https://ift.tt/4adsrl2 Estimate the range of a future observation with confidence Target Image — By Afif Kusuma Forecasting in the real...
Estimate the range of a future observation with confidence

Forecasting in the real world is an important task. Consider forecasting energy demand, temperature, food supply, and health indicators just to name a few. Getting an inaccurate forecast in these cases can have a significant impact on people’s lives.
This is where prediction intervals can help. Prediction intervals are used to provide a range where the forecast is likely to be with a specific degree of confidence. For example, if you made 100 forecasts with 95% confidence, you would have 95 out of 100 forecasts fall within the prediction interval. By using a prediction interval you can account for uncertainty in the forecast, and the random variation of the data.
Loading Temperature Data
In this article, we will be forecasting the average monthly temperature in Sau Paulo, Brazil. The data set was collected and curated by NCEI⁶ and NASA⁷. Thank you to everyone involved for sharing this dataset with the world! (License: CC0 — Public Domain)

Unfortunately in the real world, data is never in the format that you want. In the following cell, we use Pandas to transform it into two columns. Date and Temperature. The resulting data is visualized using Matplotlib.
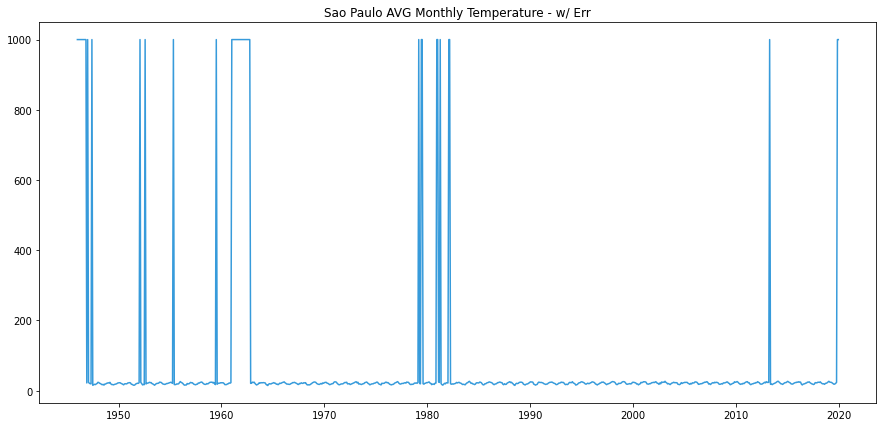
In the plot above, we can see that the dataset has missing values and errors. These points are filled with temperatures of 999.9. We can simply sample 372 data points between ~1980 and ~2015 that contain no errors. We will use this sample of data for the rest of the article.
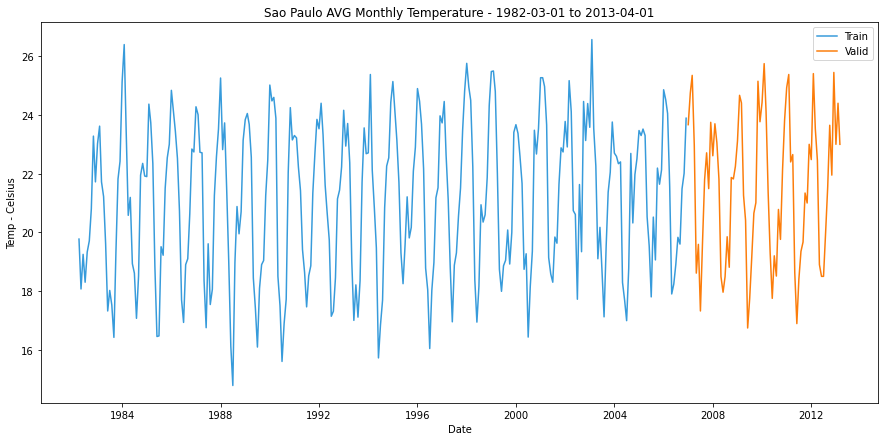
Creating Model
I have worked with many time series models, but I always come back to ARIMA models. These models are reliable and regularly outperform competing model types (NeuralProphet, ExponentialSmoothing, Last-Value).
We will use a modified version of ARIMA called SARIMA. SARIMA adds a lagged term to ARIMA that keeps track of seasonality in the data. Using a package called pmdarima⁹ we can automatically tune the model parameters. For a more detailed explanation of ARIMA models check out this amazing article here.

The cell above gives us the optimal order and seasonal order to fit our ARIMA model. In the following cell we do just that, and iteratively make 1-step predictions on the validation dataset.
Prediction Intervals
Method 1: RMSFE
The first method that we can use is called RMSFE(root mean squared forecasting error). RMSFE is very similar to RMSE. The only difference is that RMSFE has to be calculated on residual terms from predictions on unseen data (ie. Validation or Test set).
It’s important to note that we can only use this method if we assume that the residuals of our validation predictions are normally distributed. To see if this is the case, we will use a PP-plot and test its normality with the Anderson-Darling, Kolmogorov-Smirnov, and D’Agostino K-squared tests.
The PP-plot(Probability-to-Probability) plots the data sample against the normal distribution plot in such a way that if normally distributed, the data points will form a straight line.
The three normality tests determine how likely a data sample is from a normally distributed population using p-values. The null hypothesis for each test is that “the sample came from a normally distributed population”. This means that if the resulting p-values are below a chosen alpha value, then the null hypothesis is rejected. Thus there is evidence to suggest that the data comes from a non-normal distribution. For this article, we will use an Alpha value of 0.01.
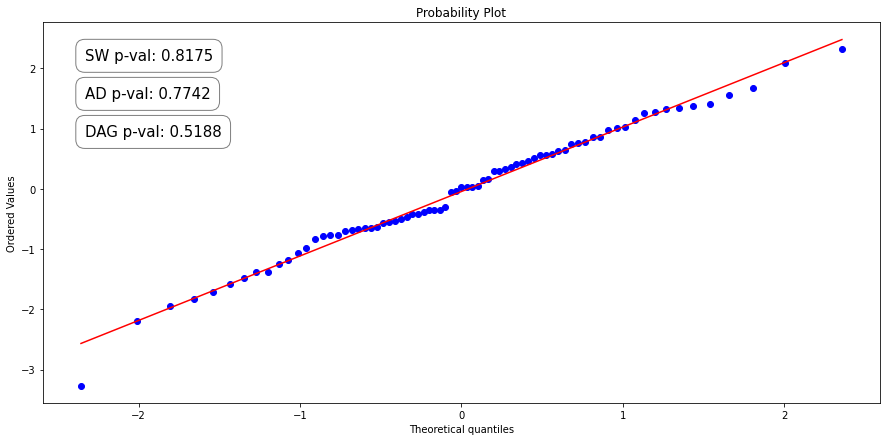
Great! All three tests returned a p-value greater than the alpha value of 0.01. That means that the null hypothesis can not be rejected and it is likely that the data points come from a normal distribution. We can now use RMSFE to generate prediction intervals on our forecast.
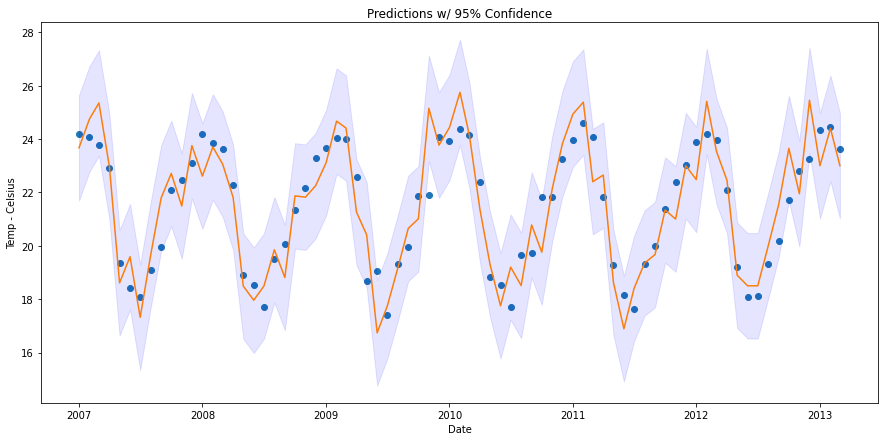
The first step here is to choose the degree of confidence that we want to provide. Do we want our prediction to fall within the prediction interval of 75%, 95%, or 99% of the time? We will use a prediction interval of 95%. In a normal distribution, 95% of data points fall within 1.96 standard deviations of the mean, so we multiply 1.96 by the RMSFE to get get the prediction interval size. This is shown in the plot below.
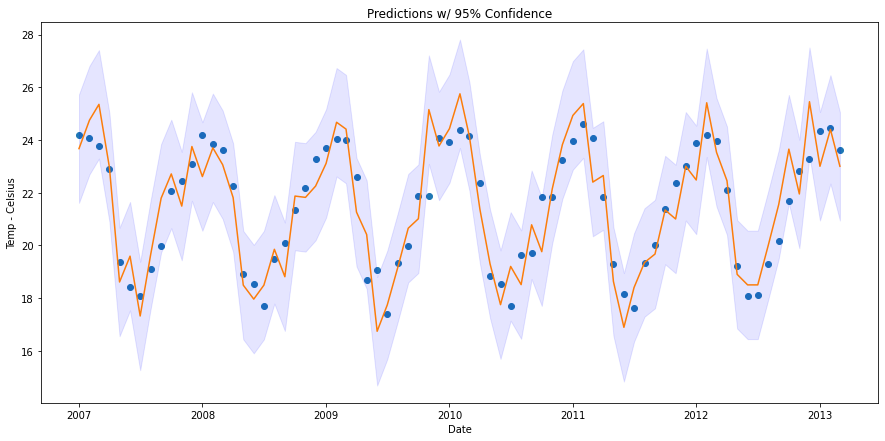
The downside of this method is that the prediction interval is highly dependent on the residuals from the validation predictions. This is not the end of the world, but the prediction interval is likely overfitting to the variation in the validation set.
Method 2: BCVR (Bootstrapping Cross-Validation Residuals)
NOTE: BCVR is a theoretical method that I am proposing!
Let’s call this method BCVR (Bootstrapping Cross-Validation Residuals). BCVR is an attempt to reap the benefits of both cross-validation and bootstrapping. Bootstrapping residuals is a common way to generate prediction intervals, and typically yields similar results to the RMSFE method with normally distributed residuals, but performs slightly better than RMSFE on non-normal residuals. Furthermore, by using cross-validation, BCVR should generate a residual distribution that is more representative of the entire dataset.
We can start by performing cross-validation to generate residuals. We randomly select a training sample that is between 250 and 372 points long and make a one-step forecast. Then, we calculate the residual for this prediction and repeat the process 1000 times.
Then, we can test the normality of the residual distribution.
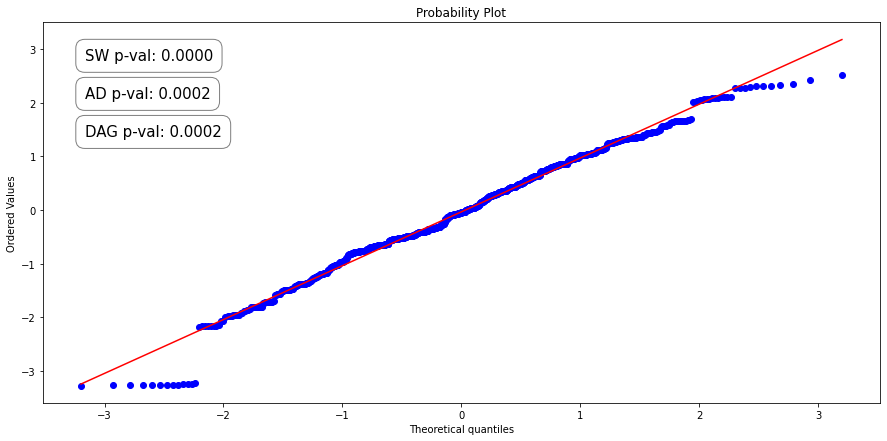
Oh no! We have p-values that fall well below the Alpha threshold so should reject the null hypothesis? Fear not, we can use a technique called bootstrapping to get a measure of the residual variance. To do this, we take the cross-validated residuals and perform random sampling with replacement. We then compute the standard deviation of the resampled set and store this in an array. We repeat this process several times, and then take the mean/median of the stored bootstrapped standard deviations.
There is no consensus among mathematicians as to how many times one should bootstrap, but I use early stopping in this implementation to reduce computational demand. In the following cell, we check the mean standard deviation of the bootstrapped samples every 200 iterations. If the mean standard deviation does not deviate by more than 0.001% from the previous measurement, then we terminate the loop. In our case, early stopping occurred on the 7500th iteration.
The downside of the BCVR approach is that it is computationally expensive for one machine. Thankfully this method is well-suited for clustered computing. This means that the workload can be divided among multiple machines. For example, if we had a cluster with 10 nodes and wanted to perform 1000 bootstrapped samples, we could have each node perform 100 samples at the same time. This would dramatically reduce the compute time and allow us to increase the number of bootstrapped samples.
RMSFE vs BCVR
How do the two methods compare?
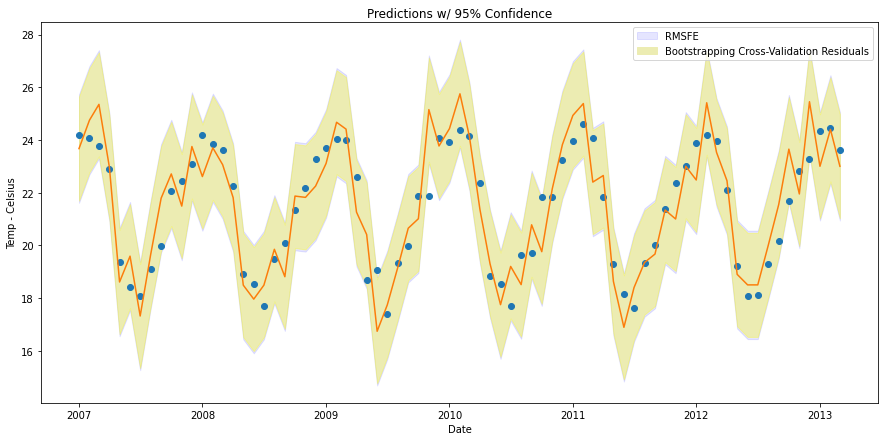
In both cases, all 75 points fall within the prediction interval. Although unlikely (2% chance each), there are points that fall very close to the boundary. The two methods are slightly different in their interval range. The BCVR approach produces a slightly narrower prediction interval range than the RMSFE approach (see the faint blue line surrounding the BCVR prediction interval above).
Final Thoughts
This example indicates that the proposed BCVR implementation could be useful in generating a prediction interval that is more representative of the entire population. It would be interesting to see it applied in different scenarios.
Code for this article can be found here.
References
- Forecasting: Principles and Practice — Rob J Hyndman and George Athanasopoulos
- Confidence and Prediction intervals for forecasted values — Charles Zaiontz
- Add Prediction Intervals to your Forecasting Model — Marco Cerliani
- Bootstrapping Prediction Intervals — Dan Saattrup Nielson
- A Gentle Intro to Normality Tests — Jason Brownlee
- NCEI (National Centers for Environmental Information)
- NASA GISS (Goddard Institute for Space Studies)
- Shapiro-Wilk Test — Wikipedia
- Pmdarina
Time Series Forecasting: Prediction Intervals was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/Y0sn37o
via RiYo Analytics








No comments