https://ift.tt/egk9YMT Photo by Martin Adams on Unsplash Accelerated methods now have a theoretical justification Optimization analys...

Accelerated methods now have a theoretical justification
Optimization analysis is an active area of research and interest in machine learning. Many of us that have taken optimization classes have learned that there are accelerated optimization methods such as ADAM and RMSProp that outperform standard Gradient Descent on many tasks. Although these adaptive methods are popularly used, a theoretical justification of why they performed well on non-convex problems was not available, until recently. Today, I’d like to introduce “Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity”, a paper published in 2020.
TL;DR
Under a novel, relaxed smoothness condition that was motivated from empirical analysis of gradient norms and Lipschitz constants, there is a theoretical explanation for why Gradient Clipping/ Normalized Gradient methods outperform standard methods.
Contributions:
The contributions of the paper can be summarized to:
- A relaxed smoothness condition that allows the local smoothness constant to increase with the gradient norm.
- A convergence rate for clipped Gradient Descent and normalized Gradient Descent under the relaxed smoothness condition.
- An upper and lower bound of the convergence rate of vanilla Gradient Descent under the relaxed smoothness condition, which demonstrates that vanilla gradient descent can be arbitrarily slower than clipped Gradient Descent.
- Similarly, an upper bound for clipped Stochastic Gradient Descent and vanilla Stochastic Gradient Descent, which demonstrates that clipped SGD may be arbitrarily faster than vanilla SGD.
L -smoothness
Before introducing the proposed relaxed smoothness condition, let’s review the definition for L-smooth functions.
Definition: An objective function f is considered L-smooth if:
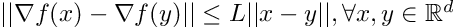
For twice differentiable functions, this condition is equivalent to (setting y = x-h):
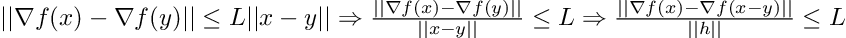
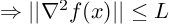
The authors explain that the limitation of this definition of L-smoothness is that assuming existence of a global constant L that upper bounds the variation of the gradient is restrictive. Even a simple polynomial function such as f(x) = x*x*x can break the assumption. One remedy could be to assume that L exists in some local region, and show that the iterates do not escape this region, or run projection based algorithms that guarantee the iterates will not escape the region. However, this remedy can make L very large, and would not contribute to a tight theoretical convergence rate.
The primary motivation behind this paper can be summarized to this question:
Can we find a fine-grained smoothness condition under which we can design theoretically and empirically fast algorithms at the same time?
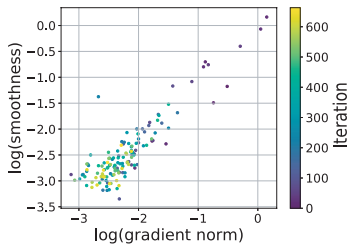
To gain an empirical understanding of the relationship between gradients and Lipschitz constants, the authors show a plot of the gradient norms and Lipschitz constants that shows a strong positive correlation (Fig 1). The hypothesis for the positive correlation is that the gradient and Hessian share components in their computation, such as the matrix product of weights. To capture the positive correlation between the Lipschitz constant and the gradient norm, the authors propose a relaxed (weaker) smoothness condition that allows local smoothness to grow with gradient norms.
Relaxed Smoothness Condition
Definition: A second order differentiable function f is (L0,L1)-smooth if:
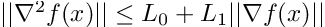
This definition is a relaxed condition in that L0 and L1 can be balanced such that L0 << L and L1 << L. Secondly, we can find functions that are globally (L0,L1)-smooth, but not L-smooth. One lemma in the paper helps understand the second benefit of the relaxed condition better: for univariate polynomial functions with a polynomial degree greater than or equal to 3, the function is (L0,L1)-smooth, but not L-smooth. The relaxed condition simply requires that the second order derivative of f is less than the first order derivative of f, which can be shown as such:
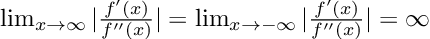
This is true because a first order derivative must be of a higher polynomial than a second order derivative. Then, as x approaches positive/negative infinity, the absolute value of the fraction will be infinity.
We can know that this function is not L-smooth from the definition of L-smoothness (eq 2), which requires that the norm of the second derivative of f be bounded by some constant L, however f’’(x) is unbounded.
Problem Setup and Assumptions
With the motivation and proposed condition under our belt, we move on to look at the setup of the problem and the necessary assumptions before proceeding to theoretical analyses.
We define f to be the nonconvex optimization problem. Because this optimization problem is generally intractable to directly solve, it is common practice to optimize until an epsilon stationary point is reached.
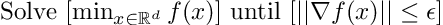
Next, the following assumptions are made to the class of functions to be studied.
- Assumption 1: The function f is lower bounded by f*, which is larger than negative infinity.
- Assumption 2: The function f is twice differentiable.
- Assumption 3: The function f is (L0,L1)-smooth (eq 3).
- Assumption 4: Given an initialization x0, we assume that:
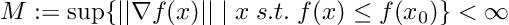
Assumption 4 allows us to assume that the gradient norm for objective function f can be bounded by some constant. This constant M would be larger for “bad” initialization x0, and smaller for “good” initializations.
Lastly, to relax global assumptions, the assumptions above are only required to hold in a local region defined by S for an initialization x0:
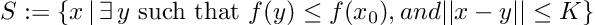
Convergence for Clipped/Normalized Gradient Descent
Clipped Gradient Descent updates its weights at each iteration using the equation:
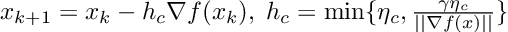
Normalized Gradient Descent has the following update:
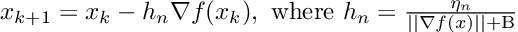
On closer examination, we find that these updates are very similar. By allowing
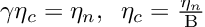
we have that
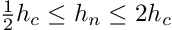
These updates are equivalent up to a constant factor, and thus an analysis on clipped gradient would also apply to normalized gradient descent.
Then, for a class of functions that satisfy Assumptions 1,2 and 3, and is in the set S (eq 6), the iteration complexity of clipped GD is upper bounded by:
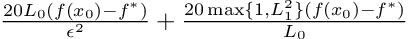
where
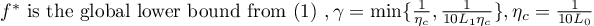
In other words, the upper bound for clipped GD is
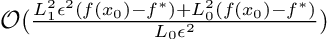
Convergence for Vanilla Gradient Descent
Vanilla gradient descent updates its weights at each iteration using the equation:
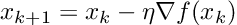
For a class of functions that satisfy Assumption 1,2,3 and 4, and hold in set S (eq 6) and M is defined as in Assumption 4, the iteration complexity of vanilla GD is upper bounded by:
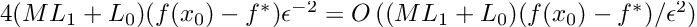
The authors further provide a lower bound for fixed-step vanilla gradient descent, and show that it cannot converge to an epsilon-stationary point faster than:
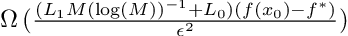
Note that the Big-Omega (best case) and Big-O (worst case) notations for vanilla GD are tight by a factor of log(M). Comparing the upper bound for clipped GD and the upper bound for vanilla GD, we can know that clipped GD can be arbitrarily faster than GD when M is large, or when the problem is initialized poorly.
This is acceptable intuitively as well. When the weights are initialized poorly, the gradients can take arbitrarily small or large values, and regularizing (clipping) the weights would stabilize training and thus lead to faster convergence. This was known intuitively, but only now has it been explained theoretically.
The paper extends the complexity analysis to non-deterministic (stochastic) gradient descent settings by employing a fifth Assumption. It draws a similar conclusion that clipped SGD can be arbitrarily faster than vanilla SGD when M is large.
Conclusion
The paper introduced today finally bridges the gap between theoretically fast algorithms and empirically fast algorithms. The analyses provided lets us be confident in our choice of accelerated optimization methods and reminds us of the importance of proper initialization.
For those that are interested in continuing research in this area, the authors left behind directions for possible improvements. First is extending this analysis to other accelerated methods, such as momentum. The second direction is to further investigate empirically motivated smoothness conditions that provide tighter and cleaner theoretical guarantees.
Bibliography:
[1] J.Zhang, T.He, S.Sra, A.Jadbabaie, Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity (2020), ICLR 2020
Why Gradient Clipping Methods Accelerate Training was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/vJqFx7W
via RiYo Analytics








ليست هناك تعليقات