https://ift.tt/eXQvWLY Photo by Luca Bravo on Unsplash Create your custom model and upload it on Hugging Face Introduction Often whe...

Create your custom model and upload it on Hugging Face
Introduction
Often when we want to solve an NLP problem, we use pre-trained language models, obviously being careful to choose the most appropriate model that has been fine-tuned on the language of our interest.
For example, if I’m working on a project that is based on the Italian language I will use models such as dbmdz/bert-base-italian-xxl-cased or dbmdz/bert-base-italian-xxl-uncased.
These language models usually work very well on generic text, but often do not fit well when we use them in a specific domain, for example, if we use them in a medical or scientific domain which has its peculiar language.
For this purpose, we need to apply domain adaptation!
Domain adaptation, it’s when we fine-tune a pre-trained model on a new dataset, and it gives predictions that are more adapted to that dataset.
What does fine-tuning mean?
Fine-tuning in NLP refers to the procedure of re-training a pre-trained language model using your own custom data. As a result of the fine-tuning procedure, the weights of the original model are updated to account for the characteristics of the domain data and the task you are interested in.
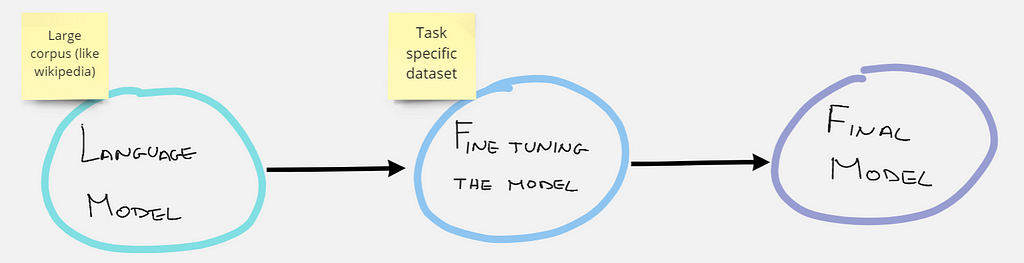
In our case we will fine-tune using a masked language model task (MLM). In other words our dataset will not have prefixed labels, but for each sentence some words will be hidden (masked), and the model will have to guess which are the hidden words.
Dataset
The dataset we are going to use for this purpose is public and can be found on kaggle at this link. This dataset contains around 13k news. We are only interested about the content of the review, so you only need to use the text column. In this article I will not describe the procedure to download the dataset from kaggle and extract the csv file, in case you have problems you can read the other articles I posted on TDS.
Hands-On
Let’s import all the libraries that we will need first.
Let’s define the hyperparameters needed for the model training. (Feel free to play with them if you have enough computational power!)
Let’s start with data preparation. Load your csv file, split it and transform it to a Dataset object.
Now you have to choose your strating model and tokenizer. I like to use distilbert because it’s light and faster to train.
In order to feed the model, we need to tokenize our dataset.
Now we can actually train our model. The DataCollatorForLanguageModeling is a function that allows us to train the model on masked language task very easily.
Perplexity Evaluation
Is the custom model you created really better than the source model? To understand if there have been improvements we can calculate the perplexity of the model! If you are interested in this metric read this article.
Hopefully you noticed an improvement in the model perplexity!
Publish your custom model on Hugging Face!
If you trained your model on a personal dataset, or a particular dataset you created yourself, your model could probably be useful to someone else. Upload it to your Hugging Face account with just a few lines of code!
First of all create a personal account on Hugging Face, and then run the following commands.
Done! Now your model is on Hugging Face and anyone can download and use it! Thank you for your contribution!
Conclusion
If you also enjoyed creating your own custom language model and posting it on Hugging Face, please continue to create new ones and make them available to the community.
If you want to have a look to my model trained on space articles (remote sensors, satellites,…) here it is:
Chramer/remote-sensing-distilbert-cased · Hugging Face
The End
Author : Marcello Politi
Fine-Tuning for Domain Adaptation in NLP was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/GkUWB5M
via RiYo Analytics







ليست هناك تعليقات