https://ift.tt/xEtQgLi Dissecting the Data Mesh Technical Platform : Exposing Polyglot Data Context and motivation No matter how we look ...
Dissecting the Data Mesh Technical Platform : Exposing Polyglot Data
Context and motivation
No matter how we look at it, data consumption is perhaps one of the central user journeys of any data platform, if not the main one. Consuming data somehow represents the culmination of all the multi-team efforts put into the platform over time: data ingestion, cataloging, transformation , quality control or skills enablement just to name a few.
At the end of the days, data consumption is the final deliverable for data teams.
Ironically, data consumption is also one of the areas that generates more friction between central IT data teams — the teams responsible for building the data platform and model its contents — and the data consumers embedded into the business areas — responsible for consuming the data and generating insights that ultimately can turn into business value.
Why is that? On one hand, data consumers expect a simple and familiar way to access the data, that needs to be workable from day one with little to none adaptation efforts. Data needs to be in their “native” format, the format in which they are used to work with. And on the other hand, the central IT teams are incentivized to generate a unique and standardized way for data consumption instead of maintaining a growing number of specific interfaces. More often than not, the standard tends to be heavily influenced by the platform underlying technology, priming technology simplicity over business users needs.
The result tends to be suboptimal for both parties, with a slightly canonical way to access the data that in the end requires extensive integration plumbing and transformation downstream in the business areas, generating technical debt for both sides.
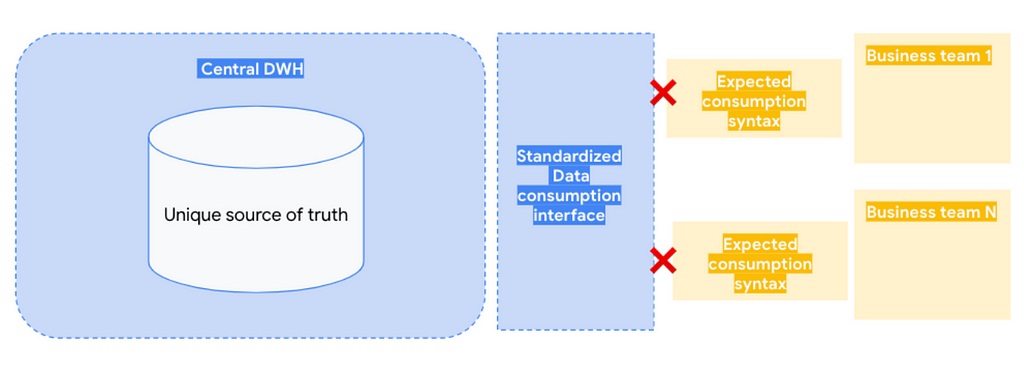
The Data Mesh answer to the data consumption problem
The Data Mesh paradigm recognizes and appreciates this tension and takes a VERY clear position in its resolution: it definitely stands up for the data consumers. Rather than imposing a standardized way to work dictated by technology, the platform should adapt to their user needs and offer the data in the most convenient way — evokating a native feeling.
We won't discuss Data Mesh in detail in this article, but in essence, it means decentralization of data ownership — transferring the responsibility from a central IT data team to the business areas where the consumption happens.
With that principle in mind, the solution to the data consumption problem can be quite simple: to transfer the consumption responsibility into the business areas. Under this scenario the consumers themselves will acquire the responsibility for generating data interfaces into their preferred native format for the data products under the business domain they own.
But as the mesh grows so do its inter-domain use cases and the need for data sharing, so we can end in a undesired situation where the data interfaces are tightly coupled to the consumers, limiting or even neglecting data product sharing among different consumers.
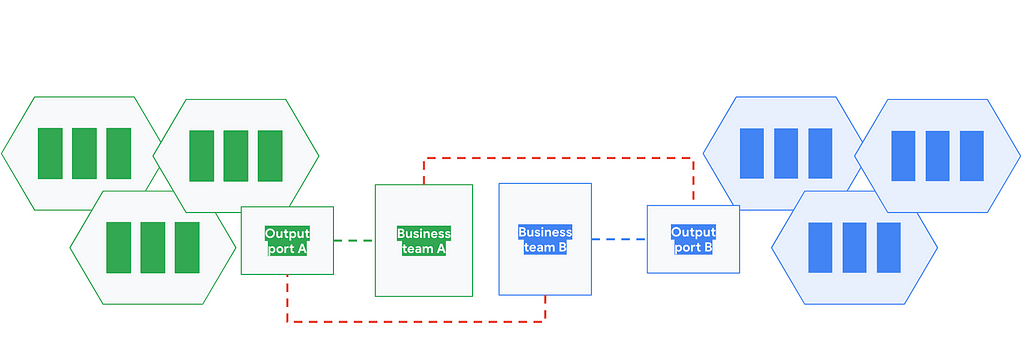
With the ultimate goal to ensure reusability, data mesh’s answer to this problem is to introduce the concept of polyglot data, an abstraction to clearly differentiate between the data semantics and the data consumption format/syntax. Under this new scenario, the data consumers could instantiate the data in their prefered format from a list of predefined consumption patterns that hopefully cover all the possible use cases.
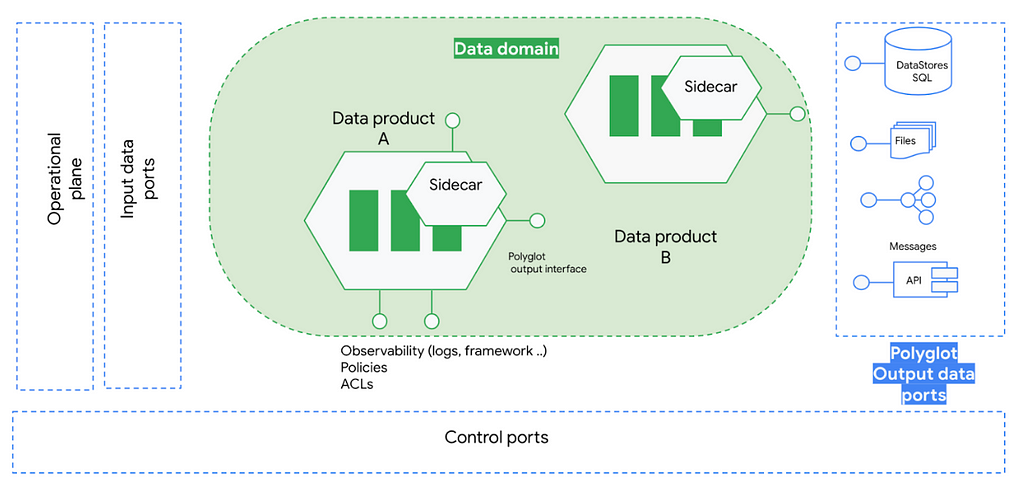
In theory, this is a very elegant approach with a very clear separation of responsibilities between data semantics and its underlying technology. But in practice as Data Mesh does not prescribe any kind of technical architecture, sometimes it can be very abstract and challenging to conceptualize or implement such a solution.
The idea of this article is to present an opinionated technology architecture that implements this polyglot data pattern running in Google Cloud using as many open source components as possible.
A polyglot data framework MVP on Google Cloud : polyexpose
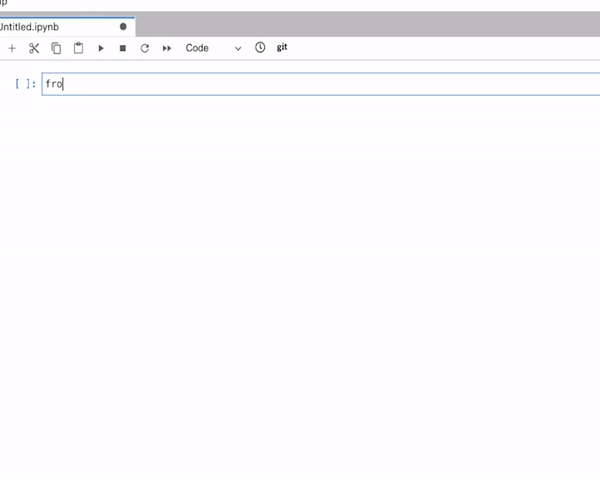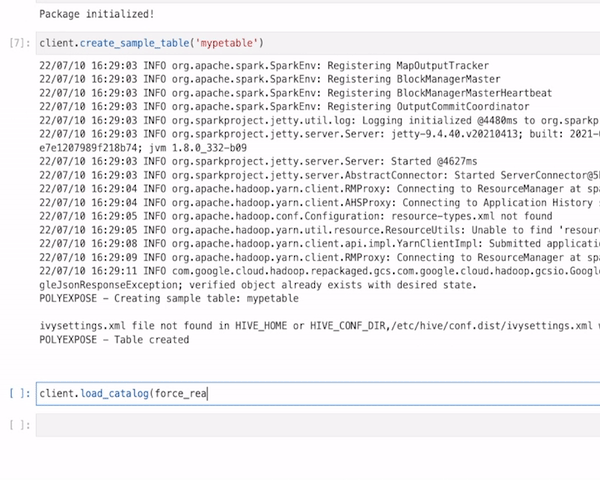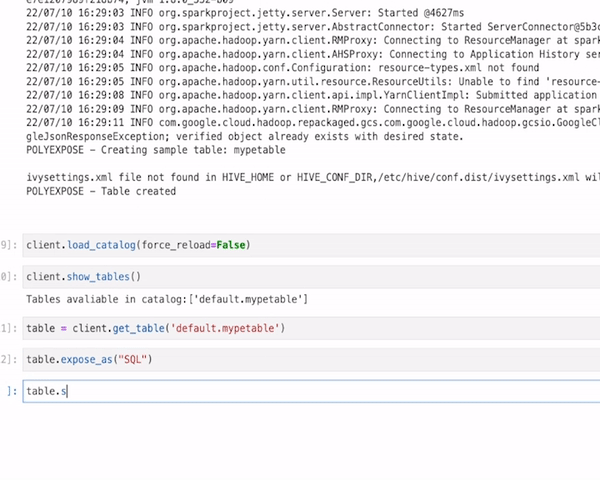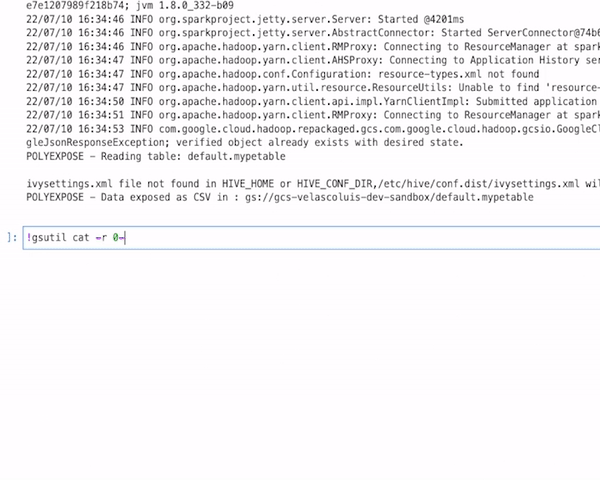
To illustrate these concepts and give some inspiration, I have built a simplistic python package — not production ready! — called `polyexpose` that orchestrates and streamline data serving with different syntaxes making use of different cloud technologies like Google Cloud Storage, SPARK, hasura or Google Kubernetes Engine.
The actual use will be to bundle this package code together with the desired data product and then letting the consumers choose their preferred consumption format for the data product.
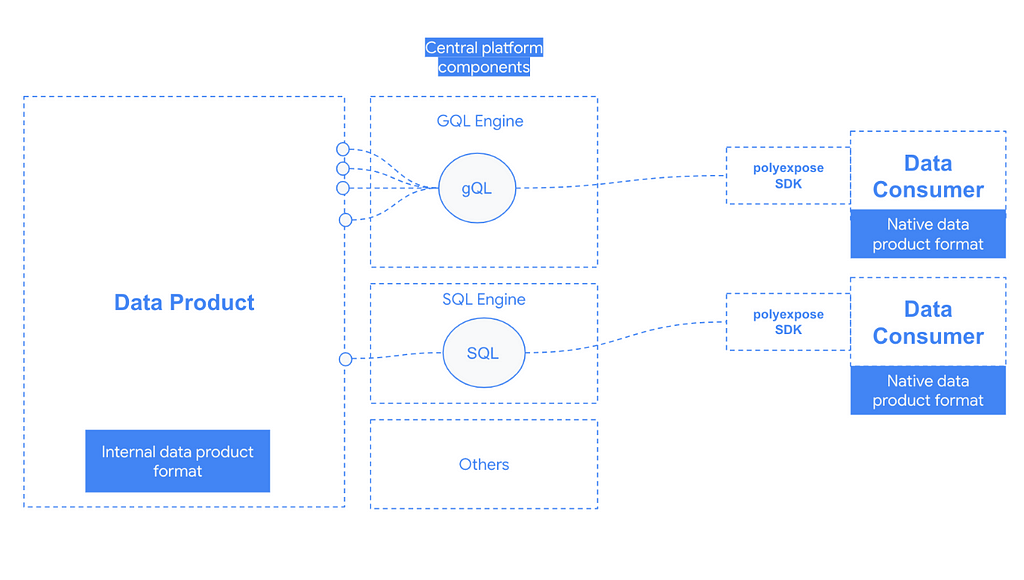
Who should own this package/code?
With Data Mesh, the central data team role shifts from “full data platform control” to a enablement role focused on “platform engineering”. In my view, the key responsibility of the redefined data team is to build artifacts/software/accelerators like ingestion frameworks, observability APIs, policy execution engines or data quality engines with the ultimate goal of enabling generic software developers in the business areas to fully embrace the data-driven benefits.
Now let's dig in this data consumption artifact. In order to define the different data syntaxes to support, I have come up with three different consumption personas that I believe are fairly generic and can be found in almost every organization.
- Data analysts — Used to work with SQL as their primary data interface
- Data application developers — APIs are the golden standard for application developers, thus we should respect that and offer an API interface to data — GQL. Another common pattern is based on event driven architectures, so we should be able to generate real time even like data from out data product.
- Data scientists — As part of the experimentation lifecycle, Data Scientists are used to load plain text files, in my experience this approach is often seen seen as an anti-pattern from the IT department lens, but again, the Data Mesh approach recognizes and celebrates the heterogeneity of data consumption patterns.
Internal polyexpose architecture
With these patterns in mind, our data exposure framework should support the following data access mechanisms.
- SQL
- GQL
- CSV
- EVENTs
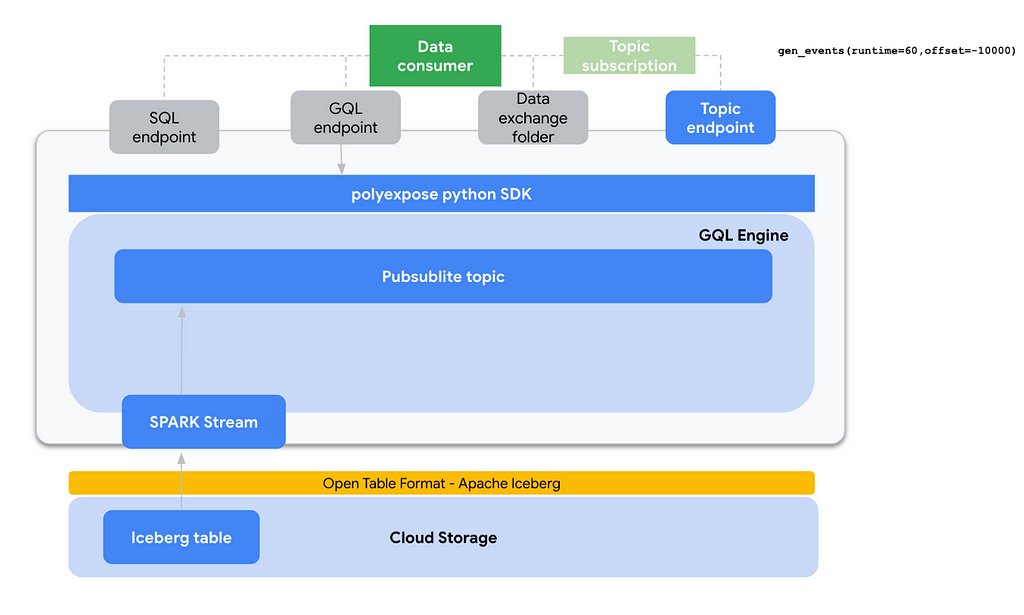
An initial technical architecture blueprint could look like this:
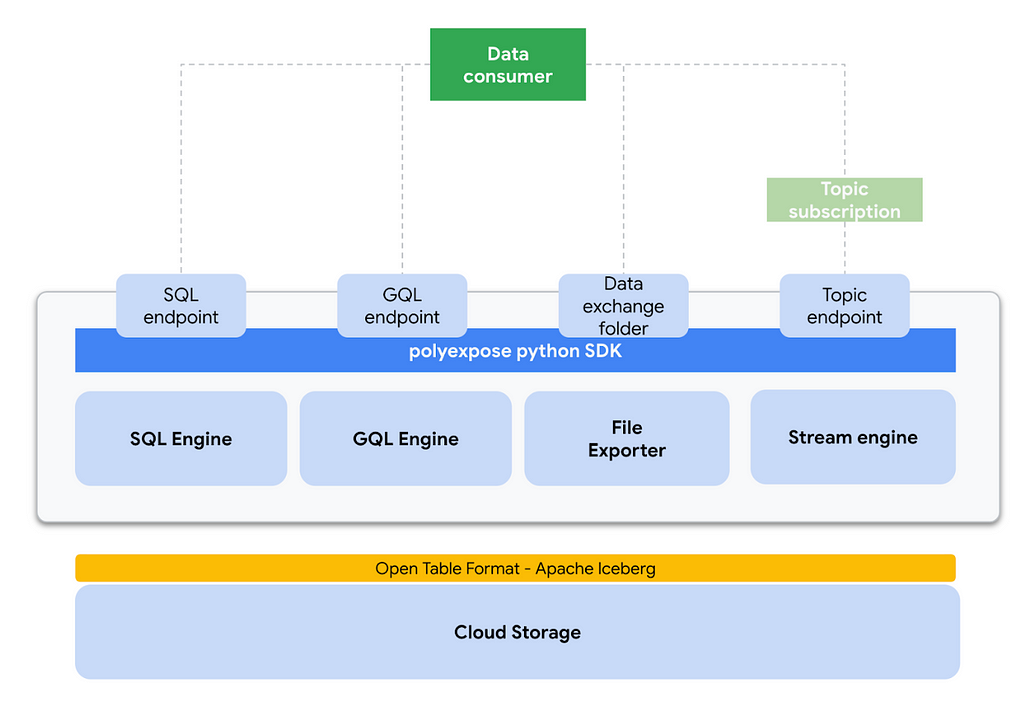
Lets now dig in every component:
- End user interface: I have chosen to bundle the software into a python package. python is without any doubt the de-facto standard for data engineering, giving to our users a very familiar interface. Regarding UX, the basic workflow of polyxpose is:
# 1 Generates polyexpose client
client = polyExpose(config.yaml)
... # 2 Execute initialization actions (e.g. load catalog)
# 3 Select table
table = client.get_table("table_name")
# 4 Enable exposure mode
EXPOSE_MODE = SQL | GQL | CSV | EVENT
table.expose_as(EXPOSE_MODE)
# 5 Access data via SQL query, pub/sub client, reading CSV or calling a GQL API
For more detailed information check this notebook with and end to end run.
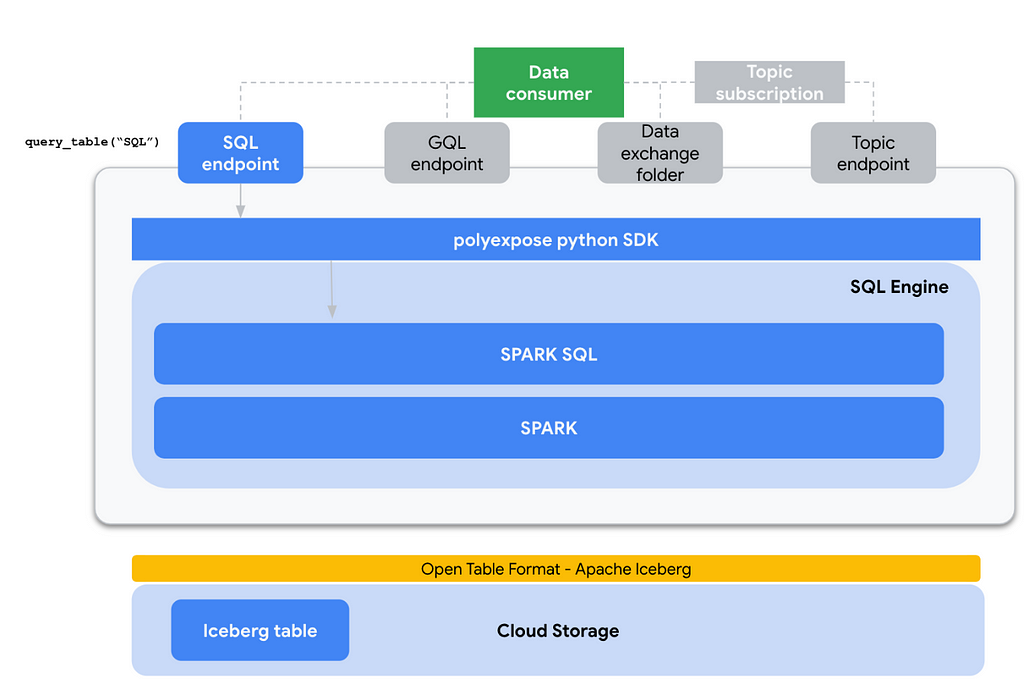
- Primary data storage: At the very core of the implementation, I have chosen Apache Iceberg as the internal table format for analytic tables. Iceberg is tightly integrated with engines like Spark and brings a number of great features like schema evolution, time travel, hidden partitioning or scan planning and file filtering. The Iceberg tables are deployed on Google Cloud Storage.
- SQL interface: Since we are using Iceberg for internal data representation, SPARK SQL seems to be the default choice for exposing a SQL engine to end users. We basically use a GCP dataproc cluster where a number of predefined spark templates are already deployed, the SPARK SQL execution is one of them.
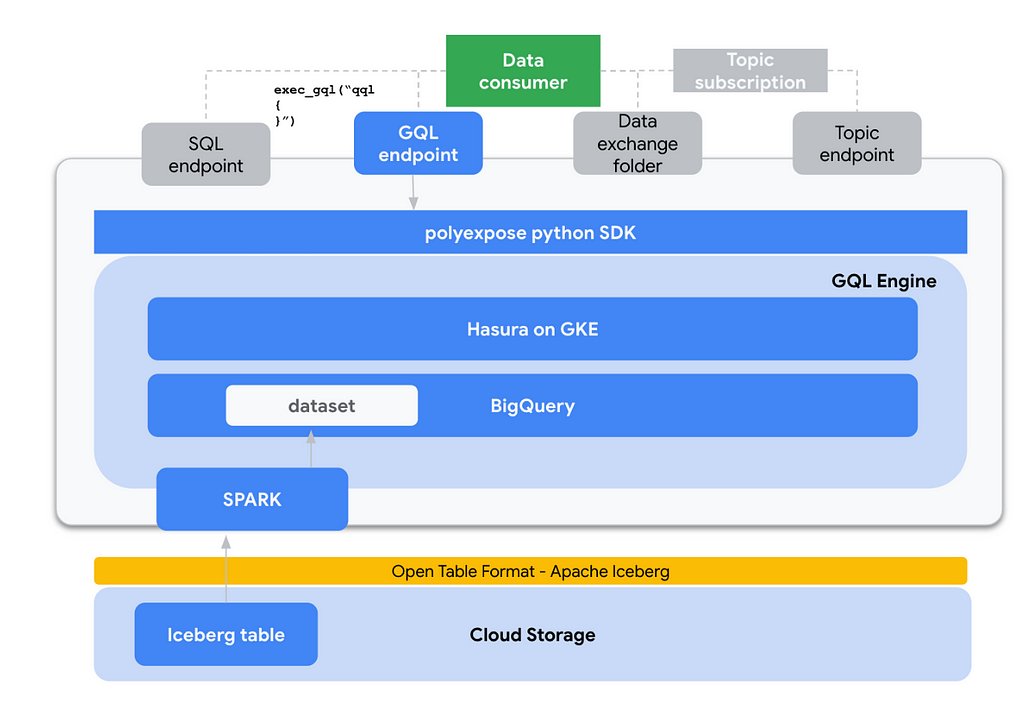
- GQL interface: This one is a bit more tricky to implement as under the hood the GQL interface is exposed using the hasura graphQL engine. At the time of development, hasura supported backends are Postgres and BigQuery, so when exposing data via the GQL interface there is and additional step that copies the data from GCS / Iceberg to BigQuery, then using the hasura API we generate a new connection to BQ and track the data.
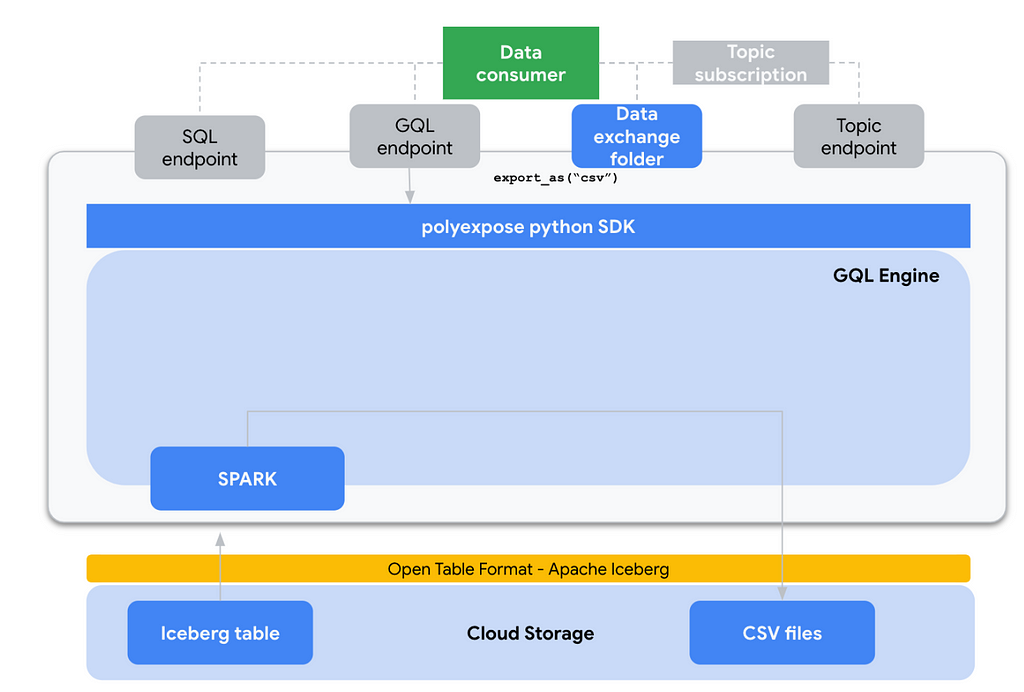
- CSV interface: We just use SPARK for mutating the data frame format, reading the Iceberg Tables and writing in plain CSV also in Google Cloud Storage.
- Events interface: This expose mode uses a pubsublite topic (KAFKA-compatible) in conjunction with SPARK Structured streaming to offer the data in a real time event fashion. It needs the client to generate a subscription to the topic.
Conclusions and future work
In this article, we have explored the challenges associated with data consumption in a traditional centralized DWH architecture and how the Data Mesh paradigm proposes a solution: the polyglot data output port abstraction, a great conceptual idea to clearly differentiate between data semantics and technical details of its consumption. Then with the objective of inspire readers I have shown a technical framework called `polyexpose` for implementing this pattern using Google Cloud and open source components.
The `polyexpose` repository contains JUST an inspirational architecture for exposing data in different syntaxes, but it is far from being a productive solution, requiring extensive work on security or access controls unification just to name a few areas. Apart from that, other interesting areas I’d be looking at into the future are:
- Implementation of data contracts
- Implementation of global policies on different technologies
Dissecting the Data Mesh technical platform : Exposing polyglot data was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/qR16rga
via RiYo Analytics








No comments