https://ift.tt/CKYeWa1 go_backwards() — Unravelling its ‘hidden’ secrets Understanding its hidden nuances & exploring its leaky nature...
go_backwards() — Unravelling its ‘hidden’ secrets
Understanding its hidden nuances & exploring its leaky nature!
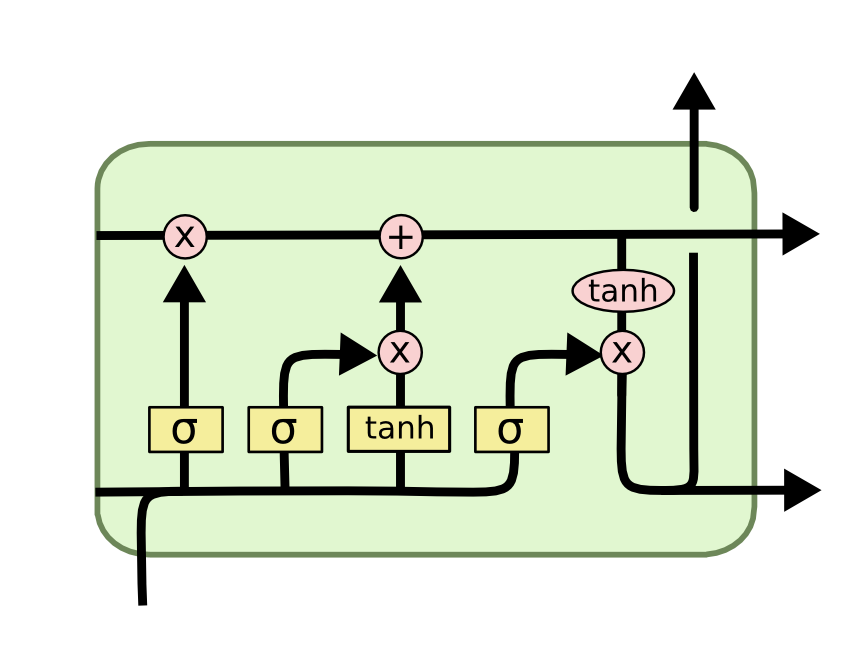
Introduction
Long Short Term Memory (LSTM) are superior versions of Recurrent Neural Networks (RNN) and are capable of storing ‘context’, as the name suggests, over relatively long sequences. This allows them to be a perfect utility for NLP tasks such as document classification, speech recognition, Named Entity Recognition (NER), etc.
In many applications, such as machine translation, speech recognition, etc., context from both sides improves the performance of the language based models. To implement this in practice, we use Bi-Directional LSTMs. However, if you need to extract the embeddings for the forward and the backward run individually, you would need to implement two separate LSTMs where the first takes in forward input and the other processes the input in the backward fashion.
To save lots of your effort, Tensorflow’s LSTM gives you the flexibility to use give the input normally while processing it in the reversed fashion internally to learn the context from right-to-left! This is made possible by putting go_backwards( )=True in the LSTM layer. In simple terms, if you have the input as [‘I’, ‘am’, ‘the’, ‘author’], then the LSTM would read it from right to left, thanks to go_backwards( ), and treats the input as [‘author’, ‘the’, ‘am’, ‘I’]. This allows the model to learn the bi-directional context!
So far so good. However, here’s a piece of caution! When you add the forward and reversed contexts in the pipeline, you tend to leak a lot of information in the process, and this can lead to the model giving ~100% accuracy during evaluation!! This is because we miss understanding the true, subtle implementation of go_backwards( ).
In this blog, I unravel the true implementation of go_backwards( ) using a real NLP example and explore how a slight change from expected behaviour of go_backwards( ) can lead to massive leaks during model evaluation!
Task: Next Word Prediction
Consider the next word prediction task where based on the current input the model needs to predict the next word. The backward direction takes in, say, word at index 2 of the original sentence, so it needs to predict the word at index 1 there!

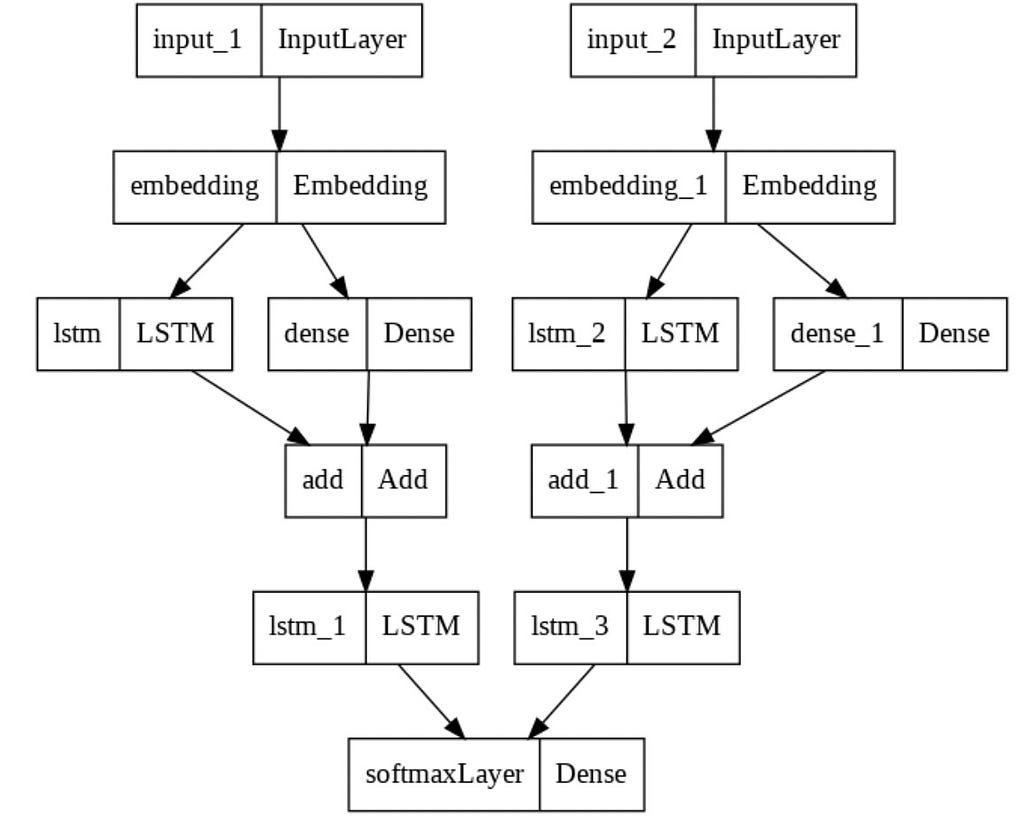
Model Architecture
Let us consider the following architecture. We have two separate inputs, one for the forward direction of LSTMs and another with backward direction.

We create or utilize pre-trained embeddings like Word2Vec, Glove, etc. for each word, pass them through the LSTMs, use a skip connection by passing the embeddings through a dense layer and adding it with LSTM1 outputs, pass the sum through another set of LSTM layer, finally going through a common Softmax layer to get the most probable prediction amongst the entire vocabulary!
Observations
The above model is trained over the IMDB training dataset over 75 epochs with decent batch size, learning rate and early stopping implemented. The model training stopped around 35 epochs due to latter. You should notice the astonishing results for the output from the backward LSTM layers!
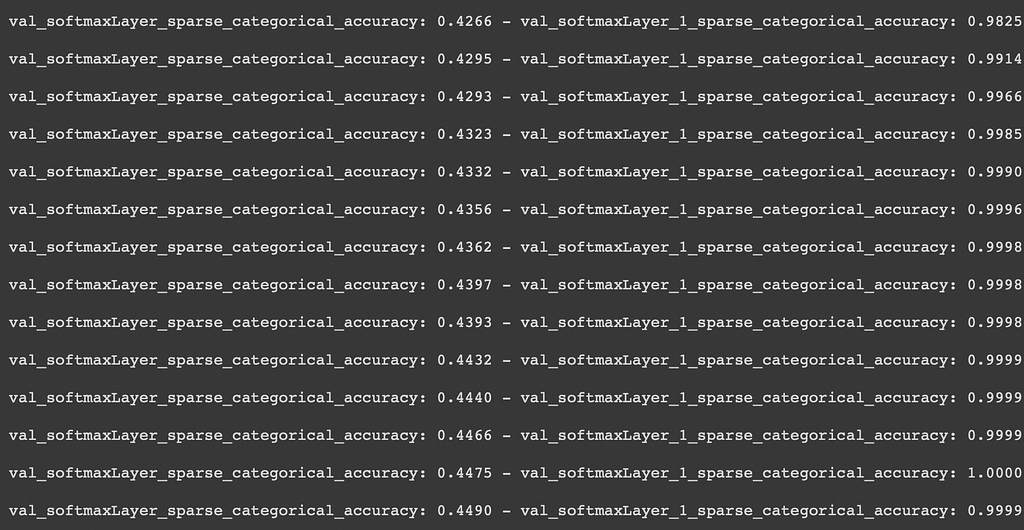
Do you notice that 100% accuracy in the second last row!!! Crazy, right? That means that the model has ‘perfectly learnt’ the right pattern to give out the output based on the input. But next word prediction is not a task that can be learned perfectly. This is like saying prediction of future is possible with 100% accuracy. 😮
But we know that there must be some leakage happening somewhere in the model that the output is already hinted at before. And that is what I realized while working my project in the course AI-3 (NLP) at Univ.AI. This revelation is the main agenda of this post — to figure the WHY behind this strange behaviour!
Something secretive about go_backwards( ) ?:
The forward direction LSTM is mostly clear through the documentation. However, the go_backwards( ) function seems a bit tricky. If you look at its documentation, you would notice that it takes the inputs sequence in the forward direction, reverses it internally and then processes it, finally giving out the reversed sequence.


However, unlike our expectations, reversing the sequence is not that straightforward in LSTMs. As per the official documentation of go_backwards( ), tf.reverse_sequence( ) is the function used to reverse the inputs and this is not a simple reverse. Rather than putting it all right to left, the function only reverse the number of tokens attributed by ‘sequence length’ and keeps rest of the sentence intact, since other tokens are pad tokens and need not be reversed!
The argument go_backwards()=True means that the LSTM layer would take in the input, reverse it using tf.reverse_sequence strategy, find the output through the LSTM layer and finally, puts the padded tokens in front!! This final reverse is made using tf.reverse().
Under-the-Hood: First LSTM
So this is what is going on under-the-hood when you put the go_backwards() argument as True in the first LSTM layer. Note that we have assumed LSTM to be an identity mapper i.e. giving output as the input. This is done for ease of representation and understanding.
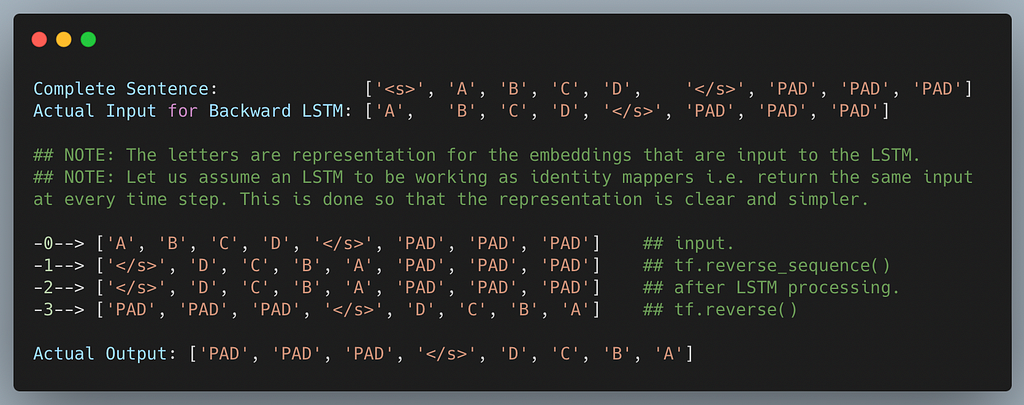
If you notice carefully, the output of the LSTM layer with go_backwards()=True is doing its task as mentioned in the documentation. The final output is actually the true reverse (in literal sense) of the output we were expecting (taking the assumption to be true)
But, rather than reversing this output, we were directly using it for a skip connection and using is down the pipeline! And this is where things go south!
Zeroing down on the issue!
In our model, we are adding the output (actually the reverse output from above xD) to the dense input just before passing it to the next backward LSTM. Let’s do a dry-run with our above example and see how things work out for the second LSTM layer with the reverse output that you get from LSTM 1:

Do you notice how the output is symmetric!! Even if we weight the additions and remove the symmetry, you won’t be able to escape the LSTM2!

Now suppose PAD=0, <s>=1, A=2, B=3, C=4, D=5, </s>=6 (numericals for simplicity) then the inputs is:

Given the input of line 0, how difficult would it be for a neural network of the worth of LSTM to find the pattern in the output? 😌 This is the reason the second LSTM layer catches up extremely fast and goes to nearly 100% validation accuracy!!
And the root of the problem was that the output of an LSTM with go_backwards()=True is reversed in nature, as mentioned in the documentation. You need to flip it before passing it through!
Experimentation
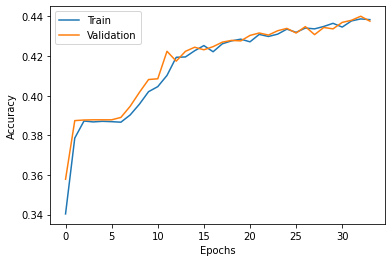
I manually flipped the outputs of the two LSTM layers, with go_backwards()=True, on axis=1 and got about 44% accuracy for both layers over 75 epochs with early stopping. Later, I observed the following results for threee different transfer learning implementations over IMDB dataset for sentiment classification:
1. Baseline: 85.75%
2. Word2Vec: 84.38%
3. ELMo: 80.17% [using embeddings from the embeddings layer, concatenated outputs of first LSTM’s forward and reverse runs, and the concatenated outputs of second LSTM.
(about 50 epochs with early stopping)

If you are interested in understanding in detail what runs under-the-hood of a fancy LSTM, check out the proceeding link:
Moral of the story!
Always carefully read the documentation before implementation! 🤓
Know your tools well before you use them! :)
LSTM go_backwards() — Unravelling its ‘hidden’ secrets was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/pe5kUFq
via RiYo Analytics





ليست هناك تعليقات