https://ift.tt/htuyoQ7 Opinion The modern data warehouse architecture creates problems across many layers. Image courtesy of Chad Sanders...
Opinion
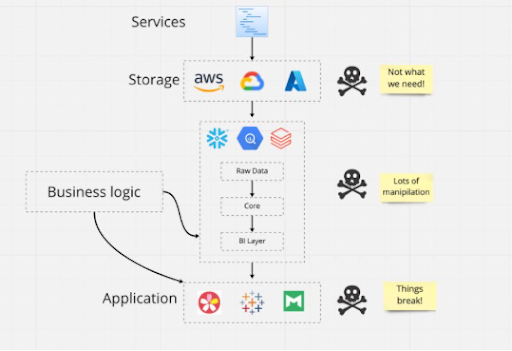
The data warehouse is the foundation of the modern data stack, so it caught our attention when we saw Convoy head of data Chad Sanderson declare, “the data warehouse is broken” on LinkedIn.
Of course, Chad isn’t referring to the technology, but how it’s being used.
As he sees it, data quality and usability issues arise from the conventional best practice of “dumping” data in the warehouse to be manipulated and transformed afterward to fit the needs of the business. This is not out of line with the general efforts of providers like Snowflake and Databricks to ensure their customers are being efficient (in other words, saving money and resources) in their storage and consumption.
Whether or not you agree with Chad’s approach detailed below, what can’t be disputed is how his opinions have generated a tremendous amount of debate.
“One camp is mad at me because they think this is nothing new and it requires long manual processes and data architects with 30 years of experience. The other camp is mad at me because their modern data stack is fundamentally not set up this way and it isn’t how they have been building out their data products,” said Chad.
I’ll let you decide for yourself if the “immutable data warehouse” (or active vs passive ETL) is the right path for your data team.
Either way, I’m a strong proponent that moving our industry forward will require more than overviews of technologies such as data warehouses and data observability platforms, but frank discussions and unique perspectives on how to deploy them.
We’ll let Chad take it from here.
How an Immutable Data Warehouse Combines Scale and Usability
A perspective from Chad Sanderson
The modern data stack has many permutations, but the data warehouse is a foundational component. To oversimplify:
- Data is extracted via passive pipelines (really just the “E” in ETL) and dumped into…
- A data warehouse where it is processed and stored before it is then…
- Transformed into the format needed by data consumers for…
- A specific use such as analytic dashboards, machine learning models, or activation in systems of records such as Salesforce or Google Analytics…
- With technologies or processes such as data observability, governance, discovery, and cataloging running across the stack.
Before diving into the challenges of this approach, and a suggested alternative, it’s worth exploring how we arrived at what we define as “the modern data stack.
How did we get here?
In the early days of data, with pioneers such as Bill Inmon, the original ETL (extract, transform, load) process involved extracting from the source and transforming it before landing in the data warehouse.
Many businesses still operate this way today. For large companies where data quality is paramount, this process involves a manual, intensive governance framework with a tight coupling between data engineers and the data architects embedded across different domains in order to leverage data quickly for operational insights.
Tech giants like Google, Facebook, and others ditched this process and started dumping virtually everything in the data warehouse. The ROI of logically organizing the data just wasn’t as high for rapidly growing startups as this much faster, more scalable process. Not to mention, loading (the “L” in ELT) had become much easier to integrate in the cloud.
Along the way, popular transformation tools made transforming data in the warehouse easier than ever. Modular code and dramatically reduced runtimes made the ETL model radically less painful…so much so the use of popular transformation tools expanded downstream from data engineers to data consumers such as data scientists and analysts.
It seemed like we had found a new best practice and we were on our way to a de facto standardization. So much so, that suggesting an alternative would generate swift and strong reactions.
The challenge with passive ETL or transformations in the warehouse
There are several problems with an architecture and process that heavily relies on transforming data once it has entered the data warehouse.
The first problem is the disconnect, really chasm, it creates between the data consumer (analysts/data scientists) and the data engineer.
A project manager and a data engineer will build pipelines upstream from the analyst, who will be tasked with answering certain business questions from internal stakeholders. Inevitably, the analyst will discover that data will not answer all of their questions and that the program manager and data engineer have moved on.
The second challenge arises when the analyst’s response is to go directly into the warehouse and write a brittle 600 line SQL query to get their answer. Or, a data scientist might find the only way they can build their model is to extract data from production tables which operate as the implementation details of services.
The data in production tables are not intended for analytics or machine learning. In fact, service engineers often explicitly state NOT to take critical dependencies on this data considering it could change at any time. However, our data scientist needs to do their job so they do it anyway and when the table is modified everything breaks downstream.
The third challenge is when your data warehouse is a dumping ground, it becomes a data junkyard.
An older Forrester study from the Hadoop era found between 60% and 73% of all data within an enterprise goes unused for analytics. A more recent Seagate study found 68% of data available to the enterprise goes unused.
As a result, data scientists and analysts spend too much of their time searching for context in an overly processed production code haystack. As data engineers, we need to emphasize data usability in addition to data quality.
If your users can’t find and leverage what they need reliably in your current data warehouse, what’s the point?
Another approach: introducing the immutable data warehouse
The immutable data warehouse concept (also referred to as active ETL) holds that the warehouse should be a representation of the real world through the data instead of a tangled mess of random queries, broken pipelines, and duplicated information.
There are five core pillars:
#1 The business is mapped and owners are assigned. For businesses to truly gain value from the massive amounts of data they possess, teams need to take a step back and model their business semantically before defining entities and events through code for the express purpose of analytics. This can be an iterative process starting with the most crucial elements of the business.
An entity relationship diagram (ERD) is a map of the business based on the REAL world, not what exists in the data warehouse or production databases today. It defines the critical entities, their relationships (cardinality, etc), and the real world actions that indicate they have interacted. An engineering owner is established for each entity and event. End-to-end automated lineage can help establish the ERD and make it actionable.
#2 Data consumers define their needs upfront and contracts are created. Perhaps the most controversial tenant is that data should bubble up from business needs instead of trickle down from unstructured pipelines. Instead of data analysts and scientists combing through the dusty shelves of your warehouse to see if there is a data set close enough to what they need, no data enters the warehouse unless it is directly requested and defined by the data consumer first.
No data enters the warehouse without a business question, process, or problem driving it. Everything is purpose built for the task to be done.
It’s essential this process is designed to be simple as data needs are always changing and increased friction will threaten adoption. At Convoy, implementing a new contract takes minutes to hours not days to weeks.
Next, it’s time to draw up the data contract, which is an agreement between the business and engineering leads about what the schema of an event/entity should be and the data that is needed most for that asset to be most effective. For example, perhaps an existing inboundCall event is missing an OrderID which makes it difficult to tie phone calls to completed orders.
SLAs, SLIs, and SLOs are one type of data contract you can apply to this model of change management and stakeholder alignment.
#3 Peer reviewed documentation within an active environment. In the same way we need a peer review process for code (GitHub) or UX (Figma) that hits production, there should be an equivalent for data assets. However, the right level of abstraction for this review is not code — but semantics.
That review process should have the same outcome as a GitHub pull request — version control, sign-off of relevant parties, etc — all handled through the cloud. By applying modern, cloud based technologies we can speed up old processes making them far more viable forevent the fastest growing internet businesses.
There is a place for data catalogs as a pre-data warehouse definition surface, but the challenge is there is no carrot and no stick for data consumers to keep metadata current. What is the incentive for a data scientist that uses an ELT process and finishes their model to go back and document their work?
#4 Data is piped into the warehouse pre-modeled as defined in the contract. Transformations take place upstream from the consumption layer (ideally in the service). Engineers then implement the data contracts within their service. The data is piped into the data warehouse, and with the modeling metadata can ideally be automatically JOINed and categorized.
#5 An emphasis is placed on preventing data loss as well as ensuring data observability, integrity, usability, and lifecycle management. A transactional outbox pattern is used to ensure the events in the production system match what’s in the data warehouse while a log and offset processing pattern (which we use extensively at Convoy) protects against data loss. Together, these two systems ensure data is preserved with complete integrity so the immutable data warehouse is a direct representation and source of truth for what is occurring across the business.
Data quality and usability require two different mindsets. Data quality is a technical challenge for the most part. Think “back-end” engineering. Data usability on the other hand, is a “front-end” engineering challenge that requires the same skill set used to create great customer experiences. Lastly, an immutable data warehouse does not lend itself to petabyte measuring contests and whipping out your big data stats. Deprecation and maintenance is just as important as provisioning.
This approach leverages the advantages of technology to achieve the best of both worlds. The governance and business driven approach of traditional approaches with the speed and scalability associated with the modern data stack.
How an immutable data warehouse works. Treating data like an API.
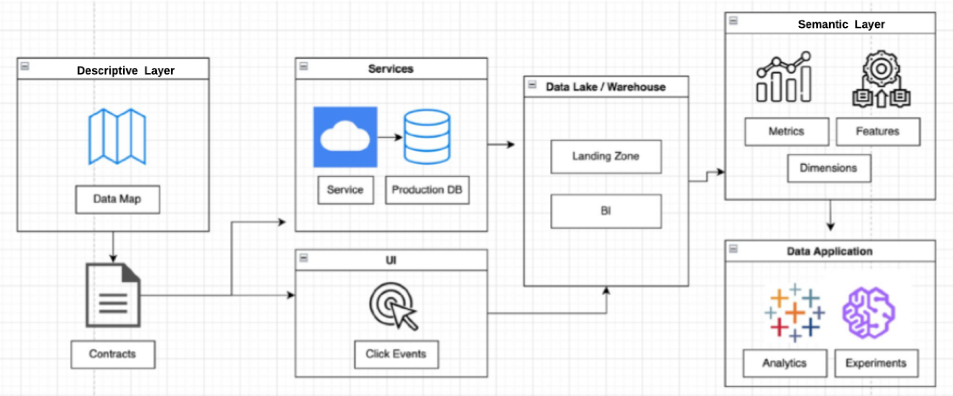
Let’s start by reviewing the full stack surrounding the immutable data warehouse.
1. Descriptive Layer: Unlike traditional warehouses, a descriptive layer moves the business logic above the services layer and puts the data consumer in the driver’s seat. The consumer is able to provide their requirements without the need for technical skills as the data engineer serves as a crucial requirement to code translator. These contracts can be held in a data catalog or even a general document repository.
2. Data Warehouse: The warehouses function primarily as a ‘data showcase’ and the underlying compute layer.
3. Semantic Layer: Data consumers build data products that are validated and shared with the business. Assets in the semantic layer should be defined, versioned, reviewed, and then made available through an API for consumption in the application layer.
4. Application Layer: This is where data is used to accomplish some business function, such as experimentation, machine learning, or analytics.
5. End-To-End Support: Solutions that support data operations across the data stack such as data observability, catalogs, testing, governance, and more. The ideal is to have perfect, pre-modeled, highly reliable data once it hits the warehouse, but you still need to cover all the permutations the real world may throw at you (and have enforcement mechanisms when processes move out of bounds).
The immutable data warehouse itself is designed for streaming — it’s easier to go from streaming to batch data than vice versa–and therefore fed by three different types of APIs.
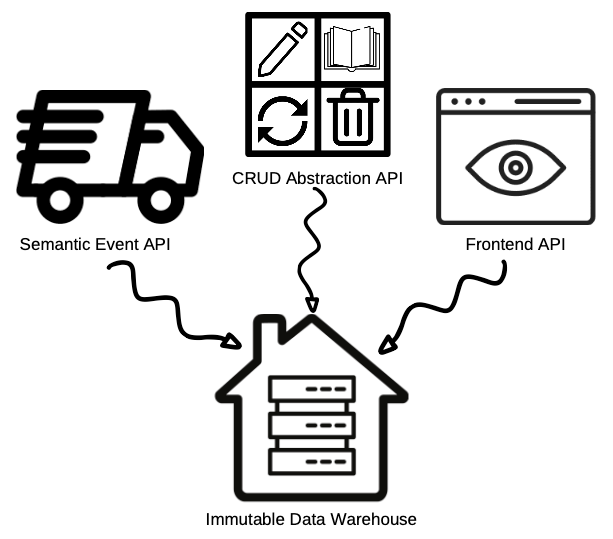
- Semantic Events API: This API is for semantic real world service level events that are the core building blocks of the company, not events from front end applications. For example, in Convoy’s case this could be when a shipment is created or goes off hold. Events from the real world are built in the service code, not SQL queries.
- CRUD Abstraction API: Data consumers do not need to see all production tables, particularly when they’re simply implementation details of the data service they’re using to generate insights or power decision making. Instead, when properties of a data asset in a production table are updated, , an API wrapper or abstraction layer (for instance, dbt) will expose the CRUD concepts that are meaningful to data consumers in the warehouse — for instance, whether or not the data is fresh or row volume is within expected thresholds.
- Frontend API: There are many tools that already handle front-end event definition and emission like Snowplow, Mixpanel, and Amplitude. That being said, some front-end events are important enough that teams need to be able to ensure their delivery and integrity using the long offset pipeline. In some cases, front-end events are critical for machine learning workflows and “close enough” systems just won’t cut it.
There also needs to be a mapping layer that sits outside of the warehouse as things change (perhaps one service needs to become many) or if a schema a data scientist has in mind does not fit with what is happening in the real world.
Mapping should be handled either upstream of the warehouse through a streaming database or in the warehouse itself. This layer is where a BI engineer matches what is coming up from engineering to what a data consumer needs, which can be automated to produce Kimball data marts.
Immutable data warehouses have challenges too. Here are some possible solutions.
I am under no delusion that an immutable data warehouse is a silver bullet. Like any approach it has its pros and cons, and is certainly not for every organization.
Like the data mesh and other lofty data architectural initiatives, the immutable data warehouse is an ideal state and rarely the reality. Achieving one — or attempting to achieve one — is a journey and not a destination.
Challenges that should be considered and mitigated are:
- The upfront costs of defining the descriptive layer
- Handling entities without clear ownership in place
- Implementing new methods to enable rapid experimentation
While there is a cost to defining the descriptive layer, it can be greatly accelerated through software and done iteratively by prioritizing the most important business components.
This needs to be a collaborative design effort that includes data engineers to prevent the diffusion of data quality responsibility across distributed data consumers. It’s OK if you don’t get it right the first time, this is an iterative process.
Handling entities without clear ownership can be a tricky governance problem (and one that is frequently bedeviling data mesh proponents). It’s not typically in the data team’s purview to sort these issues on the business side.
If there is a core business concept that crosses multiple teams and is generated by a monolith rather than microservice, the best way forward is to have a strong review system in place and a dedicated team standing by to make changes.
Data engineers can still be allowed to experiment and given flexibility without limiting workflow. One way to do this would be through a separate staging layer. However, API data from these staging areas should not be allowed to be consumed downstream or across external teams.
The key is that when you move from experiment to production or make it accessible to the border team, it must go through the same review process. Just like in software engineering, you can’t make a code change without a review process just because you want to move faster.
Wishing you luck on your data quality journey
There are many permutations of the modern data stack, and as an industry, we’re still going through an experimentation phase to understand how to best lay our data infrastructure.
What’s clear is that we are rapidly moving toward a future where more mission critical, external facing, and sophisticated products are” powered by” the data warehouse.
Regardless of the chosen approach, this will require us as data professionals to raise our standards and redouble our efforts toward reliable, scalable, usable data. Data quality must be at the heart of all data warehouses, no matter the type.
The bottom line from my perspective: when you build on a large, amorphous foundation, stuff breaks and it’s hard to find. And when you do find it, it can be hard to figure out exactly what that “thing” is.
Immutable or not, maybe it’s time we try something new.
This article was co-written with Chad Sanderson.
Interested in improving the data quality in your data warehouse? Set up a time to talk to the Monte Carlo team.
Is The Modern Data Warehouse Broken? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/FDnV6Aw
via RiYo Analytics








ليست هناك تعليقات