https://ift.tt/YMrWaNv How to use causal influence diagrams to recognize the hidden incentives that shape an AI agent’s behavior There is ...
How to use causal influence diagrams to recognize the hidden incentives that shape an AI agent’s behavior
There is rightfully a lot of concern about the fairness and safety of advanced Machine Learning systems. To attack the root of the problem, researchers can analyze the incentives posed by a learning algorithm using causal influence diagrams (CIDs). Among others, DeepMind Safety Research has written about their research on CIDs, and I have written before about how they can be used to avoid reward tampering. However, while there is some writing on the types of incentives that can be found using CIDs, I haven’t seen a succinct write up of the graphical criteria used to identify such incentives. To fill this gap, this post will summarize the incentive concepts and their corresponding graphical criteria, which were originally defined in the paper Agent Incentives: A Causal Perspective.
A Quick Reminder: What are CIDs?
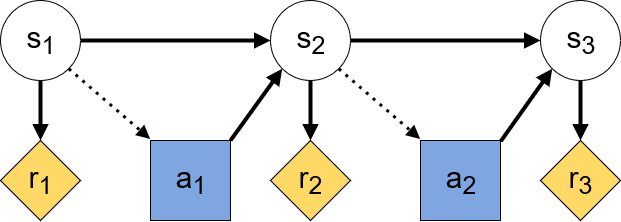
A causal influence diagram is a directed acyclic graph where different types of nodes represent different elements of an optimization problem. Decision nodes represent values that an agent can influence, utility nodes represent the optimization objective, and structural nodes (also called change nodes) represent the remaining variables such as the state. The arrows show how the nodes are causally related with dotted arrows indicating the information that an agent uses to make a decision. Below is the CID of a Markov Decision Process, with decision nodes in blue and utility nodes in yellow:
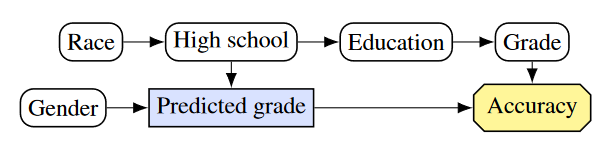
Example 1: A potentially unfair grade prediction model
The first model is trying to predict a high school student’s grades in order to evaluate their university application. The model uses the student’s high school and gender as input and outputs the predicted GPA. In the CID below we see that predicted grade is a decision node. As we train our model for accurate predictions, accuracy is the utility node. The remaining, structural nodes show how relevant facts about the world relate to each other. The arrows from gender and high school to predicted grade show that those are inputs to the model. For our example we assume that a student’s gender doesn’t affect their grade and so there is no arrow between them. On the other hand, a student’s high school is assumed to affect their education, which in turn affects their grade, which of course affects accuracy. The example assumes that a student’s race influences the high school they go to. Note that only high school and gender are known to the model.
When AI practitioners create a model they need to be mindful of how sensitive attributes such as race and gender will influence the model’s prediction. To rigorously think about when a model may be incentivized to use such an attribute, we first need a condition for when a node can provide useful information for increasing the reward. We call such a node “requisite”.
Requisiteness and d-separation
Requisiteness is a special case of the more general graphical property of d-separation. Intuitively, a node a is d-separated from another node b given a set of nodes C if knowledge of the elements of C means that knowing a does not provide any additional information for inferring b. We say that C d-separates a from b. In the context of graphical models, d-separation allows us to talk about when a node provides useful information about the value of some other node. This is exactly what we need to define requisiteness, which concerns the information a node can provide, so that we can infer the value of the reward node based on a decision. A node x is non-requisite if the decision and its parents (excluding x) d-separate x from those utility nodes that the decision can influence (i.e. to which there is a path from the decision).
Now that we know that to tell if a node is requisite we need to be able to recognize d-separation, let me explain its three graphical criteria. Suppose you have two nodes, x and u, and you want to determine if they are d-separated by some set of nodes A. To do so, you need to consider each path from x to u (ignoring the direction of arrows). There are three ways this path can be d-separated by the elements of A.
- The path contains a collider which is not an element of A and which does not have any children that are elements of A. Here, a collider means a node that has arrows coming into it from both sides as shown in the image below. Intuitively, a collider is causally influenced by both ends of the path, so x and u. Hence, if you know the value of a collider node or one of its children, then knowing the value at one end of the path allows you to make inferences about the other end. So if some element of A was a collider, that would make knowledge of x more useful and not less!
- The path contains a chain- or fork element which is an element of A. A chain element contains an inward arrow from x and an outward arrow towards u. A fork element has two outward arrows. If the value of such an element is known, then knowing x provides no further information.
- This point is vacuous but I will mention it for the sake of completeness: If x or u themselves are elements of A, then A d-separates x and u. Obviously, if x or u are already known, then gaining knowledge of x won’t help with inferring u.
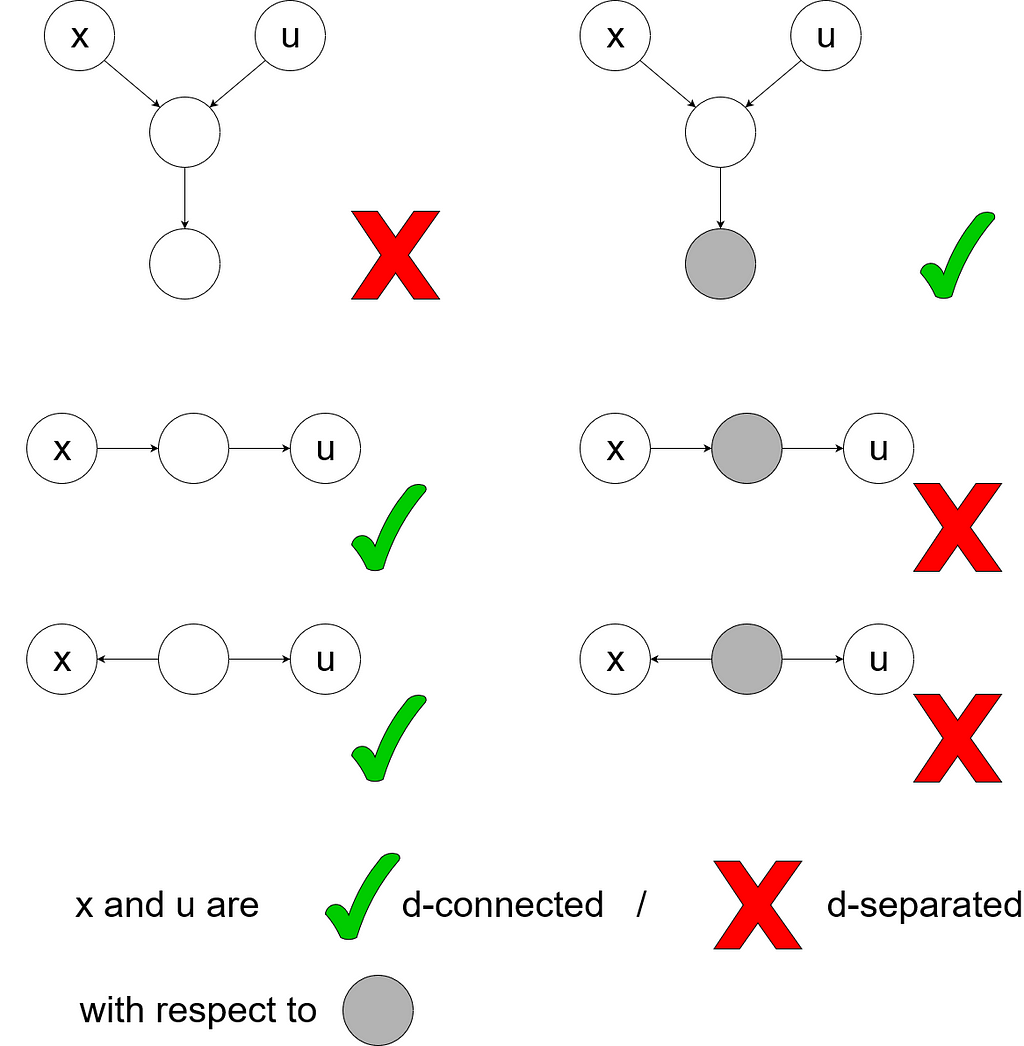
If every path from x to u is d-separated by A, then we say that x and u are d-separated by A. To come back to the topic of requisiteness, let us inspect the grade-prediction example again. We see that the only path from gender to accuracy goes over the decision node. As the predicted grade is the middle element of a chain, it d-separates this path. Hence, gender is not a requisite observation in this model.
We have talked about how knowledge of a node can be useful for inferring another node’s value. When an agent needs to make inferences to solve an optimization problem, this usefulness can give rise to incentives that may cause the agent to have undesirable properties. I will now introduce two types of incentives that are important for the grade prediction model.
Value of Information
In our example, the agent needs to infer a student’s grades to optimize accuracy. This is easier if the student’s high school is known as it influences the true grade and thus accuracy. We say that the node high school has Value of Information (VoI). Intuitively, positive VoI means that an agent can achieve a higher reward by knowing the value of a node.
The VoI of a node x depends on the answer to the question ‘Can I make a better decision if I consider the value of x?’. This question is potentially hypothetical, as there may be no direct link from x to the decision. For example, if x is not an input to our predictive model. This is why we need to look at a modification of our model’s CID where we have added an arrow from x to the decision. If x is requisite in this modified CID, then x has positive Value of Information.
In the grade prediction model, it is clear that gender does not have VoI as we have already established that it is not requisite and it already has an arrow into the predicted grade. Further, it turns out that race does not have VoI. When we add an arrow from race to predicted grades there are two paths to accuracy: one is d-separated from accuracy by predicted grades and the other by high school, which is an ancestor of predicted grades. Hence, race is not requisite in the modified CID and thus has no positive VoI. On the other hand, high school, education, and grade all have positive VoI.

That race does not have positive VoI does not mean it does not influence the model in an undesirable way. To see what type of influence this may be, we need to look at another type of incentive.
Response Incentive
Even if an agent does not need to know the value of a node to make an optimal decision, the downstream effects of the node may influence its behavior. If an agent changes its behavior based on a node’s value, we say there is a response incentive on the node. Clearly, requisite nodes have a response incentive. Additionally, there is a response incentive on the nodes that influence a requisite node or its ancestors. This is because a change in their values will trickle downstream and change the requisite node’s value, incentivizing the agent to respond.
Graphically, to find out which nodes have a response incentive we first remove the arrows going into the decision node from those nodes that are not requisite. The resulting CID is called the minimal reduction of the original model’s CID. If there is a directed path from node x to the decision node in the minimal reduction, then there is a response incentive on x.
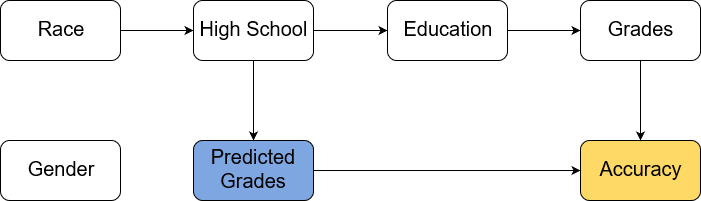
In the grade prediction model, the only arrow from a non-requisite node into the decision comes from gender. If we remove it, we see that there is still a directed path from race to predicted grade. This means our model might make different predictions about a students grade based on their race! For an algorithm that’s suppose to help evaluate university applications that is bad news. In the language of the AI fairness literature we would say that the model is counterfactually unfair with respect to race. Here, counterfactual fairness with respect to an attribute means that the attribute’s value does not change a model’s prediction. It can be shown that a response incentive on a node is the same as the model being counterfactually unfair with respect to the corresponding attribute.
Example 2: The manipulative content recommender
We have seen how the causal relationships between variables can incentivize models to make unfair predictions that are biased against a certain group. Next to fairness, another primary concern when developing AI systems is their safety. The AIACP paper uses the example of a content recommender system, to illustrate how unsafe behaviour can be incentivized. This well known example is about a system that recommends posts for a user to read on a social media application and aims to maximize the user’s click rate. To do so it creates a model of original opinions of the user. Based on this model, the system makes a decision about the posts to show the user. This decision creates an influenced user opinion. The system is rewarded for the clicks of the user whose opinion has been influenced. This leads to a recommender system that purposefully shows the user more polarizing content, as the system learns that a more radical user’s clicks are easier to predict and hence it is easier to show them posts that generate clicks.
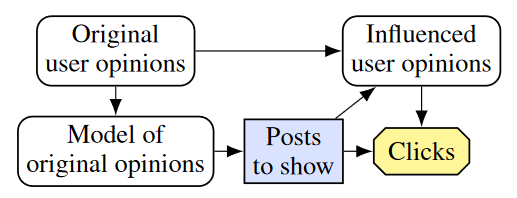
There are two new types of incentives involved in this model which we have not seen in the fairness example. We observe that the agent manipulates the variable influenced user opinions even though we do not want it to. This poses the question of when it is valuable for an agent to control a variable.
Value of Control
Intuitively, a non-decision node has Value of Control (VoC) if an agent could increase its reward by setting the node’s value. Like VoI, this condition is hypothetical, so a node has VoC even if it is impossible for the agent to influence it, as long as doing so would increase their reward.
To determine which nodes have VoC graphically, we need to look at the minimal reduction of the model’s CID. Any non-decision node that has a directed path to the utility node in the minimal reduction has VoC. In practice, this means that requisite nodes and those non-decision nodes that can influence them have VoC.
When we look at our recommender system we see that every node, except by definition the decision node, have VoC. The minimal reduction is the same as the original CID and every node has a directed path to clicks. Unfortunately, this means that influenced user opinions has positive VoC. Still, as I mentioned earlier, a node may have VoC even if the agent cannot influence its value. Hence, if an attribute we do not want the agent to change has VoC, that does not mean that the agent can or will change it. To make sure, we need a property that takes into account the agent’s limitations.
Instrumental Control Incentive
When we pursue a complicated goal, there are often several smaller side goals that are helpful to fulfill even though they do not directly contribute to our main goal. For example, to advance in any job it is helpful to make friends with colleagues, as a student, it is easier to do good in any degree when having a healthy lifestyle, and it is almost always helpful to have more money rather than less. In the context of artificial intelligence, such goals are called instrumental. In a CID, we say there is an Instrumental Control Incentive (ICI) on a node if controlling it is a tool for increasing utility. More formally, there is an ICI on node x if the value of the utility node could be changed by choosing the decision node d’s value to influence x independently of how d influences other aspects of the problem.
The graphical criterion to recognize an ICI is simple. There is an ICI on node x, if there is a directed path from the decision node to the utility node that passes through x. The path from the decision node to x indicates that the agent can change x with their decision, and the path from x to the utility node indicates that changing x influences the resulting utility.
Considering the recommender system again, we see that there is no ICI on the original user opinon or model of original user opinion nodes even though they have VoC. This is because the agent can not control them. Worryingly, there is an ICI on influenced user opinion, indicating that changing its value would influence the received reward and that the agent is able to do so.
How to fix the manipulative recommender system
If we were AI researchers or engineers designing a recommender system, then analyzing our model’s incentives using CIDs would hopefully have alerted us to the ICI on influenced user opinion. One way to fix this is to change the reward signal. Instead of selecting posts to maximize clicks by the user, select posts to maximize the clicks predicted by the original model of the user’s opinion. This removes the arrow from influenced user opinion to the utility node and thus the ICI. The resulting CID can be seen below:
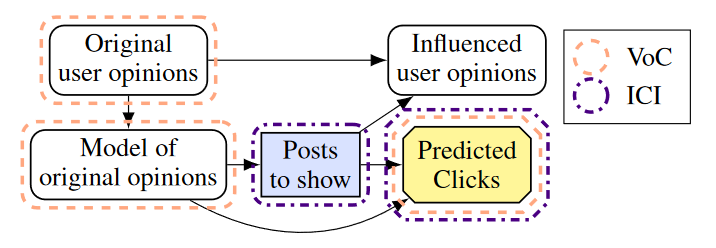
Discussion
We have seen various ways in which causal relations between variables can incentivize unfair or unsafe behavior in agents. Fortunately, on CIDs, there are easy-to-use graphical criteria to spot such incentives. The challenge for AI practitioners lies in correctly determining the relevant causal relations and creating a useful CID. In a real-life version of the grade prediction model, it is presumably impossible to know the exact causal relationship between gender, race, all other relevant variables, and the result. Hence, to create a CID and do causal incentive analysis, the practitioner will have to resort to estimates and educated guesses. Ultimately, it may be impossible to find useful features that are completely uncorrelated to sensitive attributes such as gender or race. There is still a discussion to be had on how to deal with such attributes that go beyond the domain of AI research.
Further, if an incentive is desirable depends entirely on the purpose of the model. In the grade prediction example, we saw how response incentives can be dangerous as they lead to counterfactual unfairness. On the other hand, if you train an agent with an off-switch, you want to incentive it to respond to the switch. Instead of thinking of incentives as good or bad, it is more helpful to view them as a mechanic of the learning process that has to be used to the programmer’s advantage.
The concept of CIDs and incentive analysis is still new. Yet, there are already many interesting results and promising research directions, some of which I want to discuss in future articles. I’m excited to see how this field will contribute to making AI more fair and safe for everyone.
Bibliography
[1] Carey Ryan, New paper: The Incentives that Shape Behaviour, Towards Data Science, 22nd January, https://towardsdatascience.com/new-paper-the-incentives-that-shape-behaviour-d6d8bb77d2e4
[2] Everitt et al, Agent Incentives: A Causal Perspective, Arxiv, 2nd February 2021, https://arxiv.org/abs/2102.01685
[3] Everitt et al, Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective, Arxiv, 26th March 2021, https://arxiv.org/abs/1908.04734
[4] Everitt et al, Progress on Causal Influence Diagrams, DeepMind Safety Research on Medium, 30th June 2021, https://deepmindsafetyresearch.medium.com/progress-on-causal-influence-diagrams-a7a32180b0d1
Spotting Unfair or Unsafe AI using Graphical Criteria was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/qGdvHQg
via RiYo Analytics







No comments