https://ift.tt/VOAwhRv Photo by Jason Dent on Unsplash Reproducibility is critical for robust data science — after all, it is a scienc...

Reproducibility is critical for robust data science — after all, it is a science.
But reproducibility in ML can be surprisingly difficult:
The behaviour of your model doesn’t only depend on your code, but also the underlying dataset that was used to train it
Therefore, keeping tight control on which data points were used to train and test your model to is critical to ensure reproducibility.
How you split your data can have a big effect on the perceived model performance
If you split your data ‘randomly’ there is a statistical chance that more outliers end up in the test set than the training set. As your model won’t ‘see’ many outliers during training, it will perform poorly on the test set when predicting ‘outlier’ values.
Now imagine you randomly split the data again and the ‘outliers’ now all reside in the training set and none in the test set. It is likely that your ‘model performance’ will increase. This performance increase has little to do with the chosen model, just the statistical properties of the training/test sets.
Therefore, it is important to control and understand the training and test splits in order to effectively compare different model candidates across multiple training runs.
Sklearn train_test_split
Probably, the most popular way to split your dataset is to use Sklearn’s train_test_split function.
Out of the box, the train_test_split function will randomly split your data into a training set and a test set.
Each time you run the function you will get a different split for your data. Not ideal for reproducibility.
“Ah!” — you say
“I set the random seed so it is reproducible!”.
Fair point.
Setting random seeds is certainly an excellent idea and goes a long way to improve reproducibility. I would highly recommend setting random seeds for any functions which have non-deterministic outputs.
However, random seeds might not be enough to ensure reproducibility
This article will demonstrate that the train_test_split function does not always guarantee reproducible splitting even with the random seed set. I will also suggest alternative solution — hashing — for more robust and repeatable splitting.
This isn’t to say you should never use train_test_split , just to highlight it is perhaps more sensitive than you might think. In certain scenarios, this can lead to inconsistent splitting which is difficult to debug.
This article was originally published on my blog, engineeringfordatascience.com
What is the problem with train_test_split?
Setting the random reed only guarantees reproducible splits if the underlying data does not change in any way.
The train_test_split is not deterministic.
The splits generated from train_test_split are sensitive to the *ordering* of the underlying data and any *new data* added to the existing dataset.
If your dataset is shuffled or amended in any way, the data will be split completely differently. It cannot be guaranteed that an individual data point will *always* be in the training set or *always* be in the test set. This means data points that were in the original training set might now end up in the test set and visa versa if the data was shuffled.
Therefore, for the same dataset, you can get *completely* different splits depending on how the rows in the dataset are ordered. That’s quite worrying.
Even if one data point is removed, the order of two rows are switched, or a single data point is added you will get a *completely* different training and test split.
This ‘ultra sensitivity’ to the data might be surprising — it certainly was to me at first — and lead to unexpected model training results.
Let’s demonstrate the issue with a simple demo.
💻 All code for this post is provided in the accompanying notebook stored on GitHub 🚀
We will first download an example dataset from sklearn.datasets and create an ‘index’ column to uniquely identify each row.
from sklearn.datasets import load_breast_cancer
import pandas as pd
# download an example dataset
data = load_breast_cancer()
df = pd.DataFrame(data["data"], columns=data["feature_names"])
# create an 'index' column to use to uniquely identify each row
df = df.reset_index(drop=False)
df.head()

Now let’s split the data using Sklearn’s train_test_split, setting the random state (seed).
from sklearn.model_selection import train_test_split
TEST_RATIO = 0.1
SEED = 42
# split into training and test using a random seed
x_train_skl, x_test_skl = train_test_split(df, test_size=TEST_RATIO, random_state=SEED)
Next, we shuffle the original dataframe and split the data again. We will still use the same random seed as before for consistency.
Note that no new data has been added, we have just reordered the rows.
# shuffle the orginal dataframe
df_shuffled = df.sample(frac=1)
# split the shuffled dataframe using the same random seed
x_train_skl_shuffled, x_test_skl_shuffled = train_test_split(
df_shuffled, test_size=TEST_RATIO, random_state=SEED
)
Ideally the rows contained in the x_test_skl and x_test_skl_shuffled test sets should be identical as we used the same random seed.
However, when we compare the row ids contained in each test set, we notice they are different! Even though the random state (seed) was the same both times. Nothing in the data has changed, it was just shuffled.
# compare the row ids included in the original test set vs shuffled test set. Should return True if identical rows are included in each test set
set(x_test_skl["index"]) == set(x_test_skl_shuffled["index"])
False
This highlights just how sensitive the train_test_split function is, even to reordering of the data.
More importantly, if there was a change in the underlying data, it would be extremely difficult to reproduce the original data splits and debug model performance.
What are the consequences of relying on a random seed?
It is risky
The random seed only guarantees reproducibility when the dataset has not changed in any way.
Can you be 100% sure the dataset has not changed between training runs? If a colleague has removed an outlier data point or if new rows have been added. Your data splits will be completely different to your original splits with no way to easily replicate the old data splits.
You can use data versioning tools, such as dvc to help keep track of changes, however, that doesn’t prevent your data splits from changing. It would be better to protect against split changes in your code.
Difficult to effectively compare models
When comparing models, we want to be able to control as many variables as possible. That should include which data points were used for training and testing.
If your data splits are significantly different between runs you might observe considerable differences in performance. For example if you have a couple of ‘outlier’ data points that were in your training set for the original training run, but are now in your test set, your model performance might ‘decline’ as it could not predict outlier values in the test set as well as before.
Difficult to debug
If you can’t effectively compare models, it can make it hard to debug performance issues.
Imagine you add some new data points to your dataset and retrain your model, but the performance of the model drops.
If you have used train_test_split with the random seed set, you will have completely different data splits as the underlying data has changed. It would be difficult to understand whether the model performance decline was due to the quality of the new data, or, as highlighted in the previous point, it was just because the data was split differently.
When might train_test_split not be appropriate?
…if you need to retrain your model in the future on the original data & new data
As demonstrated, any underlying change to your existing data, be it reordering or even adding one additional data point will cause completely different data splits. Your original data splits will not be reproducible.
If you are retraining the model with a completely new dataset it isn’t a problem as obviously all the training and test data points will be different.
But if you are training again with a dataset that includes your original data points, ideally you should be able to replicate their original data splits during the new training run. Even with the random seed set, train_test_split will not guarantee this.
…if you are sampling or retrieving your source data from an evolving data source
In an ideal situation, you should have full control of your source dataset, however, sometimes this is not the case.
For example, if you are using a table stored in BigQuery as the source that is used by many teams. You cannot guarantee the order of the rows returned by a query and new rows might be appended to the table in the meantime.
Another example, would be if you are working with image data stored in a filesystem. If new images are added to your source folder you cannot guarantee the ordering of filepaths especially if new images are added.
…if you have large datasets which do not fit in memory
If you need to distribute your data across many machines in order to parallelise data processing, using a non-deterministic method for splitting your training and test data can be problematic and difficult to ensure reproducibility.
…if your experimentation or production code will be rewritten in another language
As the train_test_split is non-deterministic, the data splits will not be easily reproducible across languages.
For example, you might want to compare the performance of your custom Python model to a model created using BigQuery’s BQML which is defined using SQL. The splits from train_test_split Sklearn will not easily translate directly to SQL.
It can also be common for teams to prototype models using Python, but then write production systems in another language such as Java. To help the process of translating the prototype model into another language, ideally we should be able to split the data in the same way in both languages to ensure reproducibility and help debug any differences from the original model to the new model.
The Solution: Hashing
What is hashing?
“A hash function is any function that can be used to map data of arbitrary size to fixed-size values” Wikipedia
There are many different hashing algorithms, but essentially they allow you to reproducibly convert an input into an arbitrary value.
The output of the hashing function is deterministic — it will always be the same for the same input.
How does it work for splitting data reproducibly?
In the context of data splitting, we can use hashing to reliably assign splits to individual data points. As this is a deterministic process, we can ensure that the data point is always assigned to the same split which aids reproducibility.
The process works as follows:
- Use a unique identifier for the data point (e.g. an ID or by concatenating multiple columns) and use a hashing algorithm to convert it to an arbitrary integer. Each unique data point will have a unique output from the hashing function.
- Use a modulo operation to arbitrarily split the data into ‘buckets’
- Select all datapoints in a subset of buckets to be the training set and the rest to be in the test set
Pseudo Code (90:10 data split)
row_id = "0001"
# convert id into a hashed integer value
hash_value = hash(row_id)
# assign a bucket between 0 and 9
bucket = hash_value % 10
# add id to train set if less than 9 (i.e. approx 90% of the data)
if bucket < 9:
train_set.append(row_id)
else:
test_set.append(row_id)
Reasons to use hashing
Deterministic
Hashing is robust to underlying changes in the data, unlike train_test_split.
Using this method, an individual data point will always be assigned to the same bucket. If the data is reordered or new data is added, the assigned bucket will not change. This is preferable as a data point’s train/test split assignment is now independent of the rest of the dataset.
Improves development and reduces chances of human error
When working on models in parallel with colleagues, it is very easy to accidentally forget to use random seeds or even use different random seeds. This leaves you open to the risk of human error.
Using the same hashing algorithm removes the need to control reproducibility explicitly in your code with random seeds. As long as you agree with your team on which hashing algorithm to use you will always recreate the same splits. No risk of human error.
Consistent splitting across raw and preprocessed data
During experimentation you might investigate different preprocessing steps and save intermediate and preprocessed data in a new file. You then might load this intermediate data at another stage to continue your analysis.
As the preprocessed data is different to the raw data, using train_test_split and random seeds will give different splits for the raw and preprocessed data when loaded from a new file.
Hashing will provide identical splits for raw and preprocessed data as long as the column used for calculating the hash value has not changed.
Storage and memory efficient
There are other strategies to combat reproducibility (discussed later in this article) such as explicitly saving data in a ‘training’ file and a ‘test’ file or adding a new column to your data to indicate which train/test split the data point belongs to.
However, sometimes you are not able to save data to new files and add columns — for example, if you don’t have permissions to copy or edit the original datasource or the data is too large.
Hashing is deterministic and the data point split can be calculated ‘on the fly’ in memory when required without needing to explicitly change the underlying data or save into a new file.
The Farmhash Algorithm
There are many different hashing algorithms which are used for multiple use cases such as checksums and cryptography.
For the purpose of creating reproducible train/test splitting we need to use a ‘fingerprint’ hash function. Fingerprint hash functions are lightweight, efficient and deterministic — they will always return the same value for the same input.
Cryptographic hash functions, such as MD5 and SHA1, are not suitable for this use case as they are not deterministic and they are also purposefully made to be computationally expensive.
Farmhash is developed by Google and recommended for this use case . It has a simple Python library implementation and is available across many other languages including BigQuery SQL .
Another alternative to Farmhash is to use zlib and the crc32 checksum algorithm. An example of the implementation is shown in this notebook from Hands-on Machine Learning with Scikit-Learn, Keras and TensorFlow
Below is a demo of farmhash and how we can use it to assign buckets to our data points.
Demo
# install Python library
# ! pip install pyfarmhash
We can hash a data point using its unique identifier (i.e. an ID or concatenation of column values).
Let’s start by converting an individual ID into a hashed integer value using farmhash’s fingerprint64 function.
import farmhash
example_id = "0001"
hashed_value = farmhash.fingerprint64(example_id)
print(hashed_value)
6241004678967340495
We can now assign this datapoint to a ‘bucket’ using an arbitrary function.
A useful method for this can be to use the modulo function. The integer outputs from the hashing algorithm are randomly distributed, therefore using the modulo function with a divisor of 10, for example, will split the data into 10 random buckets (from 0 to 9).
# assign a bucket using the modulo operation
bucket = hashed_value % 10
print(bucket)
5
Therefore, our datapoint ID of “0001” would be assigned to bucket 5. When we use a divisor of 10 we will have 10 different buckets. Therefore, for example, we could assign all data points with a bucket of ‘1’ to the test set to use 10% of the data for testing.
Splitting the dataset using Farmhash
Now let’s apply this splitting strategy to our dataset.
The hash_train_test_split function below can be used to split a dataframe into training and test sets using a specified hash function. In this example, the function creates a new column to store the bucket assignments. This is just for demonstration purposes, there is no need to actually store the bucket values in your data as the bucket can be calculated reproducibly ‘on the fly’ from the row ID.
As before, we will create a train/test split using the original breast cancer dataset, but use the hashing method with Farmhash instead of sklearn’s train_test_split with random seeds.
Then we will shuffle the data, split the data again and compare the test set IDs to ensure the splits are the same.
# create a training and test set from original dataset using hashing method
x_train_hash, x_test_hash = hash_train_test_split(
df,
split_col="index",
approx_test_ratio=TEST_RATIO,
)
# create a training and test set from shuffled dataset using hashing method
x_train_hash_shuffled, x_test_hash_shuffled = hash_train_test_split(
df_shuffled,
split_col="index",
approx_test_ratio=TEST_RATIO,
)
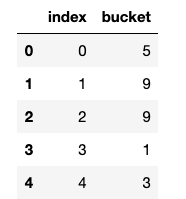
# show which bucket each row has been assigned for demo purposes
x_train_hash[["index", "bucket"]].head()
# compare the row ids included in each test set
set(x_test_hash["index"]) == set(x_test_hash_shuffled["index"])
True
Problem solved! Even though the underlying dataframe was shuffled, the same row ids appear in the test dataset regardless.
Considerations
The hashing method is a little (although not much) more complicated than the common Sklearn train_test_split. As such, there are some additional important things to think about and be aware of when implementing this approach.
Hashing will not split your data exactly according to your specified train/test ratio
The output integers from the hashing algorithm are consistent but still random. By statistical chance, you may have slightly more outputs assigned to a particular bucket which means you might not get exactly 10% of your data being assigned to the test set. It might be slightly more or less. This is why I named the argument in the hash_train_test_split function ‘approx_test_ratio’ as the result will only be approximately that ratio.
In our example above, we specified a ratio of 0.1 and would expect a test set size of 56. However, we actually ended up with only 46 records in the test set (8%).
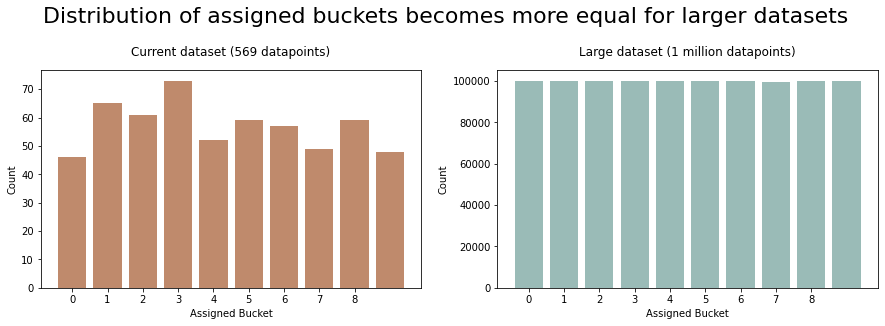
The larger your dataset, the more uniform the bucket assignments will be and the closer to your desired ratio the splits will become (law of large numbers).
Generally this should not be a problem though. Using a 90:10 train/test split is arbitrary. In reality, it doesn’t matter if your split is a little over or under this target ratio.
How many buckets should you choose?
I.e. which number should you use as the divisor for the modulus operation.
This really depends on granularity of the desired test split. If you want to have a split of 90:10 you can split your data into 10 buckets using ‘10’ as the divisor. Then choose one of the buckets to be your test set which will be approximately 10% of your data points.
If you want 15% of your data for testing, you could use 100 as the divisor to split the data into 100 buckets. You could randomly choose 15 buckets from your data to get 15% of your data for testing.
Platform cross-compatibility quirks
Having said that the hashing approach is consistent across platforms. That is true to an extent.
I won’t go into extra detail here. A more detailed discussion on the ‘gotchas’ using hashing to split data in BigQuery vs Python can be found in the original article on my blog:
tl;dr: Just be careful about how different languages deal with applying the modulus function for negative numbers…
Alternatives to hashing
For completeness, here are two other common more explicit approaches for ensuring consistent train/test splitting.
Create an additional column in your data
You could use train_test_split (or another random splitting method) to initially define the splits. Then create an additional column in your dataset to explicitly record whether the data point should be included for training or test (or specify the fold for K-Fold validation).
Here is an example implementation by Abhishek Thakur who uses it to define the ‘folds’ for cross validation.
This will ensure your splits are ‘remembered’ between training runs as they are explicitly defined.
On the positive side, it is very transparent which data points belong to each split. However, a downside is that it increases the total size of your dataset which may not be sustainable for very large datasets. Additionally, if you do not have full control of the dataset (e.g. shared database table) you may not be able to add columns to the original schema.
Save your training and test data to different files
Another common approach is to store your training data and test data to individual files after splitting the data for the first time. For example, into files called train.csv and test.csv. If the data is too large for individual files you could also save multiple files into folders named train and test respectively.
This can be a valid approach. However, sometimes it may not be feasible to make a copy of all your data and save into individual files. For example, if the dataset size is very large or you don’t have the permissions to make a copy from the original source.
The hashing approach can compute the deterministic data splits reproducibly on the fly and in-memory, preventing the need to copy data into individual files.
Conclusion
Sklearn’s train_test_split works well for introductory tutorials and small static datasets, however, in the real-world things get more complicated.
Reproducibility is key for sustainably deploying ML models. The Sklearn train_test_split is surprisingly sensitive to changes in the underlying data and may not be appropriate, particularly if you add new data to your existing data.
Hashing decouples an individual data point’s train/test assignment from the rest of the dataset. This results in a more robust method for splitting your data.
Hashing is a great solution, however, it can be overkill. If you are completing a one-off training on a small static dataset, Sklearn’s train_test_split with a random seed will be sufficient. However, hashing is a great addition to a data scientist’s toolbox to improve reproducibility and protect against unexpected changes in model performance.
Happy coding!
This article was originally published on my blog, engineeringfordatascience.com
Code for the article can be found in this GitHub repository
References & Resources
Hashing
- ML Design Pattern: Repeatable sampling (inspiration for this post)
- Hash your data before you create the train-test split
- Farmhash Algorithm Description
- Python Farmhash library
- Different hashing implementation from Hands-on Machine Learning with Scikit-Learn, Keras and TensorFlow also see notebook
- Google documentation: Considerations for Hashing
Reproducible ML: Maybe you shouldn’t be using Sklearn’s train_test_split was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3RK0rjI
via RiYo Analytics







No comments