https://ift.tt/KgbULHD How to use SageMaker’s built-in algorithm TabTransformer with your own data Image by author (created with OpenAI’s...
How to use SageMaker’s built-in algorithm TabTransformer with your own data

What is this about?
In June 2022 AWS announced a new range of built-in algorithms for Tabular Data. Since I’ve been working with Transformers in the NLP space for a while now, I was, of course, curious about the TabTransformer algorithm.
The premise of the TabTransformer is promising: Categorical values in a feature can mean different things, depending on the context. Just like the word “bank” can mean different things in a sentence depending on the context (“river bank” vs “Bank of England”), TabTransformer use that information in tabular data and represent the same value with differently, if the context is different. You can read more about it in this paper.
In this tutorial we will use the new built-in algorithm to leverage this new capability by bringing our own data. The code of this tutorial is encapsulated in Python script rather than notebooks, so that we can run the whole workflow from the comfort of our local IDE.
The code for this tutorial can be found in this Github repo.
Why is this important?
TabTransformer uses the concept of contextual embeddings of Natural Language Processing (NLP) and expands it to tabular data, which potentially could lead to a better understanding of the data and might eventually lead to better results than traditional classification models.
But the reason why this is a big deal is that the vast majority of ML projects are still classification or regression problems and deal with tabular data. Therefore any improvements we can achieve with new architectures have an outsized impact just because of the sheer numbers of tabular data projects out there.
Plan of attack
The AWS documentation provides sample code on how to use TabTransformer but this code uses a standard data set that has already been prepared accordingly. However, in this tutorial we want to bring our own data set so that we understand how to set up the entire ML workflow end-to-end.
We will prepare the data and upload it to an S3 bucket where it can be accessed by SageMaker (SM). We will then kick off an SM Training Job to train the TabTransformer model and deploy it to an SM Endpoint. Once we have done that we can test the model performance with a holdout test set.
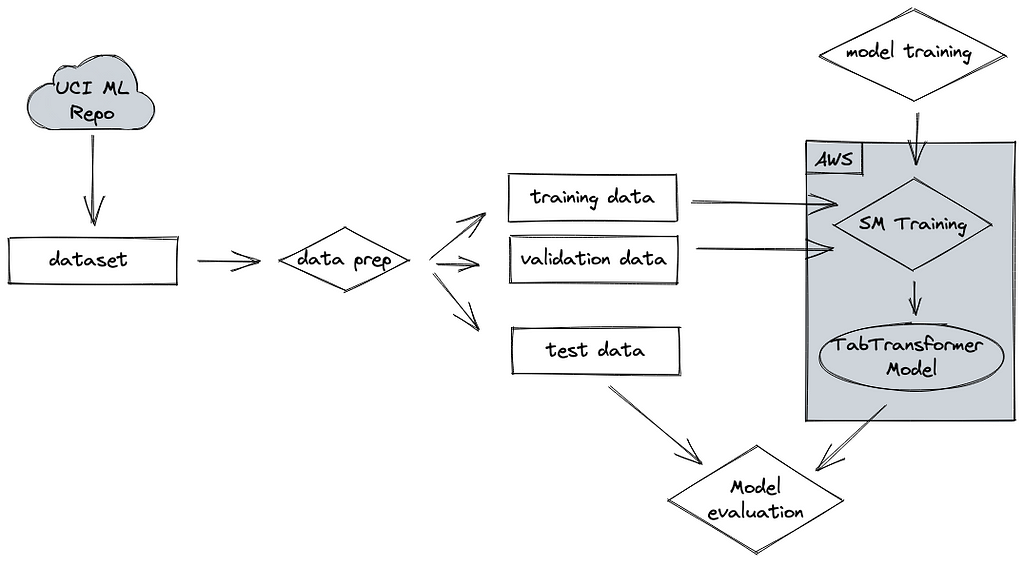
The data
The data set we will be using is the German Credit Data set from the UCI Machine Learning website. It is licensed via Database Contents License (DbCL) v1.0 which explicitly grants the rights for commercial use.
The data set consists of 1,000 records with 20 features and a target variable. Each entry represents a person who takes a credit. Each person is classified as good or bad credit risks (1 = Good, 2 = Bad) according to the set of attributes.
It’s a particularly good data set for TabTransformer because it has several categorical features which is where the algorithm shines.
Data preparation
We can download the data straight from the website into a Pandas Dataframe like so:
As mentioned, the data consists of 20 attributes and a target column. The documentation describes how we have to prepare the data. First off, the target variable needs to be the first column in the data set. Next, we want to change the target variable so that we have zeros and ones instead of ones and twos.
Then we want to split the data into training, validation, and test data set. Training and validation data will be used to train the model while the test set will be used to assess the model performance after the training is completed.
Finally we need to specific folders in an S3 bucket so that the algorithm can access the data. The final structure in the folder should look like this:

We can achieve this like so:
Model training
Once we have prepared and uploaded the data wed have done most of the leg work. We have now set up the structure to be able to just run the algo. In fact, we can just copy/paste the code from the doc. All we need to do is to adapt the paths and we’re good to go.
One thing to note is that we can extract the default values for the hyper parameters for the algorithm and then either run the training job with these default values or change them like so:
Once we have kicked off the training job, we can check the status of it and deploy once the training has finished:
Testing the model
Once we have deployed the model we can test its performance by using the holdout test data set from the data preparation step. All we need to do is serialize the data before submitting it to the endpoint and parse the response to get the predicted labels:
Then we compare these predictions with the actual labels and check for the usual metrics:
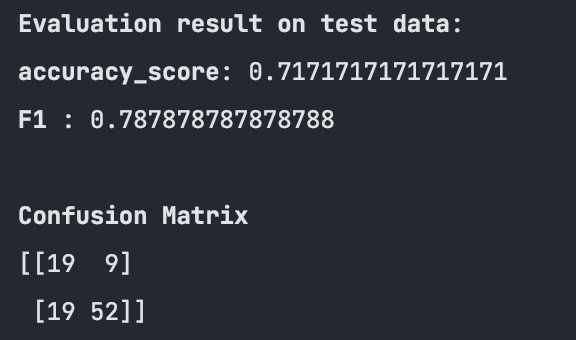
These results are promising and it might be that different values for the hyper parameters would improve the model even further.
Conclusion
In this tutorial we have used the TabTransformer algorithm with our own data. We have prepared the data, trained the algorithm on our data and deployed and tested the model in our AWS account.
As next steps we could:
- Compare the results from the TabTransformer algorithm with tradition, non-deep learning algorithms, such as XGBoost.
- Check out the ability of TabTransformer to perform better at datasets with lots of missing data, because the contextual embeddings learned from TabTransformer are highly robust against both missing and noisy data features, and provide better interpretability.
- Check out the ability of TabTransformer to use unlabeled data to train the model, because these models are promising in extracting useful information from unlabeled data to help supervised training, and are particularly useful when the size of unlabeled data is large.
I hope this tutorial was useful, feel free to reach out if you have any comments or questions.
Transformers for Tabular Data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/zT8L0Qq
via RiYo Analytics







No comments