https://ift.tt/zBD3MN4 Perform rapid loss-function prototypes to take full advantage of XGBoost’s flexibility Photo by Matt Artz on Uns...
Perform rapid loss-function prototypes to take full advantage of XGBoost’s flexibility

Motivation
Running XGBoost with custom loss functions can greatly increase classification/regression performance in certain applications. Being able to quickly test many different loss functions is key in time-critical research environments. Thus, manual differentiation is not always feasible (and sometimes even prone to human errors, or numerical instability).
Automatic differentiation allows us to automatically get the derivatives of a function, given its calculation. It does so by representing our function as a composition of functions with known derivatives, requiring zero effort from the developer’s side.
We will start with a quick introduction, clarifying our problem. Then, we will dive into the implementation of automatic differentiation with PyTorch and JAX and integrate it with XGBoost. Finally, we will perform run-time benchmarks and show that JAX is ~10x faster than PyTorch for this application.
Background
Gradient Boosting is a framework of machine learning algorithms. It outputs predictions based on an ensemble of weak learners, usually decision trees. The weak learners can be optimized according to an arbitrary differentiable loss function, giving us substantial flexibility. We will focus on the case of decision trees as weak learners — Gradient Boosted Decision Trees (GBDT).
In tasks where Neural Networks lack, e.g., tabular data, and small training sets, GBDTs demonstrate state-of-the-art performance.
XGBoost is a popular library that efficiently implements GBDT. It provides a simple interface for writing custom loss functions for our decision trees. Given a custom loss function, all we have to do is provide XGBoost with calculations of its gradient and its Hessian. Let’s see how we can achieve this with automatic differentiation in minutes.
Problem Setting
We will run our experiments over the California Housing dataset, a regression task for predicting house prices.
Our loss function will be the Squared Log Error (SLE):
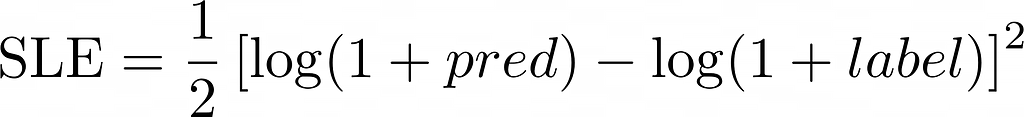
Note that this loss penalizes an under-predicted estimate greater than an over-predicted estimate. It could reflect a real business requirement when predicting house prices, and we are able to fulfill it by choosing a custom loss function.
Let’s apply it in XGBoost.
Automatic Calculation of the Hessian with PyTorch
In the following, we will focus on working with PyTorch, as it is clearer — the comparison to JAX will come later.
Calculating gradients with PyTorch is a familiar workload from Neural Network programming. However, seldom are we required to calculate Hessians. Thankfully, PyTorch has implemented a convenience function for us, torch.autograd.functional.hessian. With these technicalities covered, we can proceed to the implementation.
First, we implement our loss function:
Next, our automatic differentiation:
Putting them together:

And running on real-world data:


This gives us a simple working implementation of automatic differentiation with PyTorch. However, this code does not scale well to large datasets. Thus, in the next section, we will show a more complex approach that improves our run-time.
Run-Time Performance Optimization with JAX
We can achieve considerable run-time speedups if we use JAX correctly. Let's write the PyTorch code from above in JAX:
We change the loss calculation such that it uses jax.numpy (imported as jnp),
And use the respective syntax for automatic differentiation in JAX,
Running on the previous data, in comparison to the PyTorch implementation (Figure 3), we see a ~2x speedup:

Note that we use the hvp (Hessian-vector product) function (on a vector of ones) from JAX’s Autodiff Cookbook to calculate the diagonal of the Hessian. This trick is possible only when the Hessian is diagonal (all non-diagonal entries are zero), which holds in our case. This way, we never store the entire hessian, and calculate it on the fly, reducing memory consumption.
However, the most significant speedup is due to the efficient calculation of the Hessian by “forward-over-reverse differentiation”. The technical details are beyond the scope of this post, you can read about them in JAX’s Autodiff Cookbook.
In addition, we utilize JAX’s JIT compilation to cut the run time even more, by an order of ~3x.
Run-Time Performance Benchmark
Let’s present a more thorough comparison of run-time performance.
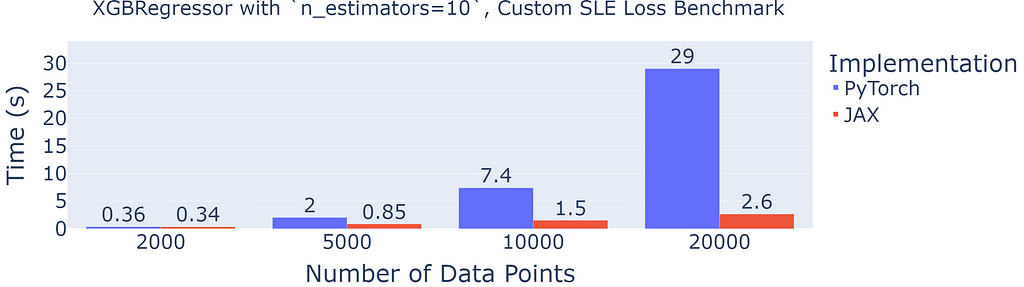
We note that the PyTorch implementation has quadratic run-time complexity (in the number of examples), while the JAX implementation has linear run-time complexity. This is a tremendous advantage, which allows us to use the JAX implementation on large datasets.
Now, let’s compare automatic differentiation to manual differentiation:
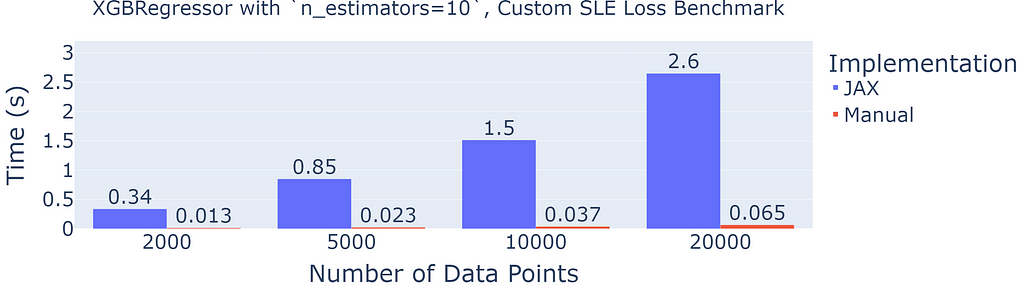
Indeed, in comparison, manual differentiation is blazing fast (40x faster). However, for complex loss functions, or small datasets, automatic differentiation can still be a valuable skill in your toolbox.
The full code for this benchmark can be found here:
GitHub - 1danielr/auto-gb: Automatic Differentiation for Gradient Boosted Decision Trees.
Conclusion
We harnessed the power of automatic differentiation to seamlessly use custom loss functions in XGBoost, with a feasible compromise on run-time performance. Of course, the above code also applies to other popular Gradient Boosting libraries such as LightGBM and CatBoost.
We saw that JAX provides us with substantial speed-ups thanks to its efficient implementation of the Hessian, and transparent utilization of JIT compilation. Moreover, we outlined the few lines of code that allow us to generically calculate gradients and Hessians. Namely, our approach can be generalized to additional workloads that require high-order automatic differentiation.
Thanks for reading! I would love to hear your thoughts and comments 😃
JAX vs PyTorch: Automatic Differentiation for XGBoost was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/P7c2OhB
via RiYo Analytics








ليست هناك تعليقات