https://ift.tt/eY1E8TJ An overview of ETL in healthcare, a critical part of the data lifecycle in clinical data science This is the second...
An overview of ETL in healthcare, a critical part of the data lifecycle in clinical data science
This is the second article in my clinical data science series. In the first article, I provided a thorough overview of the expansive field of clinical data science, and that sets the foundation upon which this edition is built. If you are unfamiliar with the area of clinical data science or you just want a fast refresher on the key ideas, you might want to have a sneak peek of the introductory article. With that said, the rest of the article is organized as follows;
- General overview of ETL
- ETL in clinical data science/healthcare domain
- ETL life cycle
- ETL tools
- Clinical Data Warehouse
- Challenges with ETL in healthcare.
General overview of ETL
Extract, Transform and Load (ETL) is a three-stage process that involves fetching the raw data from one or more sources and moving it to an intermediate, temporary storage known as staging area; transforming the extracted data to enforce data validity standards and conformity with the target system; and loading the data into the target database, typically a data warehouse or repository.
The extract phase of ETL deals with exporting and validating the data, the transform phase involves cleaning and manipulating the data to ensure it fits into the target and the final stage, which is loading involves integrating the extracted and cleaned data into the final destination. This process is what forms the foundation upon which workflows in data analytics is built. Through the use of a set of technical and business criteria, the ETL process makes sure the data is clean and properly organized to meet the needs of business intelligence.
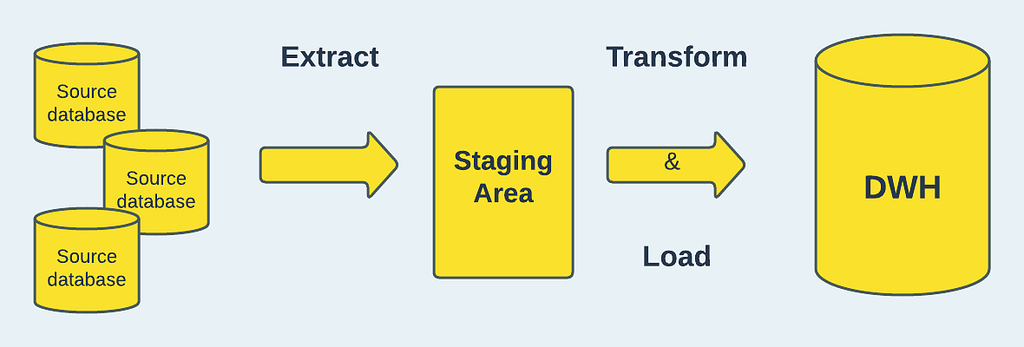
A typical ETL process employs a step-by-step approach which starts by understanding the structure and semantics of the data contained in the source system. The source of the data we are trying to fetch could be a data storage platform, legacy system, mobile devices, mobile apps, web pages, existing databases etc. After establishing the technical and business requirements, there is a need to understand the right fields/attributes that meet these requirement and also the format in which they are stored. Many of these formats, including relational forms, XML, JSON, flat files, etc., could be used for the data in the source system.
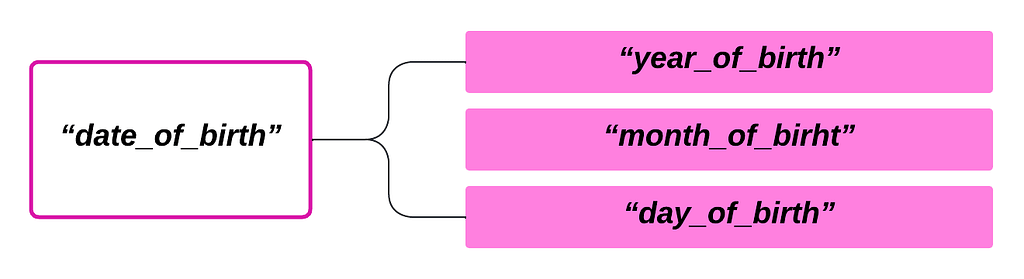
In order to prepare the extracted data for integration into a data warehouse, a series of rules are applied to scrutinize, cleanse, and organize the data to ensure only the ‘fit’ data are loaded. During this phase, a number of transformation types are applied. For instance, not every field in the source system can be used in the target system; the transformation process will look into choosing the precise fields that can be synchronized between the source and the target. A good illustration of this is a situation where we have a field named “date_of_birth” in the source system which is a date value making up the year, month and date of birth of an individual. Whereas, in the target system, the fields are broken down into “year_of_birth”, “month_of_birht”, and “day_of_birth” fields. In our transformation pipeline, we’ll need to create a rule for breaking down the single field in the source system to the corresponding three fields in the target system to ensure they are in conformity.
After extraction and transformation, the data is ready to be loaded into the target system either for querying or further analytics processing. As previously stated, the most typical example of a target system is a data warehouse, which simply serves as a repository for data that has been compiled from a variety of sources. More on this later.
ETL in clinical data science/healthcare domain
Answering health-related questions requires a thorough understanding of the complicated nature of the data generated in the healthcare industry, as well as how the data from the source system are organized in the destination database. ETL is necessary in the healthcare industry to export data from one source, typically an EHR, and transform it into a form that is compatible with the target database’s structure, where the data will be stored, either for later use or supplied in a presentation-ready format. EHR, which offers information on people’s health state, is an essential information source in the healthcare industry, as was mentioned in the first series. Data from EHRs give both practitioners and researchers the chance to enhance patient outcomes and health-related decision-making.
ETL in healthcare can be as simple as combining data from several departments in a clinical setting to improve decision-making, or as sophisticated as integrating data from a large number of EHR systems into a Common Data Models (CDMs) such as those of the Observational Medical Outcomes Partnership (OMOP), Informatics for Integrating Biology and the Bedside (i2b2), Mini-Sentinel (MS) and the Patient Centered Outcome Research Network (PCORNet), which are typically used by research networks for the purpose of knowledge-sharing and research.
In order to populate the target database for extraction and provide the mappings between the source data and target data elements, the extract phase of ETL in healthcare entails defining the suitable fields in the source data (such as EHR or claims data) by individuals with domain expertise.
As described by Toan et al., after identifying the correct data elements to map to the target database, engineers/database programmers define the rules/techniques for data transformation and the schema mappings for loading data into the harmonized schema. To conform to the target schema format and codes so they can be put into the target database, transformation is a complex process of data “cleaning” (e.g., data de-duplication, conflict resolution), standardization(e.g., local terminology mapping). This stage necessitates manual database programming using languages like structured query language (SQL). These processes are frequently repeated until the altered data are acknowledged as comprehensive and accurate.
In the context of clinical science, integrating data from disparate sources is a demanding task that requires several iterations in the ETL process. These iteration processes frequently have their own difficulties, which may be caused by inaccurate mappings, lengthy query times, and data quality problems. Incorrect mappings usually stem from compatibility conflicts between the source data and the destination system in which case the source database often have different data representation, vocabularies, terms for data elements, and levels of data granularity.
ETL life cycle
At the granular level, the ETL process involves several iterations starting with ETL specification, data extractions, data validation, ETL rule creation, query generation (with SQL), testing & debugging, and data quality reporting.
- ETL specifications is a document collecting necessary information for developing ETL scripts.
- Data validation in simple terms, is the process of ensuring that the data that is transported as part of ETL process is consistent, correct, and complete in the target production live systems to serve the business requirements.
- Rule creation and query generation involves creating the rules for data extraction and implementing the rules using (most commonly with SQL).
- The testing and debugging ensures that the data is accurate, dependable, and consistent across the data pipeline, including the data warehouse and migration stages. By measuring the effectiveness of the entire ETL process, we may find any bottlenecks and ensure that the procedure is prepared to scale with the increasing volumes of data.
- Data quality reporting gives the account of any quality flaws found during the ETL process and this is necessary to ensure data integrity. To more accurately reflect its dimensions and influences, data quality is acknowledged as multi-dimensional. Each dimension has a set of metrics that enable its assessment and measurement.
In clinical data science, data quality problems can occur in terms of accessibility, validity, freshness, relevance, completeness, consistency, reliability and integrity. The clinical data quality is a critical issue because it affects the decision making and reliability of research.
ETL Tools
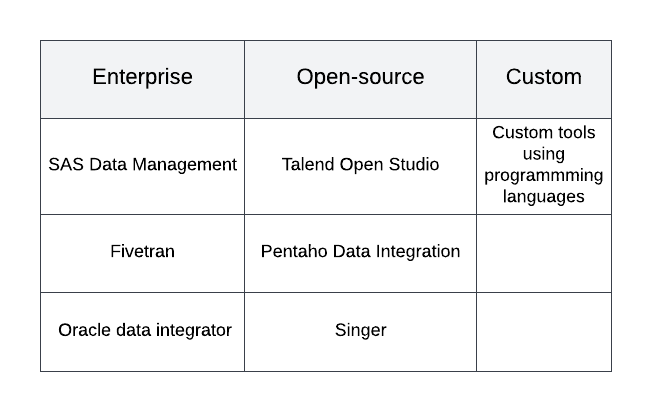
ETL tools are technological solutions designed to facilitate the ETL processes. When used appropriately, ETL technologies offer a consistent approach to data intake, sharing, and storage, which simplifies data management techniques and enhances data quality. Commercial businesses produce and provide support for some of the ETL tools that are readily available. They offer a variety of functions, including a Graphical User Interface (GUI) for developing ETL pipelines, support for relational and non-relational databases, and a rich documentation. They are quite robust and mature in design. Examples of these include SAS Data Management, Fivetran, Oracle data integrator, etc.
Due to high price tag and the level of training required to use enterprise-built ETL tools, other alternatives include using open source software like Talend Open Studio, Pentaho Data Integration, Singer, or Hadoop. However, open-source tools might fail to meet up with the specific needs of an organization. In addition, since open-source ETL technologies are frequently not backed by for-profit businesses, their maintenance, documentation, usability, and usefulness can vary.
As argued by Toan et al. in their paper, a data integration solution with a GUI, can facilitate the ETL process and lessen the manual workload associated with the ETL design process. However, GUI-based technologies frequently lack the flexibility needed to handle complex transformation operation needs, such as unique protocols for performing data de-duplication or incremental data loading. Additionally, it might be challenging to evaluate transformation issues with GUI-based tools since they frequently lack transparency of the underlying query commands executing the transformation.
If an establishment values control over flexibility highly, they may design an internal solution if they have the necessary development resources. The ability to create a solution that is specific to the organization’s priorities and processes is the main benefit of this approach. Popular programming languages like SQL, Python, and Java can be used for this. The primary disadvantage of this strategy is the internal resources required for testing, maintenance, and updates of a bespoke ETL tool.
Clinical Data Warehouse (CDW)
A data warehouse is a collection of old data that has been arranged for reporting and research. It makes data access easier by bringing together, and linking, data from various sources thereby making them easily accessible. One of the most crucial tools for decision-making by stakeholders across many disciplines is a data warehouse (DW). Data in the DW are combined and represented in multidimensional form, facilitating quick and simple display and analysis.
According to Wikipedia, a Clinical Data Warehouse (CDW) or Clinical Data Repository (CDR) is a real time database that consolidates data from a variety of clinical sources to present a unified view of a single patient. It is optimized to allow clinicians to retrieve data for a single patient rather than to identify a population of patients with common characteristics or to facilitate the management of a specific clinical department. Typical data types which are often found within a CDR include: clinical laboratory test results, patient demographics, pharmacy information, radiology reports and images, pathology reports, hospital admission, discharge and transfer dates, ICD-9 codes, discharge summaries, and progress notes.
The CDW can serve as a base for documenting, conducting, planning, and facilitating clinical research. Additionally, CDW improves clinical decision-making while streamlining data analysis and processing. In conventional ETL projects, the extracted and transformed data are loaded into a data warehouse (DW); however, in clinical data science, the data are loaded into a clinical data warehouse (CDW). The data imported into the CDW is as good as the clinical decision and research it is being utilized for, hence it is crucial that all parts of the ETL process are thoroughly executed.
Challenges with ETL in healthcare
It is recognized that data harmonization operations is a demanding task that consumes a lot of resources. As such, there has been a lot of work done in the past to address the challenges associated with ETL in healthcare.
According to Toan et al., the typical technical challenges of an ETL process include compatibility between the source and target data, source data quality, and scalability of the ETL process.
While many EHR systems are flexible in their design, allowing health personnel, including doctors and nurses the ability to enter information in a non-codified manner, this leads to a lack of uniformity in the data that must be integrated from various sources, which is why compatibility is a problem. There may be inconsistencies in the source system due to fields, vocabularies, and terminology that are conflicting between systems. Compatibility issues could lead to information loss if the target data system is unable to effectively integrate the source data.
Owing to the fact that health data is usually of high volume and there’s a constant updates and operational changes in the source system, designing and maintaining a tool that can adapt to the growing data size and workload, while maintaining a reasonable response time becomes challenging, hence the issue of scalability.
The data being extracted from the source may have originated from a system where the organization of the data is entirely different from the design used in the destination system. As a result, it is challenging to ensure the accuracy of the data obtained via ETL procedures. To provide end users with data that is as clear, thorough, and correct as possible, data quality issues that might range from simple misspellings in textual characteristics to value discrepancies, database constraint violations, and contradicting or missing information must be eliminated.
The first step in resolving these problems is acknowledging their existence and realizing that you will probably encounter many of them when creating an ETL solution. By concentrating and extracting the data that satisfy the requirements of CDW stakeholders and storing them in a certain format, data quality may be ensured.
As argued by Fred Nunes in his blog post, the absence of high-quality data pipelines at the moment is the biggest barrier to the widespread adoption of the available cutting-edge approaches in the healthcare sector. This obstacle is not inherent to the industry, nor is it connected to its practitioners or patients
Conclusion
In this series, we went over the fundamentals of ETL before showing how it is applied in healthcare. Then, we examined the ETL tools and the integration of the extracted data into a repository as the process’s final output. I made the point that ETL in clinical data science and healthcare is sensitive to data integrity and quality since low-quality data can have a detrimental effect on an organization’s decision-making process or the results of the study the data is utilized for. The complexity of clinical data structure and diversity of medical operations requires implementation of complex ETL before the data are loaded into CDW storage.
References
Data Pipelines in the Healthcare Industry (daredata.engineering)
A Survey of Extract-Transform-Load Technology. (researchgate.net)
ETL Challenges within Healthcare Business Intelligence — Health IT Answers
13 Best ETL Tools for 2022 (hubspot.com)
ETL Testing Data Warehouse Testing Tutorial (A Complete Guide) (softwaretestinghelp.com)
CLINICAL DATA WAREHOUSE: A REVIEW (researchgate.net)
Clinical data repository — Wikipedia
ETL in the Context of Clinical Data Science was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/c8Y73sx
via RiYo Analytics






No comments