https://ift.tt/oidT8xc What every data scientist should know about the shell It is now 50 years old, and we still can’t figure out what to...
What every data scientist should know about the shell
It is now 50 years old, and we still can’t figure out what to call it. Command line, shell, terminal, bash, prompt, or console? We shall refer to it as the command line to keep things consistent.
The article will focus on the UNIX-style (Linux & Mac) command line and ignore the rest (like Windows’s command processor and PowerShell) for clarity. We have observed that most data scientists are on UNIX-based systems these days.
What is it?
The command line is a text-based interface to your computer. You can think of it kind of as “popping the hood” of an operating system. Some people mistake it as just a relic of the past but don’t be fooled. The modern command line is rocking like never before!
Back in the day, text-based input and output were all you got (after punch cards, that is). Like the very first cars, the first operating systems didn’t even have a hood to pop. Everything was in plain sight. In this environment, the so-called REPL (read-eval-print loop) methodology was the natural way to interact with a computer.
REPL means that you type in a command, press enter, and the command is evaluated immediately. It is different from the edit-run-debug or edit-compile-run-debug loops, which you commonly use for more complicated programs.
Why would I use it?
The command line generally follows the UNIX philosophy of “Make each program do one thing well”, so basic commands are very straightforward. The fundamental premise is that you can do complex things by combining these simple programs. The old UNIX neckbeards refer to “having a conversation with the computer.”
Almost any programming language in the world is more powerful than the command line, and most point-and-click GUIs are simpler to learn. Why would you even bother doing anything on the command line?
The first reason is speed. Everything is at your fingertips. For telling the computer to do simple tasks like downloading a file, renaming a bunch of folders with a specific prefix, or performing a SQL query on a CSV file, you really can’t beat the agility of the command line. The learning curve is there, but it is like magic once you have internalized a basic set of commands.
The second reason is agnosticism. Whatever stack, platform, or technology you are currently using, you can interact with it from the command line. It is like the glue between all things. It is also ubiquitous. Wherever there is a computer, there is also a command line somewhere.
The third reason is automation. Unlike in GUI interfaces, everything done in the command line can eventually be automated. There is zero ambiguity between the instructions and the computer. All those repeated clicks in the GUI-based tools that you waste your life on can be automated in a command-line environment.
The fourth reason is extensibility. Unlike GUIs, the command line is very modular. The simple commands are perfect building blocks to create complex functionality for myriads of use-cases, and the ecosystem is still growing after 50 years. The command line is here to stay.
The fifth reason is that there are no other options. It is common that some of the more obscure or bleeding-edge features of a third party service may not be accessible via GUI at all and can only be used using a CLI (Command Line Interface).
How does it work?
There are roughly four layers in how the command-line works:
Terminal = The application that grabs the keyboard input passes it to the program being run (e.g. the shell) and renders the results back. As all modern computers have graphical user interfaces (GUI) these days, the terminal is a necessary GUI frontend layer between you and the rest of the text-based stack.
Shell = A program that parses the keystrokes passed by the terminal application and handles running commands and programs. Its job is basically to find where the programs are, take care of things like variables, and also provide fancy completion with the TAB key. There are different options like Bash, Dash, Zsh, and Fish, to name a few. All with slightly different sets of built-in commands and options.
Command = A computer program interacting with the operating system. Common examples are commands like ls, mkdir, and rm. Some are prebuilt into the shell, some are compiled binary programs on your disk, some are text scripts, and some are aliases pointing to another command, but at the end of the day, they are all just computer programs.
Operating system = The program that executes all other programs. It handles the direct interaction with all the hardware like the CPU, hard disk, and network.
The prompt and the tilde

The command line tends to look slightly different for everyone.
There is usually one thing in common, though: the prompt, likely represented by the dollar sign ($). It is a visual cue for where the status ends and where you can start typing in your commands.
On my computer, the command line says:
juha@ubuntu:~/hello$
The juha is my username, ubuntu is my computer name, and ~/hello is my current working directory.
And what’s up with that tilde (~) character? What does it even mean that the current directory is ~/hello?
Tilde is shorthand for the home directory, a place for all your personal files. My home directory is /home/juha, so my current working directory is /home/juha/hello, which shorthands to ~/hello. (The convention ~username refers to someone's home directory in general; ~juha refers to my home directory and so on.)
From now on, we will omit everything else except the dollar sign from the prompt to keep our examples cleaner.
The anatomy of a command
Earlier, we described commands simply as computer programs interacting with the operating system. While correct, let’s be more specific.
When you type something after the prompt and press enter, the shell program will attempt to parse and execute it. Let’s say:
$ generate million dollars generate: command not found
The shell program takes the first complete word generate and considers that a command.
The two remaining words, million and dollars, are interpreted as two separate parameters (sometimes called arguments).
Now the shell program, whose responsibility is to facilitate the execution, goes looking for a generate command. Sometimes it is a file on a disk and sometimes something else. We'll discuss this in detail in our next chapter.
In our example, no such command called generate is found, and we end up with an error message (this is expected).
Let’s run a command that actually works:
$ df --human-readable
Filesystem Size Used Avail Use% Mounted on
sysfs 0 0 0 - /sys
proc 0 0 0 - /proc
udev 16G 0 16G 0% /dev
. . .
Here we run a command “ df" (short for disk free) with the "--human-readable" option.
It is common to use “-” (dash) in front of the abbreviated option and “ — “ (double-dash) for the long-form. (These conventions have evolved over time; see this blog post for more information.)
For example, these are the same thing:
$ df -h
$ df --human-readable
You can generally also merge multiple abbreviated option after a single dash.
df -h -l -a
df -hla
Note: The formatting is ultimately up to each command to decide, so don’t assume these rules as universal.
Since some characters like space or backslash have a special meaning, it is a good idea to wrap string parameters into quotes. For bash-like shells, there is a difference between single (‘) and double-quotes (“), though. Single quotes take everything literally, while double quotes allow the shell program to interpret things like variables. For example:
$ testvar=13
$ echo "$testvar"
13
$ echo '$testvar'
$testvar
If you want to know all the available options, you can usually get a listing with the --help parameter:
Tip: The common thing to type into the command line is a long file path. Most shell programs offer TAB key to auto-complete paths or commands to avoid repetitive typing. Try it out!
The different types of a command
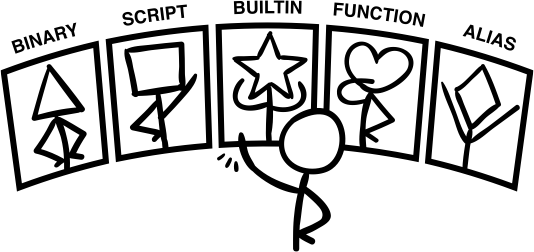
There are five different types of commands: binary, script, builtin, function, and alias.
We can split them into two categories, file-based and virtual.
Binary and script commands are file-based and executed by creating a new process (an operating system concept for a new program). File-based commands tend to be more complex and heavyweight.
Builtins, functions, and aliases are virtual, and they are executed within the existing shell process. These commands are mostly simple and lightweight.
A binary is a classic executable program file. It contains binary instructions only understood by the operating system. You’ll get gibberish if you try to open it with a text editor. Binary files are created by compiling source code into the executable binary file. For example, the Python interpreter command python is a binary executable.
For binary commands, the shell program is responsible for finding the actual binary file from the file system that matches the command name. Don’t expect the shell to go looking everywhere on your machine for a command, though. Instead, the shell relies on an environment variable called $PATH, which is a colon-delimited (:) list of paths to iterate over. The first match is always chosen.
To inspect your current $PATH, try this:
If you want to figure out where the binary file for a certain command is, you can call the which command.
$ which python /home/juha/.pyenv/shims/python
Now that you know where to find the file, you can use the file utility to figure out the general type of the file.
$ file /home/juha/.pyenv/shims/pip
/home/juha/.pyenv/shims/pip: Bourne-Again shell script text executable, ASCII text
$ file /usr/bin/python3.9
/usr/bin/python3.9: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, stripped
A script is a text file containing a human-readable program. Python, R, or Bash scripts are some common examples, which you can execute as a command.
Usually we do not execute our Python scripts as commands but use the interpreter like this:
$ python hello.py
Hello world
Here python is the command, and hello.py is just a parameter for it. (If you look at what python --help says, you can see it corresponds to the variation "file: program read from script file", which really does make sense here.)
But we can also execute hello.py as directly as a command:
$ ./hello.py
Hello world
For this to work, we need two things. Firstly, the first line of hello.py needs to define a script interpreter using a special #! Notation.
#!/usr/bin/env python3
print("Hello world")
The #! notation tells the operating system which program knows how to interpret the text in the file and has many cool nicknames like shebang, hashbang, or my absolute favorite the hash-pling!
The second thing we need is for the file to be marked executable. You do that with the chmod (change mode) command: chmod u+x hello.py will set the eXecutable flag for the owning User.
A builtin is a simple command hard-coded into the shell program itself. Commands like cd, echo, alias, and pwd are usually builtins.
If you run the help command (which is also a builtin!), you'll get a list of all the builtin commands.
A function is like an extra builtin defined by the user. For example:
$ hello() { echo 'hello, world'; }
Can be used as a command:
$ hello
hello, world
If you want to list all the functions currently available, you can call (in Bash-like shells):
Aliases are like macro. A shorthand or an alternative name for a more complicated command.
For example, you want new command showerr to list recent system errors:
$ alias showerr="cat /var/log/syslog"
$ showerr
Apr 27 10:49:20 juha-ubuntu gsd-power[2484]: failed to turn the kbd backlight off: GDBus.Error:org.freedesktop.UPower.GeneralError: error writing brightness
. . .
Since functions and aliases are not physical files, they do not persist after closing the terminal and are usually defined in the so-called profile file ~/.bash_profile or the ~/.bashrc file, which are executed when a new interactive or login shell is started. Some distributions also support a ~/.bash_aliases file (which is likely invoked from the profile file -- it's scripts all the way down!).
If you want to get a list of all the aliases currently active for your shell, you can just call the alias command without any parameters.
Combining commands together
Pretty much anything that happens on your computer happens inside processes. Binary and script commands always start a new process. Builtins, functions, and aliases piggyback on the existing shell program’s process.
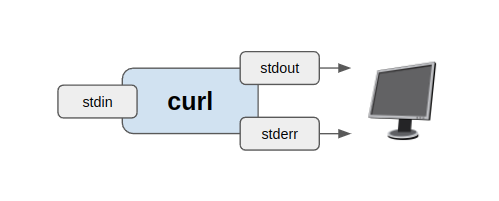
A process is an operating system concept for running an instance of a command (program). Each process gets an ID, its own reserved memory space, and security privileges to do things on your system. Each process also has a standard input ( stdin), standard output ( stdout), and standard error ( stderr) streams.
What are these streams? They are simply arbitrary streams of data. No encoding is specified, which means it can be anything. Text, video, audio, morse-code, whatever the author of the command felt appropriate. Ultimately your computer is just a glorified data transformation machine. Thus it makes sense that every process has an input and output, just like functions do. It also makes sense to separate the output stream from the error stream. If your output stream is a video, then you don’t want the bytes of the text-based error messages to get mixed with your video bytes (or, in the 1970s, when the standard error stream was implemented after your phototypesetting was ruined by error messages being typeset instead of being shown on the terminal).
By default, the stdout and stderr streams are piped back into your terminal, but these streams can be redirected to files or piped to become an input of another process. In the command line, this is done by using special redirection operators (|,>,<,>>).
Let’s start with an example. The curl command downloads an URL and directs its standard output back into the terminal as default.
$ curl https://filesamples.com/samples/document/csv/sample1.csv
"May", 0.1, 0, 0, 1, 1, 0, 0, 0, 2, 0, 0, 0
"Jun", 0.5, 2, 1, 1, 0, 0, 1, 1, 2, 2, 0, 1
"Jul", 0.7, 5, 1, 1, 2, 0, 1, 3, 0, 2, 2, 1
"Aug", 2.3, 6, 3, 2, 4, 4, 4, 7, 8, 2, 2, 3
"Sep", 3.5, 6, 4, 7, 4, 2, 8, 5, 2, 5, 2, 5
Let’s say we only want the first three rows. We can do this by piping two commands together using the piping operator (|). The standard output of the first command ( curl) is piped as the standard input of the second ( head). The standard output of the second command ( head) remains output to the terminal as a default.
$ curl https://filesamples.com/samples/document/csv/sample1.csv | head -n 3
"May", 0.1, 0, 0, 1, 1, 0, 0, 0, 2, 0, 0, 0
"Jun", 0.5, 2, 1, 1, 0, 0, 1, 1, 2, 2, 0, 1
"Jul", 0.7, 5, 1, 1, 2, 0, 1, 3, 0, 2, 2, 1
Usually, you want data on the disk instead of your terminal. We can achieve this by redirecting the standard output of the last command ( head) into a file called foo.csv using the > operator.
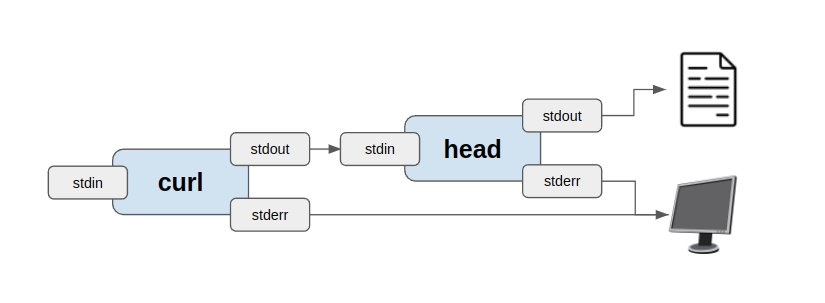
$ curl https://filesamples.com/samples/document/csv/sample1.csv | head -n 3 > foo.csv
Finally, a process always returns a value when it ends. When the return value is zero (0), we interpret it as successful execution. If it returns any other number, it means that the execution had an error and quit prematurely. For example, any Python exception which is not caught by try/except has the Python interpreter exit with a non-zero code.
You can check what the return value of the previously executed command was using the $? variable.
$ curl http://fake-url
curl: (6) Could not resolve hostmm
$ echo $?
6
Previously we piped two commands together with streams, which means they ran in parallel. The return value of a command is important when we combine two commands together using the && operator. This means that we wait for the previous command to succeed before moving on to the next. For example:
cp /tmp/apple.png /tmp/usedA.png && cp /tmp/apple.png /tmp/usedB.png && rm /tmp/apple.png
Here we try to copy the file /tmp/apple to two different locations and finally delete the original file. Using the && operator means that the shell program checks for the return value of each command and asserts that it is zero (success) before it moves. This protects us from accidentally deleting the file at the end.
If you’re interested in writing longer shell scripts, now is a good time to take a small detour to the land of the Bash “strict mode” to save yourself from a lot of headache.
Manage data science projects like a boss

Often when a data scientist ventures out into the command line, it is because they use the CLI (Command Line Interface) tool provided by a third party service or a cloud operator. Common examples include downloading data from the AWS S3, executing some code on a Spark cluster, or building a Docker image for production.
It is not very useful to always manually memorize and type these commands over and over again. It is not only painful but also a bad practice from a teamwork and version control perspective. One should always document the magic recipes.
For this purpose, we recommend using one of the classics, all the way from 1976, the make command. It is a simple, ubiquitous, and robust command which was originally created for compiling source code but can be weaponized for executing and documenting arbitrary scripts.
The default way to use make is to create a text file called Makefile into the root directory of your project. You should always commit this file into your version control system.
Let’s create a very simple Makefile with just one "target". They are called targets due to the history with compiling source code, but you should think of target as a task.
Makefile
hello:
echo "Hello world!"
Now, remember we said this is a classic from 1976? Well, it’s not without its quirks. You have to be very careful to indent that echo statement with a tab character, not any number of spaces. If you don't do that, you'll get a "missing separator" error.
To execute our “hello” target (or task), we call:
$ make hello
echo "Hello world!"
Hello world!
Notice how make also prints out the recipes and not just the output. You can limit the output by using the -s parameter.
$ make -s hello
Hello world!
Next, let’s add something useful like downloading our training data.
Makefile
hello:
echo "Hello world!"
get-data:
mkdir -p .data
curl <https://filesamples.com/samples/document/csv/sample1.csv>
> .data/sample1.csv
echo "Downloaded .data/sample1.csv"
Now we can download our example training data with:
$ make -s get-data
Downloaded .data/sample1.csv
(Aside: The more seasoned Makefile wizards among our readership would note that get-data should really be named .data/sample1.csv to take advantage of Makefile's shorthands and data dependencies.)
Finally, we’ll look at an example of what a simple Makefile in a data science project could look like so we can demonstrate how to use variables with make and get you more inspired:
Makefile
DOCKER_IMAGE := mycompany/myproject
VERSION := $(shell git describe --always --dirty --long)
default:
echo "See readme"
init:
pip install -r requirements.txt
pip install -r requirements-dev.txt
cp -u .env.template .env
build-image:
docker build .
-f ./Dockerfile
-t $(DOCKER_IMAGE):$(VERSION)
push-image:
docker push $(DOCKER_IMAGE):$(VERSION)
pin-dependencies:
pip install -U pip-tools
pip-compile requirements.in
pip-compile requirements-dev.in
upgrade-dependencies:
pip install -U pip pip-tools
pip-compile -U requirements.in
pip-compile -U requirements-dev.in
This example Makefile would allow your team members to initialize their environment after cloning the repository, pin the dependencies when they introduce new libraries, and deploy a new docker image with a nice version tag.
If you consistently provide a nice Makefile along with a well-written readme in your code repositories, it will empower your colleagues to use the command line and reproduce all your per-project magic consistently.
Conclusion
At the end of the day, some love the command-line and some don’t.
It is not everyone’s cup of tea, but every data scientist should try it out and give it a chance. Even if it doesn’t find a place in your daily toolbox, it benefits to understand the fundamentals. It is nice to be able to communicate with colleagues who are command-line enthusiasts without getting intimidated by their terminal voodoo.
If the topic got you inspired, I highly recommend checking out the free book Data Science at the Command-Line by Jeroen Janssens next.
Originally published at https://valohai.com.
Data Science at the Command Line was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/OvXthBb
via RiYo Analytics









No comments