https://ift.tt/5xpJnBt What are adversarial attacks and How to protect your embedded devices from those Image by author A Quick Intro ...
What are adversarial attacks and How to protect your embedded devices from those

A Quick Intro
With very limited options for adversarially robust Deep Neural Networks (DNN) for Embedded Systems, this article attempts to provide a primer on the field and explores some ready-to-use frameworks.
What is an adversarially robust DNN?
Deep Neural Networks have democratized machine learning and inference. There are two primary reasons for that. Firstly, we do not need to find and engineer features from the target dataset — a DNN does that automatically. Secondly, the availability of pre-trained models helps us to quickly create task-specific, fine-tuned / transfer learned models.
Despite their widespread popularity, DNNs have a serious vulnerability, which prevents these networks from being used on real-life safety-critical systems. Although a DNN model is shown to be reasonably robust against random noise, it fails against well-designed, adversarial perturbations to the input.
In computer vision, adversarial attacks alter an input image with small changes in the pixels, such that these changes remain visually imperceptible to humans, but a DNN fails to infer the image correctly. The consequences can be very serious. The traffic sign recognition module of an autonomous vehicle may interpret a left turn as a right turn road sign and fall into a trench! An Optical character recognizer (OCR) may read numbers wrongly, resulting in financial skulduggery.
Fortunately, many dedicated researchers are working hard to create adversarially robust DNN models that cannot be fooled easily by adversarial perturbations.
Is adversarial robustness important for Embedded Vision?
Absolutely. CISCO predicts that the number of Machine-to-machine (M2M) connections will reach 14.7 billion by 2023 [8]; this report [9] from The Linux Foundation expects Edge Computing to have a power footprint of 102 thousand megawatts (MW) by 2028, and Statista predicts 7,702 million Edge-enabled IoT devices by 2030[10]. Many of the Edge Computing applications are embedded vision-related and are often deployed in safety-critical systems. However, there are not many options for adversarial robustness for embedded systems. We are actively researching in this area, and I will be referring to one of our recent research here.
But before delving deep into adversarial robustness for embedded systems, I will give a brief background on the topic in the next section. Readers already familiar with the subject can skip to the next part.
Adversarial Robustness Primer
Adversarial Robustness is a highly popular and fast-advancing research area. One can get a glance at the huge body of research articles dedicated to this area in this blog [1].
The biggest concern about an adversarial image is that it is almost impossible to spot that an image has been tampered with.
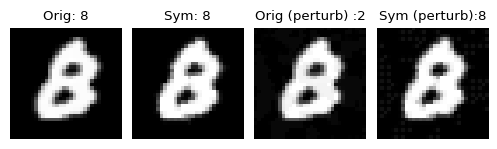
For example, the above image of a handwritten digit 8 from the MNIST dataset [15] is misclassified as a digit 2 by a standard Convolutional Neural Network (CNN) inference. Can you identify any significant difference between the image in Column 1 and Column 3? I could not.
Well, CNN did. The adversary made some minute changes, which are not important to the human eye, but it wreaks havoc with the CNN decision-making process. However, when we use a robust inference mechanism (denoted by Sym), we see that the attacked image is also correctly classified (Column 4).
Let us think from the other side. Is the picture in Column 3 a digit 2 from any angle? Unfortunately, CNN thinks so. This is a bigger problem. An adversary can tweak any image and coax out a decision favorable to it to fulfill its malicious goals.
In fact, this was how these adversarial examples were invented. As recounted by Ian Goodfellow in this lecture (at around 7 minutes), they were exploring the explanations of why a CNN works so well. In that process, they wanted to inflict small changes to images of different classes, such that these turn into an image of the Airplane class. While they expected some kind of airplane specific features (say, wings) to become manifested in a Ship image, nothing of that sort happened. After some changes to the image, their CNN started to confidently infer an image that completely looked like a Ship, as an Airplane.
Now, with that basic overview, let me quickly summarize the key points one needs to know, to get started with Adversarial Robustness:
- Adversarial Attacks are optimization algorithms to find example inputs for which a DNN makes an incorrect decision. Intriguingly, such examples are not at all difficult to find, rather they exist almost everywhere in the input manifold. Although a standard, empirical risk minimization-based training method may not include such examples while training a DNN model.
- A good adversarial attack quickly finds out the most effective adversarial examples. An effective adversarial image is visually similar ( in terms of a distance metric) to the original image, but forces the model to map it to a different decision boundary, than the original. The distance metric is either Manhattan distance (L1 norm), Euclidean distance (L2 norm), or Chebyshev distance (L∞ norm).
- If the goal of the adversary is to force the DNN to map the decision to any wrong class, it is called an untargeted attack. In contrast, in a targeted attack, the adversary forces the DNN to map to a particular class desired by the adversary.
- Perturbations are measured in change per pixel and is often denoted by ϵ. For example, an ϵ of 0.3 would mean that each pixel of the clean example (original image) undergoes a maximum change of 0.3 in the corresponding adversarial example.
- The accuracy of a DNN measured with clean images and adversarial images is often referred to as clean accuracy and robust accuracy, respectively.
- An adversary can attack a DNN inference without having access to a model, training details, and only a limited estimate about the test data distribution. This threat model is called a complete blackbox setting [2]. This can be as simple as attaching a small physical sticker on a real object, which the DNN is trying to infer. On the other extreme, a complete whitebox setting refers to an attack model where the model, training details, and even the defense mechanism are known to an adversary. This is considered the acid test for an adversarial defense. Different attacks and defenses are evaluated under intermediate levels of the above two settings.
- An adversarial defense aims to thwart adversarial attacks. Adversarial robustness can be achieved by empirical defenses e.g., adversarial training using adversarial examples, or heuristic defenses e.g. pre-processing attacked images to remove perturbations. However, these approaches are often validated through experimental results, using the then attacks. There is no reason why a new stronger adversary can not break these defenses later. This is exactly what is happening in adversarial robustness research and is often referred to as a cat and mouse game.
The adversarial research community aims to solve this catching-up game highlighted in the last point. The current research focus in that field is developing certified and provable defenses. These defenses modify the model operations such that those are provably correct for a range of input values or perform randomized smoothing of a classifier using Gaussian noise, etc.
Adversarial Robustness For Embedded Vision Systems?
The adversarial research community is not focusing on the adversarial robustness of embedded systems, as of now. This is perfectly normal, as the field itself is still shaping up.
We have seen the same trend with Convolutional Neural Networks. After AlexNet [12] won the ILSVRC challenge in 2012 [14], it took four years before DeepCompression [11] pioneered in generating small pruned models. However, at that period there was no way to fully exploit these pruned models as there was no established hardware support to exploit sparsity during CNN inference. Recently, such supports are getting developed, and researchers are running CNN even on micro-controllers.
An adversarial defense for an embedded system must be very low overhead in terms of size, runtime memory, CPU cycles, and energy consumption. This immediately disqualifies the best available option, namely, the adversarially trained models. These models are huge, ~500 MB for CIFAR-10 (see here). As aptly explained in this paper [3], the adversarially trained models tend to learn much more complex decision regions, compared to the standard models. The provably robust defenses are yet to scale for real-life networks. The heuristic defenses that use a generative adversarial network (GAN) or autoencoders to purify attacked images are too resource-heavy for embedded devices.
That leaves only simple heuristic input transformation-based defenses as only options for resource-limited devices. However, as shown in the seminal works [4–5], all such defenses rely on some form of gradient obfuscation, and can eventually be broken by a strong adaptive attack. The way such defenses can bring in some benefits is to make the transformation very strong. This cannot defend against a strong adaptive attack, but the time to break the transform would depend on the computing resources accessible to the adversary.
One such successful work [6], uses a series of simple transforms e.g., reducing bit-resolution of color, JPEG compression, noise injection, etc. which together defend against the Backward Pass Differentiable Approximation (BPDA) attack introduced in [4]. Unfortunately, there is no public implementation of this paper to try out.
Another recent work [7] uses input discretization to purify adversarial images before DNN inference. In the purification process, the pixel values of an image, lying in an unrestricted real number domain, are transformed into a restricted set of discrete values. As these discrete values are learned from large clean image datasets, the transform is difficult to break, and the replacement removes some adversarial perturbations.
Some hands on…
First, let us see a few sample attacks to create some adversarial images.
We can use any existing libraries e.g. Foolbox, Adversarial-attacks-pytorch, ART…, and so on.
Here is an example of attacking and creating adversarial examples with adversarial-attacks-pytorch using the implementation of AutoAttack [13]:
from torchattacks import *
attack = AutoAttack(your_dnn_model, eps=8/255, n_classes=10, version='standard')
for images, labels in your_testloader:
attacked_images = attack(images, labels)
Here is another example of attacking and creating adversarial examples with Foolbox using the Projected Gradient Descent attack [3]:
import foolbox
attack = foolbox.attacks.PGD(your_dnn_model)
for images, labels in your_testloader:
attacked_images = attack(images, labels)
These attacked_images can be used to perform inference with a DNN.
Next, let us try defending the attacks with SymDNN. The first step in using this library is to clone or download the repository from this link.
The next step is installing the dependencies for SymDNN. The steps for this and the python optional virtual environment setup is described in the README file of the repository.
Next, we need to set up some default parameters for discretization. The default values provided work fine for several datasets and attacks. We can tweak these later for inference robustness-latency-memory tradeoff.
# For similarity search
import faiss
import sys
sys.path.insert(1, './core')
# function for purification of adversarial perturbation
from patchutils import symdnn_purify
# Setup robustness-latency-memory tradeoff parameters, defaults are good enough, then call the purification function on attacked image
purified_image = symdnn_purify(attacked_image, n_clusters, index, centroid_lut, patch_size, stride, channel_count)
These purified images can be used for further inference using the DNN. This purification function is extremely low-overhead in terms of processing and memory, suitable for embedded systems.
SymDNN repository contains many examples of attacks on CIFAR-10, ImageNet & MNIST under several attacks and different threat models.
Here is an example of attacking and creating an adversarial example with the BPDA attack [4] implementation in SymDNN, taken from here:
bpda_adversary16 = BPDAattack(your_dnn_model, None, None, epsilon=16/255, learning_rate=0.5, max_iterations=100)
for images, labels in your_testloader:
attacked_images = bpda_adversary16.generate(images, labels)
The attack strength, iterations, etc. hyperparameters are explained in the original paper [4] and are in general dependent on the application scenario.
Conclusions
Although Adversarial Robustness is a well-investigated area, we believe that there are several dots to connect before it can be successfully deployed in the field, especially in Edge Computing scenarios. The SymDNN defense we presented, is not capable of undoing all attacks. However, it is something that can be readily used for making embedded vision systems robust against some adversarial attacks. With embedded AI (Artificial Intelligence) poised to grow rapidly in the future, having something at hand to protect those is better than nothing.
References
[1] Nicholas Carlini, A Complete List of All (arXiv) Adversarial Example Papers (2019), https://nicholas.carlini.com/writing/2019/all-adversarial-example-papers.html
[2] Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z. Berkay Celik, and Ananthram Swami, Practical black-box attacks against machine learning (2017), In Asia Conference on Computer and Communications Security 2017
[3] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu, Towards deep learning models resistant to adversarial attacks (2018), In ICLR 2018
[4] Anish Athalye, Nicholas Carlini, and David A. Wagner, Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples (2018). In ICML 2018
[5] Florian Tramèr, Nicholas Carlini, Wieland Brendel, and Aleksander Madry, On adaptive attacks to adversarial example defenses (2020). In NeurIPS 2020
[6] Edward Raff, Jared Sylvester, Steven Forsyth, and Mark McLean, Barrage of random transforms for adversarially robust defense (2019) In CVPR 2019
[7] Swarnava Dey, Pallab Dasgupta, and Partha P Chakrabarti, SymDNN: Simple & Effective Adversarial Robustness for Embedded Systems (2022), In CVPR Embedded Vision Workshop 2022
[8] CISCO, Cisco annual internet report (2018–2023), https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11–741490.html
[9] The Linux Foundation, State of the edge 2021 (2021) https://stateoftheedge.com/reports/state-of-the-edge-report-2021/
[10] Statista, Number of edge enabled internet of things (iot) devices worldwide from 2020 to 2030, by market(2022),https://www.statista.com/statistics/1259878/edge-enabled-iot-device-market-worldwide/, 2022
[11] Song Han, Huizi Mao, William J. Dally, Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding (2016), ICLR 2016
[12] A. Krizhevsky, I. Sutskever, and G. E. Hinton, Imagenet classification with deep convolutional neural networks (2012), In NeurIPS 2012
[13] Francesco Croce, and Matthias Hein, Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks (2020), ICML 2020
[14] Olga Russakovsky*, Jia Deng*, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg and Li Fei-Fei. (* = equal contribution) ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015
[15] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, November 1998
Adversarial Robustness For Embedded Vision Systems was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/5T0FECL
via RiYo Analytics








ليست هناك تعليقات