https://ift.tt/GeTMdZA Causal AI — Enabling Data-Driven Decisions Understand how Causal AI frameworks and algorithms support decision maki...
Causal AI — Enabling Data-Driven Decisions
Understand how Causal AI frameworks and algorithms support decision making tasks like estimating the impact of interventions, counterfactual reasoning and repurposing previously gained knowledge on other domains.

1. Introduction
AI and Machine Learning solutions have made rapid strides in the last decade and they are being increasingly relied upon to generate predictions based on historical data. However they fall short of expectations when it comes to augmenting human decisions on tasks where there is a need to understand the actual causes behind an outcome, quantifying the impact of different interventions on final outcomes and making policy decisions, perform what if analysis and reasoning for scenarios which have not occurred etc.
Let’s consider a practical scenario to understand the decision making challenges faced by business and how current AI solutions help address those:
- Say a firm has invested in building an employee attrition model that predicts the propensity of employees to leave. Among other factors, regular business training, increasing communication, employee recognition is identified by model to influence the final outcome.
While generation of model predictions and explaining key features influencing the outcomes is helpful, it does not allow taking decisions.
To facilitate decision regarding the right interventions needed to reduce attrition, we need answers to below questions :
- What is the impact on final outcomes if the firm decides to make an intervention and organize regular quarterly training for its staff?
- How can we compare the impact of different competing interventions, say organizing quarterly trainings with that of arranging regular senior leadership connect?
What will also be of immense help in this situation is to understand the consequences of different actions in hindsight.
- “What would have been the propensity to leave, if quarterly training was being imparted for the last 1 year?
The above is an example of a counterfactual problems and is more difficult than estimating interventions as the data to answer is not observed and recorded.
The next level of more complex decisions require understanding how the systems will respond to external stimulus and why the change occurs.
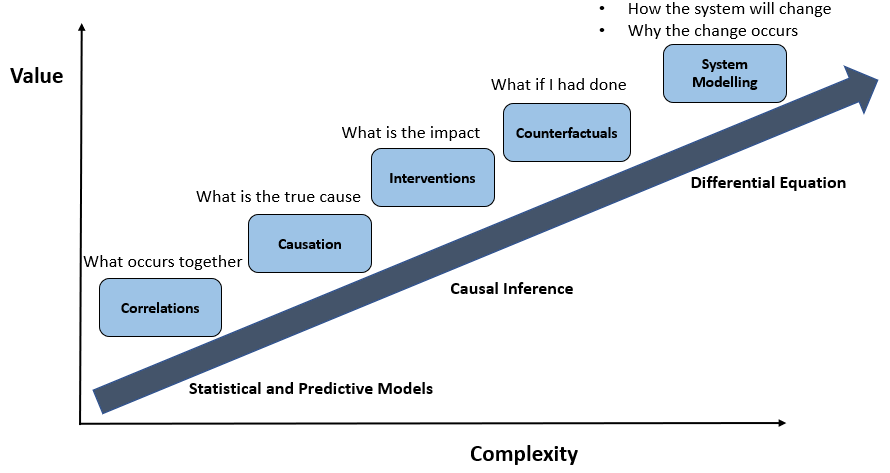
How does the business get answer to the above questions, which enable true decision making ?
It is important to realize that decision making can have deep downstream consequences, hence there is a need to not only understand why a system makes a decision, but also understand the effects of that decision, and how to improve decision-making to achieve more desirable outcomes.
2. Decision Making through existing methods
Let’s explore if we are able to get answers to above questions from Supervised Machine Learning and other traditional approaches
2.1 Does Supervised Machine Learning help?
Our first instinct may be to take a Machine learning approach and predict the outcomes from a set of features that includes past trainings taken, sessions attended etc. . However, there is a catch here!
We need to take into consideration that the interventions change the statistical distribution of the variables of interest in observed data and invalidate the fundamental assumptions on which the models were built. The resulting predictions are hence unreliable.
Answering the counterfactual questions can be even more difficult than answering interventional questions using traditional ML. The fundamental problem here is that the model learns from training data and in this case the data to answer counterfactual questions is not observed and measured.
2.2 What about Randomized Control Trials?
The other approach one can think of is to conduct Randomized Control Trials (also referred as A/B testing). These have been the gold standards for measuring the impact of interventions for a long time.
However, there are practical challenges observed while using them:
- Ensuring random assignment between Control and Treatment group is not always feasible and systematic differences between groups bias the results.
- Randomized controlled trials are expensive and time-consuming
- Ethical issues arise in conducting random trials in many situations — is it ethical to expose people to potentially harmful treatments?
2.3 How Causal AI help address the challenges
The above questions are all causal questions and, unlike many conventional machine learning tasks, cannot be answered using only passively observed data and traditional machine learning algorithms. New approaches to machine learning based on principles of causal reasoning provide us with a promising path forward.
Causal inference bridges the gap between prediction and decision-making and allows researchers and program designers to simulate an intervention and infer causality by relying on already available data.
Below chart highlights the key difference between Machine Learning and Causal Inference.

Why Causal AI
Causal AI has obvious benefits when compared to statistical and traditional supervised learning approaches.
Some of the key benefits are outlined below:
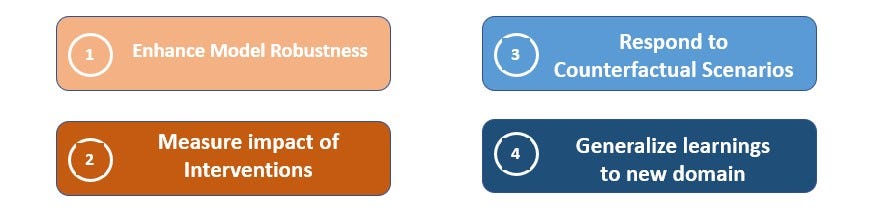
- Causal models remain robust when underlying data changes and thus can help in generalizing the solution to unseen data
- Causal AI helps measure the impact of an intervention and are very tool for decision making
- Causal models also allow us to respond to situations we haven’t seen before and enable the solution to plan for unforeseen counterfactual situation
- Causal models also allow humans to generalize previously gained knowledge to unseen and different challenges
3. Causal AI — Quick Overview
3.1 Basic Concepts
Causal inference enables estimating the causal effect of an intervention on some outcome from real-world observational data, holding all other variables constant.
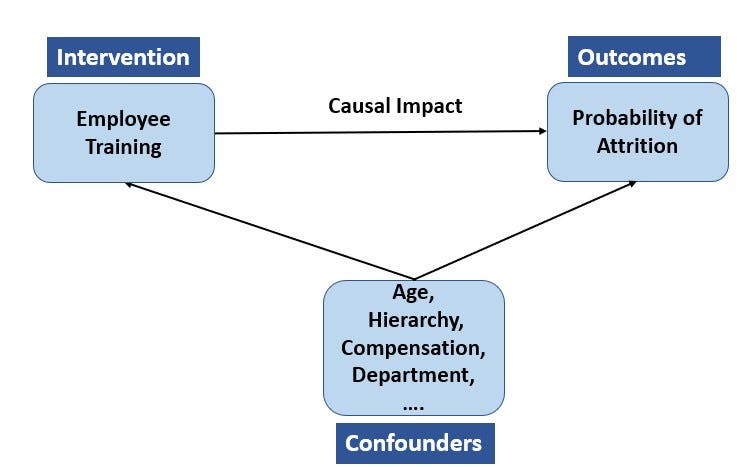
To relate back to our original scenario, the firm decides to measure the impact of an intervention say investing in quarterly training for employees. The employee base was divided into two treatment groups; Group 1 are those who received training and Group 2 comprise employees who did not receive any training.
Now in this scenario, Causal effect estimate requires computing the difference of outcome when employees attend the training with the situation when they do not, keeping other variables constant. We need to be aware that only one of the outcomes is possible i.e., either an employee attends training or not. The unobserved outcome is a counterfactual one. Causal inference methods employ various assumptions to let us estimate the unobservable counterfactual outcome.
Some of the factors that make the Causal Inference problem challenging are discussed below:
- Confounders: A Confounder is a variable that influences both the treatment and outcome. Fundamentally, if something other than the treatment differs between the treated and control groups, we cannot conclusively say that any difference observed in the outcome is due solely to the treatment.
- Selection Bias: takes place when the distribution of the observed group is not representative of the group, we are interested in computing causal effect . If we directly train the causal model on the data without handling selection bias, the trained model works poorly in estimating the outcomes for the units in the other group.
- Measuring Treatment Effect: The treatment effect can be measured at the population (Average Treatment Effect), treated group, subgroup (Conditional average treatment effect (CATE)), and individual levels (Individual treatment effect (ITE).
3.2 Approaches to Causal Inference
There are two fundamental approaches to Causal inference:
I. Potential Outcomes Framework : compares the outcome of an individual who has received training with the scenario if they were not exposed to the training. So, for each employee who was exposed to the training, the Causal AI algorithms will find an individual in the data set who was not exposed to the training but who is identical in other significant respects such as age, experience, hierarchy, department, education etc. The limitation of this approach is that the approach can test the impact of only one intervention at a time
II. Causal Graph Model : This approach helps us to map the different causal paths to an outcome of interest and show how different variables relate to each other. One widely used method is the Structural Equation Model, in which we specify the variables that may interact, how they might do so, and the model then analyzes the data to reveal whether they actually do. The limitation of this model is that it tests only the linkages between the specified variables. Another causal graph method is the Causal Bayesian network, which estimates the relationships between all variables in a data set.
Both approaches make it possible to test the effects of a potential intervention using real-world data. What makes them AI are the powerful underlying algorithms used to reveal the causal patterns in large data sets.
3.3 Causal Inference Algorithms
Causal Inference consists of a family of methods and at its core there are two types of estimation methods:
- Estimation methods under un-confoundedness: The assumption made here is that we are measuring all confounding variables in observed data. If that is not the case then the results will have some bias in them. Matching Methods and Re-weighting methods are two of the commonly used methods for estimation . The key theme implemented is to create a “pseudo-population” to address the challenge due to different distributions of the treated and control groups. This is being accomplished through finding the closest match using distance metrics(Matching methods), weighting the samples (Inverse Propensity Weighting). Apart from above the other methods for estimation include Meta Learners, Forest based Estimators (Non-Linear models) etc.
- Estimation methods for quasi-experiments: In quasi experiments, pre-existing groups have received different treatments and there is a lack of randomness in creation of the groups. Commonly used approaches include simple natural experiments, Instrumental Variables (IV), and Regression-discontinuity models.
4. Practical Implementations
4.1 Open Source Python Libraries for Causal Inference
Causal AI is gaining a lot of traction and below are two Python libraries that I found very helpful in carrying out causal analysis:

- DoWhy — is a Python library from Microsoft that aims to spark causal thinking and analysis. It provides a principled four-step interface for causal inference that focuses on explicitly modeling causal assumptions and validating them as much as possible. More details about the library is available at https://github.com/microsoft/dowhy
- Causallib — library from IBM provides a suite of causal methods, under a unified scikit-learn-inspired API. It implements meta-algorithms that allow plugging in arbitrarily complex machine learning models. This modular approach supports highly-flexible causal modelling. More details about the library is available at https://github.com/IBM/causallib/
4.2 Solve the Job Training intervention challenge
A related challenge of measuring the causal impact of Job Training on increase of earnings is discussed in the research paper Evaluating the Econometric Evaluations of Training Programs with Experimental Data paper.
- Solution to above problem using DoWhy library : https://microsoft.github.io/dowhy/example_notebooks/dowhy_lalonde_example.html
- Solution using IBM Causallib library: https://nbviewer.org/github/IBM/causallib/blob/master/examples/lalonde.ipynb
5. Road Ahead
- Integration of Causal learning with Machine Learning: Lack of causal understanding makes it very hard for traditional Machine Learning solutions to generalize on unseen data or when there are interventions made to the environment. Causal learning is effective when it comes to learning from less data, being more robust to any change in environment and responding to counterfactual scenarios for which there is no observed data. A lot of research work is currently underway that combine machine learning mechanisms and structural causal models.
- Promoting Ethical and Socially Responsible AI: Causal learning is one of the key approach, researchers are using to develop Socially Responsible AI. It is playing a key role in specifying the nature and timing of interventions on social categories, understand explicit causal assumptions, causal discovery, mediation analysis and implications of fairness evaluation techniques.
- Development of Next Gen AI Solutions: Causal models are being used to repurpose previously gained knowledge for generating insight on new domains. Some of the cutting-edge work involves learning real time strategy and applying the learned knowledge to generalize on different domains. Causal Models can play a crucial role in strengthening the defense against adversarial attacks . Causal learning techniques are also being used to help make the training of reinforcement learning more efficient by allowing them to make informed decisions from the start of their training instead of taking random and irrational actions.
6. References
- Towards Causal Representation Learning, https://arxiv.org/pdf/2102.11107.pdf
- Causality for Machine Learning, https://arxiv.org/abs/1911.10500
- Causal Inference, https://medium.com/data-science-at-microsoft/causal-inference-part-2-of-3-understanding-the-fundamentals-816f4723e54a
- DoWhy, https://microsoft.github.io/dowhy/
- Causallib, https://github.com/IBM/causallib/
Disclaimer: The opinions shared in this article are my own and do not necessarily reflect those of Fidelity International or any affiliated parties.
Causal AI — Enabling Data Driven Decisions was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/6Aisc74
via RiYo Analytics






ليست هناك تعليقات