https://ift.tt/1ngSFO0 A detailed guide on how to clean your data to kickstart your personal projects Photo by Towfiqu barbhuiya on Uns...
A detailed guide on how to clean your data to kickstart your personal projects

When I participated in my college’s directed reading program (a mini-research program where undergrad students get mentored by grad students), I had only taken 2 statistics in R courses. While these classes taught me a lot about how to manipulate data, create data visualizations, and extract analyses, working on my first personal project in the program made me realize I had never worked with “messy data”. Those courses involved pre-cleaned and processed datasets but didn’t teach students how to clean datasets which creates a barrier to starting on personal projects. Hence, I hope that this article serves as a starting point for you to learn how to clean your data efficiently to kickstart your personal projects.
For this article, I’ll be working with the Netflix TV Shows and Movies Dataset which features many inconsistencies and missing data.
Table of Contents
- Look into your data
- Look at the proportion of missing data
- Check the data type of each column
- If you have columns of strings, check for trailing whitespaces
- Dealing with Missing Values (NaN Values)
- Extracting more information from your dataset to get more variables
- Check the unique values of columns
All images unless otherwise noted are by the author.
Step 1: Look into your data
Before even performing any cleaning or manipulation of your dataset, you should take a glimpse at your data to understand what variables you’re working with, how the values are structured based on the column they’re in, and maybe you could have a rough idea of the inconsistencies that you’ll need to address or they’ll be cumbersome in the analysis phase. Here, you might also be able to eliminate certain columns that you won’t need depending on the analysis you want to do.
1. Print the first few rows of your dataset
Here, I printed the first 7 rows of my dataset, but you can print 5 or 10. I recommend keeping it to anything less than 10 or else it’ll be too overwhelming for what you’re currently trying to do–a quick glimpse of the dataset.

Doing this will give you a good idea of what data types you might be dealing with, what columns you need to perform transformations or cleaning, and other data you might be able to extract.
Before we look at this more closely, let’s perform the next step.
2. Save the variables to a list
You want to do this to have easy access to the different columns of the dataset, especially when you want to perform the same transformations to different subsets of columns.
3. Note down potential issues you will have to address in each column.
To stay organized, note the issues you see in your dataset (by taking a glimpse of your dataset like in Step 1).
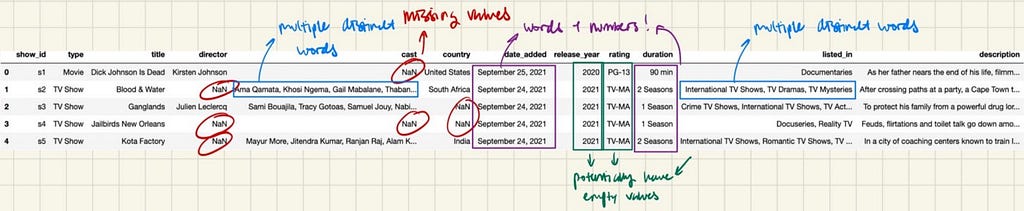
This picture above represents what I can see just from glimpsing at the dataset and is something that you should think about when you’re looking at your dataset. Here are a few things that stand out to me:
- There are some columns with missing values. This could cause a lot of problems for analysis and plotting if not addressed and resolved early in the process.
- There are columns with words and numbers, such as date_added and duration. This can be a problem if we want to make time-series graphs by the date, or other plots to explore duration’s relationship with other variables.
- There are 2 columns with multiple distinct words joined together by a comma. This is an issue if we want to make plots exploring the distribution of listed_in (genre) or the actors on Netflix.
- Other columns could potentially have missing values. The next step looks at the way to check which columns have missing values and how much missing data they have.
Step 2: Look at the proportion of missing data
From this code chunk, you can easily look at the distribution of missing values in the dataset to get a good idea of which columns you’ll need to work with to resolve the missing values issue.
From the output, these are insights you can gather:
- director column has the highest percentage of missing data ~ 30%
- cast and country column also has a considerable percentage of missing data ~ 9%
- date_added, rating and duration don’t have that much missing data ~ 0% - 0.1%
- Fortunately, most other columns are not empty.
Your next question is probably, how do I deal with these columns with missing values?
There are a few ways to deal with it:
- Drop the column completely. If the column isn’t that important to your analysis, just drop it.
- Keep the column. In this case, because the director, cast and country columns are quite important to my analysis, I will keep them.
- Imputation — the process of replacing missing data with substituted values. Here, it is not possible to do so because most of the data are string values and not numerical values. However, I will be writing an article that talks more about imputation in detail, why and when it should be used, and how you can use it in R and Python with the help of some packages.
Before I continue, I will bring up the issue of missing values across rows.
In some cases, you might want to examine the distribution of missing values across all the rows of your dataset (given that your dataset doesn’t have a large number of observations/rows). From here, you can choose from the choices above depending on how important the rows are to your analysis. For instance, your dataset contains recorded data of something that is changing over time. Even though a row can contain missing values, you might not want to eliminate it because there is important time information you want to retain.
Let’s continue to step 3 before I show you how to deal with the NaN values even after keeping the columns.
Step 3: Check the data type of each column
Here, you can see that all the columns have object as their datatype aside from release_year. In pandas, object means either string or mixed type (numerical and non-numerical type mixed). And from our dataset, you’ll be able to tell which columns are strictly string and mixed type.
Step 4: If you have columns of strings, check for trailing whitespaces
After we know which data types we are dealing with, let’s make sure we remove any trailing characters and whitespace using strip .
Step 5: Dealing with Missing Values (NaN Values)
Referring back to the columns of missing values, let’s take a look at the columns: director, cast, country, date_added, rating, duration. We can segment these columns by whether they are a string or mixed type.
String: director, cast, country, rating (here, it’s a string and not mixed because the numerical values won’t have any meaning if separated)
Mixed: date_added, duration
NaN means Not a Number in pandas. It is a special floating-point value that is different from NoneType in Python. NaN values can be annoying to work with, especially when you want to filter them out for plots or analysis. To make our lives easier, let’s replace these NaN values with something else.
For string type values, we can replace NaN values with “” or “None” or any string that can indicate to you that there isn’t any value in that entry. Here, I chose to replace it with “” using the fillna function. Because it’s not an in-place function, I reassigned the changed values to the column in the dataset.
Here, you must have noticed that I left out the duration column. This is because we’ll be doing something with that column later down the road.
Step 6: See if there are any other variables that you can obtain by extracting them from other variables
For mixed-type values, before we tackle the missing value issue, let’s see if we can extract any data to make our analysis richer or process easier.
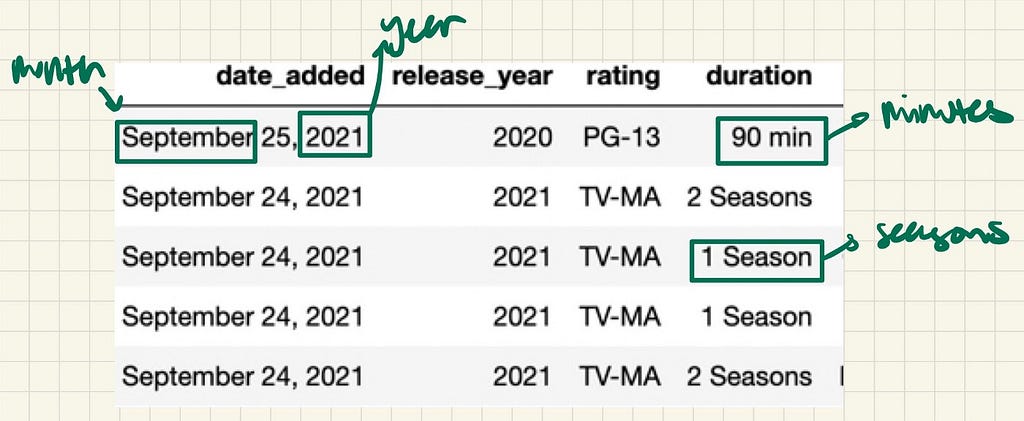
Looking at date_added, we can see that it contains the month, date, and year that the film/show was added. Instead of having all this information in one column, why not try to separate them? That way, we can choose to isolate how month or year interacts with the other variables instead of looking at date_added where its granularity will make it difficult for any trend to be discovered.
Below, I’ve written code to not only separate the information into 2 other columns but also filtered out the rows with NaN values and replaced them with 0, just like what was done before with “”.

Now, the new dataset contains the month_added and year_added columns. This will allow us to do some trend analysis later.
Looking at duration, on top of it being a mixed type, there are also 2 different time units in this column. This is a problem because we are dealing with 2 different types of content that are measured differently for time. Thus, making graphs for durationwill be quite difficult to interpret if we keep them as it is. The good thing is that there are many ways to deal with this issue. The way I’ve chosen to deal with it is by separating the type of content into 2 different datasets and naturally, the duration column will just be numerical and just have 1 type of time unit. This way, you can easily and clearly plot using the values.
Because the duration column has both strings and numbers, I’ll also have to create a function to extract the number from that column so that it can be inserted into the columns of the 2 new datasets.
Step 7: Check the unique values of columns
Beyond potentially missing values, there could be corrupted values that you can run into once you perform analysis. To check this, we can check for unique values for some of the columns. Let’s refer to the first 5 rows of the datasets as our starting point.


It might not be strategic to check the unique values of all the columns, especially the title, director, and cast as there could be a large number of unique values to examine. Instead, let’s focus on a list of potential unique values that could be easier and more important to check given that it could be more insightful for future analysis. From a glimpse at the datasets, the columns country, rating, listed_in are probably the ones of interest. Let’s examine the rating column first as that seems to be the least complicated one to deal with.
You can easily obtain the unique values of a column like rating using Python’s built-in function, unique. Let’s try that!
This seems interesting. Why are there 74 min, 84 min, and 66 min in the unique types of rating for films? And why are there UR (Unrated) and NR (Not Rated)? Aren’t they supposed to mean the same thing? Let’s investigate this further by extracting the rows that have these weird entries.
Using this code chunk, we can see that 3 distinct rows contain this weird rating and that it actually belongs to the length column. We can also see the row number where the issue is located which will be useful to use for fixing the entries.
After some quick Googling, we can proceed to fix these entries by moving the “wrong ratings” (actually duration) to the length column and entering the right ratings.
For the UR and NR values in the rating column, we should keep the consistency where NR is used in the netflix_shows dataset and change UR values to NR.
Now that we’ve cleaned up the rating column, let’s look at the country and listed_in column. By now, you must have realized that it’s not as easy as the rating column to extract unique values. This is because the values in those columns are words joined together by commas, making it more difficult to extract the set of words and then find unique words from that set.
How we’re going to get around this issue is by implementing a unique function for this special case.
To start, let’s think about what data structure can give us unique values easily. If you guessed sets, you’re right! Given its ability to store unique elements of the same type in sorted order, it’s a fitting data structure for what we want to do.
Then, to extract those words that are joined by commas, we can use the split function to split up the string by the comma.
After using the function, we can easily obtain the unique values for the country and listed_in columns.
Next, let’s examine the list of unique countries to see if there are any inconsistencies or mistakes. By doing so and with a little bit of Googling, we can see there are some issues with this list:
- There’s both the Soviet Union and Russia
- There’s both the West/East Germany and Germany
We can easily fix this with a few modifications to the dataset.
As for the list of genres, we can see that there are some genres we might not want or need to include. Thus, we can easily remove it from the dataset to make our analysis less confounding.
In both the TV shows and films dataset, there is a “TV Shows” and “Movies” genre. Technically, this isn’t a genre but could be a label of the type of content. To confirm this, we should print out the counts of these “genres” appearing in the respective datasets.
The hypothesis is that if these “genres” appear in all the rows of the datasets, it means that they’re simply labels. Otherwise, we’ll have to investigate further as to what those “genres” represent.
As the count of the “genres” is less than the size of the datasets, let’s use the output of the code to examine the rows.
Since I’ve written the code to specifically output the row indices in a list, we can easily use that list and the iloc function to get a view of the rows.


Taking a look at the rows, it is now obvious that the “TV Shows” and “Movies” genre was used to signify that these content didn’t have a genre in the first place. Now that we understand what this meant, we can either choose to exclude or include it in our analysis. Here, I’ve chosen to include it because it doesn’t affect my analysis.
Although this step is tedious, it is also quite important as it allows us to find the issues in our dataset that are hidden away at a first glance.
Step 8: Join the cleaned datasets together to create another dataset [Optional]
This step is optional, but in the case that you’d want the cleaned TV shows and movies dataset in one place, you should concatenate them.
And that’s it! You’ve successfully cleaned this dataset. Keep in mind that everyone has their methodology of data cleaning, and a lot of it is just from putting in the effort to understand your dataset. However, I hope that this article has helped you understand why data scientists spend 80% of their time cleaning their datasets. In all seriousness, this article highlights the importance of data cleaning and more importantly, the need for a good data cleaning methodology which will help you keep your work organized which will help if you need to go back to it during the analysis process. You can check out the full notebook here.
Thanks for reading. You can check me out on LinkedIn and Twitter!
How to Clean Your Data in Python was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/GomnsRE
via RiYo Analytics






No comments