https://ift.tt/dDK3SYt This post was written in collaboration with Databricks partner Immuta. We thank Sam Carroll, Partner Solutions Arch...
This post was written in collaboration with Databricks partner Immuta. We thank Sam Carroll, Partner Solutions Architect, Immuta, for his contributions.
Imagine you are a NOC/SOC analyst in a globally distributed organization. You just received an alert, but you can’t access the data because of compliance roadblocks – and as a result your response time lags. But, what if there was a way to enforce data privacy and catch the baddies?
In this blog, you will learn how Databricks and Immuta solve the complicated problem of large scale data analysis and security. Databricks provides a lakehouse platform for big data analytics and artificial intelligence (AI) workloads on a collaborative cloud-native platform. Immuta ensures that data is accessed by the right people, at the right time, for the right reasons. With the Databricks Lakehouse Platform coupled with Immuta’s user and data access controls, empowers organizations to find insights in the most stringent zero trust and compliance environments.
The growing need for Zero Trust architectures
Modern Network Operation Centers (NOCs) and cybersecurity teams collect hundreds of terabytes of data per day, amounting to petabytes of data retention requirements for regulatory and compliance purposes. With ever growing petabytes that contain troves of sensitive data, organizations struggle to maintain the usability of that data while keeping it secure.
According to Akamai, a Zero Trust security model is a methodology that controls access to information by ensuring a strict identity verification process is followed. To maintain data security, Zero Trust architecture (ZTA) is emerging as a requirement for organizations. The ZTA maturity model is underpinned by visibility and analytics and governance. But this model has operational implications, as it requires organizations to adopt technologies that enable large scale data access and security.
We will use a representative example of network data to illustrate how a network security team uses Databricks and Immuta to provide a secure and performant big data analytics platform across multiple compliance zones (different countries). If you want to play along and see the data, you can download it from the Canadian Institute for Cybersecurity. By the end of this blog, you will know how to:
- Register and classify a sensitive data source with Immuta
- Implement data masking
- Enforce least privilege for data access
- Build a policy to prevent accidental data discovery
- Execute a Databricks notebook in Databricks SQL with least privilege
- Detect a DDoS threat while maintaining least privilege
Enabling Zero Trust with Databricks and Immuta
In this scenario, there are network analysts in the United States, Canada, and France. These analysts should only see the alerts for their specific region. However, when we need to perform incident analysis, we’ll need to see information on the events in other regions. Due to the sensitive nature of this data set, we should have a least privilege access model applied in our Databricks environment.
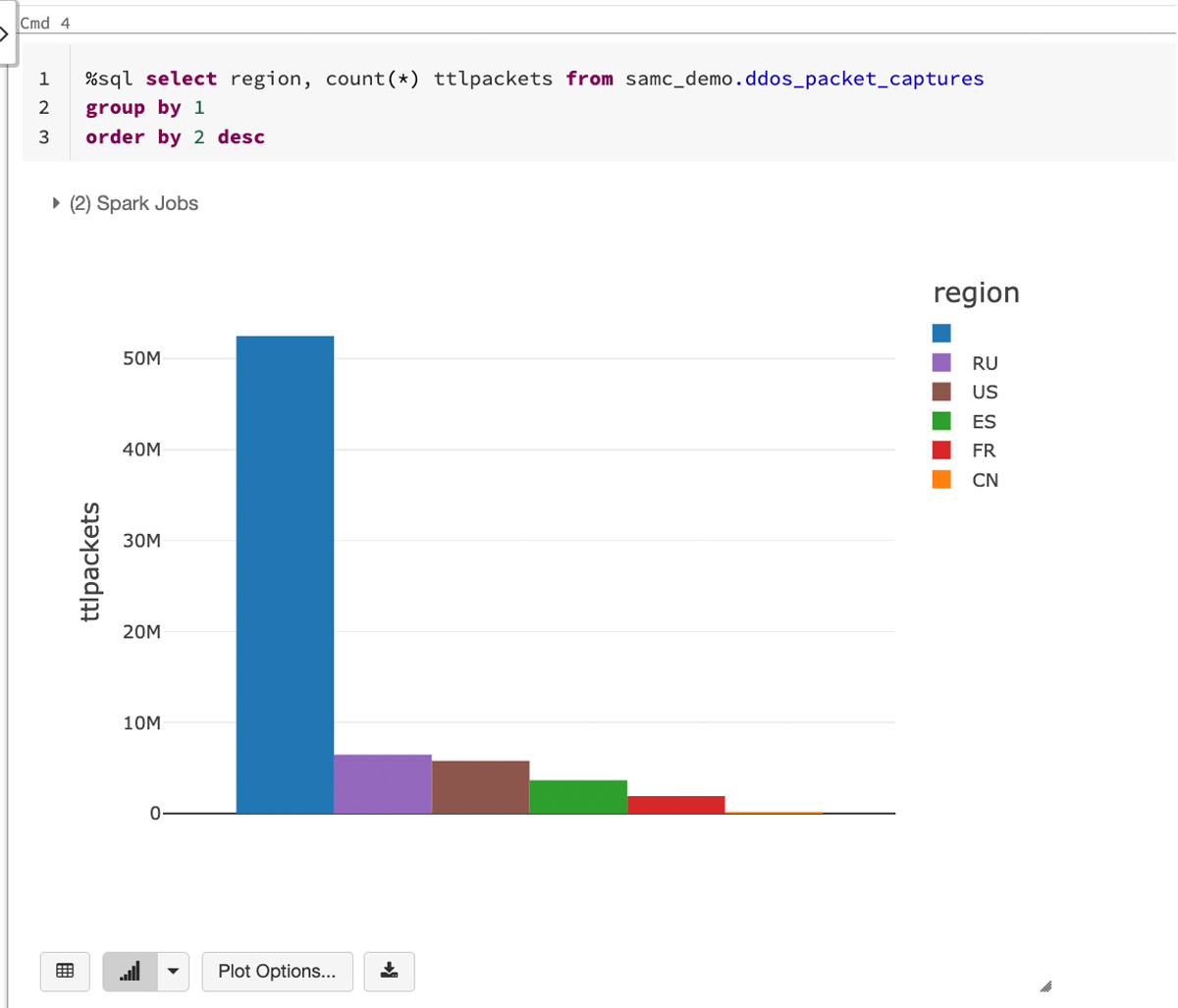
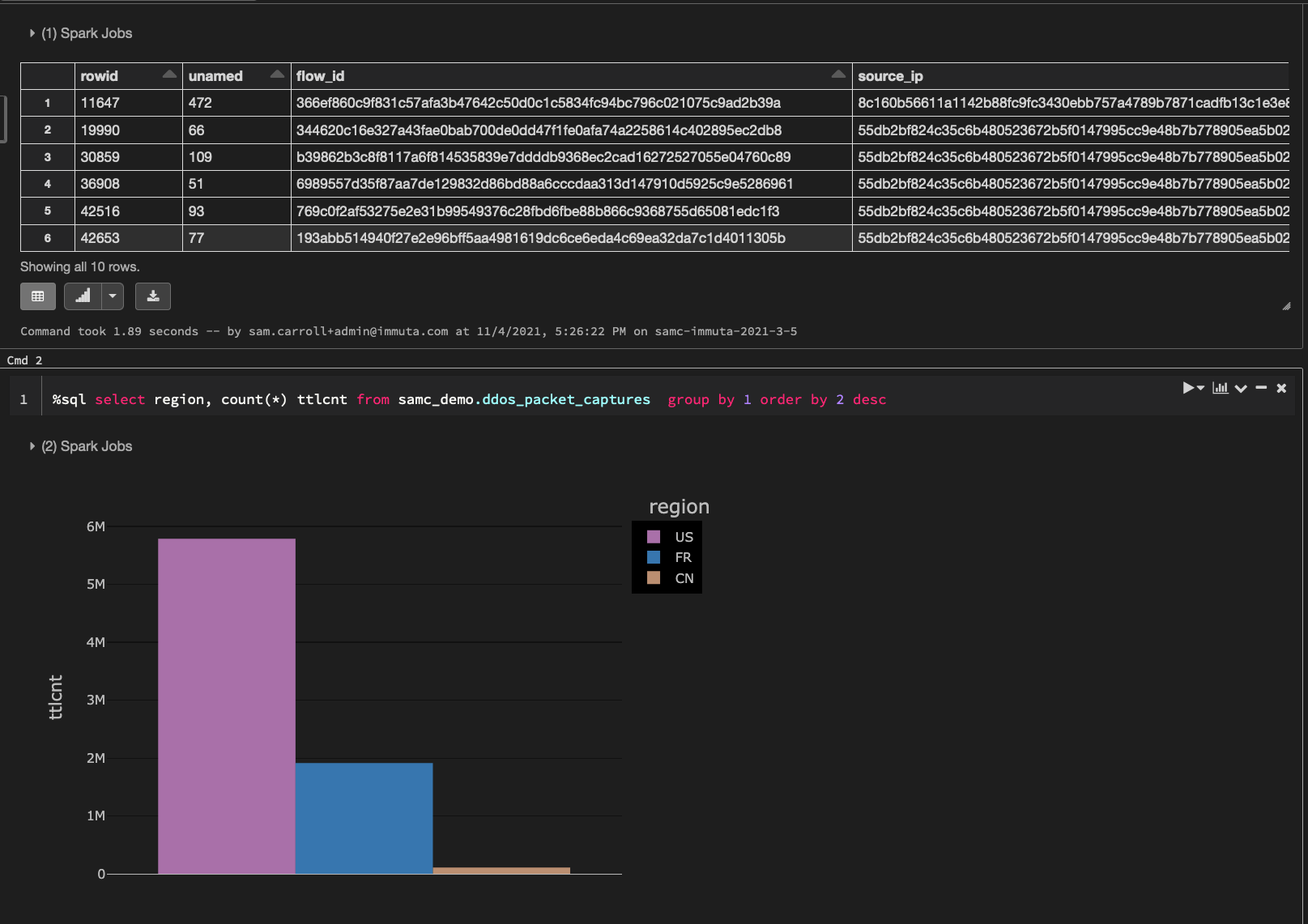
Let’s take a look at the packet capture data in Databricks that we will be using for this blog:
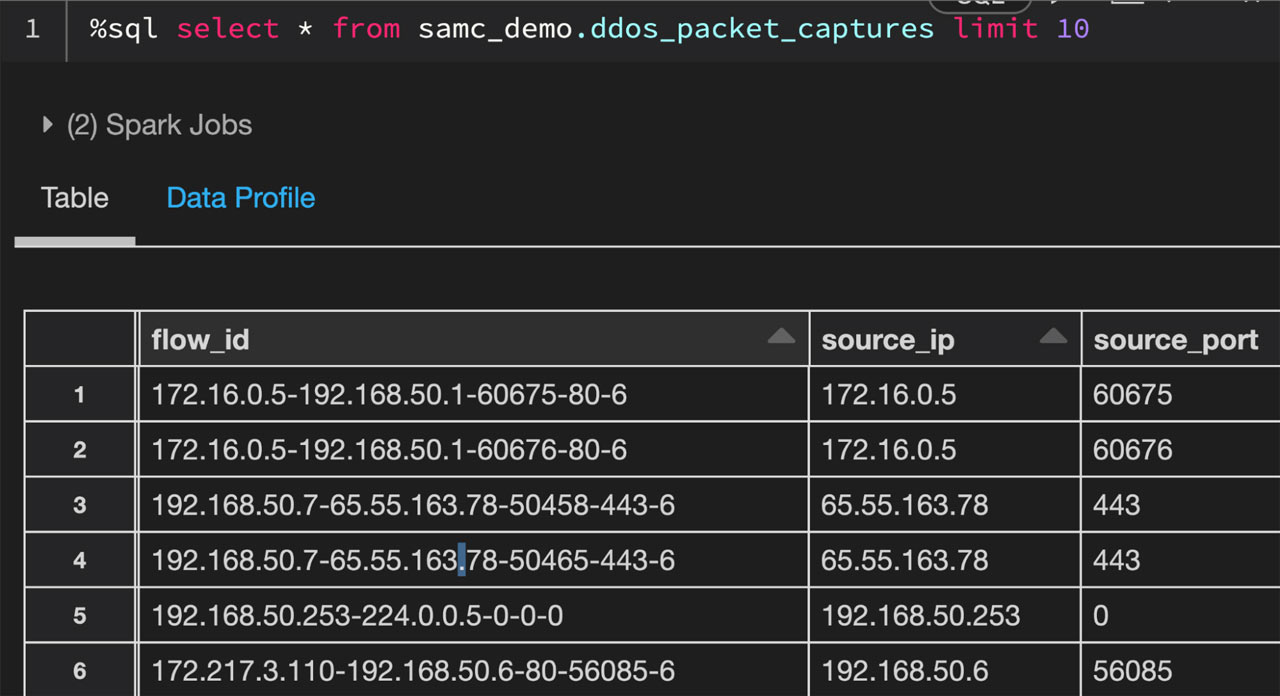
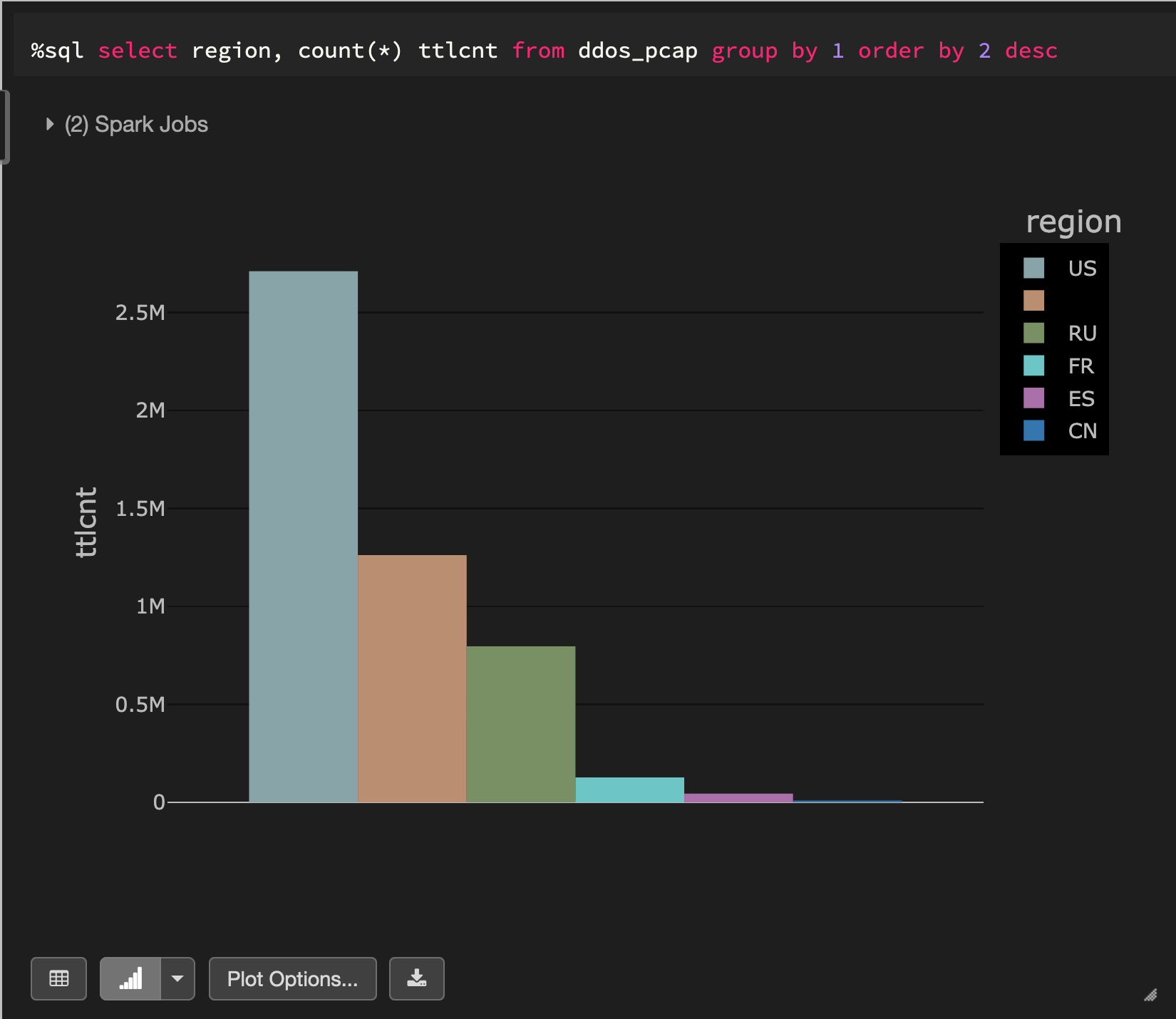
The above data illustrates packet captures during a simulated distributed denial-of-service (DDoS) attack. In order to make this a regional-based simulation, we will generate a country code for each record. Here’s how the data breaks down by country code:
Now that we’ve established what the data set looks like, let’s dive into how Immuta helps enable Zero Trust.
Immuta is an automated data access control solution that was born out of the U.S. Intelligence community. The platform allows you to build dynamic, scalable, and simplified policies to ensure data access controls are enforced appropriately and consistently across your entire data stack.
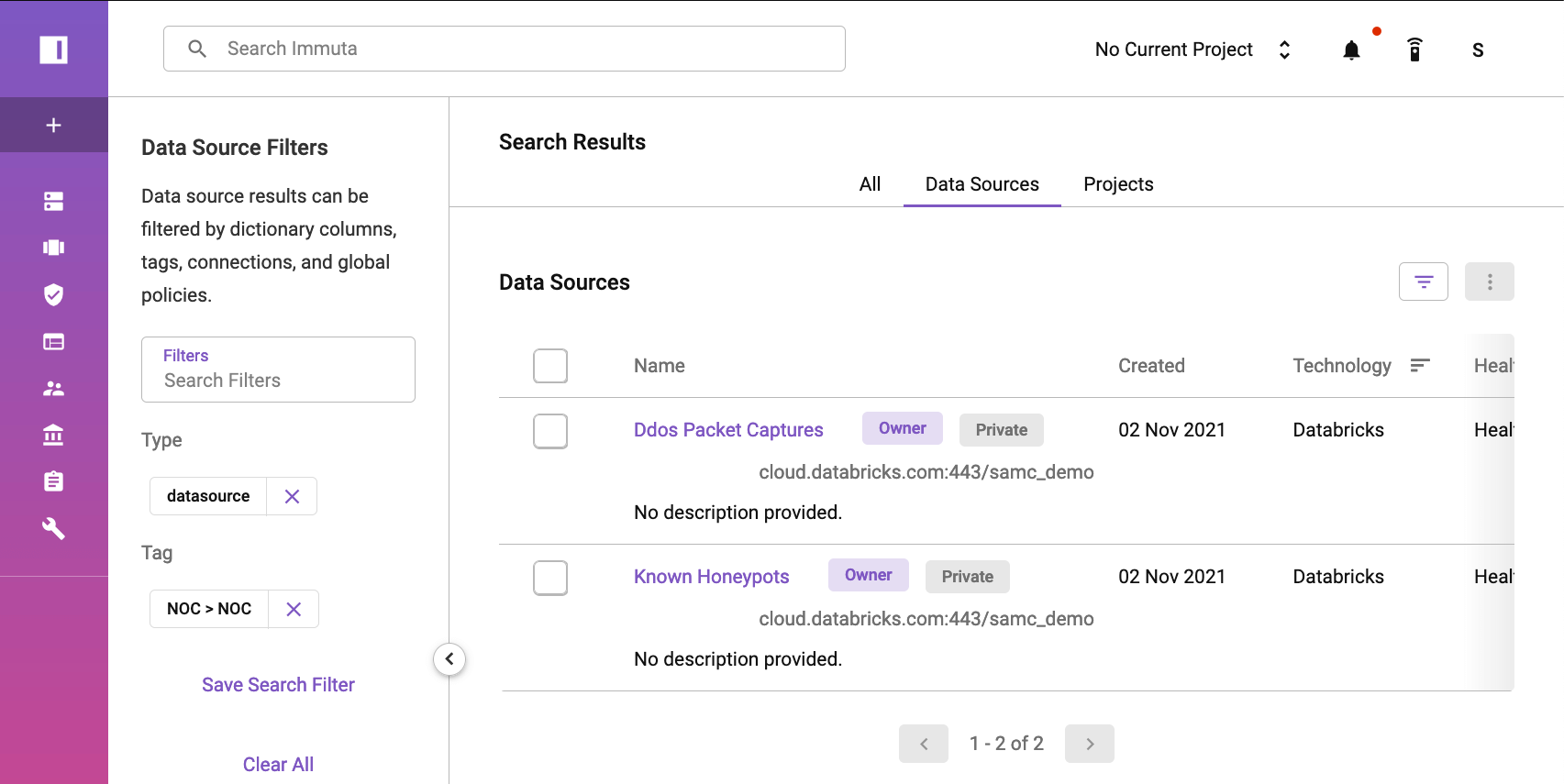
The first step to protect this PCAP data set is to register the data source in Immuta. This registration simply requires inputting connection details for our Databricks cluster. Once complete, we will see the data sets in Immuta:
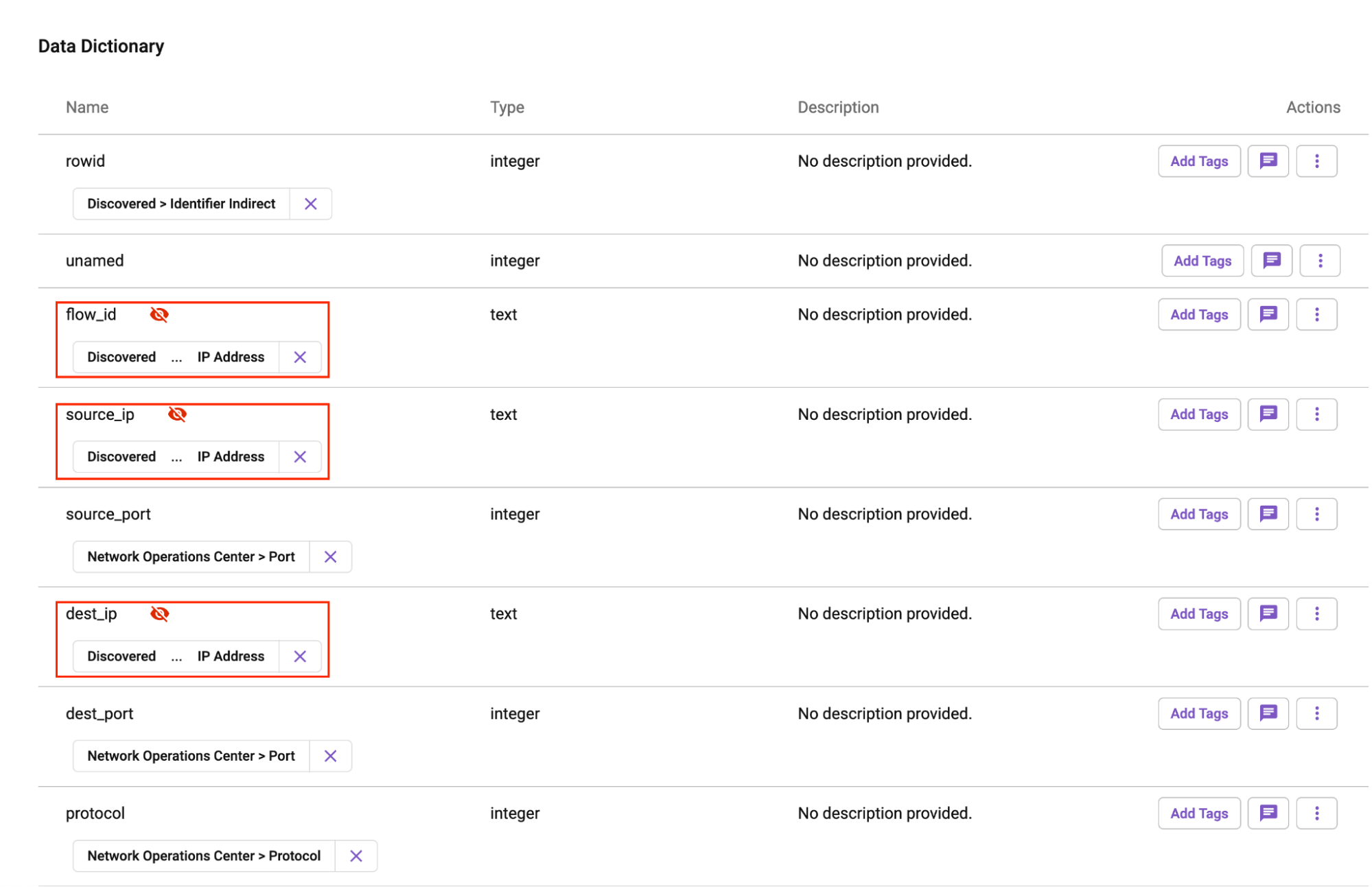
Once this table has been registered, Immuta will automatically run sensitive data discovery (SDD). This step is critical, as we will need to prevent certain users from seeing sensitive information. On the PCAP table, SDD identified several different types of sensitivity in the data set, including the IP addresses, personally identifiable information (PII), and location data in the region column.
Now that we’ve classified the data using SDD, let’s build data policies to ensure the sensitive information from the packet data is masked. Immuta offers many dynamic data masking techniques, but in this case we will use an irreversible hash. In the real world, it might not be important to see the actual values for an IP address, but the hashed values still must be consistent and unique. This is important for two reasons:
- Analysts need to ensure they can determine if a specific IP address is causing a spike in network traffic.
- Any data set containing IP addresses must be consistent. For example, imagine we have a table with honeypot server information that will need to be joined to on a hashed key. Immuta allows users to perform masked joins while ensuring sensitive information is protected using “projects.” Consistency across data sets ensures no sensitive data slips through the cracks in a collaborative project situation.
The example below shows how easy it is to ensure a user has least privilege access, meaning no user has default access to any data set in a Databricks cluster protected by Immuta. Data owners can specify why someone should get access to the data, whether it be for a legal purpose they need to attest to or based on group membership or user profile attribute. In our example, we will allow any user with a Department of “NOC” on their user profile to see this table in Databricks. With Immuta’s plain English policy building capabilities, a policy is as easy to understand as reading a sentence. Consider the following subscription policy:
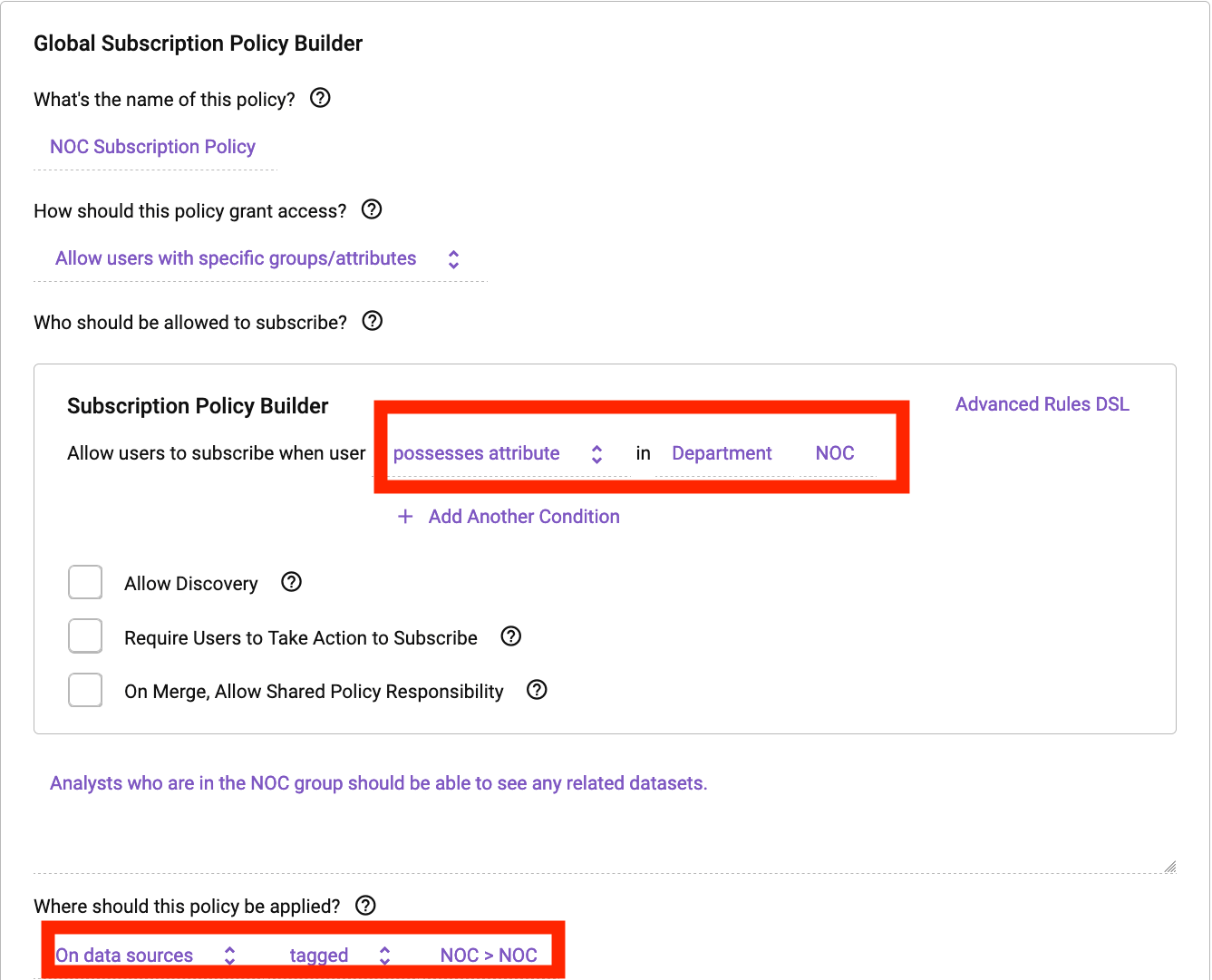
This policy will automatically dictate who can see any table that has been classified as “NOC” transparently in Databricks. Below is the Databricks notebook for someone who doesn’t have the subscription policy applied:
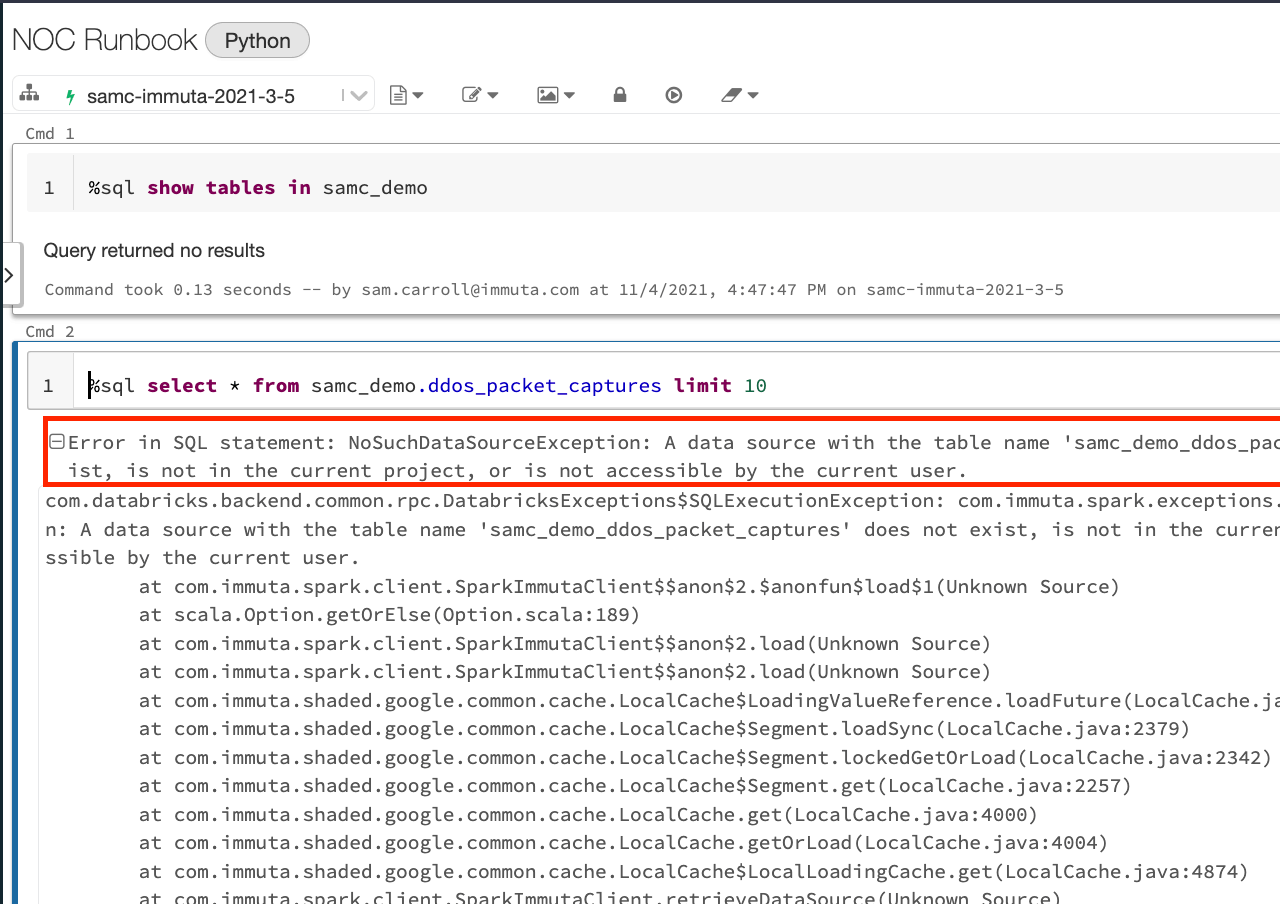
The user can’t see any tables in Databricks, and if they try to query the table directly, they get a permission error. This least-privilege concept is core to Immuta and one of the reasons it can help enable Zero Trust in Databricks.
Next, let’s enable the subscription policy and see what happens:
As you can see, the user now gets access to the PCAP table and an additional honeypot table because it was classified as a NOC data set. This is beneficial when onboarding new users, groups, or organizations, as it proactively and dynamically lets users see data sets that are relevant to their jobs, while ensuring they can access only those data sets they actually need to see.
Next, let’s build a policy to further protect the data and ensure users don’t accidentally discover any sensitive data in this Databricks environment. Below is a simple data masking policy in Immuta:
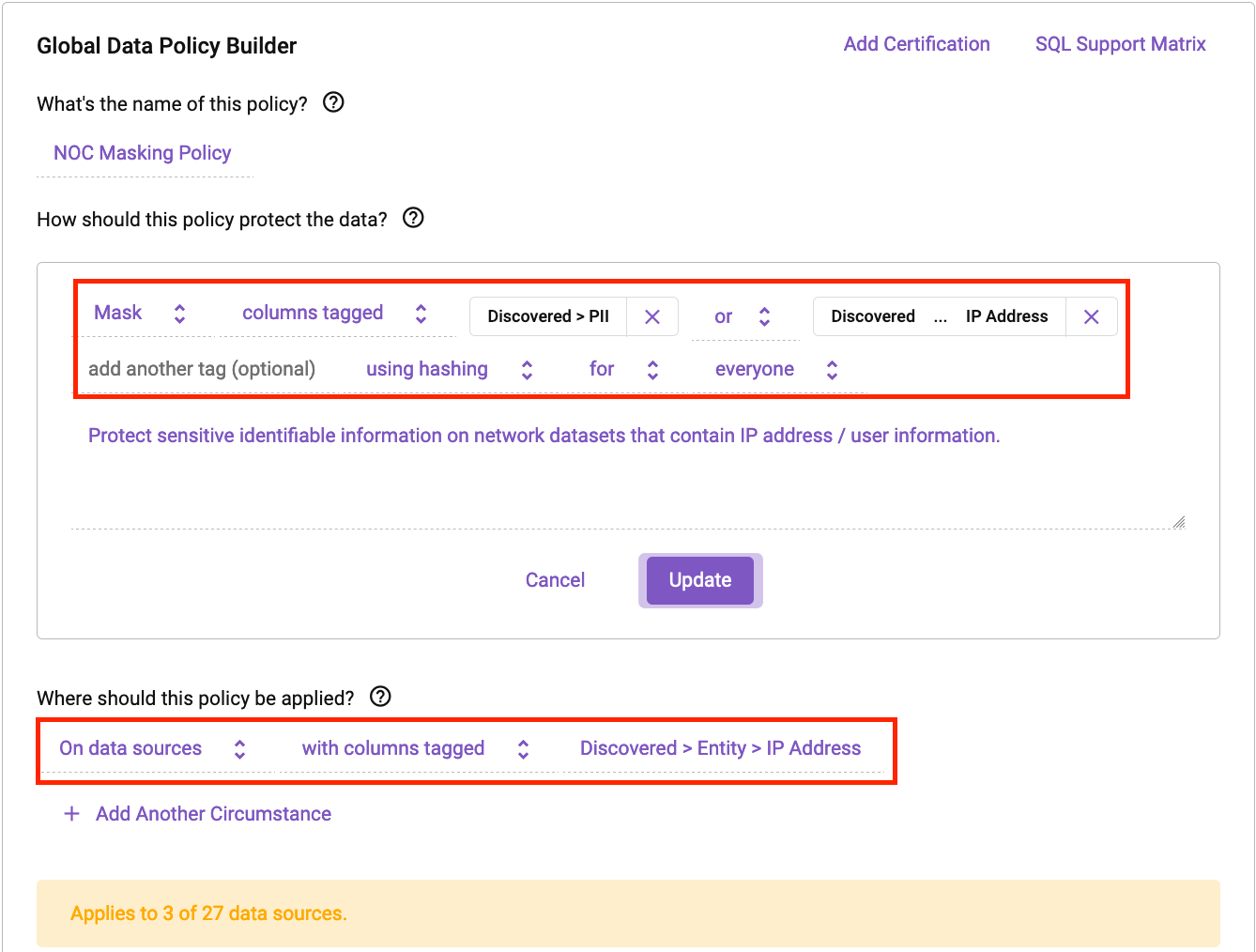
In the above example, we can see how easy it is to make rules that can protect your NOC data sets. Any data set containing an IP address will now automatically have the IP address or PII masked for anyone in the organization using Databricks. This ensures that your data is protected in a consistent manner.
Now that we’ve defined a single policy that can be applied to all of our Databricks data sets, let’s take a look at what happened to our honeypot table mentioned earlier:
Notice how all the IP address information and PII are dynamically masked. That one policy is now applied consistently across two different tables because their context is the same.
Next, let’s see how we can ensure least privilege access even more granularly by only allowing users to see the regions they are authorized to see. Currently, users can see data from all countries in their data set:
We will build a segmentation policy in Immuta that uses an attribute derived from an identity manager (in this case, Okta):
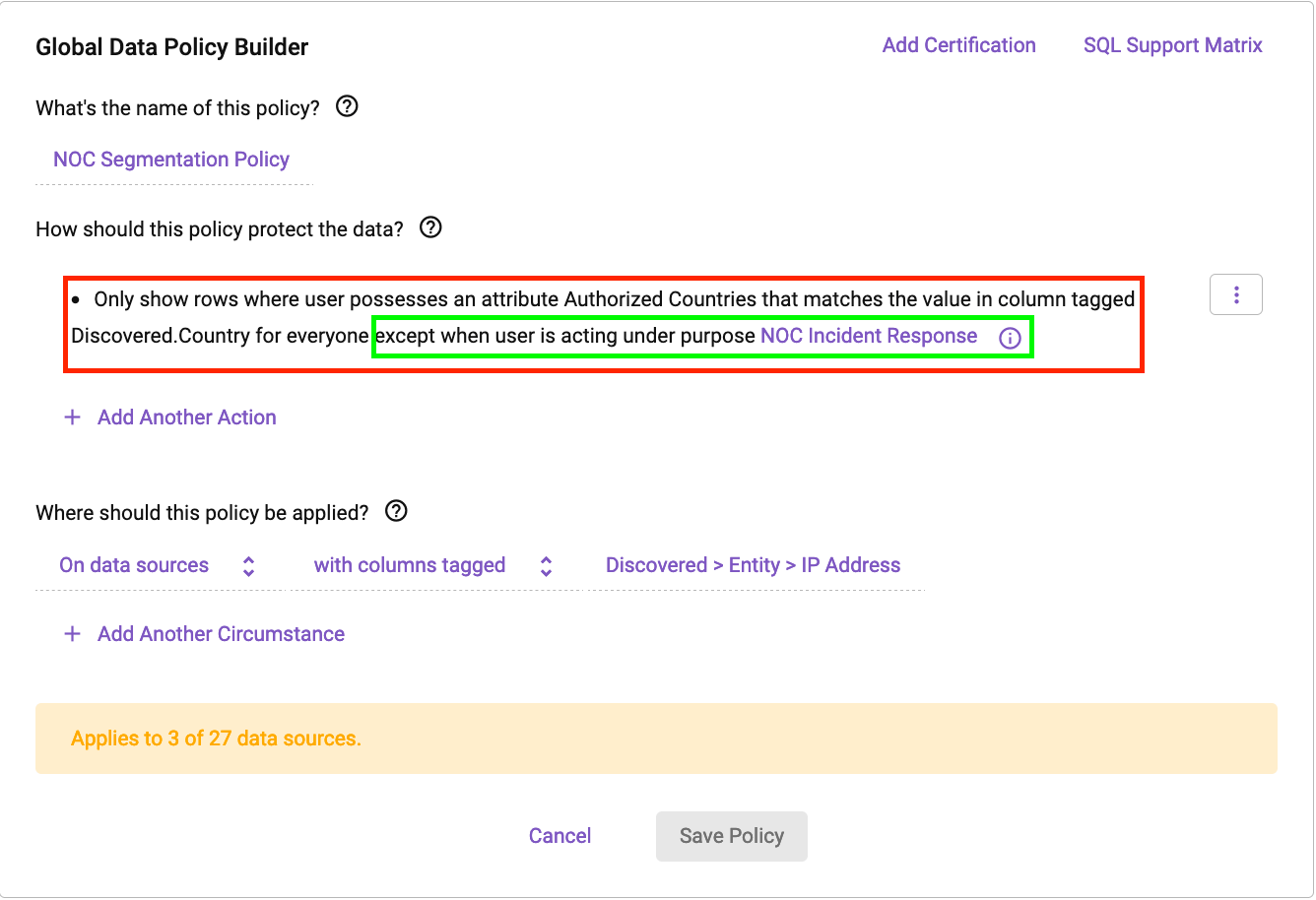
This policy states that we will use “Authorized Countries” from a user’s profile to dynamically build a filter that matches any column tagged Discovered.Country on any data set containing an IP address field.
Next, let’s dig into the exclusion rule (in green). The exclusion rule states that users won’t see filtered data when they are operating under a “Purpose” context. This purpose context states that if an analyst is working on an incident response, they are authorized to see unfiltered location data. Purposes have many uses in Immuta, including allowing users to elevate their data access privilege when necessary for a specific, approved reason. Changes like this are audited, and users can update contexts directly in a Databricks notebook.
Now that this data policy has been built, let’s dive into what it will do to our PCAP data set:
![Example of masked data set]](https://databricks.com/wp-content/uploads/2022/03/db-91-blog-img-13.jpg)
Now this user is seeing only the countries they are authorized to access, thus limiting their access to the least amount of data they should see. Let’s check another user to see what their data looks like:
This user is seeing consistent masking, but for the set of countries that they are authorized to access.
Lastly, let’s take a look at the exclusion rule we set earlier. Imagine a cyber attack has just occured and our analyst needs to view network traffic for the entire company, not just their areas of authorization. To do this, the user is going to switch context into the “Incident Response” purpose:
The user in Databricks updated their “project” context to “Incident Response.” This context gets logged in Immuta and when the user runs their subsequent query, they will see all regions within the PCAP data set because they are working under this Purpose. Now you, as the NOC analyst can detect DDoS attacks originating outside of your default access level.
We’ve walked step-by-step how quickly Immuta enables least privilege access on Databricks but to see this process in action, you can watch a demo here. Immuta provides compliance officers assurance that users will only be granted access to the information for which they should have access to, while maintaining robust audit logs of who is accessing what data source and for what reason. Utilizing both Databricks and Immuta allows NOCs to enable a Zero Trust architecture on the data lake. To get started with Databricks and Immuta request a free trial below:
https://databricks.com/try-databricks
--
Try Databricks for free. Get started today.
The post Enabling Zero Trust in the NOC With Databricks and Immuta appeared first on Databricks.
from Databricks https://ift.tt/2amrqkD
via RiYo Analytics








No comments