https://ift.tt/czjYnZt A Simple Solution for Increasing Resource Utilization and Accelerating Training Photo by Anders Norrback Bornholm ...
A Simple Solution for Increasing Resource Utilization and Accelerating Training

One of the measures of the health of a deep learning project is the degree to which it utilizes the training resources that it was allocated. Whether you are training in the cloud or on your own private infrastructure, training resources cost money, and any block of time in which they are left idle represents a potential opportunity to increase training throughput and overall productivity. This is particularly true for the training accelerator — typically the most expensive training resource — whether it be a GPU, a Google TPU, or a Habana Gaudi.
This blog is a sequel to a previous post on the topic of Overcoming Data Preprocessing Bottlenecks in which we addressed the undesired scenario in which your training accelerator, henceforth assumed to be a GPU, finds itself idle while it waits for data input from an overly tasked CPU. The post covered several different ways of addressing this type of bottleneck and demonstrated them on a toy example, all the while emphasizing that the best option would very much depend on the specifics of the model and project at hand. Some of the solutions that were discussed were:
- Choosing a training instance with a CPU to GPU compute ratio that is more suited to your workload,
- Improving the workload balance between the CPU and GPU by moving some of the CPU operations to the GPU, and
- Offloading some of the CPU computation to auxiliary CPU-worker devices.
The third option was demonstrated using the TensorFlow Data Service APIs which, with just a single line of code, enable you to program a portion of your pre-processing pipeline to run on one or more pre-configured remote devices. We showed how by applying the tf.data service to our toy example, we were able to completely eliminate the CPU bottleneck and maximize the GPU utilization. Sounds great, right? Sadly, this compelling solution has two significant limitations:
- It is limited to the TensorFlow framework, and
- Even within the TensorFlow framework, the tf.data service is limited to pipelines that are programmed using only native TensorFlow operations. This can be a confining constraint as many pre-processing pipelines require operations that do not have built in TensorFlow equivalents.
The goal of this post is to demonstrate a more general way of offloading pre-processing to auxiliary devices using gRPC, the same protocol underlying the TensorFlow data service.
Although the examples in this post will be based on PyTorch 1.10 and Amazon EC2, the technique we will describe can be applied to other training frameworks and infrastructures as well. Please keep in mind that by the time you read this some of the libraries that we use may have changed in ways that may require some tweaking to the code samples we share.
The CPU bottleneck in Action
As a toy example we will use the following PyTorch model loosely based on this official MNIST example.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import time
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
class MyMNIST(datasets.MNIST):
'''
A personalized extension of the MNIST class in which we
modify the __len__ operation to return the maximum value
of int32 so that we do not run out of data.
'''
def __len__(self) -> int:
import numpy as np
return np.iinfo(np.int32).max
def __getitem__(self, index: int):
return super(MyMNIST,self).__getitem__(index%len(self.data))
def main():
from torch.profiler import profile, schedule, \
ProfilerActivity, tensorboard_trace_handler
profiler = profile(activities=[ProfilerActivity.CPU,
ProfilerActivity.CUDA],
schedule=schedule(wait=120, warmup=5,
active=20, repeat=0),
on_trace_ready=tensorboard_trace_handler(
dir_name='profile'),
profile_memory=True)
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
train_kwargs = {'batch_size': 8192,
'num_workers': 8,
'pin_memory': True
}
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset = MyMNIST('/tmp/data', train=True, download=True,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset,
**train_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters())
model.train()
t = time.perf_counter()
for idx, (data, target) in enumerate(train_loader, start=1):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
profiler.step()
if idx % 100 == 0:
print(
f'{idx}: avg step time: (time.perf_counter()-t)/idx}')
if __name__ == '__main__':
main()
Our goal in the following sections will be to compare the training throughput in different scenarios. We will not concern ourselves with whether the model converges. As a measure of the training throughput, we will use the average number of samples that are fed into the model per second. Since our goal is to maximize throughput, we increase the batch size to the point where either the value step-time/batch-size reaches a minimum or we run out of memory. We further overwrite the built-in PyTorch MNIST Dataset so that we will not run out of data samples.
When running the above script on an Amazon EC2 p3.2xlarge instance (with the Deep Learning AMI (Ubuntu 18.04) Version 60.1 and built-in pytorch_p38 conda environment), we recorded an average step time of 0.33 seconds, or an average throughput of ~26 thousand samples per second.
As is typical of common deep learning training jobs the model training (including the forward pass and gradient calculation) is computed on the GPU while the training data is loaded and pre-processed on the CPU cores before being passed to the GPU. In the use case we wish to study, the pre-processing pipeline is not able to keep up with the speed of the GPU. As a result, the GPU will be intermittently idle as it waits for data input from the CPU. We demonstrate this phenomenon by adding a relatively heavy blurring operation to the pre-processing pipeline.
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
transforms.GaussianBlur(11)
])
When we rerun the script with the above change, the step time jumps to 1.01 seconds and the throughput drops to ~8 thousand samples per second. We emphasize that there has been no change to the training graph running on the GPU; the significant slowdown in the training speed is a result of the compute heavy pre-processing pipeline running on the CPU.
In the training loop above we have enabled the built-in PyTorch profiler. A summary of the collected profile in the case of our input bottleneck can be viewed in TensorBoard.
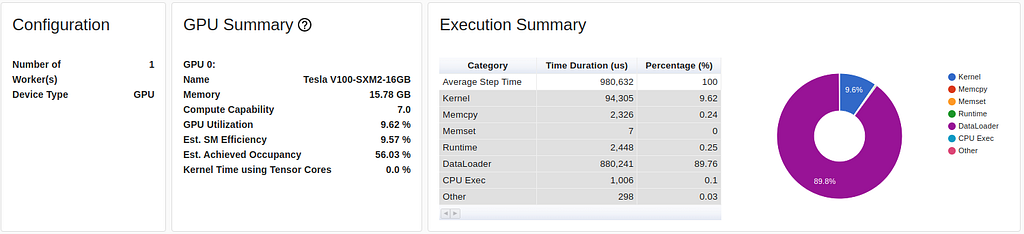
The profiling report shows the GPU utilization to be below 10% with nearly 90% of the training step time focused on loading and processing the training data.
It should be noted that closer analysis would show that a data input bottleneck, although less severe, occurs even in our baseline run, absent the heavy blur operation. We will see evidence of this later when we are able to demonstrate a step time as low as 0.17 seconds.
One of the ways to overcome a bottleneck in the data input pipeline is to offload a portion of the data pre-processing work to one or more auxiliary CPU devices. In the next section we explore how to do this using the gRPC protocol.
Offloading Data Processing Using gRPC
In a remote procedure call (RPC) system a client-server interface is defined with the server implementing the specified methods which can be called remotely by a client. In what follows we will define a dedicated gRPC service for extracting processed training batches using Protocol Buffers. The server and client will be implemented in Python following this introductory tutorial.
The GRPC Interface
We create a protobuf file named data_feed.proto that defines a DataFeed service with a single get_samples method:
syntax = "proto3";
service DataFeed {
rpc get_samples(Config) returns (stream Sample) {}
}
message Config {
}
message Sample {
bytes image = 1;
bytes label = 2;
}
The method is defined to return a stream of type Sample, where each sample represents a training batch consisting of batch_size images and their associated labels.
As described in the tutorial, the command below will generate the corresponding gRPC Python files, data_feed_pb2.py and data_feed_pb2_grpc.py, that we will use to implement the server and client.
python -m grpc_tools.protoc -I<protos folder> --python_out=<out_path> --grpc_python_out=<out_path> <path to proto file>
The GRPC Server
The next step is to implement our data feeding gRPC server.
import multiprocessing as mp
from concurrent import futures
import grpc
import data_feed_pb2
import data_feed_pb2_grpc
import torch
from torchvision import datasets, transforms
import numpy as np
# The following class implements the data feeding servie
class DataFeedService(data_feed_pb2_grpc.DataFeedServicer):
def __init__(self, q):
'''
param q: A shared queue containing data batches
'''
self.q = q
def get_samples(self, request, context):
while True:
sample = self.q.get()
yield data_feed_pb2.Sample(image=sample[0],
label=sample[1])
# The data loading and preprocessing logic.
# We chose to keep the existing logic unchanged, just instead
# of feeding the model, the dataloader feeds a shared queue
class MyMNIST(datasets.MNIST):
def __len__(self) -> int:
return np.iinfo(np.int32).max
def __getitem__(self, index: int):
return super(MyMNIST,self).__getitem__(index%len(self.data))
def fill_queue(q,kill):
train_kwargs = {'batch_size': 8192, 'num_workers': 16}
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
transforms.GaussianBlur(11)
])
dataset = MyMNIST('/tmp/data', train=True,
transform=transform, download=True)
loader = torch.utils.data.DataLoader(dataset, **train_kwargs)
for batch_idx, (data, target) in enumerate(loader):
added = False
while not added and not kill.is_set():
try:
# convert the data to bytestrings and add to queue
q.put((data.numpy().tobytes(),
target.type(torch.int8).numpy().tobytes()),
timeout=1)
added = True
except:
continue
def serve():
'''
Initialize the data batch queue and start up the service.
'''
q = mp.Queue(maxsize=32)
kill = mp.Event() # an mp.Event for graceful shutdown
p = mp.Process(target=fill_queue, args=(q,kill))
p.start()
server = grpc.server(futures.ThreadPoolExecutor(max_workers=8))
data_feed_pb2_grpc.add_DataFeedServicer_to_server(
DataFeedService(q), server)
server.add_insecure_port('[::]:50051')
server.start()
server.wait_for_termination()
kill.set()
p.join()
if __name__ == '__main__':
serve()
As described in the code documentation, we have chosen an implementation that keeps the data loading logic intact and where data batches are entered into a shared queue. The get_samples function of the DataFeedService pulls batches from the same queue and sends them to the client in the form of a continuous data stream.
The script includes a few constant values that should be tuned (or auto-configured) based on the manner in which the gRPC based solution will be deployed:
- The max_workers setting of the gRPC server’s ThreadPoolExecutor should be configured according to the number of gRPC clients you intend to create. Since we plan to create one client for each CPU core on the training device, and our EC2 p3.2xlarge instance has 8 vCPUs, we have set this to 8.
- The num_workers setting of the train_kwargs structure that is input to the DataLoader should be configured to the number of vCPUs on our server instance. The instance we intend to use is the EC2 c5.4xlarge consisting of 16 vCPUs and we have set num_workers accordingly.
- For the maxsize value of the shared queue we have simply chosen twice the value of num_workers.
We should emphasize that there are many different ways of implementing a data feeding server. The implementation we have demonstrated here is not necessarily the most optimal for use cases such as our toy problem. More on this below.
The GRPC Client
Lastly, we modify our training script so as to consume the processed training data from the gRPC server. The block below includes the modifications:
class RemoteDataset(torch.utils.data.IterableDataset):
'''
An iterable PyTorch dataset that opens a connection to the
gRPC server and reads from a stream of data batches
'''
def __iter__(self):
import grpc
import data_feed_pb2_grpc
import data_feed_pb2
import numpy as np
host = '<ip of host>'
channel = grpc.insecure_channel(f'{host}:50051',
# overwrite the default max message length
options=[('grpc.max_receive_message_length',
200 * 1024 * 1024)])
stub = data_feed_pb2_grpc.DataFeedStub(channel)
samples = stub.get_samples(data_feed_pb2.Config())
for s in samples:
image = torch.tensor(np.frombuffer(s.image,
dtype=np.float32)).reshape(
[8192, 1, 28, 28])
label = torch.tensor(np.frombuffer(s.label,
dtype=np.int8)).reshape(
[8192]).type(torch.int64)
yield image, label
def main():
device = torch.device("cuda")
train_kwargs = {'batch_size': None, #the data is already batched
'num_workers': 8,
'pin_memory': True
}
dataset = RemoteDataset()
train_loader = torch.utils.data.DataLoader(dataset,
**train_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters())
train(model, device, train_loader, optimizer)
We have defined an iterable PyTorch dataset, RemoteDataset, that opens a connection to the gRPC server and reads from a stream of data batches. The number of DataLoader workers is set to 8, the number of vCPUs on the training instance. As a result, a total of 8 gRPC clients will be created.
Once again, we emphasize that the gRPC client implementation was chosen mostly for its simplicity and that more optimal implementations are likely to exist.
Results
The time has come to measure the extent to which our gRPC solution has succeeded in alleviating our CPU bottleneck. The table below summarizes the throughput results we received when running the data server on the EC2 c5.4xlarge and EC2.9xlarge instances. For the EC2.9xlarge experiment, we updated the constant parameters to reflect the presence of 36 vCPUs.
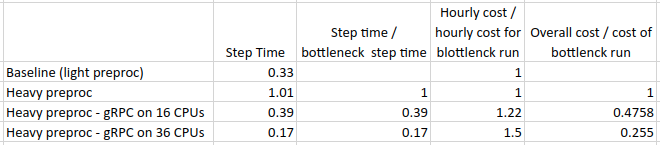
Using a 16 vCPU worker enables us to accelerate training by ~60% and a 36 vCPU worker by over 80%. Taking the hourly cost of the EC2 instances into account (at the time of this writing, $3.06 for a p3.2xlarge, $0.68 for a c5.4xlarge, and $1.53 for a c5.9xlarge), we find that offloading data processing onto a 16 vCPU worker results in over 50% cost savings and onto a 36 vCPU worker ~75% savings. We should note that our cost calculation does not take into account the potential gains from the accelerated development time (e.g. freeing up both human and computation resources for other tasks).
We should note that the c5.9xlarge experiment resulted in a lower step time than our baseline experiment. This is evidence that even the baseline experiment was not maximizing GPU utilization and that it too suffered from a bottleneck on the data input pipeline.
The below TensorBoard screenshot summarizes the training performance for the c5.9xlarge case:
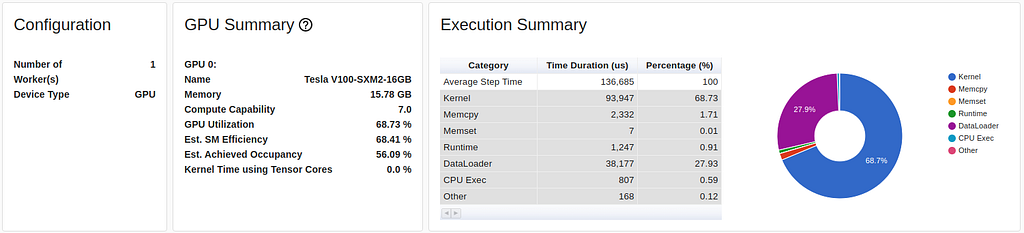
While the severity of the bottleneck has decreased significantly, it is apparent that there is still room for further optimization as the GPU remains roughly 30% idle.
Notes on the Implementation
We conclude this section with a few general notes on the gRPC based solution and the specific implementation we have demonstrated.
Explore All Options: While the notion of eradicating a CPU bottleneck in the manner we have described may be very compelling, you would be well advised to consider other alternatives before adopting the gRPC based solution. You might find that, without great difficulty, you can optimize your data processing to utilize the CPU more efficiently, or that a different type of training instance contains a CPU compute to GPU compute ratio that better suits your workload.
Optimize Load Balancing: In the solution we have demonstrated we chose to offload the entire pre-processing pipeline to the gRPC server. However, this may result in severe under-utilization of the CPU cores on the training instance. A more efficient solution would be to use the minimal number of total CPUs required to keep the GPU fully active and balance the load between the CPUs on the training instance and the auxiliary CPUs in such a way that they are all fully utilized. This might be accomplished by running the beginning of the pre-processing pipeline on the gRPC server and sending over the partially processed data to the training instance for completion of the pipeline.
Beware of Network-IO Bottlenecks: One of the things to be conscious of is the amount of data being passed from the server to the client. Otherwise, we may end up replacing the CPU bottleneck with a network bottleneck. The network IO bandwidth limits are determined by the properties of both the server and client instances. One option to consider in order to reduce bandwidth is to take advantage of the compression support built into the gRPC protocol.
Extension to Multi GPU: While the solution we have set forth can be extended to support a multi-GPU — data distributed setting without great difficulty, the details of how to do this can vary. Depending on your project you may opt for a single gRPC server instance and a single service that feeds all GPU cores, multiple services on a single instance, multiple server instances, or some other combination.
Multiprocessing Issues with Python GRPC: Be aware that the Python implementation of gRPC has limitations when it comes to forking processes. This could interfere with the PyTorch data loader which relies on multiprocessing for its multi work support. Any implementation of the gRPC server and client needs to negotiate this potential conflict. See here for more details on this limitation.
Comparison to tf.data service: Similar to the solution we have presented, tf.data service also relies on the gRPC protocol under the hood. However, contrary to our solution, it is based on a C++ gRPC which has fewer limitations and is likely to be more optimal. Furthermore, the tf.data service hides many details of the gRPC implementation from the user, to the extent that offloading operations to the data service is reduced to adding just one line of code to the input pipeline. This makes it especially easy to find the most optimal point in the pipeline to perform the offloading. Our solution, by comparison, requires more effort. If your workload is compatible with tf.data service, it quite likely will result in better performance and is probably the better option. However, as we already mentioned, as of the time of this writing, the tf.data service is limited to pipelines that contain only native TensorFlow operations. The gRPC based solution we have described is far more flexible — not only does it enable greater freedom in building your input pipeline but it also allows greater control over how tasks are distributed among the CPU workers.
Summary
The advances in AI of the past years are owed, in part, to the availability of powerful training accelerators. It is our opinion that we, as developers, have a responsibility to pay attention to how we are using this specialized machinery so as to maximize efficiency, increase cost savings, and reduce carbon emissions. This article has focused on one of the options at our disposal for increasing resource utilization — offloading data pre-processing to one or more auxiliary CPU instances.
As always, feel free to reach out with comments, questions, and corrections.
Overcoming ML Data Preprocessing Bottlenecks With gRPC was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/rbPxB97
via RiYo Analytics









No comments