https://ift.tt/RQAbmLS An introduction and a case study Image by Evan Dennis As explained in my previous post , the framework of SHAP v...
An introduction and a case study

As explained in my previous post, the framework of SHAP values, widely used for machine learning explainability has unfortunately failed to reflect the casual structure in its results. Researchers have been proposing possible solutions to remove such a limitation. In the article, I will be reviewing one of the proposed alternatives, the Causal SHAP values (CSVs), and give a simple example with detailed computation to illustrate the difference between CSVs and the “traditional” SHAP values.
Traditional SHAP values and its limitation
Let us start by recalling the definition of SHAP values, a method based on cooperative game theory, aiming to interpret a machine learning model, attributing feature importance as the payoff that a feature has contributed to the final output. For a given model f, the SHAP value of a feature x_j with j∈{1,2,…n}:=N in consideration is given by
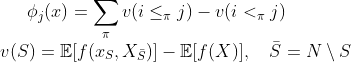
where π is a permutation of N which is chosen to be a uniform distribution and the symbol <π and ≤π represent the indices that precede and precede or equal to a given index in the permutation.
We can notice immediately that the above computation is based on a marginal expectation, which, explains why SHAP values cannot reflect the causal relation of the model.
CSVs: a possible improvement of SHAP
Definition of CSVs
Consider a very simple case where feature 1 is the direct cause of feature 2 and we would like to argue that we cannot give the two features the same weight when evaluating their contributions to the output of the model. By intuition, the cause should be considered more important than the effect when attributing feature importance. Such intuition leads to the causal SHAP values (CSVs) framework, proposed by Heskes et al., aiming to modify the current SHAP values framework without breaking its desirable properties, i.e. efficiency, symmetry, dummy, and additivity.
The CSVs has the following definition:
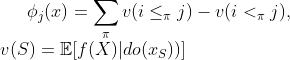
and we notice immediately the difference from the former definition (up to a constant according to authors’ preference): the marginal expectation is replaced by an interventional expectation realized by Pearl’s do-calculus. For those who are not familiar with the concept, simply note that the do(.) is a mathematical operator that allows us to conduct interventions in a casual model, usually represented by a directed acyclic graph (DAG) and this “do” can be understood literally as “do it”. Based on the definition of the CSVs, let us look back at the example above: doing feature 1, the value of feature 2 is no longer free and the cause-and-effect would be taken into account by the interventional expectation.
Difference from SHAP
Omitting details of computation, we would like to mention that the CSVs of a feature x_i can be decomposed into two parts: the direct contribution and the indirect contribution. The direct contribution is the change in prediction when the feature variable X_i takes the value of the feature x_i while the indirect contribution is the change due to the intervention do(X_i=x_i). In this sense, the difference between CSVs from traditional is this additional information of indirect contribution.
The following plot gives the SHAP values and CSVs in a bike rental model: taking the cos value of the time of the year and temperature as input, the model predicts the bike rent counts. We can see that the cos_year value is attributed to more importance by CSVs in considering the effect of the time of a year on the temperature.

To end this section, let us resume that the Casual SHAP values can be regarded as a generalization of the current SHAP values by replacing the marginal expectation of the model with the interventional expectation so that the indirect contribution of a feature is taken into account along with its direct contribution.
A concrete example of CSVs
Let us illustrate how CSVs works by considering the following simple model with only three variables:
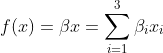
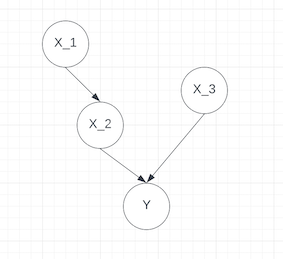
Let us suppose that the variables follow the casual model given by the following DAG in which we suppose that x_1 is the parent of x_2 and x_3 is independent of the two others.
Moreover, we suppose that:
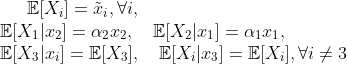
First of all, it is easy to get the SHAP values of all features:
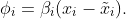
Let us move to CSVs now. Take the first feature as an example. According to the definition, a CSVs is given as the sum of the interventional expectation all of permutations of {1,2,3}. As an example, we will compute Φ_1(1,2,3). Plugging the linear function into the definition of Φ, we get:
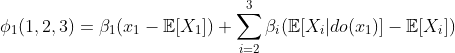
According to the casual model, we have the fact that E[X_2|do(x_1)]=α_1x_1 while E[X_3|do(x_1)]=E[X_3] and this leads to:
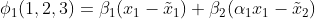
Similar computation gives the CSVs of all three features:
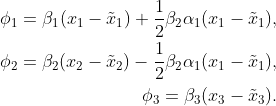
We observe from the results that CSVs end up with different feature attributions when the model has a certain casual structure. Since X_1 is the parent node of X_2 in the DAG plot shown above, there is one more term added to the SHAP value of x_1 as its indirect effect while we remove a term from that of x_2 as it is caused by x_1 instead of by x_2 itself.
Limitations of CSVs
We would like to say in the end that if it is too early to replace SHAP with CSVs. Despite the smart design, CSVs’ limitation is obvious as well. In general, we, data scientists are excited about SHAP for its ability to interpret any black box model whose casual structure would be hard to obtain in practice and we would never have a good estimation of the do-calculus with the absence of such information. However, it would still help to get a better understanding of the model even if only a part of the casual information is available.
Casual SHAP values: A possible improvement of SHAP values was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/h5l87vT
via RiYo Analytics

No comments