https://ift.tt/r9CXQdy Hyperparameter tuning tutorial using Neural Network Intelligence. At the end of this article, you will be able to d...
Hyperparameter tuning tutorial using Neural Network Intelligence.
At the end of this article, you will be able to do hyperparameter tuning using Microsoft's NNI library which is, in my opinion, one of the best hyperparameter optimization libraries for deep learning that have a web interface to visualize your experiments.
Introduction
Building a deep learning model requires building architectures, which consist of different hyperparameters such as learning rate, batch size, number of layers, number of units in the layer, etc. Therefore, it is important to choose the right hyperparameters in order to get high accuracy score. Fortunately, there exist some strategies to find the best combination of hyperparameters that maximizes a model performance.
Hyperparameter Optimization techniques
There are several techniques that are used to find the best hyperparameter combination. I will list some of them below.
- Manual Search — we manually change values of hyperparameters and try to find the best combination.
Suggestion: It is applied when a model is too big and requires too much time to train. However, The process is tedious and time-consuming. Most often does not guarantee to find the best combinations.
- Grid Search — Ties all combinations of hyperparameters from search space.
Suggestion: It can be applied when the search space is small or the model is not too big. It will in the end find the best combination of hyperparameters. However, It is too time-consuming. For example, if we have a search space that consists of 3 hyperparameters and each hyperparameter has 5 search values, we will end up with 5³=125 combinations.
- Randomized Search — Tries to select hyperparameters randomly from search space.
Suggestions: It might be surprisingly effective. It can be applied when the model does not need much to train and you have good computational resources. However, It is also time-consuming when the search space is big.
- Tree-structured Parzen Estimator(TPE)- is a black box optimization technique that sequentially constructs models to approximate the performance of hyperparameters based on historical measurements.
Suggestions: If you have limited computational recourses or the model is too big it is one of the best methods to choose. It shows awesome results in general and is better than a Random Search.
I will use TPE In our training to do hyperparameter optimization.
Classification Problem
My goal for this article is not to build a complex architecture, therefore, for simplicity, I will do a simple classification problem on the popular FashionMNIST dataset which has ten classes and I will focus more on hyperparameter tuning. Thus, I will use the code from Pytorch's official tutorial, slightly modify it and apply NNI.
Set up
- open command line/Terminal
Make sure python is installed. Otherwise, install it.
python -V #Windows
python3 --version #Unix/MacoS
python -m venv hyper_env #Windows
python3 -m venv hyper_env #Unix/MacoS
- Activate a virtual environment
hyper_env\scripts\activate #Windows
source hyper_env/bin/activate #Unix/MacOS
- Install Pytorch and torchvision
pip3 install torch torchvision torchaudio #Windows/Mac
pip3 install torch torchvision torchaudio — extra-index-url https://download.pytorch.org/whl/cpu #Linux
- Install NNI
pip install nni
After everything is ready, let's open Visual Studio Code and create four files.
after that select python interpreter of hyper_env environment (Ctrl+Shift+P)
note: if you can not see the python interpreter, press Enter interpreter path.. to add it manually and navigate through (C:\Users\gkere\hyper_env\Scripts\python.exe)
Files
mnist_without_nni.py -> it trains a baseline model with initial hyperparameters
search.py and mnist_nni.py -> it searches hyperparameters and sees web interface visualizations.
mnist_bestparams.py -> final file with best searched hyperparameters.
1. Model Performance with Initial Hyperparameters (Baseline)
- mnist_without_nni.py
Result After 10 Epochs: Accuracy: 77.3%, Avg loss: 0.649939 (Initial model accuracy)
2. Hyperparameter search with NNI
STEP 1
- search.py
In this file, we set up the search space and config of the experiment.
notes on types:
- choice: The variable’s value is one of the options.
- loguniform: The variable value is drawn from a range [low, high] according to a log uniform distribution
- uniform: The variable value is uniformly sampled from a range [low, high]
notes on config:
- trial_command: use python3 on Mac and python on Windows
- max_trial_number: number of experiments to run. In general, TPE requires min 20 trials to warm up.
- trial_gpu_number: CUDA is required when it’s greater than zero.
Step 2
create mnist_nni.py — file is the same as mnist_without_nni.py but with 4 lines of modification:
add:
nni.report_intermediate_result(test_acc)
nni.report_final_result(test_acc)
params = nni.get_next_parameter()
remove:
params = {‘batch_size’: 32,’hidden_size1': 128,’hidden_size2': 128, ‘lr’: 0.001,’momentum’: 0.5}
After you create these files, just run the search.py file only and open localhost http://localhost:8080/
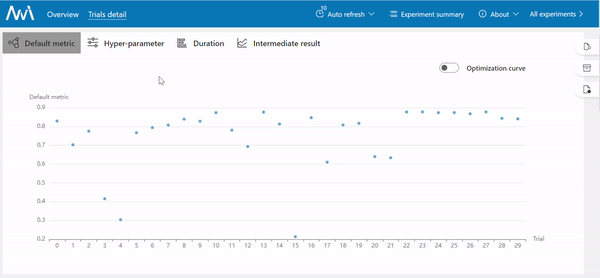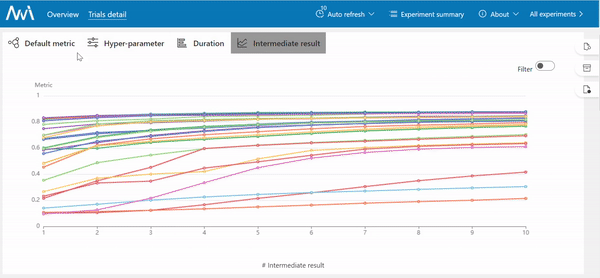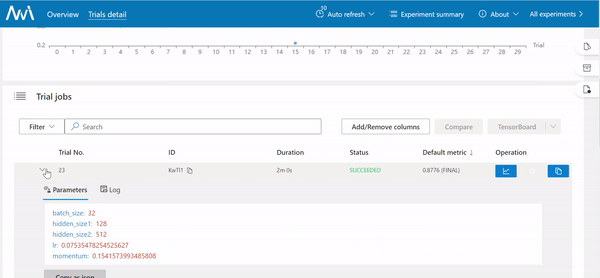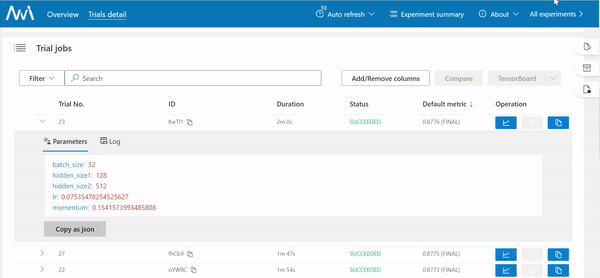
Once all trials finish, you will get a list of experiment results.
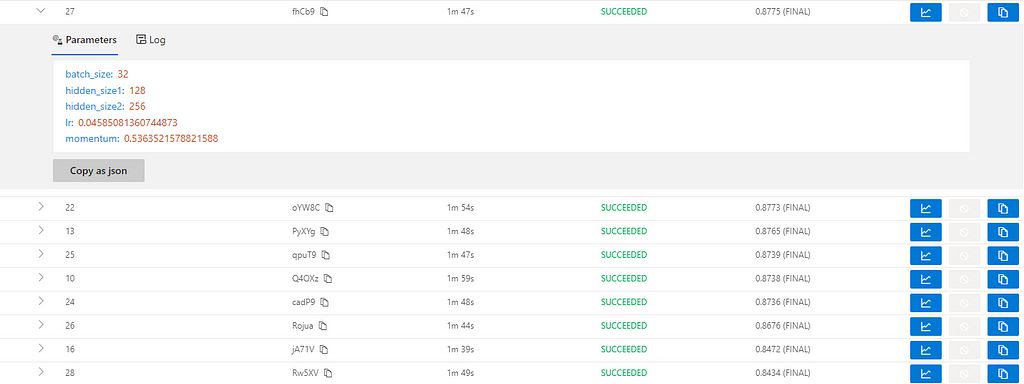
In this picture, it is shown a sorted list of trials that represent separate training with different hyperparameter optimization.
Result: Best Searched Hyperparameters Found
params = {"batch_size": 32, "hidden_size1": 128, "hidden_size2": 256, "lr": 0.04585081360744873, "momentum": 0.5363521578821588}
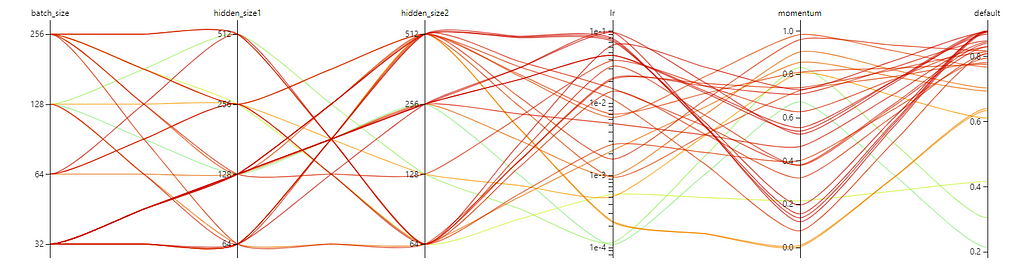
Debugging:
- If the trial fails, check the View trial error(Trial details->select failed trial->Log->Vie trial error) to see the detailed error.
- If the trial is succeeded, but the default metric does not show data, check the data type of accuracy score of the test set and make sure it returns a float dtype.
3. Model Performance with Best hyperparameters
run mnist_bestparams.py -> which is the same as mnist_without_nni.py but I just swapped initial parameters with the best-searched params.
whoa!!!!!!!!, The result is fascinating.
Result After 10 Epochs: Accuracy: 87.5%, Avg loss: 0.350102
10% improvement from initial model — from 77.3% to 87.5%.
Conclusion
Building a deep learning/machine learning model is challenging. One of the main tasks is to build a good architecture, but hyperparameters are also important aspects to take into consideration. As the result shows, hyperparameter optimization outperformed the initial model by 10%. Also, as discussed above there are different optimization techniques that have their advantages and disadvantages. In this article, I used TPE which is one of the best methods for a big model with a limited number of resources. I like the NNI library not only because it has built-in algorithms that can do hyperparameter tuning, but also because it has a nice web interface to visualize your experiment result.
Thank you for reading. I hope this article was helpful for you.
If you want to see my upcoming posts regarding black box model interpretation and many more, You can follow me on medium to keep updated.
Gurami Keretchashvili - Medium
My previous articles:
- Fish Weight Prediction (Regression Analysis for beginners) — Part 1
- Regression Analysis for Beginners — Part 2
How to Improve Any ML/DL Performance by 10% Easily was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/uSz20Jm
via RiYo Analytics








ليست هناك تعليقات