https://ift.tt/N0pPt6a An Extensive Introduction to Autoencoders A theoretical and practical introduction to image embedding and autoencod...
An Extensive Introduction to Autoencoders
A theoretical and practical introduction to image embedding and autoencoders.

They say an image says more than a thousand words. Just look at the image above and imagine the story it tells us about its leaves, their colors, and the life they have lived. It would be intriguing to let a computer tell some of these stories for us, but can a computer tell us that there are leaves in the image? Their colors? or that fall is coming? These are easy things for humans as we only need to look at the image. But it is more challenging for computers as all they see are numbers, which would be difficult to understand for humans as well.
The good thing is that we can help the computer understand. A computer can change the image into something easier for it to understand. It can change the image into variables that tell it about the texture, color, and form of the objects in the image. With these, the computer can begin to tell us stories about what is in the image. In order to tell these stories, the image must first be embedded into a computer and afterward transformed into variables using autoencoders.
This book aims to give a theoretical and practical introduction to image embedding, autoencoders, and techniques used by different applications. The book starts with the basics and builds towards modern autoencoders, all supported with examples and code to make it easier to understand.
The series comprises six chapters, each presented in the sections below. Follow me to receive an e-mail when I publish a new chapter or post.
- Introduction to Embedding, Clustering, and Similarity
- Introduction to Autoencoders
- Extend the concept of Autoencoders
- Practical: Face-detection with Autoencoders
- Adapt Autoencoders to Similarity
- Practical: Product recommendation with Autoencoders
Chapter 1: Introduction to Embedding, Clustering, and Similarity
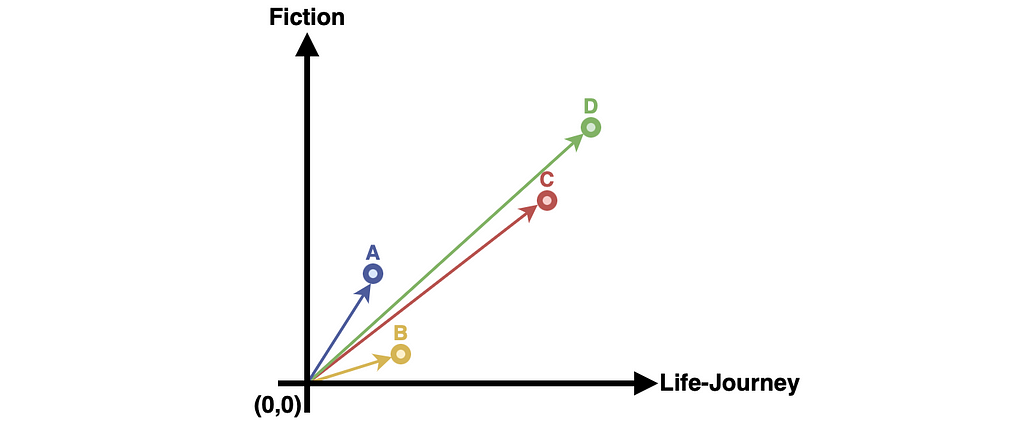
Chapter 1 explains what embedding is and how it can be used to represent the real world in variables. Each variable is a question as it asks the world for knowledge; the challenge is asking the right questions. Asking the right questions can influence how easy the computer can understand the variables and whether we can use the variables successfully in an application.
It is hard for the computer to understand embedded images, which is why we won’t look at them just yet. We will instead look at simpler representations of these and how these can be embedded using the right questions. The goal is to understand the underlying mechanisms of embedding before using the more modern approach of autoencoders.
Chapter 2: Introduction to Autoencoders
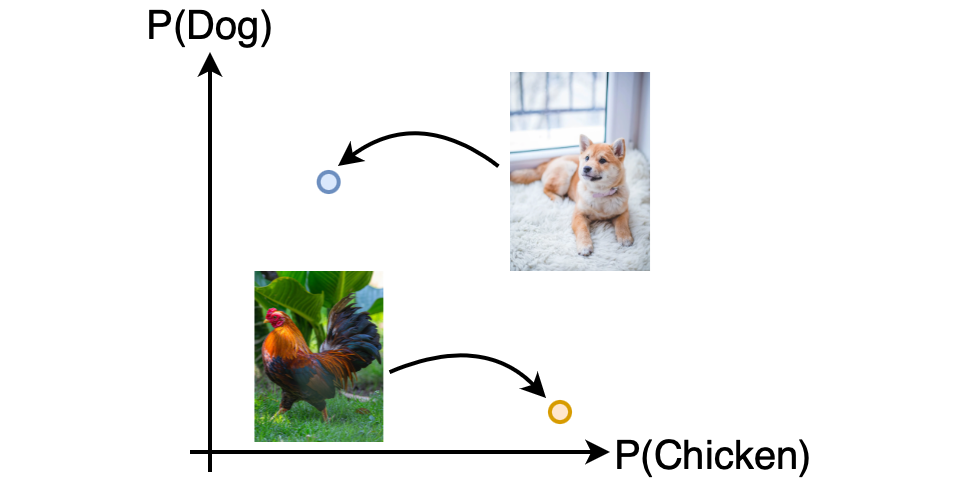
It is now time to take a closer look at images and autoencoders. Chapter 2 first looks at how to represent images with variables so we can use those variables to look for similarities and clusters, using the methods learned in chapter 1. When used directly, an image is hard to analyze, which is why chapter 2 ends with how to use autoencoder to transform the image into something more manageable for the computer to understand.
Using the methods from chapter 1 on images is challenging since the same colors do not necessarily result in the same object; A dog and a chicken can both be brown but are not the same. Transformation can lessen these challenges using standard autoencoders such as Principle Component Analysis¹ (PCA), Linear Discriminant Analysis² (LDA), and neural network classifiers³. PCA and LDA help us visualize the images in 2D but do little to make the images easier to understand. Neural Network Classifiers on the other hand significantly contribute to how well a computer can understand an image.
Neural Network Classifiers are imperfect and have their own challenges when used in practice. Simple adjustments are made to the Neural Networks to address these challenges. No adjustments come without consequences; At the end of chapter 2 the trade-offs and when to use what, are discussed.
Chapter 3: Extend the concept of Autoencoders
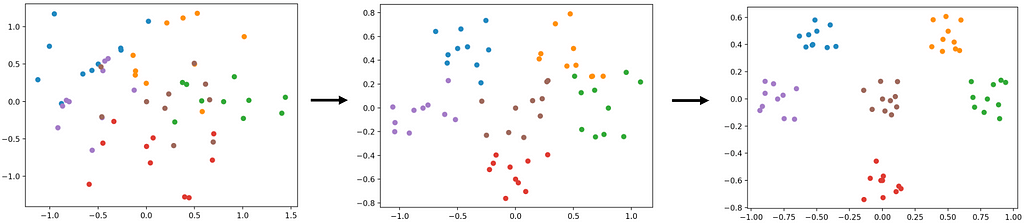
Chapter 3 explains how to make improved autoencoders for better differentiation between new animals.
Some of the challenges mentioned in chapter 2 are caused by how Neural Network Classifiers, are trained to learn the differences between a defined set of classes (e.g., animals). After learning the differences, we can lessen these challenges by asking how the neural network came to its conclusions. It might base the decision on features such as the animal’s color, fur, leg position, teeth, etc. The idea behind autoencoders is to use these features to disguise between new animals that are introduced in the future.
But why must we learn to recognize animals before asking what features are used? Why not just learn the best features to separate them from the get-go? Chapter 3 introduces modern approaches incorporating these ideas to more efficiently separate similar but different instances such as human faces.
Chapter 4: Practical: Face-detection with Autoencoders

It is now time to use our newfound knowledge in practice. The first practical case is where we build a system to identify which one of your friends is in an image. We will see how the autoencoder that focuses on classification can create a scalable system where you can easily add new friends and won’t need to worry about recognizing strangers as your friends.
Chapter 5: Adapt Autoencoders to similarity
Autoencoders focus on making a clear separation between classes, making it easier to determine which class an image belongs to. The problem is that these are ineffective when it comes to finding similarities. Similar images from the same class are closer, but similar images across classes are down-prioritized as the autoencoder tries to separate each one.
Chapter 4 looks into autoencoders that focus on the similarity between images rather than the distinction between classes. The similarity between images is a challenging task where social data and newer methods, such as Generative Adversarial Networks⁵, must be used.
Chapter 6: Practical: Product Recommendation with Autoencoders

The second practical case is where users can upload images of products they like and want to use as inspiration to find their next piece of furniture. The system will look for similar products and recommend them to the user. We will see how the autoencoders that focus on similarity can create a scalable system where you can easily add new products.
References
[1] Casey Cheng, Principal Component Analysis (PCA) Explained Visually with Zero Math (2022), Towardsdatascience.com
[2] YANG Xiaozhou, Linear Discriminant Analysis, Explained (2020), Towardsdatascience.com
[3] Victor Zhou, Machine Learning for Beginners: An Introduction to Neural Networks (2019), Towardsdatascience.com
[4] G. Huang, et al. Labeled faces in the wild: A database for studying face recognition in unconstrained environments (2007), http://vis-www.cs.umass.edu/lfw/
[5] Jason Brownlee, A Gentle Introduction to Generative Adversarial Networks (GANs) (2019), machinelearningmastery.com
All images and code, unless otherwise noted are by the author.
Thank you for reading this book about Autoencoders! We learn best when sharing our thoughts, so please share a comment, whether it is a question, new insight, or maybe a disagreement. Any suggestions and improvements are greatly appreciated!
If you enjoyed this book and are interested in new insights into machine learning and data science, sign up for a Medium Membership for full access to my content. Follow me to receive an e-mail when I publish a new chapter or post.
Into Image Embedding and Autoencoders was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/dyGPFHb
via RiYo Analytics







ليست هناك تعليقات