https://ift.tt/MEt5Dg9 The Hands-on RL Course — Part 6 Photo by Boxed Water Is Better on Unsplash Hyperparameters in Deep RL are crit...
The Hands-on RL Course — Part 6

Hyperparameters in Deep RL are critical to training successful agents. In today’s lesson, we will learn how to find the ones that make you a happy Deep RL developer.
Welcome to the course ❤️
Welcome to part 6 of the Hands-on Course on Reinforcement Learning, which takes you from zero to HERO 🦸♂️.
This is what’ve done so far:
- Introduction to Reinforcement Learning
- Tabular Q-learning
- Tabular SARSA
- Linear Q-learning
- Deep Q-learning
- 👉🏻 Hyperparameters in Deep RL (today)
In part 5 we built a perfect agent to solve the Cart Pole environment, using Deep Q Learning.
We used a set of hyperparameters that I shared with you. However, I did not explain how I got them.
If you want to become a real PRO in Reinforcement Learning, you need to learn how to tune hyperparameters. And for that, you need to use the right tools.

Today we will use the best open-source library for hyperparameter search in the Python ecosystem: Optuna.
All the code for this lesson is in this Github repo. Git clone it to follow along with today’s problem.
Wanna share some love? Please give it a ⭐ in Github!

Part 6
Contents
- The problem
- The solution: Bayesian search
- Hyperparameter search with Optuna
- Recap ✨
- Homework 📚
- What’s next? ❤️
1. The problem
Machine Learning models have parameters and hyperparameters.
What is the difference between these two?
Parameters are the numbers you find AFTER training your model. For example, the parameters of the neural network that maps states to the optimal q-values.
The hyperparameters, on the other hand, are the numbers you need to set BEFORE you train the model. You cannot find them through training, but you need to correctly guess them beforehand. Once you set them, you train the model and find the remaining parameters.
Hyperparameters exist all around Machine Learning. For example, in supervised machine learning problems (like the one we solved in part 5), you need to set the learning rate. Too low of a number and the model will get stuck in local minima. Too large of a number and the model will oscillate too much and never converge to the optimal parameters.
In Deep Reinforcement Learning things get even more challenging.
Why?
Because
- Deep RL algorithms have more hyperparameters than supervised machine learning models.
- And, even more importantly, hyperparameters in Deep RL have a huge impact on the final training outcome. In other words, deep RL algorithms are very sensitive to the hyperparameters you set beforehand. The more complex the environment, the more critical hyperparameters are.
In part 5 we saw how two sets of hyperparameters, combined with the same parameterization of the q-value network, lead to two very different agents, with very different performances. One of the agents was okayish (with an average reward of around 180), while the other was a perfect solution (average reward 500).
The question is then…
How can we find the **good** hyperparameters? 🤔
To find good hyperparameters we follow a trial-and-error approach.
Essentially, these are the 4 steps:
- We choose a set of hyperparameters,
- Train the agent,
- Evaluate the agent.
- If we are happy with the result, we are done. Otherwise, we choose a new set of hyperparameters and repeat the whole process.

Grid search
If the number of hyperparameters is low (e.g. 2–3) we can try all possible combinations and select the one that works best. This method is called grid search, and it works well for many supervised ML problems.
For example, if our algorithm has only 2 hyperparameters, each of them taking 1 out of 5 possible values, we end up with 5 x 5 = 25 combinations. We can train the agent 25 times, using each hyperparameter combination, and find the best ones.
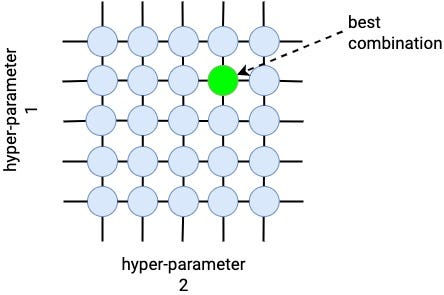
In Deep RL problems, on the other hand, there are many more hyperparameters, e.g 10–20. And each hyperparameter can take many possible values.
This creates a massive grid in which we need to search, where the number of combinations grows exponentially with respect to the number of hyperparameters and the number of values each hyperparameter can take. In this case, Grid Search is no longer a feasible way to search.
For example, if we have 10 hyperparameters, and each can take 1 out of 10 possible values, the grid size is 10,000,000,000 (a 1 followed by 10 zeros). If our training loop takes 10 minutes to complete (which is a very optimistic estimate), it would take us
10 minutes x 10,000,000,000 = 190,258 years 😵💫
Which in plain words means… impossible.
You could parallelize the search and decrease this number by a few orders of magnitude. For example, if you had a large cluster of computers that could spin up to 100,000 parallel processes, it would take you around 2 years…
Still, this is a very inefficient way to solve the problem, don’t you think?
Random search
An alternative to grid search, often used in supervised ML problems, is random search.
The idea is simple: instead of checking each of the N possible hyperparameter combinations (where N is a very large number, e.g. 1,000,000,000) we randomly try a subset of them with size T (where T is much smaller than N, e.g. 100), and train and evaluate the agent T times. From these T trials, we select the combination of hyperparameters that worked best.
Random search is a more efficient way to search and works much better than Grid Search, in terms of speed and quality of the solution.
However, with random search (as the name suggests) you are essentially spinning a roulette in each iteration to decide what hyperparameter to try next. And this seems a pretty dumb way to search for something, doesn’t it?
There must be a smarter way, right? 🤔
2. The solution: Bayesian search
To search well (whatever you are searching for in life), it is generally a good idea to remember what you tried in the past, and use that information to decide what is best to try next.
This is exactly what Bayesian search methods do.
Bayesian search methods keep track of past iteration results to decide what are the most promising regions in the hyperparameter space to try next.
With Bayesian search, you explore the space with the help of a surrogate model, that gives you an estimate of how good each hyperparameter combination is. As you run more iterations, the algorithm updates the surrogate model, and these estimates get better and better.
Eventually, your surrogate model is good enough to point your search towards good hyperparameters. And voila, this is how you get them!
Bayesian search methods are superior to random search, and a perfect choice to use in Deep RL.
Different Bayesian search algorithms differ in how they build the surrogate model. One of the most popular methods is the Tree-structured Parzen Estimator (aka TPE). This is the method we will use today.
Say 👋 to Optuna
Luckily for us, there is an amazing open-source Python library called Optuna that implements Bayesian search methods.
Optuna has a clean API that abstracts away all the fine details behind TPE and other Bayesian search methods. It is a perfect plug-and-play library that we can start using without a deep understanding of the maths behind Bayesian methods.
If you want to get into the nitty-gritty details behind Bayesian search and Tree-structure Parzen Estimator I recommend you read this wonderful post by Will Koehrsen:
📝 A Conceptual Explanation of Bayesian Hyperparameter Optimization for Machine Learning
Armed with Bayesian methods and Optuna, we are ready to find the hyperparameters that will solve our problem.
So, let’s do it!
3. Hyperparameter search with Optuna
👉🏽 notebooks/09_hyperparameter_search.ipynb
Let’s start by loading the environment:
To visualize the parameters and evaluation metrics for each hyperparameter run I like to use MLflow.
MLflow is a very modular library, aimed at the operationalization of ML models (aka MLOps). One of its components is called MLFlow Tracking, and as the name suggests, it helps us track everything we need during model development. This is important when you run lots of hyperparameters experiments, and you want to log the exact configuration you used in each run.
We will log MLflow metrics to MLFLOW_RUNS_DIR under an experiment called hyperparameter_search
🔎 Vizualization of hyperparameter search results
To see the MLFLow dashboard you go to the command line, and cd into the root directory for today’s lesson.
This is how it looks like in my computer
$ cd ~/src/online-courses/hands-on-rl/03_cart_pole
Then you start the MLFLow tracking server:
$ mlflow ui --backend-store-uri mlflow_runs/
and click on the URL printed on the console, which in my case is http://127.0.0.1:5000
To optimize hyperparameters with Optuna we encapsulate
- hyperparameter sampling
- training
- and evaluation of the RL agent
in an objective() function, that returns the metric we want to optimize.
The objective function
In our case, the objective() function samples hyperparameters with a call to sample_hyper_parameters(), trains the agent for 200 episodes, and evaluates it on 1,000 new episodes. The output of this function is the average reward in these 1,000 episodes. This is the metric we want to maximize.
The function sample_hyper_parameters() samples and returns the hyperparameter values according to
- the ranges we specify
- and the sampler used by Optuna uses, which is TPE by default.
If you check the function sample_hyper_parameters() definition in src/optimize_hyperparameters.py you will see we only provide wide intervals or ranges of values where it makes sense for a hyperparameter to be. We do not need to implement any Bayesian sampling methodology, as Optuna will do it for us.
The next step is to create an Optuna study object.
Observe how we set thestorage parameter to a local sqlite file. This is important because it allows us to resume the search if, for any reason, the computer or process where we run the code crashes.
Finally, we start the search with study.optimize() and tell Optuna to try up to 100 trials.
In my MacBook, it takes around 15 minutes to hit the hyperparameters that give a 500 score, aka the perfect agent.
I recommend you monitor the results on the MLflow dashboard and interrupt the Optuna search once you see an agent hitting the 500 rewards.
This is what the results look like for me:
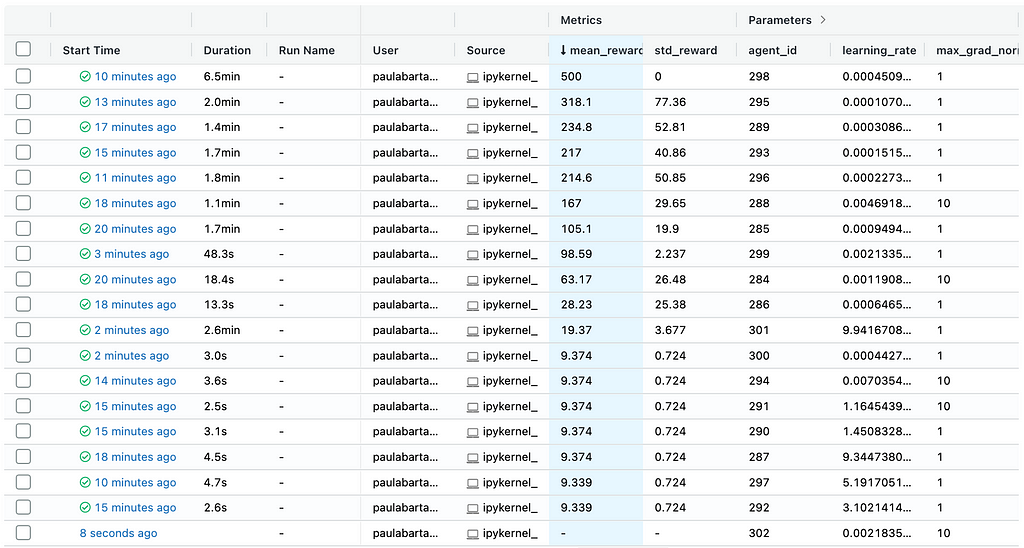
Finally, to convince you that you perfectly solved the CartPole I encourage you to load your best agent (agent_id = 298 in my case)…
…and evaluate it again. You should be scoring 500 in every episode!
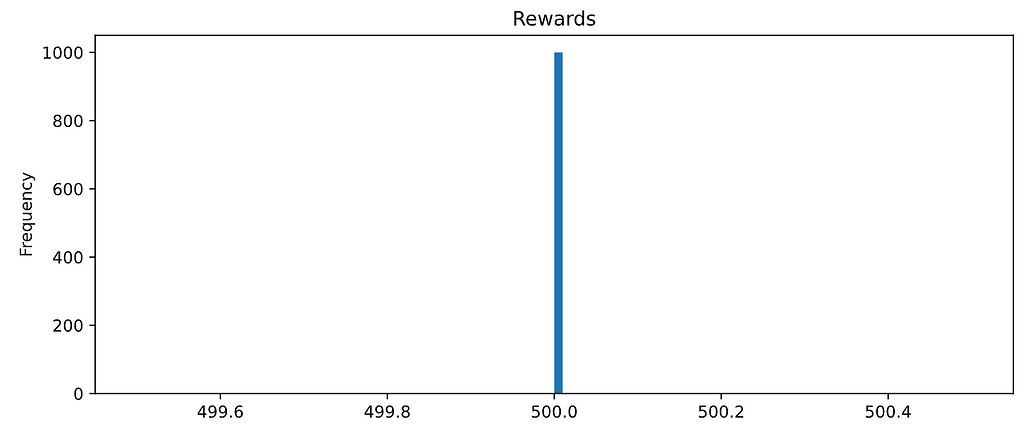
Bingo!
Congratulations on making it here. We finally learned how to tune hyperparameter to maximize the performance of our Deep Q agent.
It has been a long journey this CartPole adventure.
Time to seat, relax and look back at the path we just walked.

4. Recap ✨
These are the key takeaways for today:
- Hyperparameters in Deep RL are critical. You need to experiment to find the good ones, and this can be extremely time-consuming if you do not follow a smart search strategy. Brute-force alone (i.e. grid-search) is NOT feasible in most cases.
- Bayesian search methods are among the best tools to solve this problem. They explore and learn what are the most promising areas in the hyperparameter space to try next. They converge faster than random-search.
- Optuna is a great open-source library for hyperparameter search. It is a plug-and-play solution that abstracts away all the fine details behind Bayesian search. With a few lines of code, you can build a powerful hyperparameter experimentation pipeline.
5. Homework 📚
👉🏽 notebooks/10_homework.ipynb
Time to get your hands dirty:
- Git clone the repo to your local machine.
- Setup the environment for this lesson 03_cart_pole
- Open 03_cart_pole/notebooks/10_homework.ipynb
The challenge for today is to find a smaller network that solves perfectly the CartPole problem.
If you look carefully at the function sample_hyper_parameters() you will realize I kept the neural network architecture fixed (i.e. nn_hidden_layers = [256, 256]).
Can you find a perfect agent using a Q-network with only 1 hidden layer?
6. What’s next? ❤️
In the following lectures, we will introduce new deep RL algorithms. But, before we get there I would like to share a trick to speed up your training loops.
In the next lesson, I will share one trick I use to train deep RL models on a GPU for a reasonable price of… $0.
Wanna know how?
Stay tuned.
Until then,
Peace, love, and learning.
Do you want to become a Machine Learning PRO, and access top courses on Machine Learning and Data Science?
👉🏽 Subscribe to the datamachines newsletter.
👉🏽 Follow me on Medium.
👉🏽 Give a ⭐ to the course GitHub repo
Have a great day 🧡❤️💙
Pau
Hyperparameters in Deep RL was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/zBmSrn5
via RiYo Analytics






No comments