https://ift.tt/xnjbLgQ The Red Vineyard by Vincent van Gogh ( Source ) According to the New York Times , 90% of the energy used by data ...

According to the New York Times, 90% of the energy used by data centers is wasted, this is because most of the data collected by companies is never analyzed or used in any form whatsoever, this is more specifically called Dark Data.
Dark data is data which is acquired through various computer network operations but not used in any manner to derive insights or for decision making. The ability of an organisation to collect data can exceed the throughput at which it can analyse the data. In some cases the organisation may not even be aware that the data is being collected. IBM estimate that roughly 90 percent of data generated by sensors and analog-to-digital conversions never get used. — Dark data definition on Wikipedia
From a machine learning perspective, one of the key reasons why this data is not useful for deriving any insights is the lack of labels. This makes unsupervised learning algorithms very attractive to unlock the potential of this data.
Generative Adversarial Networks
In 2014 Ian Goodfellow et al. proposed a new approach to the estimation of generative models through an adversarial process. It involved training two separate models at the same time, a Generator model which attempts to model the data distribution, and a Discriminator which attempts to classify the input as either training data or fake data by generator.
The paper sets a very important milestone in the modern machine learning landscape, opening new avenues for unsupervised learning. Deep Convolutional GAN paper(Radford et al. 2015) continued building on this idea by applying the principles of the convolutional networks to produce 2D images successfully.
Through this article, I attempt to explain key components in the paper and implement them using PyTorch.
What is so remarkable about GAN?
To understand the importance of GAN or DCGAN let’s look at what makes them so popular.
- As a large percentage of real-world data is unlabeled the unsupervised learning nature of GANs makes them ideal for such use cases.
- Generator and Discriminator act as very good feature extractors for use cases with limited labeled data or generate additional data to improve secondary model training, as they can generate fake samples instead of using augmentations.
- GANs provide an alternative to maximum likelihood techniques. Their adversarial learning process and non-heuristic cost function make them very attractive to reinforcement learning.
- The research around GAN has been very attractive and the results have been a source of widespread debate on the impact of ML/DL. For example, Deepfake, one of the applications of GAN which can overlay people’s faces on a target person, has been very controversial in nature as it has the potential to be used for nefarious purposes.
- The last but most important point is that it’s just so cool to work with, and all the new research in the field has been mesmerizing.
Architecture
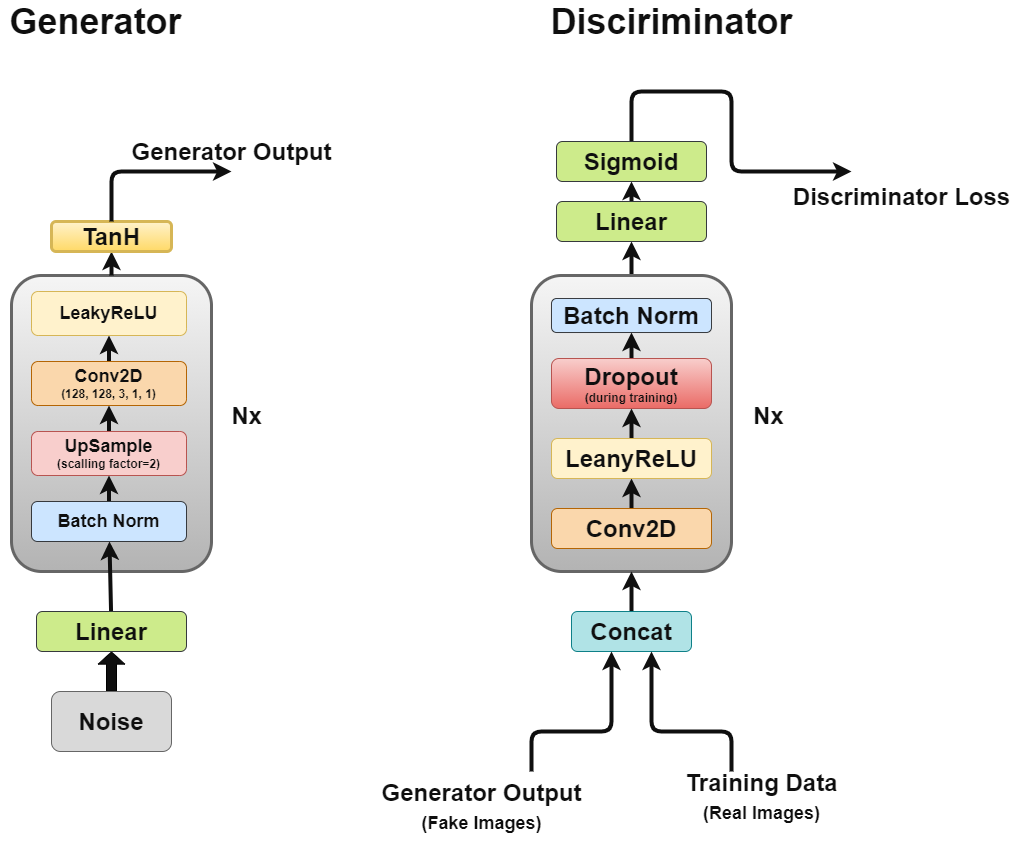
As we discussed earlier, we will be working through DCGAN which attempts to implement the core ideas of GAN for a convolutional network that can generate realistic-looking images.
DCGAN is made up of two separate models, a Generator (G) which attempts to model random noise vector as input and attempts to learn data distribution to generate fake samples, and a Discriminator (D) which takes training data (real samples) and generated data (fake samples) and tries to classify them, this struggle between the two models is what we call adversarial training process where one’s loss is other’s benefit.
Generator
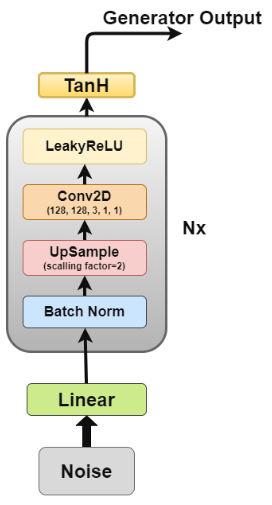
The generator is the one we are most interested in as it is the one generating fake images to try and fool the discriminator.
Now let’s look at the generator architecture in more detail.
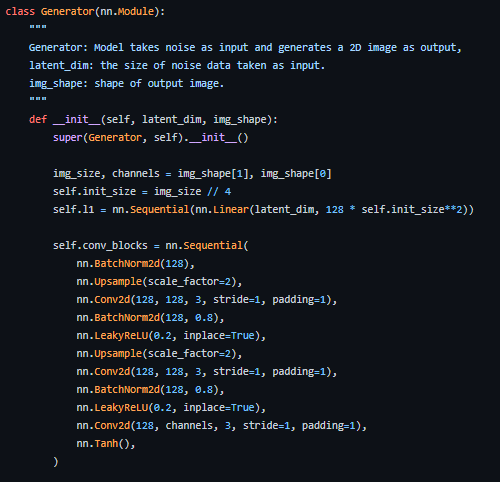
- Linear layer: The noise vector is fed into a fully connected layer the output of which is then reshaped into a 4D tensor.
- Batch Normalization Layer: Stabilizes learning by normalizing inputs to zero mean and unit variance, this avoids training issues like vanishing or exploding gradient and allows the gradient to flow through the network.
- Up sample Layer: As per my interpretation of the paper, it mentions using upsampling and then applying a simple convolutional layer on it rather than using a convolutional transpose layer to up sample. But I have seen some people use convolutional transpose, so make your own decision.
- 2D Convolutional Layer: As we up sample the matrix, we pass it through a convolutional layer with a stride of 1 and the same padding to allow it to learn from its up-sampled data
- ReLU Layer: Paper mentions using RelU instead of LeakyReLU for the generator as it allowed the model to saturate quickly and cover the color space of training distribution.
- TanH Activation: Paper suggests we use the TanH activation function for generator output but does not go into detail as to why, if we had to guess it would be because the nature of TanH allows the model to converge faster.
Layers 2 to 5 make up the core generator block which can be repeated N times to get the desired output image shape.
Here is how we can implement it in PyTorch.
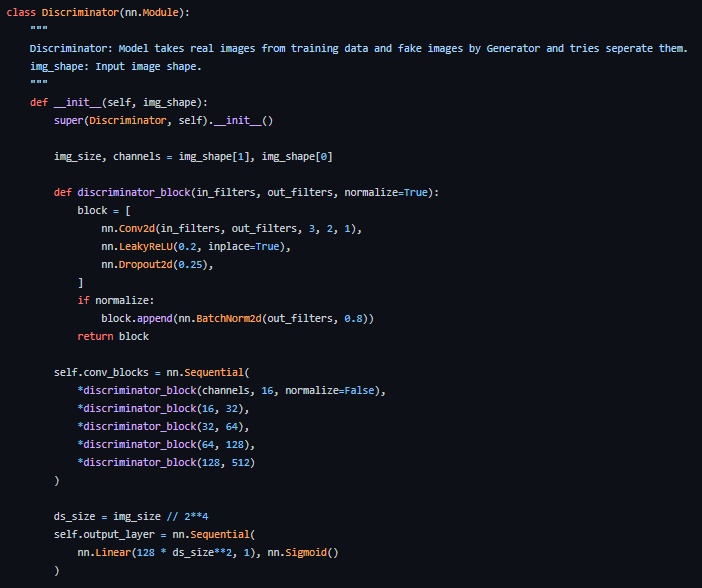
Discriminator
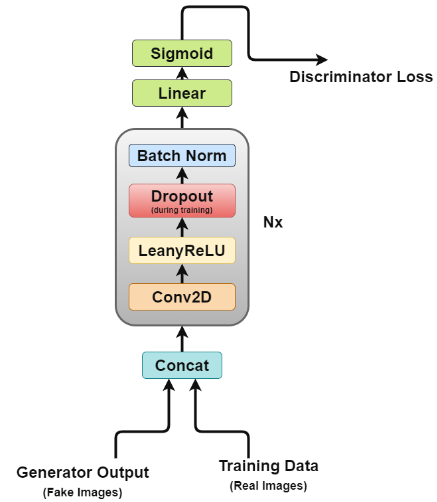
Now the discriminator is rather like an image classification network with a few minor tweaks, for example, it does not use any pooling layer to downsample but a stride convolutional layer allowing it to learn its own downsampling.
Let’s look at the discriminator architecture in more detail.
- Concat Layer: The layer combines fake images and real images in a single batch to feed the discriminator, but this can also be done separately for getting the generator loss only.
- Convolutional Layer: We use a stride convolution here which allows us to downsample the image and learn filters in a single pass.
- LeakyReLU: As the paper mentions it found LeakyReLU useful for discriminators compared to the max-out function of the original GAN paper, as it allows for easier training.
- Dropout: Used only for training, helps avoid overfitting. The model has a tendency to memorize real image data and training could collapse at that point as the discriminator cannot be fooled by the generator anymore
- Batch Normalization: The paper mentions that it applies batch normalization at the end of every discriminator block except the first one. The reason mentioned by the paper is that applying batch normalization over every layer cause sample oscillation and model instability.
- Linear: A fully connected layer that takes a reshaped vector from the 2D batch normalization layer applied through.
- Sigmoid Activation: As we are dealing with binary classification for discriminator output making a sigmoid layer logical choice.
Layers 2 to 5 make up the core discriminator block which can be repeated N times to make the model more complex per training data.
Here is how we can implement it in PyTorch.
Adversarial Training
We train Discriminator (D) to maximize the probability of assigning the correct label to both training examples and samples from Generator (G) which can be done by minimizing log(D(x)). We simultaneously train G to minimize log(1 − D(G(z))) where z is the noise vector. In other words, D and G play the following two-player minimax game with value function V (G, D):
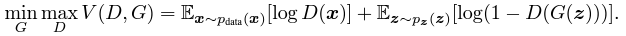
In practice, above equation may not provide sufficient gradient for G to learn well. Early in learning, when G is poor, D can reject samples with high confidence because they are clearly different from the training data. In this case, log(1 − D(G(z))) saturates. Rather than training G to minimize log(1 − D(G(z))) we can train G to maximize logD(G(z)). This objective function results in the same fixed point of the dynamics of G and D but provides much stronger gradients early in learning. — Source
As we are training two models simultaneously it could be tricky and GANs are notoriously difficult to train, one of the known problems we will discuss later is called mode collapse.
Paper suggests using an Adam optimizer with a learning rate of 0.0002, such a low learning rate suggests that GANs tend to diverge very quickly. It also uses the momentum of the first order and second order with values of 0.5 and 0.999 to further accelerate training. The model is initialized with normal weight distribution with zero mean and 0.02 standard deviation.
Here is how we can implement a training loop for this.

Mode Collapse
Ideally, we would like our generator to produce a wide variety of outputs, for example, if it generates a face, it should generate a new face for every random input. But if the generator produces a plausible output good enough to fool the discriminator it might keep producing the same output again and again.
Eventually generator over-optimizes for a single discriminator and rotates between a small set of outputs, such a condition is called mode collapse.
The following approaches can be used to remedy the condition.
- Wasserstein loss: The Wasserstein loss alleviates mode collapse by letting you train the discriminator to optimality without worrying about vanishing gradients. If the discriminator doesn’t get stuck in local minima, it learns to reject the outputs that the generator stabilizes on. So, the generator has to try something new.
- Unrolled GANs: Unrolled GANs use a generator loss function that incorporates not only the current discriminator’s classifications but also the outputs of future discriminator versions. So, the generator can’t over-optimize for a single discriminator.
Application
- Style Transfer: Face modification apps are all the hype nowadays, face aging, crying face, and celebrity face overlay are just some applications already widely popular on social media.
- Video games: Texture generation for 3D objects, and scene generation using images are just some applications helping the video games industry develop bigger games faster.
- Movie Industry: CGI has been a big part of model cinema, with the potential GAN brings, movie makers can now dream bigger than ever.
- Speech Generation: Some companies are using GANs to improve text-to-speech applications by using them to generate more realistic voices.
- Image Restoration: Using GANs to denoise and restore corrupted images, coloring historical images, and improving old videos by producing missing frames to improve their frame rate.
Conclusion
GAN along with DCGAN is a milestone paper that has opened new avenues when it comes to unsupervised learning. The adversarial training approach provides a new way of training models that closely mimic real-world learning processes. It would be very interesting to see how this area evolves.
Hope you enjoyed the article.
You can find the complete implementation on my GitHub
You can follow me on Linkedin
You can read my other articles on Medium
Implementing Deep Convolutional GAN was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/pvW26fS
via RiYo Analytics








{kind=link}
ليست هناك تعليقات