https://ift.tt/MLJTAIH Pandas vs. SQL — Part 1: The Food Court and the Michelin-Style Restaurant ( Left ) Photo by Dushan Hanuska on flic...
Pandas vs. SQL — Part 1: The Food Court and the Michelin-Style Restaurant

tldr: This is the first in a series of blog posts that contrast Pandas vs. SQL (dataframes vs. databases). Both dataframes and databases are, in fact, old ideas, dating back multiple decades. Databases opt for scalability, robustness, and efficiency, while Pandas opts for conciseness, flexibility, and convenience. Can we even hope for the best of both worlds? Yes!
Every few months, there is a tweet about Pandas vs. SQL, like this one in 2020:
I have to give a code base that combines Pandas and SQL to academics know zero Pandas or SQL, but (1) they may know some R, and (2) they may have friends/peers in academia who know either Pandas or SQL. When a task can be done in either Pandas or SQL, which should be used?
- Senior PowerPoint Engineer (@ryxcommar) July 19, 2020
or this one:
is SQL more popular than python/r among today’s data folks because it’s better, or because people can use it without needing to set up dev environments, move data from one place to another, or do any of the other hard “time to google another cryptic terminal error” stuff?
- Benn Stancil (@bennstancil) January 25, 2022
and then this one earlier this month:
Follow up question: when do you switch from SQL to another PL (Python, JS, etc.)? When it’s hard or when it’s not ergonomic or something else?
- Sarah Catanzaro (@sarahcat21) June 15, 2022
All of these tweets ask essentially the same question: Can Pandas/Python ever be better than SQL/databases for the purposes of data work — and if so, when? Clearly, the millions of data scientists who use Pandas can’t all be wrong in their preferred choice of tool — but it’s hard to find a resource that answers this question in a definitive manner.
So we decided to write a series of blog posts that explore this question, comparing Pandas vs. SQL/databases. This is the first, and we will release subsequent posts in the coming weeks. Even if you don’t read any of the posts, the punchline is this: Both dataframes and databases have been around in some form for multiple decades. And both have an essential place in the arena of data analysis and data science!
Anyway, onto the topic of this particular blog post. Mmm... who doesn’t love a good gastronomic analogy? Let’s dig in.
To begin, let’s talk about relational databases — a mature, multi-decades old technology, with a market cap of hundreds of billions of dollars, with offerings from the likes of Snowflake, Databricks, Oracle, Amazon, Microsoft, and Google. We all love relational databases.
Databases allow you to represent data in intuitive collections called relations with a predefined structure, or schema. Databases let you operate on relations using SQL, or “Structured Query Language,” a language invented in IBM in the 1970s, and often referred to as “ intergalactic dataspeak.” SQL and relational databases have stood the test of time, despite many attempts to dethrone them, including the noSQL movement from the mid-2000s. Databases will outlive us all.

It turns out that a relational database is very much like a Michelin-starred fine-dining restaurant. This type of restaurant is very formal: You need to wear a shirt or a dress, not shorts or a t-shirt — much like your database, which requires a formal schema before you operate on your data. There are not a lot of options on the menu: Often it is a fixed menu with a small, carefully curated set of options — much like your database, which only supports a small handful of keywords in SQL (SELECT-FROM-WHERE-GROUP-BY …). But for what it does, fine-dining restaurants — like databases — are finely tuned, efficient, and effective.
Alternatively, let’s consider a very different beast, Pandas, the popular dataframe library for data science.
Pandas is a fast, powerful, flexible, and easy-to-use open source data analysis and manipulation tool. Pandas’ origins stem from the statistics community, which previously developed the underlying dataframe abstraction in S in the 1990s and R in 2000s, before it was ported to Python in 2008. So dataframes have been around in some form — explicitly designed for the purpose of statistical data analysis and data science — for more than three decades!
Pandas is incredibly popular among data scientists and data analysts, being downloaded 30M times a week. In fact, Python is now the world’s fastest growing language due, in large part, to Pandas. And in various articles, it has been referred to as the most important or the most popular tool in data science.
So how do Pandas dataframes compare to databases? The Pandas dataframe system is similar to databases, but also different. Unlike database relations, within a dataframe, Pandas allows for mixed types in a column and maintains a notion of order. Dataframes also support row labels, in addition to column labels, making it easy to reference your data. And pandas supports 600+ functions spanning data cleaning, preparation, transformation, and summarization, that let you do pretty much anything imaginable to your data, drawing from relations, matrices (linear algebra), and spreadsheets — spanning data cleaning, transformation, preparation, featurization, and exploration.
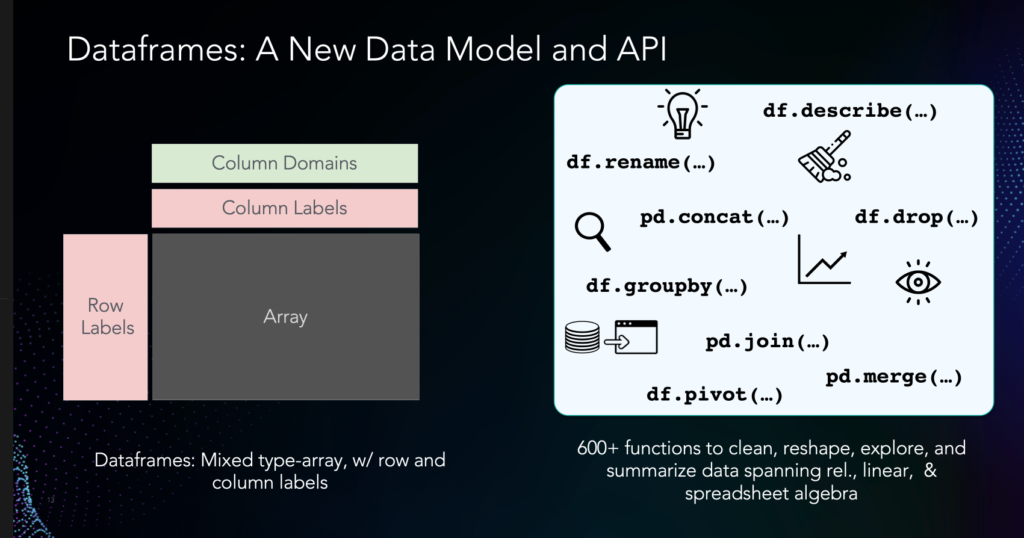
So, if relational databases are like Michelin-starred restaurants, Pandas is very much like a food court. Food courts don’t care what you’re wearing — just like Pandas, which doesn’t need you to structure or clean your data before loading it in. You can order what you like, in bits and pieces — just like Pandas, which lets you pose your query in incremental steps. You can even do ungodly things — like mix sushi and fries. You can even put ice cream on your fries. You may get some strange looks, but nobody can stop you. Everyone is happy from the oldest person to the youngest!

Let’s contrast our database fine-dining experience with the Pandas food court. In terms of convenience, relational databases require you to order your entire SELECT-FROM-WHERE query at once; Pandas lets you place your order one item at a time, inspect it, and then order more if you’d like. Our fine-dining database requires a formal schema before you can even get in the door (you’ll get kicked out if you’re wearing shorts!); the Pandas food court doesn’t care-it’s totally fine with mixed types in a column, which comes in handy during the early stages of data cleaning. Pandas is also very egalitarian: It treats rows and columns the same, and data and metadata the same; good luck getting that treatment from your fine-dining database! Our fine-dining database only has a few things on the menu — your SELECT-FROM-WHERE query; Pandas has everything imaginable, from sushi to burgers to ice cream, with 600+ open-source functions contributed by data scientists.
So what’s the downside? Unfortunately, despite the many positives of the Pandas API, the Pandas implementation doesn’t really scale since it evolved in an ad-hoc manner without any formal grounding. It only supports single-threaded execution, so even running it on a beefy cluster doesn’t give you any benefits. Since it operates entirely in memory and makes many copies, it often throws out-of-memory (OOM) errors. And finally, there’s no real query optimization across multiple pandas operators in a sequence. So what you often have happening is the following: you sample your data, explore with Pandas, then rewrite your workflow to operate at scale.

So if we were to contrast Pandas vs. big data frameworks like databases, these big data frameworks score highly on the performance spectrum, spanning scalability, robustness and efficiency. As we will explore in subsequent blog posts, Pandas scores highly on the ease-of-use spectrum, encompassing conciseness, flexibility and convenience.

One open question is whether we can get both: can we preserve the Pandas API but change the implementation in order to get scalability, robustness, and efficiency? There are teams working on this question — for example, by adapting database-like techniques to Pandas —including an open-source project, Modin, which aims to be a scalable drop-in replacement for Pandas.
In the next post in our Pandas vs. SQL series (post 2 of 4), we argue Pandas is the more concise language. Read more here!
If you are a Pandas or SQL aficionado (or one of both!) we’d love to hear from you. Feel free to follow us on Twitter for more content like this, and respond to our post!
Originally published at https://ponder.io on June 28, 2022.
Pandas vs. SQL — Part 1: The Food Court and the Michelin-Style Restaurant was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/73pzbOW
via RiYo Analytics








ليست هناك تعليقات