https://ift.tt/svaJG5e Building machine learning models in the cloud: A paradigm shift Distinguishing between persistent and ephemeral com...
Building machine learning models in the cloud: A paradigm shift
Distinguishing between persistent and ephemeral compute for machine learning development

In 2017, I ran my first machine learning (ML) model in the cloud, however, at that time I wasn’t aware of it. From my perspective, I was simply connecting to this thing called “the remote server” and executing my python scripts.
Today, building, training, and deploying ML models is the cloud is continuously getting commoditized. From access to scalable compute for intensive trainings, real-time inference, ML models packaged as APIs, to managed ML platforms, low-code/no-code ML solutions, AutoML, and the list goes on.
In this article I want to share some thoughts on how building machine learning models in the cloud led to a paradigm shift in terms of the underlying compute and infrastructure of these workloads.
More specifically, I will focus on what changes in the developer experience during the build phase; data exploration, model building, and model tuning (i.e., “How we build machine learning models”) while slightly touching on the deployment phase. I will intentionally keep a tool-agnostic approach, focusing less on which technical stack or cloud service to use and more on the concepts themselves.
Why is there a paradigm shift?
On one hand, demand for machine learning within organizations has increased. The number of projects increased and the size of data science teams got bigger. This led to teams requiring more compute capacity to satisfy the needs of their use cases.
On the other hand, access to the cloud lowered the barrier to cost-effective and scalable compute. Organizations were able to:
- Switch from fixed expenses (i.e., buying servers upfront) to variable expenses (i.e., a pay as you go pricing model).
- Reduce the operational overhead.
- Stop guessing the compute capacity needed by the data science teams.
The combination of these two factors led to an increased number of ML workloads in the cloud. Data science teams were used to run everything in one place; a persistent environment. Whereas the cloud provides a variety of services, each with a specific edge over the others: managed persistent remote servers running 24/7, ephemeral jobs that run and charge only for the duration of your script’s execution, serverless based services, etc.
As we moved to the cloud, most teams kept running everything in one place; a persistent cloud-based environment. Not using the right tool for the right job results in anti-patterns when running ML workloads in the cloud, an untapped potential for many teams and a need for a paradigm shift.
The journey
Chapter I: Where we started
Initially, data science teams only had access to the limited compute of their laptops and would develop everything locally. For the lucky ones they would get a second powerful machine providing them with more RAM/CPU and in some cases a GPU or two. This allowed data scientists to move beyond small and mostly tabular datasets and tackle compute intensive use cases utilizing Deep Learning or AutoML for example.

Chapter II: I can’t run this on my computer(s) anymore
As teams started hitting the limits of their physical infrastructure, they started transitioning to remote servers. This was mainly motivated by the need for more capacity, but it also allowed for “mutualization” of resources within teams. When your colleague wasn’t running their intensive computations, you could make use of the available capacity, thus reducing costs and increasing the team’s iteration speed.
Generally, these remote servers are provided by the IT department. You have to determine the capacity required for the team, too high and you pay for something you don’t use, too low and you risk running into capacity issues again. Additionally, it took time and effort (weeks to months) in order to request or buy servers on-premises, set them up and continuously manage them.
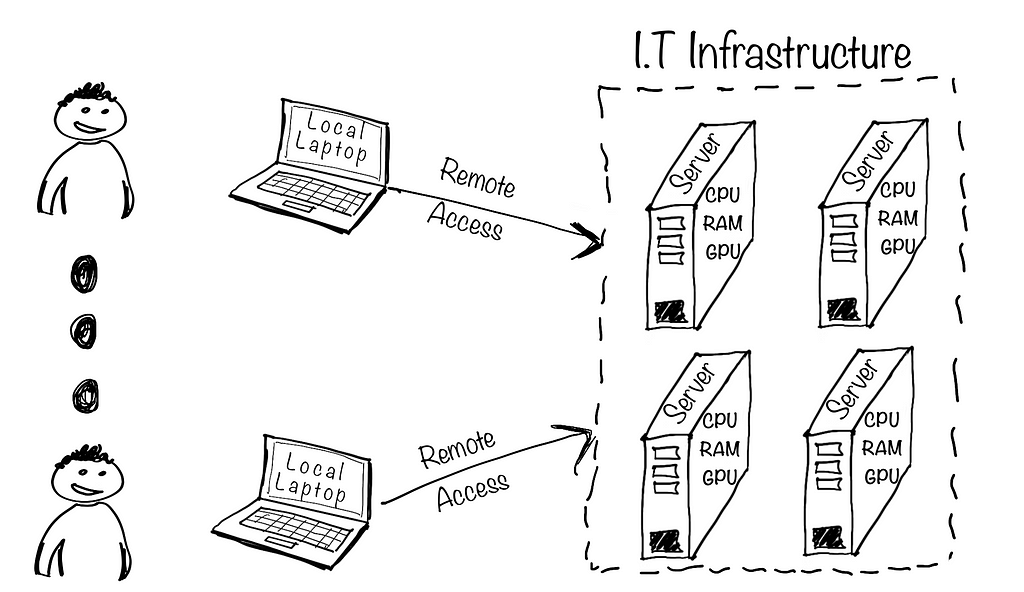
Chapter III: Moving to the cloud
Then came the cloud. Teams were now able to get access to remote servers managed by a cloud provider. If the team got bigger, you would simply increase the size of your servers with a few clicks, and if no one was using them, you would simply decrease their capacity or even shut them down. In some cases, you would even create different servers for different workloads and teams, achieving a mix of “mutualization” and segregation between teams and use cases. Moreover, cloud computing makes it easy to access a wide variety of compute instances for a variety of workloads, ranging from CPU-intensive ones, to others with hundreds of GBs of RAM and/or multiple GPUs.
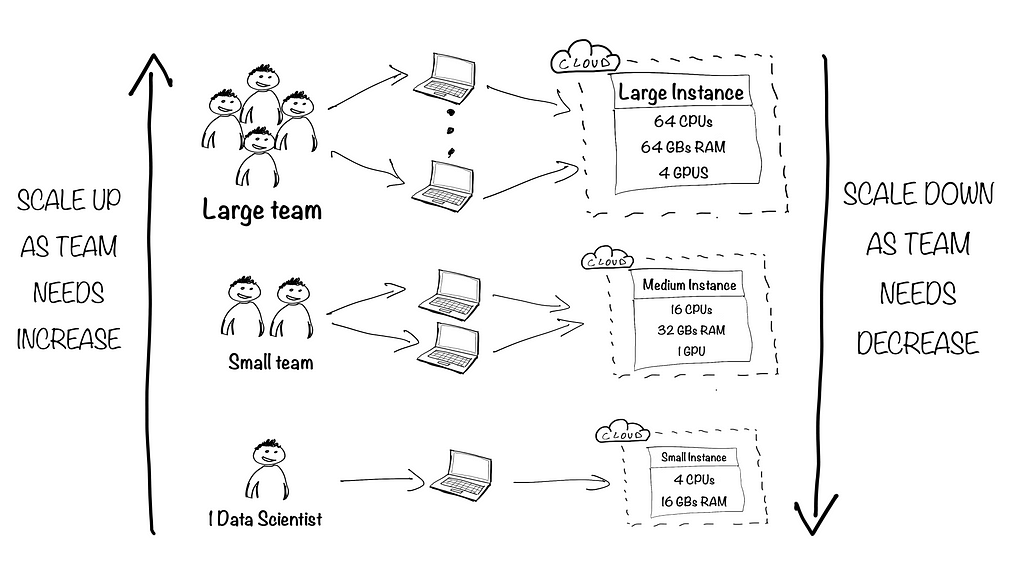
However, teams quickly realized (sadly not all) that they didn’t always scale down to the minimum capacity when testing on a small dataset, re-factoring code, or simply writing documentation. Imagine paying for a machine that has 4 GPUs and over 200GB of RAM to achieve these low-computing tasks. Aside from running into potential high costs, it doesn’t seem like the right thing to do in the context of elastic compute. A typical example of instance usage would be like the following:
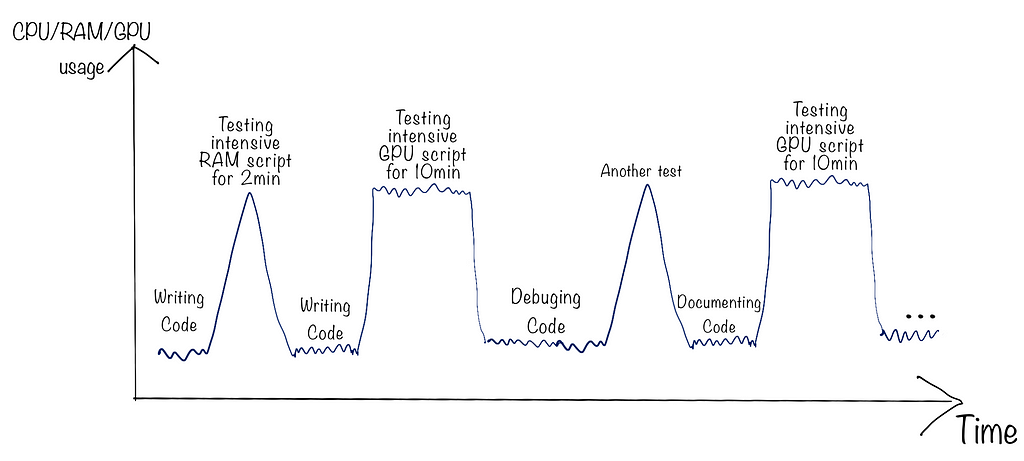
A first guardrail that early adopters implemented is the automatic shut-down and start-up of these remote servers (e.i., outside working hours, when CPUs/GPUs are idle). This comes at the cost of losing anything saved in RAM as well as waiting a few minutes for your server to come online again when you need it.
Still, when you’re working on code, building and testing models, having to restart your work environments every now and then can be inconvenient.
Chapter IV: Ephemeral compute
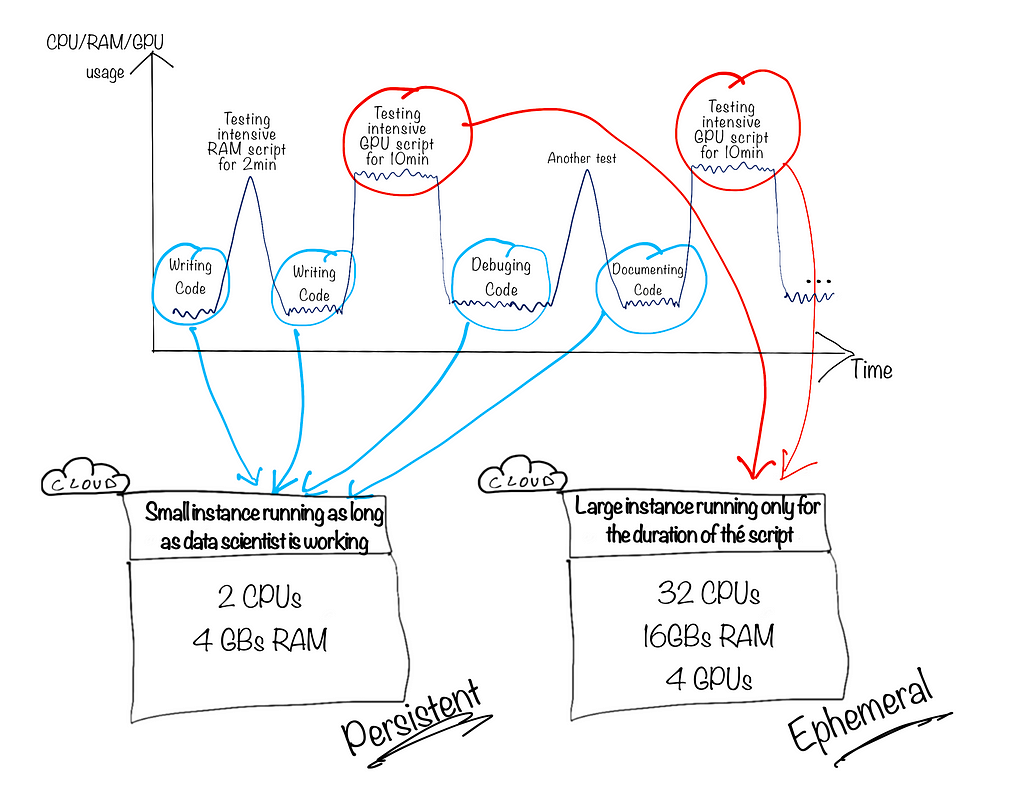
When you look at the previous graph, it raises the question: What if we decoupled the low and intensive computational tasks? What if we used a combination of cost-effective compute instances that run continuously and powerful compute instances that only run for the duration of the script’s execution?
Data science teams would be able to get the best of both worlds. Keeping their working environment running and when needed, delegating heavy executions of their code base to other instances for a specific duration. This can be done using ephemeral compute:
Interestingly, that’s not how most data science teams start using ephemeral compute. Generally, they would stumble across it in the process of moving a machine learning project into production. During that process, you package code in containers, automate steps like training, inference, etc. To make things more robust and automated, the natural next step is to “create jobs in the cloud”. Which basically means you’re now able to run your containerized code on scalable compute while the cloud provider automates the provisioning and shutdown of the required infrastructure (i.e., ephemeral compute).
You can, however, utilize the same principal during the development phase.
Chapter V: Paradigm shift — Using ephemeral compute during development
Even though this is still rare nowadays, some teams notice the potential of using ephemeral compute during the development phase as well. This is a great way of combining stability, scale, and cost efficiency. The following figure illustrates how a team of data scientists running various workloads with various computational needs would set up their environment:
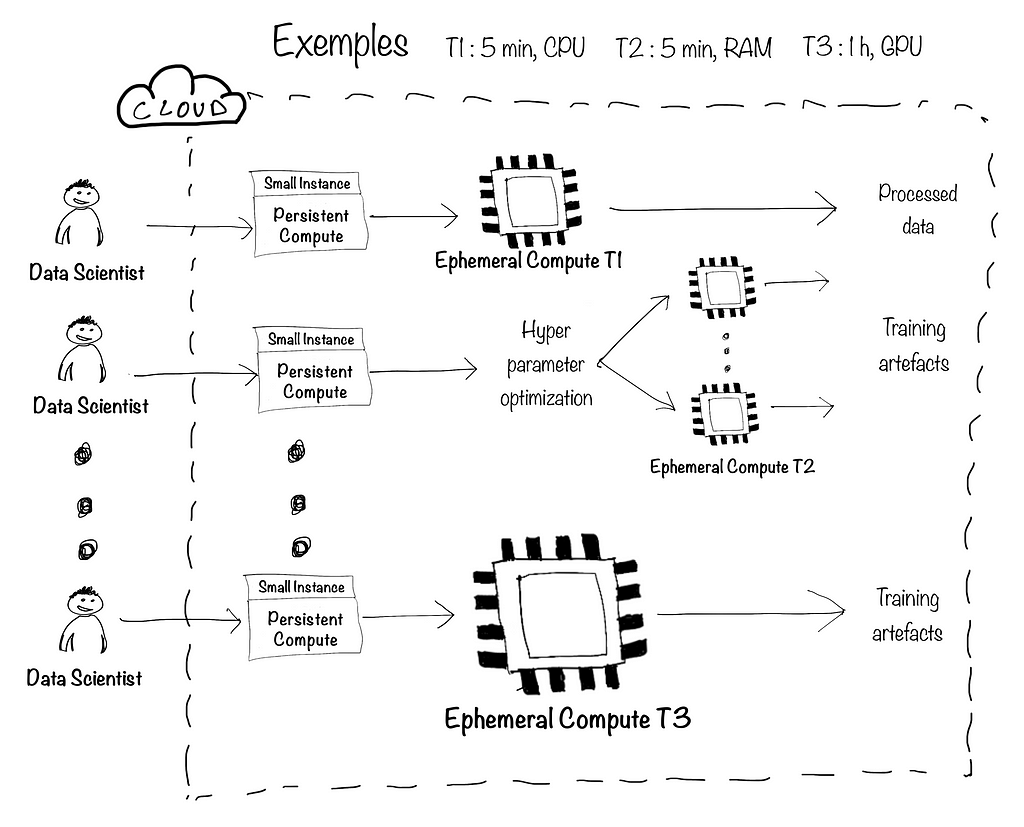
The persistent instances on the left provide a stable environment in which to write code, build initial models, and perform any task that doesn’t require intensive compute. Given their cost-efficiency, we can create multiple instances to ensure segregation of workspaces within large teams.
The ephemeral jobs on the right are launched through APIs provided by cloud services. Besides the main code logic, we would need to package the code in a certain manner and specify service configuration (based on which service you’re using). The key differentiator here is that your whole code logic is now running on an ephemeral job launched by the service and not the instance from which you made the API call.
Additionally, if your persistent instance is hosted in the cloud, you can easily scale it up (adding more RAM, CPU or GPU). This allows you to quickly test your code on the target infrastructure without much effort. However, it should be the exception, not the norm. Otherwise, you end up back in Chapter III.
The impact on the data scientist’s developer experience
The use of a hybrid working environment (i.e., persistent and ephemeral) during the development phase has the following advantages:
- You’re only paying for the duration of the execution on the ephemeral instance (i.e., 1h34min, 10min, etc.). No more wasting those precious resources on low-computing tasks.
- Your development environment is not impacted by the heavy compute jobs you launch. Your kernel/runtime is not overwhelmed, and you can continue development.
- You’re not limited to the RAM/CPU/GPU of your persistent instance. You can launch many training variations in parallel, using different datasets, hyper-parameters, and algorithms, thus accelerating your experimentation cycles.
On the other hand, you need to account for the following drawbacks:
- You’ll make changes to your code base to ensure it runs within the said service: containerization, folder structure, how data is accessed, how hyper-parameters are passed, etc.
- You have less interactivity. As your script is now executed remotely, it’s harder to debug the same way you do in a persistent instance (executing line by line or making use of an IDE’s debugger).
Depending on which elements are most important to your organization, you may lean more toward persistent or ephemeral compute. Based on my interactions so far with AI/ML practitioners (data scientists, ml engineers, etc.), the use of a hybrid working environment is key. It contributes to reducing time to market for the business while also providing the team with a frictionless and decent developer experience.
Closing thoughts
It’s equally important for AI/ML practitioners and C-level decision makers to keep in mind that building machine learning in the cloud is not only about getting access to bigger and more powerful instances, but also how we use them.
More importantly, changes are introduced to the process of how we experiment, build, and tune models: working with a hybrid environment of persistent and ephemeral compute vs. running everything in the same persistent environment.
Thanks for reading ! If you have any questions don’t hesitate to reach out over Twitter (@OHamzaoui1)or Linkedin (hamzaouiothmane).
Building Machine Learning models in the cloud: A paradigm shift was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/RbyN0kI
via RiYo Analytics








No comments