https://ift.tt/ctdmbNI Opinion Data Stewards Have the Worst Seat at the Table The data steward has an impossible job. Here’s why and what...
Opinion
Data Stewards Have the Worst Seat at the Table
The data steward has an impossible job. Here’s why and what we can do to empower them.

In his seminal 2017 blog post, The Downfall of the Data Engineer, Maxime Beauchemin wrote that the data engineer had the worst seat at the table.
Data technology and teams have changed tremendously since that time, and now the Preset CEO and creator of Apache Airflow and Apache Superset has a brighter outlook on the future of the profession.
I have also seen what was once a thankless position turn into a strategic driver of company value as data expanded beyond dashboards to machine learning models, customer-facing applications, and systems of record.
So, if the data engineer no longer has the worst seat at the table, who then on the data team has inherited this unfortunate title?
When you infer some of Maxime’s original criteria–tedious tasks, low recognition, a lack of authority, and victim of operational creep–the data steward becomes the obvious choice.
Before you fire off your angry tweets, I don’t say this out of a disdain for these increasingly critical professionals. Quite the opposite in fact.
The data steward role is designed to solve some of the hardest challenges in data today: governance, compliance, and access. The remarkable people who don this hat have stared into the eye of the big data storm and taken a step forward.
Unfortunately, they are rarely set up for success.
Here’s why.
The evolution of the data steward
The 2000s is the era that birthed the first semblance of the data steward role as we recognize it today. This was also, uncoincidentally, directly following the introduction of the World Wide Web, email, and widespread use of personal computers.
From the start, the data steward role was heavily intertwined with data governance and metadata management. However, stewards also took on leadership across initiatives designed to tame the “5 v’s” of big data: volume, value, variety, velocity, and veracity.
This meant responsibilities like data quality, accessibility, usability, change management, business intelligence, and compliance would often fall under the steward’s purview.
Over the next 15 years, monolithic data governance initiatives launched from C-suite ivory towers and designed to catalog every data asset would buckle under their own weight.
Then in 2016, the European Union announced GDPR, a groundbreaking and far reaching data privacy regulation with severe financial penalties for non-compliance. This would usher in a tidal wave of new data focused regulations across regions, countries, and even states (hello CCPA!).
To comply, organizations realized that they needed to have a better idea of where their PII and sensitive data was and how it flowed through their systems.
Much of this started to fall to information security and privacy teams that were well versed in specific regulations, but it did help bring the data steward a bit closer to the action.
Data team comparisons
Since we’re data people, let’s make this analysis a bit more quantitative before diving into additional factors that have made the data steward role less attractive over time.
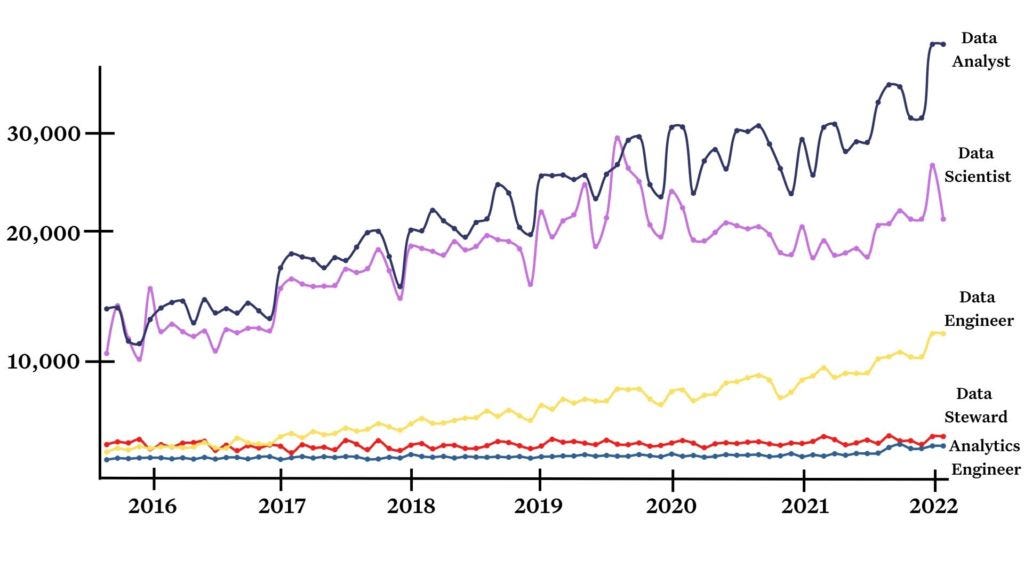
If we consider overall search volume to be a rough representation of demand and interest in a particular field, we can see the data steward has remained relatively static over the last 6 years or so.
Meanwhile, the former occupant of the worst seat at the table, data engineer, surpassed data steward search volume in 2016 and has grown 18x in that time period.
Even a newer role such as analytics engineer has similar volume, but has grown 8x in the last 6 years.
Of course, search volume does not measure the value of a role or the overall job satisfaction. Emerging roles such as data reliability engineers and data product managers have low search volume, but are still critical to the data team.
Mission Impossible: Data Steward
Your mission, data steward, should you choose to accept it, is to document the lineage, usage, compliance, business logic, quality, access, risk, and value of all data assets in the company along with our policies and processes.
As always, should you fail in this ever expanding task, we will disavow any accountability for these actions. This governance initiative will self-destruct in five months.

In other words, from the moment the data steward job description is written, these professionals find themselves facing long odds to achieving their mission.
While it’s possible, and advisable, to document and catalog key assets and sensitive data, too often either the data steward or their leadership have taken a maximalist approach.
With a maximalist approach to stewardship and governance, too much emphasis is placed on the tactic (documenting all data assets) versus a practical approach focusing on the goals (let’s make it easy to work with and understand our high value data).
The process of data governance also raises tough questions like: what is a data asset? What is the relationship and ownership of different entities across the business? Why is this process needed?
And while some data leaders are proactive in defining needs with data consumers and setting SLAs, others simply outsource to a data steward (or data custodian) and hope for the best.
Modern data solutions that leverage machine learning–such as data catalogs, data discovery, or data observability solutions–can go a long way toward making governance more of a practical endeavor by surfacing key metadata like read/writes, owners, schema changes, and team conversations.
Big accountability, little authority
The data steward’s accountability has remained, but their authority has not.
As the modern data platform has evolved and data has grown in value, the data team has become more specialized.
Data steward responsibilities have become cannibalized by new breeds of data professionals from DataOps specialists and data reliability engineers to data product managers and analytics engineers.
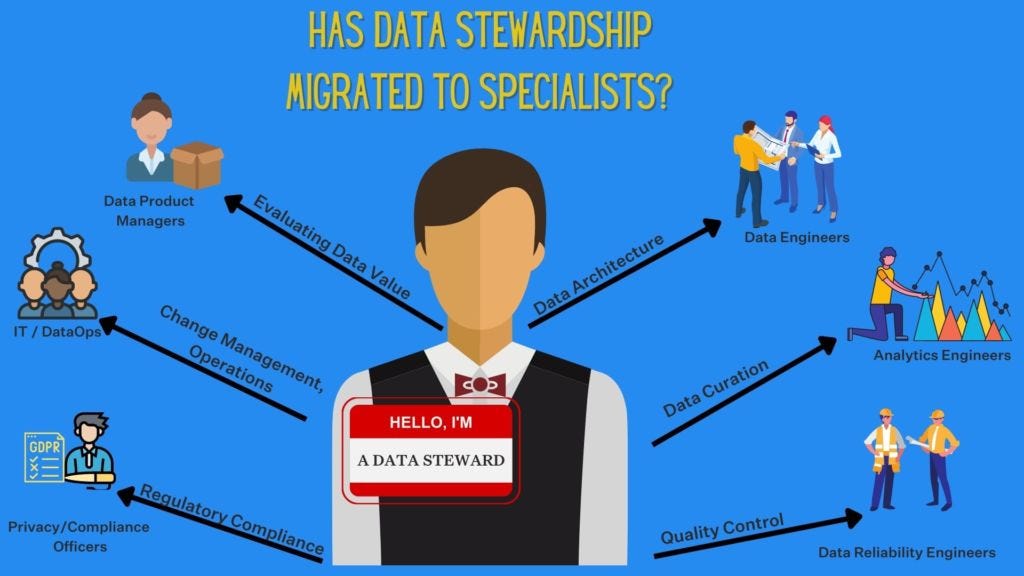
Systems grew more complex and more technical knowledge was needed to maintain; gathering valuable insights became more involved and required more business acumen to surface; and data products became more valuable and required more market knowledge to envision future development.
Another key role of the traditional steward, gatekeeping data, has been virtually removed as data teams strive to democratize data access and implement self-serve mechanisms.
Contextual information for data sets happen fast, furiously, and freewheeling in Slack channels rather than dutifully logged in a catalog.
Technologies like dbt have also played a role in enabling engineers to curate raw data into an analytics layer.
All of these processes require some degree of governance baked in, but many of them are now out of the data steward’s hands. What remained were the responsibilities no one else wanted: documenting, cataloging, and categorizing data and metadata.
Reminding and hounding overworked engineers to document items they have already checked off their to-do list is thankless but important work. Encouraging data teams to follow procedure is, too.
It reminds me of a passage from Maxime’s original blog on the downfall of the data engineer:
“Modern teams move fast, and whether your organization is engineering-driven, PM-driven or design-driven, and whether it wants to think of itself as data-driven, the data engineer won’t be driving much. You have to think of it as an infrastructure role, something that people take for granted and bring their attention to when it’s broken or falling short on its promises.”
An infrastructure role taken for granted except when it’s broken or falling short on its promises? Are we sure he isn’t referring to data stewards?
When data stewards are successful
Making data stewards successful is not about giving generalists responsibilities that have rightly migrated to specialists.
Instead, we should recognize authority across the data team has begun to decentralize (dare I say, data mesh?) and decentralize the role of data steward as well.
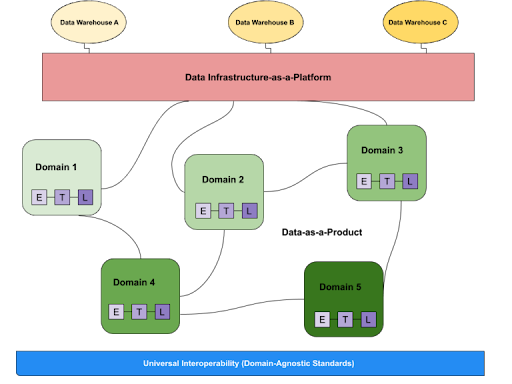
In other words, if your team has data stewards, embed them within each domain.
A modern data governance and stewardship approach must also go beyond describing the data to understanding its purpose.
How a producer of data might describe an asset would be very different from how a consumer of this data understands its function, and even between one consumer of data to another there might be a vast difference in terms of understanding the meaning ascribed to the data.
A domain-first stewardship approach can better prioritize documentation, set requirements and give shared meaning to data within the operational workflow of the business.
Clearcover Senior Data Engineering Manager Braun Reyes described how his organization has been successful deploying with a similar strategy.
We originally tried to make data governance more of a centralized function, but unfortunately this approach was not set up for success.
We were unable to deliver value because each team within the wider data and analytics organization was responsible for different components and data assets with varying levels of complexity. A one-size-fits-all, centralized governance approach did not work and was not going to scale.
We have had much more momentum with a federated approach as detailed in the data mesh principles. Each data domain has a data steward that contributes to the data governance journey.
Now, the proper incentives are in place. It all boils down to ownership. Governance had to be everyone’s problem and it had to be easy to participate.
Governance works best when each service that generates data is a domain with people who own the data and contract.
It’s their data, their enterprise relationship diagram (ERD), and their responsibility to document how to use it. We are still in the early stages, but starting to see real results and value.
Braun’s other piece of advice?
Set concrete goals with metrics that can be tracked. We’re also implementing “stewardship analytics” that can surface, for example, if 50% of the curated data is missing documentation.
Then we can have a conversation with that domain’s steward and figure out how we can remove blockers.
The future of the data steward
The evolution of the data steward reminds me of the evolution of DevOps in software engineering.
Rather than have security and quality assurance as separate stages in a waterfall process, they are integrated and tightly woven throughout the application lifecycle from start to finish.
Data stewards may encounter a similar future where they are embedded within DataOps teams and their responsibilities are broadly assimilated. After all, isn’t governance everyone’s responsibility?
Feeling this pain? I’m all ears.
Data Stewards Have The Worst Seat At The Table was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/CRyiSxO
via RiYo Analytics






No comments