREAM in ksqlDB called ACCIDENTS_BRONZE_STREAM to allow processing over its messages
Now, with the stream set up, it is possible to run SELECT queries over it, and that is where the true magic begins.
I took the liberty to insert some records in the mongoDB instance, so we have data to play with.
For example, let’s select the data and id of each message.
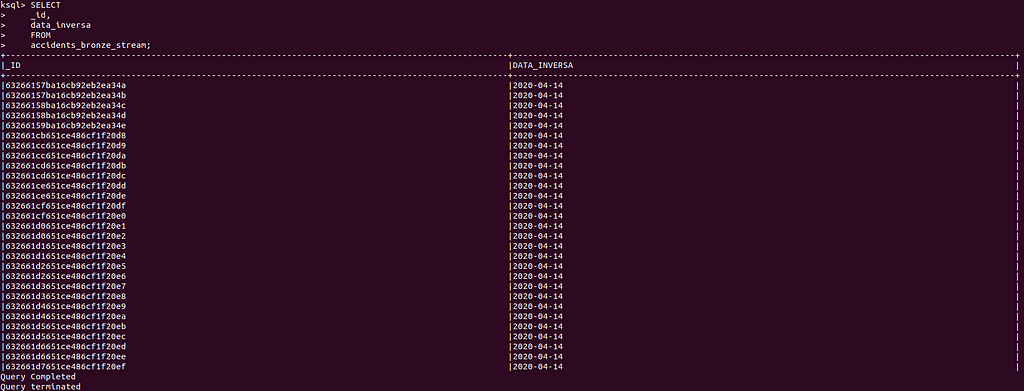
In ksqlDB, these normal SQL statements are called PULL QUERIES, because they return a response based on the stream's current state and finishes.
By adding EMIT CHANGES at the end of a PULL QUERY it is turned into a PUSH QUERIES. Unlike its counterpart, it never finishes, and it is always computing new rows based on the arriving messages. Let’s see this working.
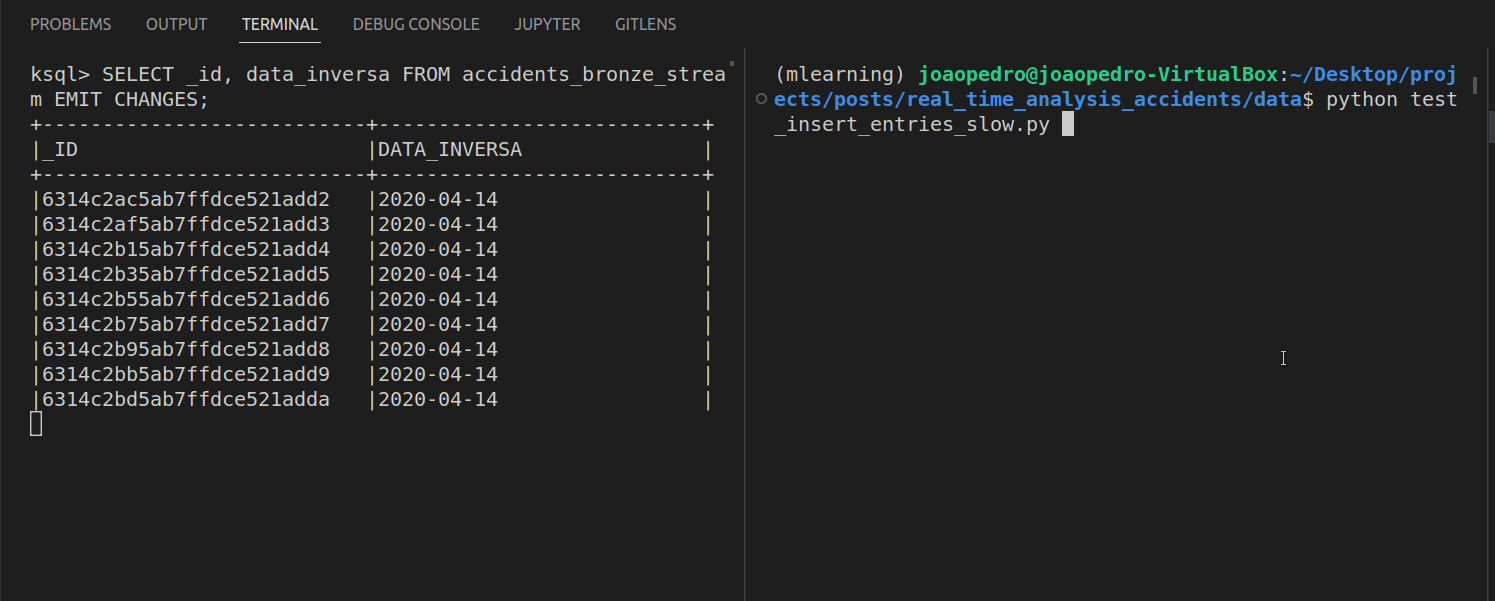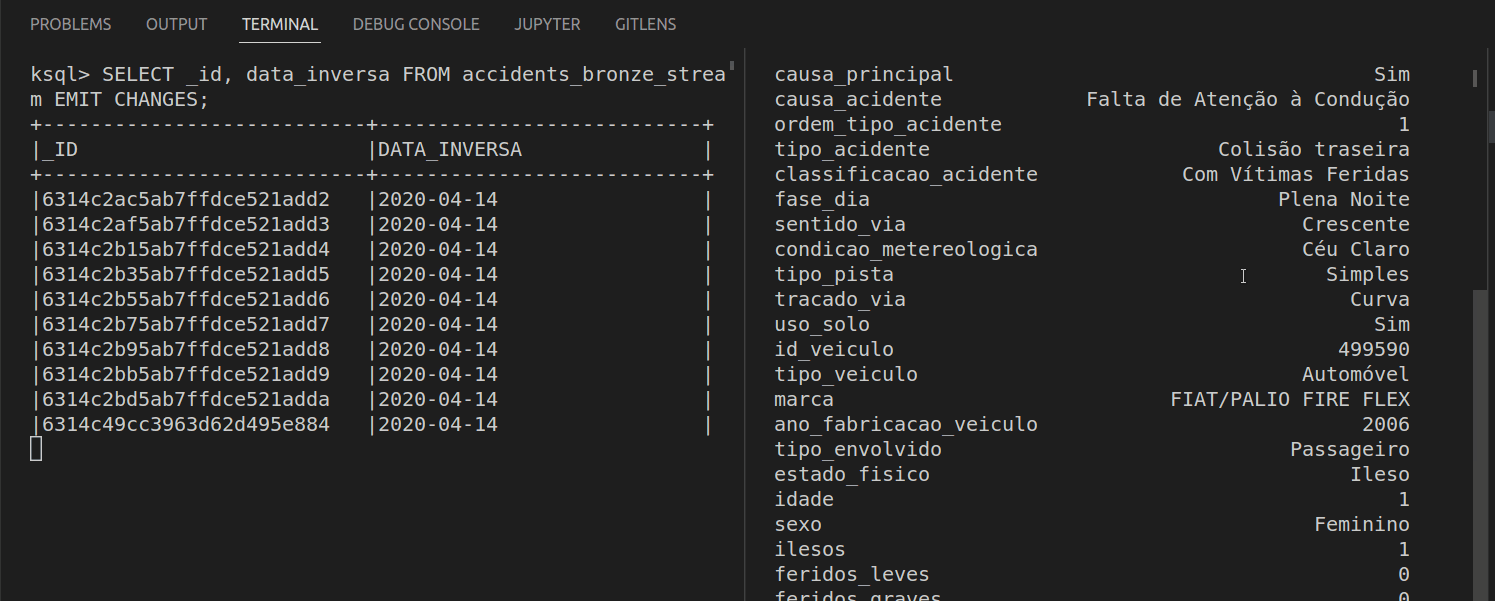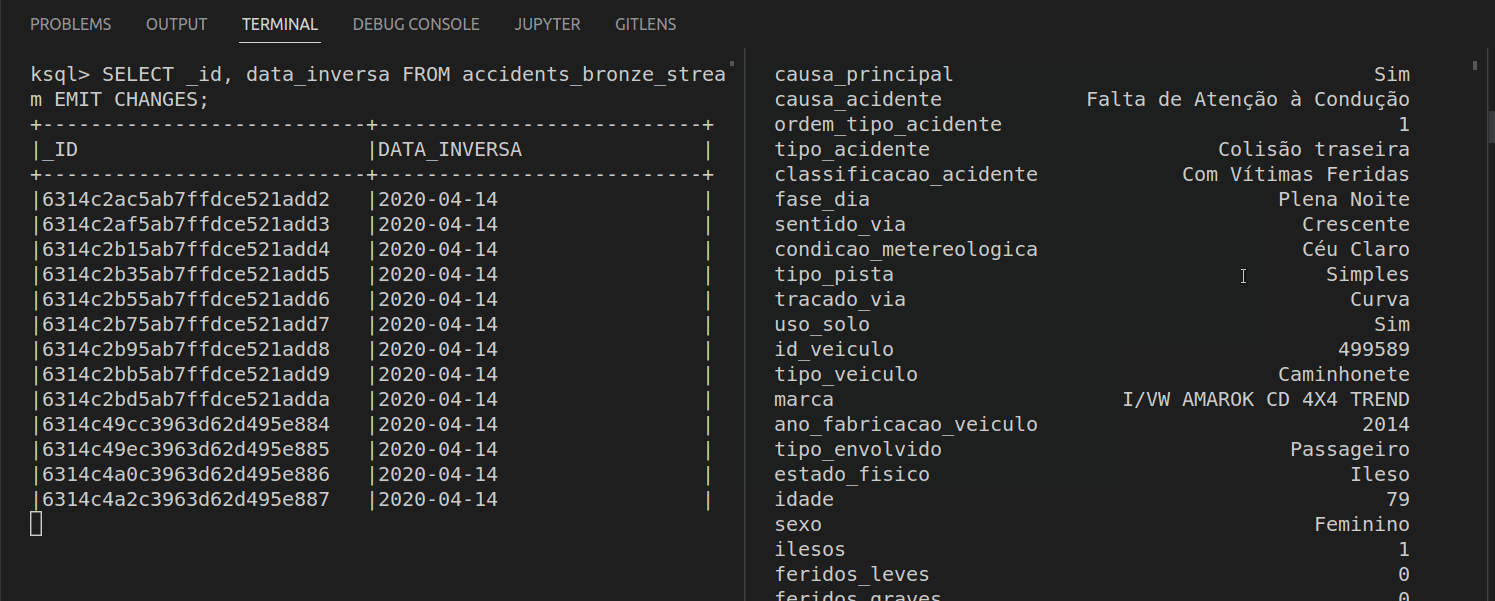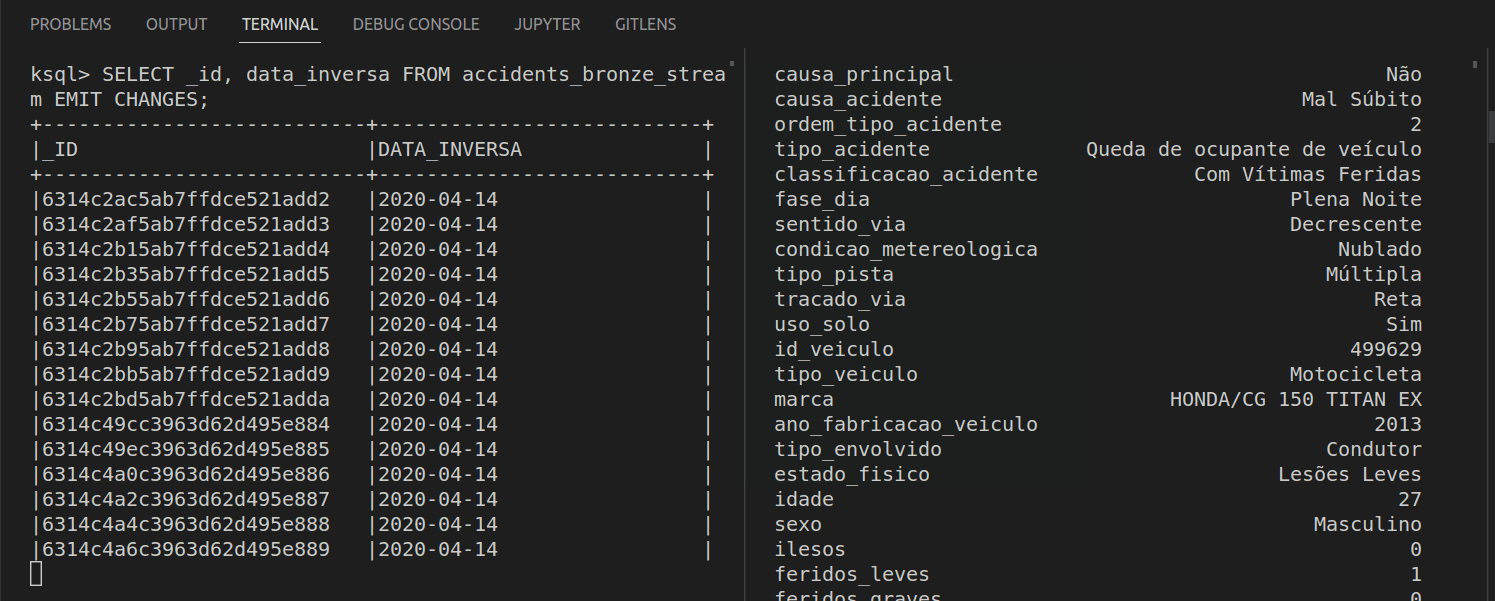
On the left, we have the PUSH QUERY and on the right, a simple python script inserting records in MongoDB. As new records are inserted, they automatically pop up in the query’s answer.
Push and Pull queries will be our building blocks to create all the transformations needed in the following sections.
Silver Layer — Cleaning the data
The Silver Layer’s objective is to store cleansed data that can be easily consumed by other applications, like machine learning projects, and the gold layer.
This layer will be represented by a MongoDB collection named accidents_silver inside the accidents database.
Our main concern is to guarantee that the data is correctly formatted, so downstream tasks can focus on solving their specific business rules.
To achieve this, we need to process the arriving messages in the bronze stream and store them inside the accidents_silver collection. This process can be split into two steps: ‘create a stream to clean the messages’ and ‘create a sink connector to save the messages in accidents_silver’
Now the true power of ksqlDB is explored — Stream processing.
It’s possible to define a stream using a query made over other streams. The new stream will be populated with the query result.
Let’s see this working.
For example, if we want a new STREAM containing only the _id and date where it is not null, we could make this:
Using this functionality, it’s possible to create a transformation (bronze_to_silver) STREAM that is responsible for selecting and cleaning the messages from the bronze stream.

Our example needs to clean the fields: sexo (gender), tipo_acidente (accident type), ilesos (unhurt), feridos_leves (lightly injured), feridos_graves (strongly_injured), mortos (dead), and data_inversa (date).
After looking into the database (I’ve made this offscreen), it is possible to note the following problems:
- The gender column contains multiple values representing the same gender: male could be either ‘masculino’ or ‘m’, and female could be either ‘feminino’ or ‘f’.
- The accident type also contains multiple values for the ‘same type’.
- The date could be formatted in one of the following ways: 2019–12–20, 20/12/2019 or 20/12/19
- Missing values are encoded as NULL, the string ‘NULL’ or the string ‘(null)’
Besides these transformations, I gonna also (try to) translate the fields and values to ease comprehension.
The fix to these problems are implemented in the accidents_bronze_to_silver STREAM defined below:
I’ll not explain deeply the SQL command above, what matters is the idea of what is possible to do with ksqlDB.
We’re able to build a powerful transformation process over a stream of messages with (almost) only SQL knowledge!
Let’s see this working below.
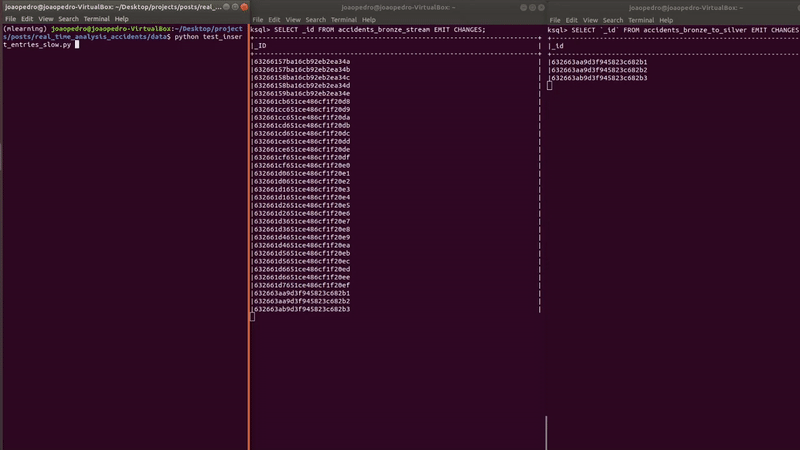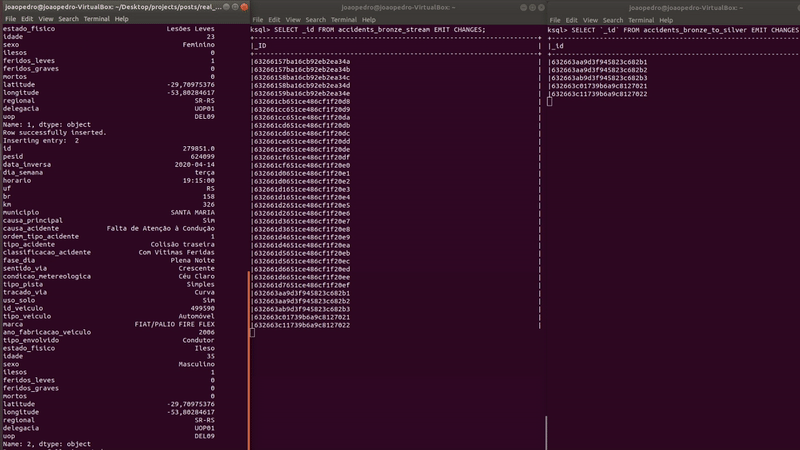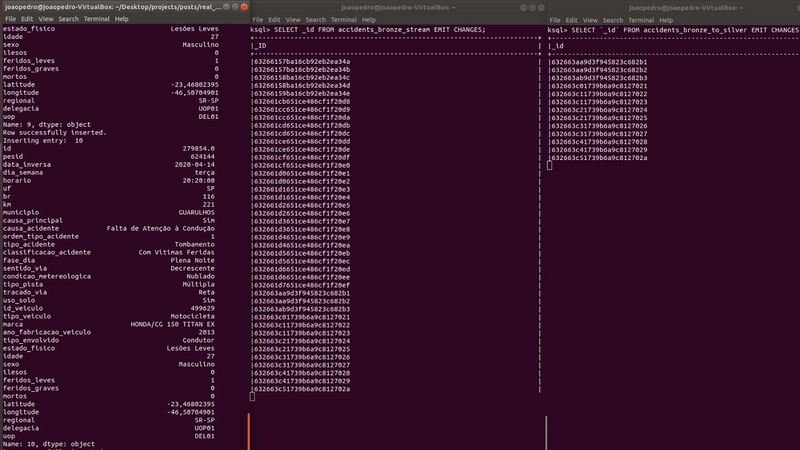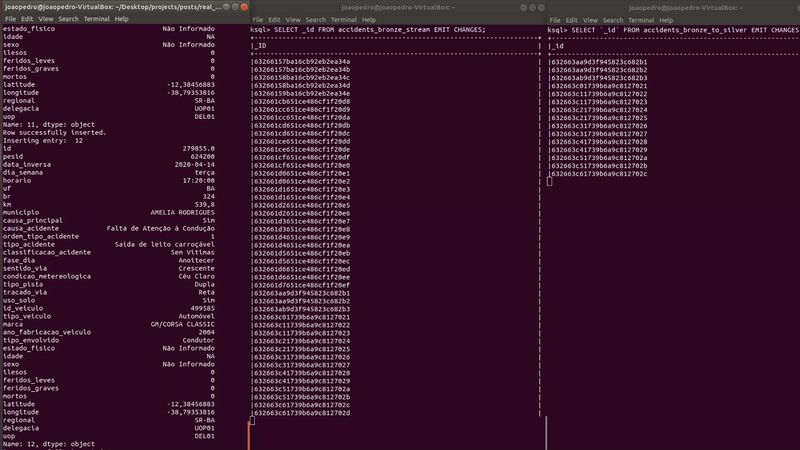
The final step is to save the data in MongoDB using a Sink Connector.
For the connector above, the Kafka MongoDB connector is used, and the rest of the configurations are self-explanatory.
The accidents_silver is automatically created, and the results can be seen below.
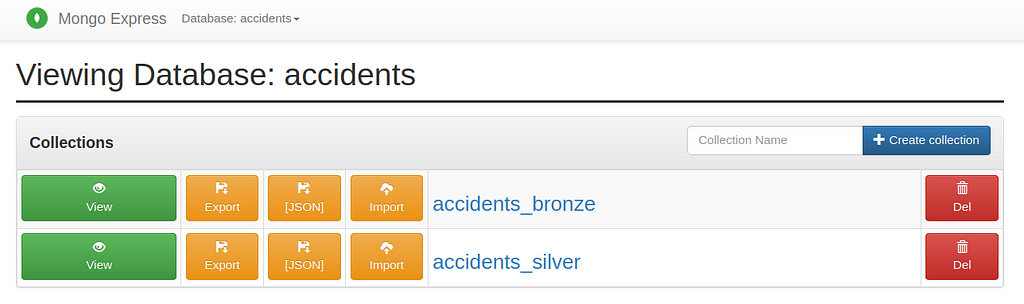
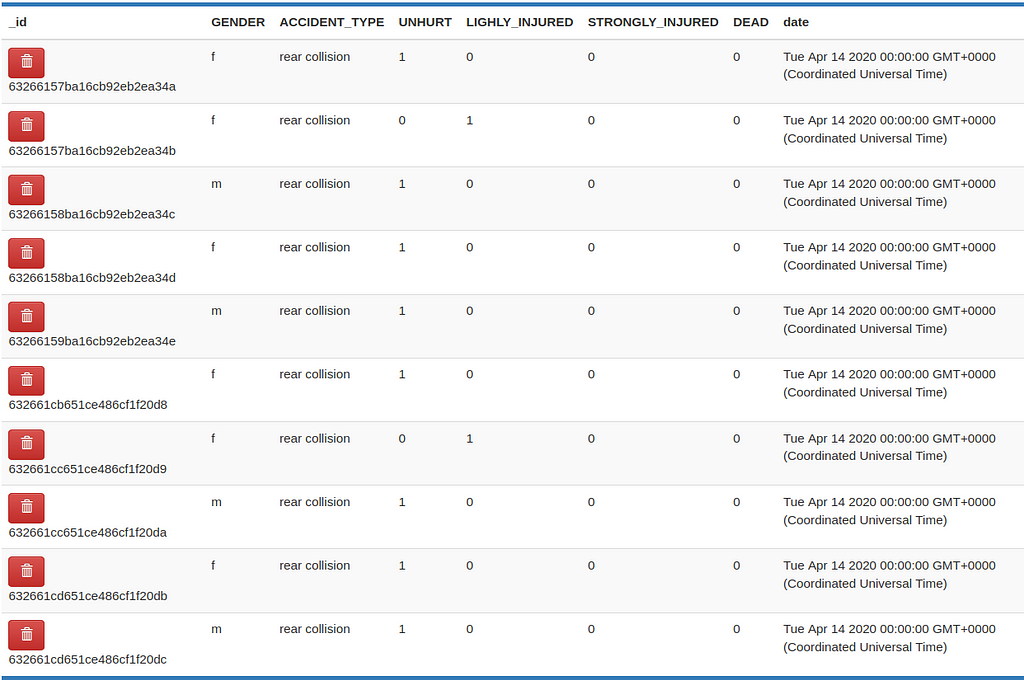
Now that we have clean accident data, it’s time to finally answer our questions.
Gold Layer — Business Rules and Aggregations
The gold layer contains business-specific rules, focusing on solving the problems of a specific project.
In our project, two ‘Gold Layers’ will be defined, one focusing on answering the monthly-aggregated questions, and another answering the death rates of each accident, each stored in a separate collection.
From an architectural perspective, this step brings no novelty. It’s just like the previous step, where we consume data from a stream, transformed it to our needs, and saved the results in the database.
What makes this step different are the aggregations needed.
To answer our questions, we do not need to store every single accident, only the current count of deaths and injuries accidents for each month (example). So, instead of using STREAMS, we’ll be using TABLES.
Luckily, in terms of syntax, there is not much difference between table and stream definitions.
As mentioned before, tables have a primary key. For these examples, we don’t need to explicitly define the keys, because ksqlDB creates them automatically with the columns used in GROUP BY.
In ksqlDB, aggregations can only be made in PUSH QUERIES, so ‘EMIT CHANGES’ is needed on the query’s end.
Let’s start with the monthly aggregated table.
And see the table in action…
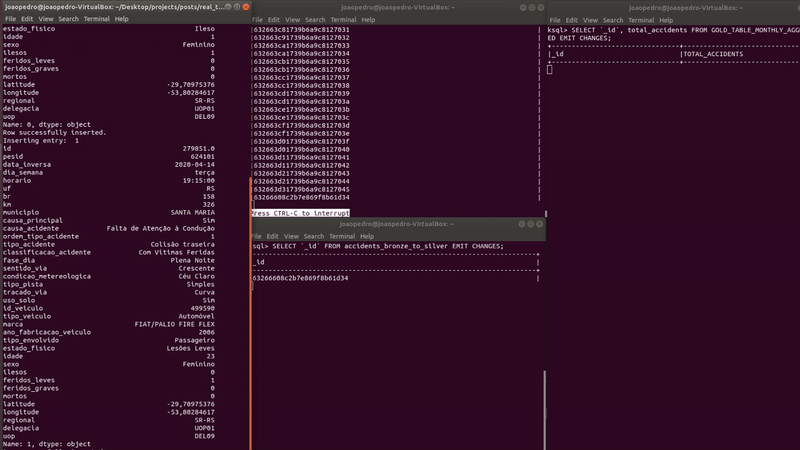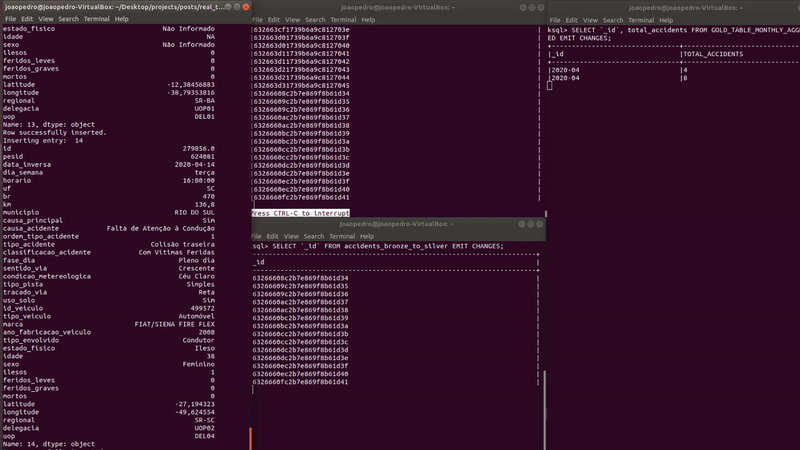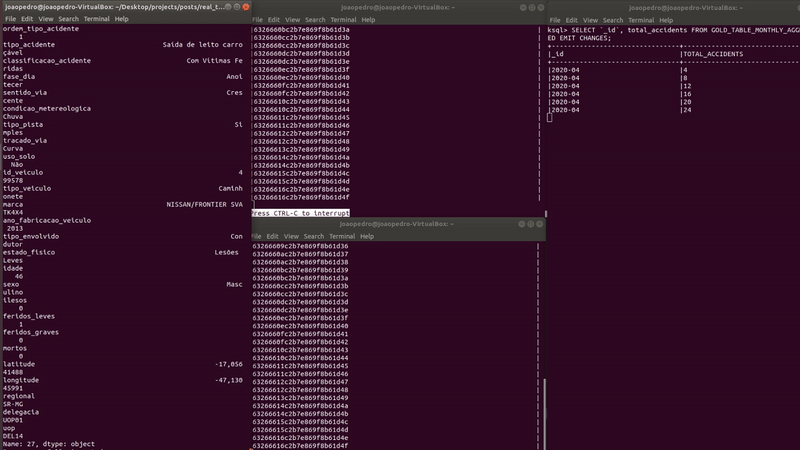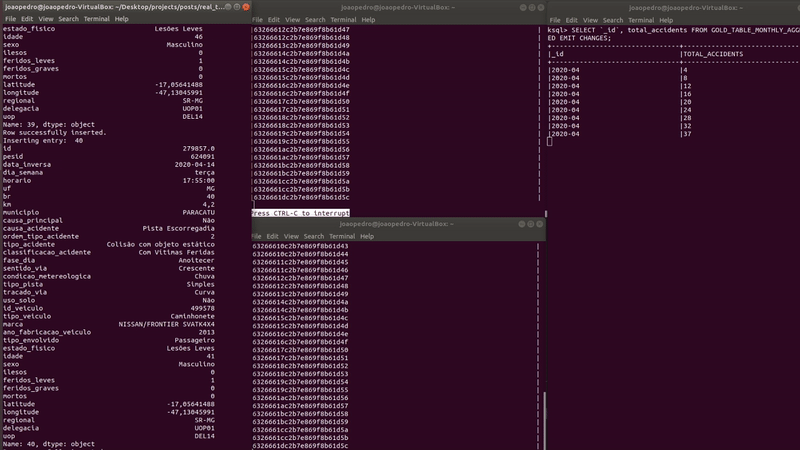
As new records are inserted, the table (on the right) automatically updates the counts of each month. Let’s see the results closely.
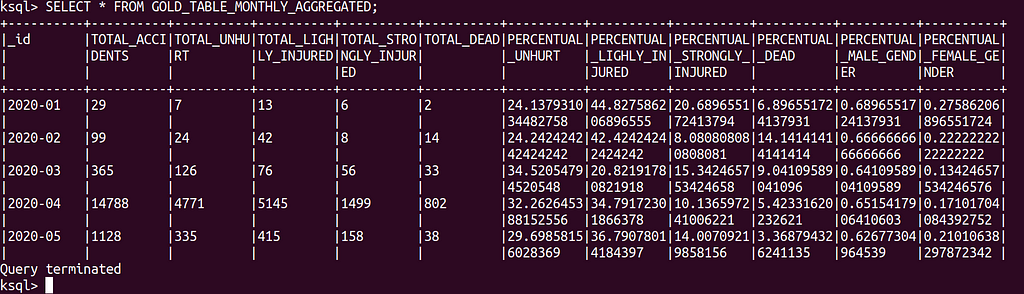
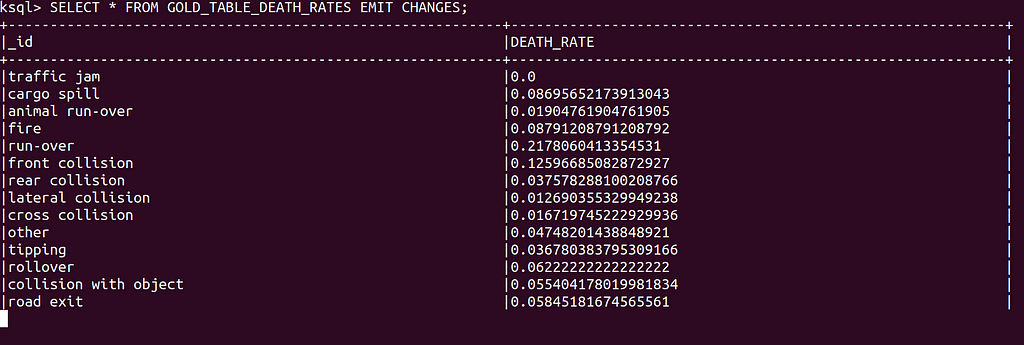
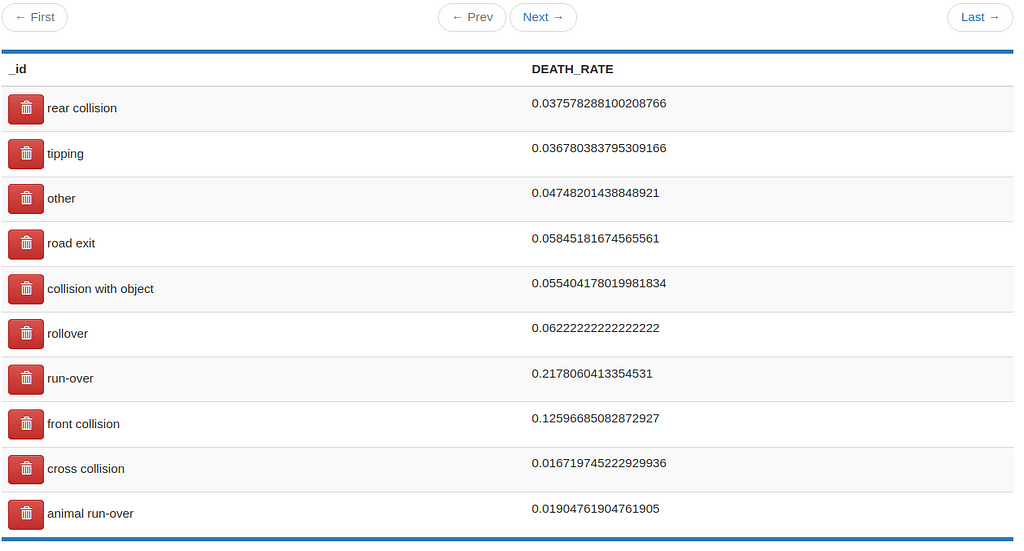
The same logic goes for the death rate table, where we calculate the probability of dying in each type of accident.
Again, see the table in action…
Finally, all that rest is to save each table in their respective MongoDB collection.
This sink connector has some different configurations (transforms and document.id.strategy) used to create an _id field in MongoDB matching the table’s primary key.
And the results should start showing up in the collections.
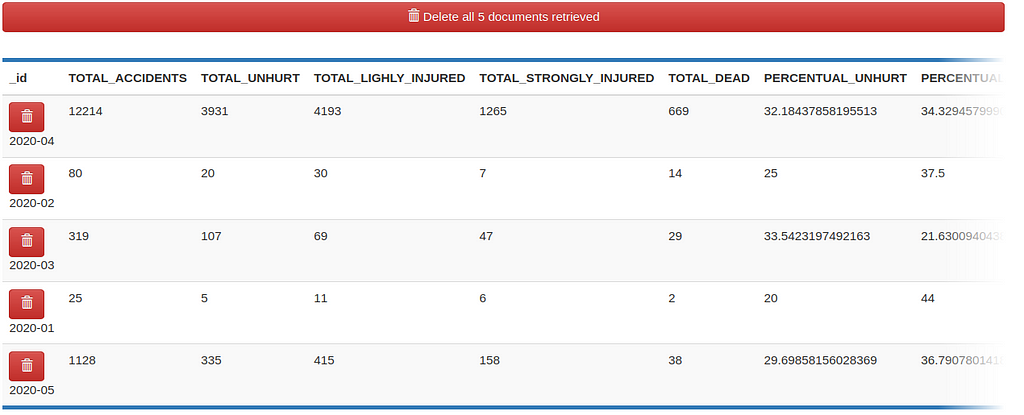
Conclusion
Stream processing is already a reality in many companies, especially among the big players. Among the technologies used, Apache Kafka is a leading solution to stream messages between applications and databases, with a huge ecosystem of assistant tools to handle intensive data-related jobs. ksqlDB is one of these.
In this post, we learned about ksqlDB with a hands-on project using a real dataset.
In my projects, I always try to mix the tools and concepts explored with interesting topics from reality. Because of this, I choose a real dataset from the Brazilian Open Gov. Data with data from road accidents.
To allow incremental (and possibly real-time) data analysis, I proposed using a Medallion Architecture to transform the raw unformatted data into the questions’ answers. The main purpose of this architecture was to allow exploring different concepts of ksqlDB.
We’ve learned about ksqlSB main storage units (streams and tables), push and pull queries, and most importantly, how this tool can help us solve a (real?) data engineering problem.
As always, I’m not an expert on any of the discussed topics, and I strongly suggest further reading, see the references below.
Thank you for reading ;)
References
All the code is available in this GitHub repository.
[1] Medallion Architecture — Databricks Glossary
[2] What is the medallion lakehouse architecture? — Microsoft Learn
[3] Streaming ETL pipeline — ksqlDB official documentation
[4] Streams and Tables — Confluent ksqlDB tutorial
[5] Featuring Apache Kafka in the Netflix Studio and Finance World — Confluent blog
[6] MongoDB Kafka Sink connector — Official Mongo Docs
[7] MongoDB source and sink connector — Confluent Hub
[8] Sink Connector Post Processors, configure document id in sink connector — Official Mongo Docs
[9] Presto® on Apache Kafka® At Uber Scale — Uber Blog
All images in this post are made by the author unless otherwise specified.
Stream processing and data analysis with ksqlDB was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/HVvB53g
via RiYo Analytics







ليست هناك تعليقات