https://ift.tt/zDcnlKm Struggling to overcome the management and cost demands of a legacy data system Tata Steel products are in almost ev...
Struggling to overcome the management and cost demands of a legacy data system
Tata Steel products are in almost everything, from household appliances and automobiles, to consumer packaging and industrial equipment. As a fully integrated steel operation, Tata mines, manufactures, and markets the finished products, leveraging data insights from our seven worldwide production sites and across business functions for transparency, coordination, and stability. We have a variety of ways we are leveraging our data and analytics in both the manufacturing and commercial areas of our business with the goals of enhancing sustainability across our operations, reducing overall costs, and streamlining demand planning.
A couple of years ago, Tata started our journey to become a data-driven company. Most use cases were ad hoc analysis focused rather than end-to-end solutions, and we were in the beginning stages of digitalization. We had plans to leverage our data across different facets of the business including:
- Streamlining supply chain management and logistics;
- Enabling capacity and demand forecasting;
- Initiating payload optimization;
- Supporting, measuring, and guiding Tata toward accomplishing our environmental initiatives.
However, achieving transformation across multiple operations was challenging to get off the ground. Initially, we were using a legacy data product that mimicked a mini data lake, without all the benefits of democratization and scale that we needed. We had limited internal knowledge of how to maximize the infrastructure and considered most of the tools to be user-unfriendly given the makeup of our data team. Issues around cluster availability and access across multiple users caused frequent outages, which frustrated users and led to costly downtime. Additionally, we had to provide our own UI on top of the infrastructure and analytics engine, causing us to incur significant overhead for productionization of use cases as well as integration with our Azure cloud. Too many infrastructure management demands were adding to overhead, and forcing IT talent to inordinate amounts of time patching, updating, and maintaining tools — wasting time on infrastructure issues rather than solving business issues. This inability to take action on our data inhibited our ability to move our target use cases into production.
We needed a fully managed, user-friendly data platform that could not only unify all our data in one place but also enable and empower teams to take advantage of our data once the barriers of access are removed. Once learning about the Lakehouse architecture, we realized the value it offered beyond standard cloud data warehouses which tended to lack the openness, flexibility and machine learning support of data lakes. Most importantly, taking a unified approach delivered by the Lakehouse would unlock the promise of our data across more teams within the organization, fueling innovation and better decision-making.
Data enablement in the lakehouse allows for smarter business decisions
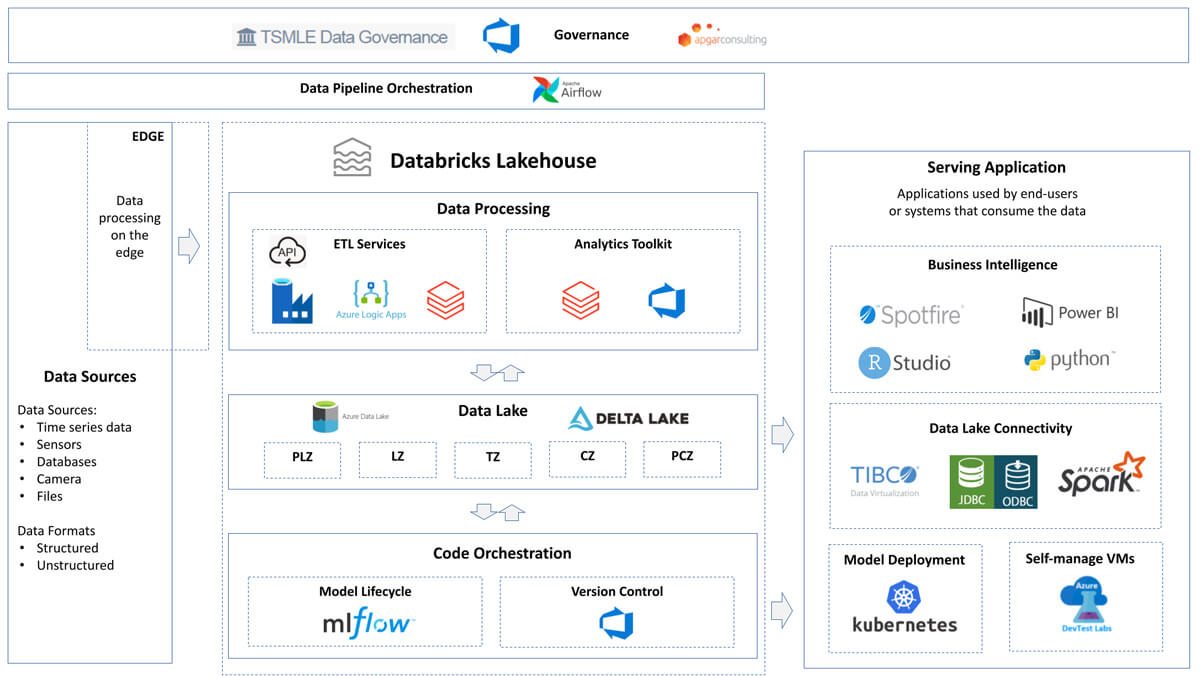
About a year and a half ago, Tata deployed the Databricks Lakehouse Platform on Azure. The migration was smooth because we had internal Azure knowledge and the software instantly solved a lot of issues, specifically from an infrastructure and data management perspective. All of a sudden, data accessibility was enhanced for both administrators and users. Our cluster issues were eliminated, and we finally had ease of scalability — allowing us to explore our data in ways not possible before. Without the low-level infrastructure maintenance tasks, we became more cost-efficient and lowered overhead. At the same time, we were finally able to leverage machine learning (ML) to better meet business goals through innovation. In total, everything in Databricks was UI-based, enabling us to shift from being IT-driven to business-value driven due to the simplicity and ease-of-use of the Databricks Lakehouse Platform.
Now equipped with a centralized and unified lakehouse platform, Tata has about 20 to 30 different use cases in production. Using Databricks Lakehouse components, MLflow, and a combination of Delta Tables with MLflow, Tata teams across the board are utilizing ML without the problems we struggled with in the past. Demand forecasting and supply chain management, which were previously estimated with rough data, are now streamlined based on customer need, existing and future supply, mode of transportation, workflow capacity, and inventory management. These insights have allowed Tata to better meet customer expectations and improve overall satisfaction by better understanding their requirements and empowering us to produce products when needed or utilize existing inventory to avoid waste and expensive rush transport for last-minute deliveries.
On the production side, uses cases include predicting finish dates of our orders, dynamic recipe control to ensure steel criteria meet customer standards prior to production completion, and predictive motor maintenance and repair planning to avoid downtime and interruptions at plants. In addition to these use cases focused on meeting customer expectations, we are also heavily invested in environmental sustainability. For example, through payload optimization during freight transportation, we are able to improve our carbon-neutral production and reduce CO2 emissions. With Databricks, Tata is able to move closer to those goals by reducing the dust and odor emissions that occur during production, and increasing freight payload so that products are only transported in fully-utilized trucks.
The value Tata is experiencing goes beyond machine learning. We are also able to serve data-driven insights to different teams and stakeholders across the organization. With our data centralized in the Lakehouse, we are able to easily feed data to dashboards used to make better decisions around supply chain workflows, demand forecasting, capacity planning, and more. On the scale that Tata operates, these small changes contribute significantly to reducing our footprint and striving toward sustainability.
Structured data sharing ensures a better tomorrow, every day
Now that structured data sharing is enabled through Databricks and the various Databricks components being used by Tata, we’re seeing hard results we can trust. Today, our demand forecasting model is performing 30% more accurately than before Databricks. Our payload optimization use case is delivering 4-8% cost savings through better transportation planning and allocation of transportation space.
From a user adoption standpoint, we have created forums to share knowledge and help teams in functional departments with their Databricks journey. In turn, this decreased project turn around and helped teams to gain deeper data insight to make smarter decisions throughout Tata. With everything originating from Databricks, we know that teams are using accurate numbers, collaborating across teams, and participating in knowledge sharing which makes master data management easier, more trustworthy, and more logical. Today, we have over 50 machine learning use cases in production across our commercial business and manufacturing including logistics planning, payload optimization, production quality management, predictive maintenance, and more.
Additionally, Databricks components like MLflow solve the traditional issues that often prevent non-IT users from successfully implementing data-based use cases. Now, less experienced users can kick off their own projects and easily get benchmarks with AutoML, monitor for data quality across various sources with MLflow, and use Delta Tables with MLflow for traceability between versions.
Overall Databricks helps us plan for the future because it allows us to focus on what really matters. We can see big picture sustainability progress and small picture use case applications without getting lost in the minutia of technical management. Instead, we can scale data ingestion, use cases, and user adoption for more impact throughout the organization. With our partnership with Databricks, we are quickly moving towards sustainable manufacturing with award-winning use cases such as Zero-carbon logistics and are well on our way to becoming the leading data-driven steel company of the future.
--
Try Databricks for free. Get started today.
The post How Tata Steel is Shifting Global Manufacturing and Production Toward Sustainability appeared first on Databricks.
from Databricks https://ift.tt/HbRWJ8g
via RiYo Analytics






No comments