https://ift.tt/MGP5Y6z The use of transformer architectures provides advantages not only in terms of speed, but also in some specific types...
The use of transformer architectures provides advantages not only in terms of speed, but also in some specific types of object detection problems
The state of art transformers techniques were used for object detection problems in the “DETR: End-to-End Object Detection with Transformers” paper that is published by Facebook’s research team. This algorithm has many advantages over classical object recognition techniques. By using this algorithm, an example object detection problem has been solved with python in the later stages of the article.

Many solution methods have been created by using different approaches in object detection problems. There is a two-stage architecture that consists of classification and regression stages for the detection of the target object in the first approach. Selective Search or Region Proposal Net (RPN) is used for generating region proposal in the first stage. Afterwards, classification and regression processes are performed. R-CNN, Fast R-CNN and Faster R-CNN are the most well-known algorithms of this architecture. Although the accuracy rates of these algorithms are high (especially for tiny objects), they are not at the desired level in terms of speed. In another approach, object detection is completed in a single stage. Selective search or RPN is not used in this method. There is a single neural network model for object detection process. Although it is a much faster technique than the first method, it has relatively worse performance in detecting small-sized objects.
A new technique was introduced by the Facebook research team in an article called End-to-End Object Detection with Transformers in 2020. It was announced that a new object detection model was created using Transformers architectures, which are generally used in NLP (Natural Language Processing) solutions.
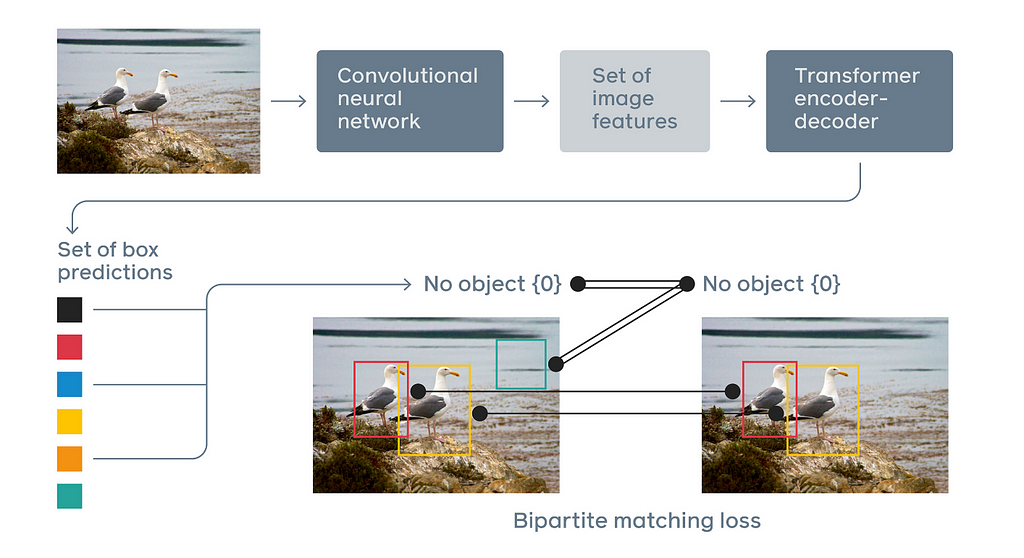
The DETR architecture basically consists of three layers (Figure 1).
- The CNN layers are used to extract features from the image (Backbone)
- Encoder-decoder structure in Transformer
- To a set loss function which performs bipartite matching between predicted and ground-truth objects
In the first stage, feature maps are extracted from the images via a Backbone layer. Many different models can be used, such as RestNet-50 or ResNet-101. In this way, 2-dimensional structure information is preserved. In the following stages, the data is flattened, so we get a 1-dimensional structure. After positional encoding, it is transferred to the encoder-decoder mechanism. Finally, each output is forwarded to the Feed Forward Network.
The last layer consists of 3 nodes. The normalized center coordinates of the predicted object and the predicted height and width values of the object are obtained where the Relu activation function is used. The class of the relevant object is predicted where the softmax activation function is used in the node. Thus, there is no need for Non-Maximum Suppression (NMS).
Suppression (NMS): It is one of the basic topic of object recognition algorithms. During the prediction of the model, the target object can be estimated with more than one frame. Some of these frames may be slanted, and some may be too large. With NMS, the most suitable one is selected among these types of frames. Intersection of Union value is used for this process.
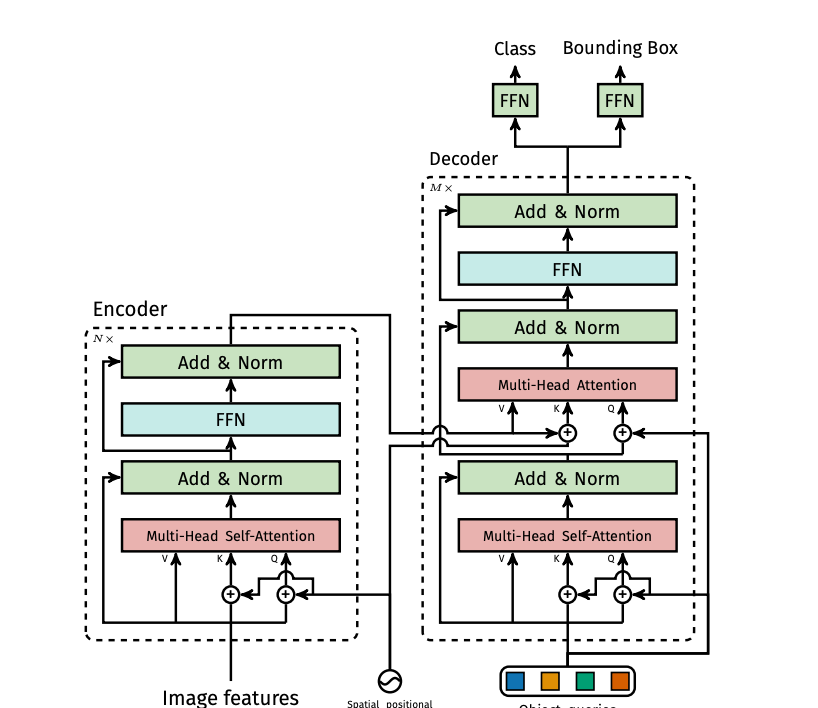
In the Positional Encoding section, the vector of each element (or token in NLP world) is re-created according to its place in the array. Thus, the same word can have different vectors at different positions in the array.
In the encoder layer, the reduction of high-dimensional feature matrix to lower-dimensional feature matrices is performed. It consists of multi-head self attention, normalizer and feed forward network modules in each encoder layer.
In the decoder layer, there are multi-head self attention, normalizer and feed forward network modules just like the encoder. N number of object queries are converted as output embedding. In the next stage, final estimation processes are carried out with the feed forward network.
Note: Since a more comprehensive work will be conducted about transformer architectures, these sections are short. However if you want to get more detailed information on the transformer, you can access the relevant article here.
The use of transformer architectures provides a great advantage not only in terms of speed but also in some specific type of problems for object detection problems. The prediction is made according to the image content of the object detection algorithm via this architecture. Thus, higher success is achieved with this approach where the context is important in the images. When recurrent neural networks are used for object detection projects, it has been seen that the accuracy is lower and the model runs slower. Because the operations are sequential. Since these operations are carried out in parallel from transformer architectures, we get a much faster model.
Python Project
The dataset to be used in the project has been downloaded from Kaggle. It can be accessed here. The dataset is MIT-licensed on Kaggle. If you want to get detailed information, you can use this link .

There are different types of wheat in this dataset (Figure 3). It is aimed to detect these wheat types correctly in this project. The repository is used to easily complete training and prediction processes (https://github.com/ademakdogan/plant_detector). The raw labeled data can be seen in Figure 4 when the dataset is downloaded.

First of all, this labeling structure should be changed in accordance with the repository. As a result of this changing, the columns names should be image_name, page_width, page_height, x, y, width, height, labels respectively in csv file. The converted version of the csv file can be seen in Figure 5.
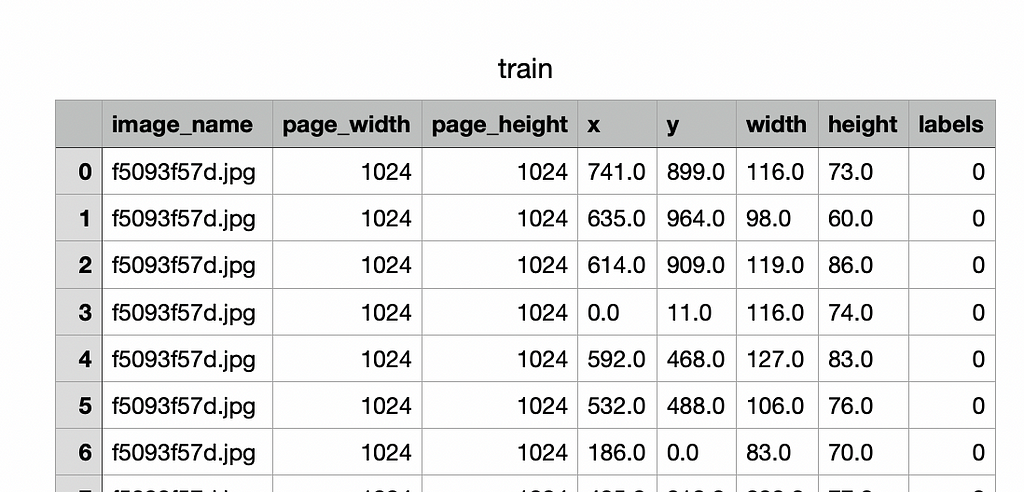
It should be noted here that the image name is written with its extension in the image_name column. In fact, this repository can be easily used for all object detection projects where the available data can be changed in this format. It will be sufficient to write a converter that only converts the data to the above format.
1- Data Preparation
The data obtained must be adapted to the DETR algorithm. The following code can be used for this.
For training:
python data_preparation.py -c /Users/.../converted_train.csv -i True
For testing:
python data_preparation.py -c /Users/.../converted_test.csv -i False
After running the python script named data_preparation, custom_train.json and custom_test.json files are created under the folder that it is named /data/json_files. If there is no problem in the creation of the files, the training phase is started.
2- Training
The training can also be done simply with the following code below. Before starting the training, the parameters in the config.json file can be changed as you needed.
python train.py -n <train_image_folder_path> -t <test_image_folder_path>
As a result of the training process, the following results are obtained.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.326
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.766
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.229
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.283
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.410
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.020
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.161
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.465
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.406
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.569
When the results are analyzed, it is clearly seen that the success is not very high due to the low epoch. It is clear that higher accuracy will be achieved when the max_steps parameter is increased in the config.json. However, depending on the hardware power, the training time will increase. Training can also be done via docker.
make docker
A new docker image is created with the above command in the project’s home directory. The name of this docker image is “detr” by default. If the image name is desired to be changed, the makefile can be used. After the necessary installations are made automatically, the training process is started with the following command.
make docker_run v=<full_path_of_the_project> n=<train_image_folder_path> t=<test_image_folder_path>
As a result of this process, a model file named model.ckpt is created under the model folder. Afterwards, prediction processes are performed using this model.
3- Prediction
Many different predicting scenarios can be created using the model that it is obtained as a result of training. The following command can be used for example prediction usage in the project.
python prediction.py -p /Users/..../test/sample.jpg
The result can be seen below.

Conclusion
End-to-End Object Detection with Transformers (DETR) method was analyzed and compared with other object detection methods in this work. General information about the layers that make up the architecture is given. The feature was extracted with the ResNet architecture in the first stage. The Transformer layer was used for encoder-decoder mechanism in the second one after that loss value was calculated using bipartite matching technique. DETR is fast due to its parallel processing capability and not using restrictive techniques such as anchor boxes and NMS. In addition, it is more powerful than other object detection architectures in cases where the content is important in the image. In order to set an example for this situation, a sample project was made with the Global Wheat Detection dataset. The objects to be detected are generally related to each other; thus, the model was able to make detections despite the small number of epochs.
Python was used for the sample project. The codes are shared so that this architecture can be used much more easily. The codes are available at https://github.com/ademakdogan/plant_detector . The dataset (MIT-licensed) downloaded from Kaggle and it was used for our example project. Data preprocess, training and prediction stages were explained step by step in this project.
Different object detection algorithms will be discussed in more detail in future articles.
Github : https://github.com/ademakdogan
Linkedin : https://www.linkedin.com/in/adem-akdo%C4%9Fan-948334177/
References
[1] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko. End-to-End Object Detection with Transformers. 2020
[2] https://github.com/facebookresearch/detr
[3] Xipeng Cao, Peng Yuan, Bailan Feng, Kun Niu. CF-DETR: Coarse-to-Fine Transformers for End-to-End Object Detection. 2022
DETR: End-to-End Object Detection with Transformers and Implementation of Python was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/UnF9YmR
via RiYo Analytics







No comments