https://ift.tt/wkyd8cC Removing unwanted objects from videos with deep neural networks. Problem set up and state-of-the-art review. Image...
Removing unwanted objects from videos with deep neural networks. Problem set up and state-of-the-art review.

While the technology for wiping out memories, as in the famous movie “Eternal sunshine of the spotless mind”, is not there (yet), we are making good progress with images and videos. Wouldn’t it be cool to remove this random guy with a beer, ruining a stunning sunset, from a holiday video?
Video-inpainting enables us to mask unwanted parts of the video. Some time ago this job would have taken animators and graphic designers hundreds of hours of manual video editing — frame by frame.
But with the advent of machine learning we can often achieve results if not better, but certainly very close to what artists are capable of — replacing unwanted objects with content that would seamlessly fit into the video.
Just check out a small snippet below, isn’t it impressive?

To me the above animation looks incredible! Notice, for example, how high frequency textures of the grass in foreground of the dancing girl are preserved. To see how we got to these results, below I set up the problem, discuss available solutions and benchmarks. At the very bottom I also include links to the code for each of the discussed methods. With all that, let's dive in!
What are we trying to solve?
It is easier to start with an example of image inpainting — where the goal is to replace part of a scene with background, for example Adobe Photoshop provides this option for photographs.



In masking this image I specified the region that I want to inpaint. And Photoshop has replaced foreground (the selected area) with the background texture using “Content-aware fill”.
For a video this process would be more laborious, as we would need to mark all frames where the object occurs.
Video inpainiting is conceptually similar to image inpainting, however, with a slight complication — the need to satisfy temporal consistency across the whole video. Gradually changing over time video should not have flickering artifacts or sudden change in colors or shapes of objects in the inpainted region. And there are many variables that impact how difficult it is to achieve temporal consistency — complexity of the scene, changing camera position, change in the scene or movement of the selected area for inpainting (for example a moving object).
While video inpainting is more challenging compared to image inpainting — due to the need to satisfy temporal-consistency between the frames, it inherently has more cues as valid pixels for missing regions in a frame may appear in other frames.
Available solutions
Generally available methods can be distinguished by the inpainting mechanism. They can either be copy and paste – where the information for the missing pixel is searched for in the nearby frames and once found copied to the specified location, or generative, where some form of a generative model is used to hallucinate the pixel information in the region based on the content of the whole video.
Both methods have their pros and cons. Copy and paste methods work well in scenarios where pixels can be tracked through the video and would obviously fail when the information cannot be retrieved, for example a stationary video with a stationary region removed. In this case generative models would be more suitable. At the same time, generative methods might not be as accurate in reconstruction, often producing blurry, averaged across possible options, solution.
Generally proposed solutions employ Convolutional Neural Networks (CNNs), Visual Transformers or 3D CNNs. With the latter being not as popular due to memory and time constraints.
Copy and paste
To copy the contents of the missing pixel from the nearby frame we first need to trace the position of that pixel. This is typically done with optical flow.
Optical flow provides information about displacement of the background and objects across frames. If the flow is computed with little error we can trace the exact position of a specific pixel from the first till the last frame. Optical flow can be forward and backward – i.e. when the displacement is computed from the first frame forward, or from the last in reverse order.
Finding optical flow is challenging, as there are might be multiple plausible solutions. That is why backward and forward flow often do not match and often both are computed and joint information is used to refine the estimates. For a quick explanation of optical flow methods check out this article.
If we cannot borrow the content to recover the current frame from the nearby frames, the still-unknown regions can be synthesized with single image inpainting for a single frame and then propagated to the rest of the video.
Below I go over the copy and paste architectures in the chronological order. Since computational complexity of optimization-based methods for flow-estimation is high, many methods described below either find mechanisms to replace, simplify or approximate it.
Deep Video Inpainting, 2019
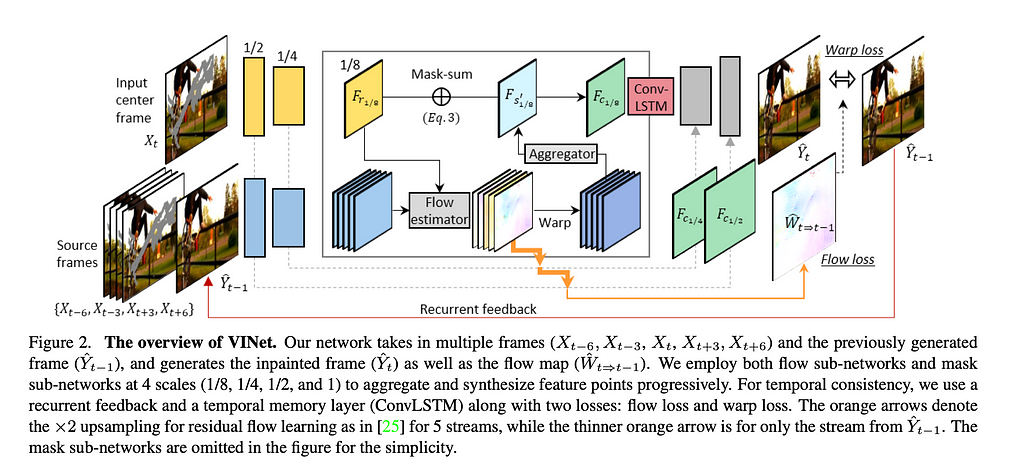
The narrative of the paper builds around ways of ensuring temporal consistency of the inpainted video. Authors set three requirements for the generation of the t-th frame. It should be should be consistent with spatio-temporal neighbour frames X(t+/-N) where N denotes a temporal radius; the previously generated frame Yt−1; and all previous history.
The first mechanism is based on feeding in the generated frame from the previous step along with the frames in the current step — recurrent feedback. Before being combined, source and reference feature points are aligned. This strategy helps the model borrow traceable features from neighbouring frames. To achieve this, flow sub-networks is used to estimate the flows between the feature maps at four spatial scales (1/8, 1/4, 1/2, and 1).
The second mechanism includes explicit flow supervision at the finest scale between two consecutive frames with FlowNet2.
While the recurrent feedback connects the consecutive frames, filling in the large holes requires more long-term knowledge. The third mechanism is based on the temporal memory layer — to help connect internal features from different time steps in the long term. Here the authors adopt a convolutional LSTM (ConvLSTM) layer and a warping loss.
The model is trained with three losses — reconstruction loss (L1 + SSIM), flow estimation loss, and the warping loss.
Copy and paste networks for deep video Inpainting, 2019
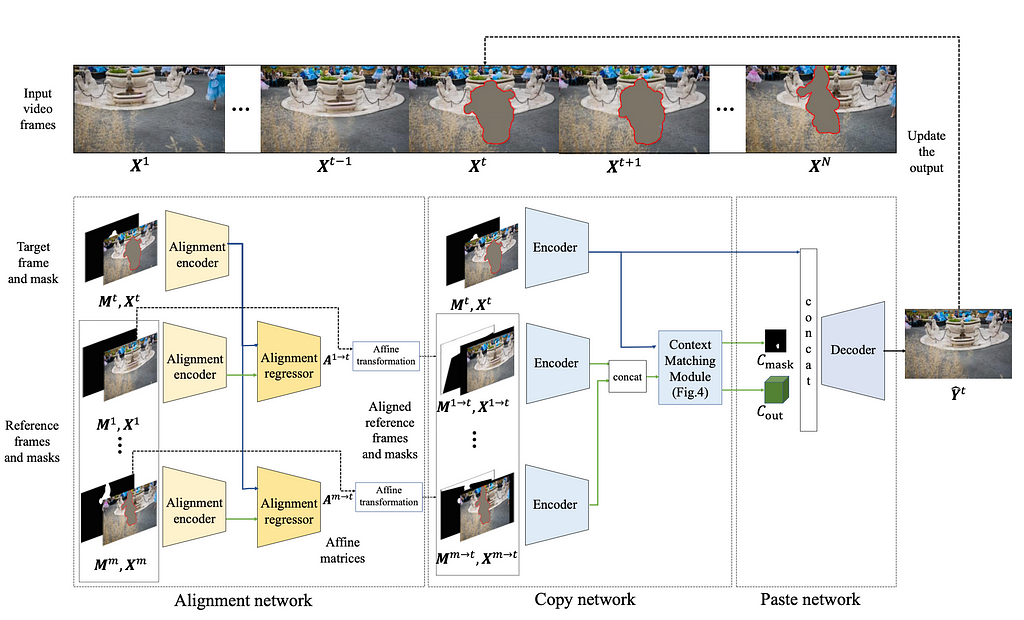
The network is based on three stages — alignment, copy, and paste.
In the alignment step reference frames are aligned with test frames — matching correspondences between pixels.
The copy stage consists of encoder and context matching modules. In the encoder module aligned frames and their masks are passed through the feature encoders. The resultant embeddings are then passed to the context matching module — combination of cosine similarity between the frame features and their visibility maps. This step produces the weight of each pixel in contributing to the missing region.
The decoder (paste module) takes the weights and concatenated frame features and outputs resultant images.
The whole network is trained with a combination of L1, style, perceptual and total variation losses.
Deep Flow Guided Image Inpainting, 2019 (DFC-Net)
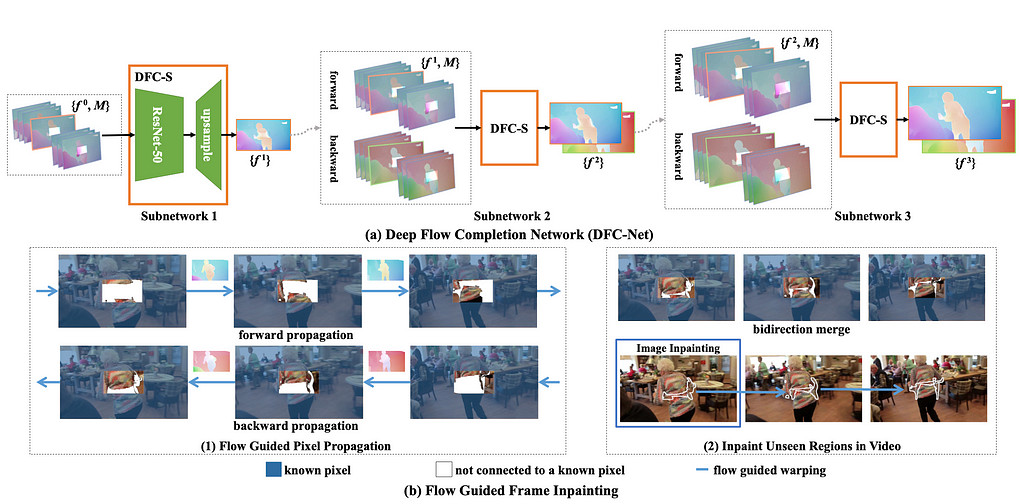
This paper addresses high computational complexity of optical flow with a coarse to fine Deep Flow Completion Network (DFC-Net) consisting of three small sub-networks — DFC-S. Each of the three subnetworks takes inputs resized to 1/2, 2/3 and 1 of the original size.
The first DFC-S takes two types of inputs: a concatenation of flow maps estimated with FlowNet2, and associated sequence of binary masks, indicating missing regions in each flow map. The network outputs a refined estimate of the flow.
The estimated flow field is used to guide propagation of pixels to fill up the missing regions. Specifically, the DFC-Net follows a coarse-to-fine refinement to complete the flow fields, while their quality is further improved by hard flow example mining.
The optimization goal is to minimize the L1 distance between predictions and ground-truth flows. However, because the majority of the flow area is smooth in video sequences, using L1 loss directly leads to dominance of smooth areas during training with the boundary region in the prediction blurred. To overcome this, all pixels are sorted in a descending order of the loss. The top p percent pixels are labeled as hard samples. Their losses are weighted more to force the model pay more attention to those regions.
Flow-edge Guided Video Completion, 2020 (FGVC)
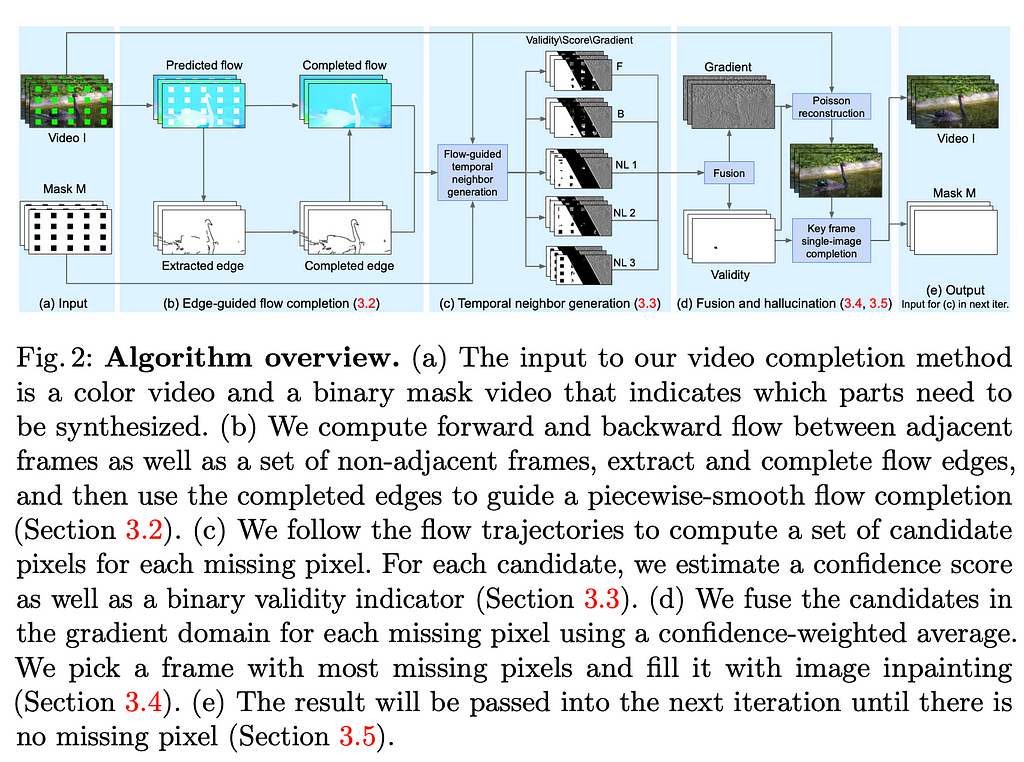
Flow-edge Guided Video Completion (FGVC) consists of flow completion, temporal propagation and fusion steps.
In the flow completion step both backward and forward flows between adjacent and non-adjacent frames are computed with a FlowNet2. To provide as much information as possible the method uses the flow both between the local and non-local frames. Since some of the information in the flow is missing (due to the mask) the method first finds edges in the flow with Canny Edge detector and EdgeConnect to connect disjoint regions. Based on the edges, an edge-guided flow compensation is performed. For non-local frames a homography warp is used to compensate for large motions.
During temporal propagation the flow trajectories are followed to propagate a set of candidate pixels for each missing pixel. Five candidate pixels are allocated — two from forward and backward flow passes and three from distant, non-local frames.
In the seamless-fusion step, the candidates are fused by confidence-weighted average. The fusion is performed in a gradient domain to avoid visible colour seams. The final fusion is obtained with the Poisson optimisation.
Occlusion-Aware Video Object Inpainting, 2021 (VOIN)
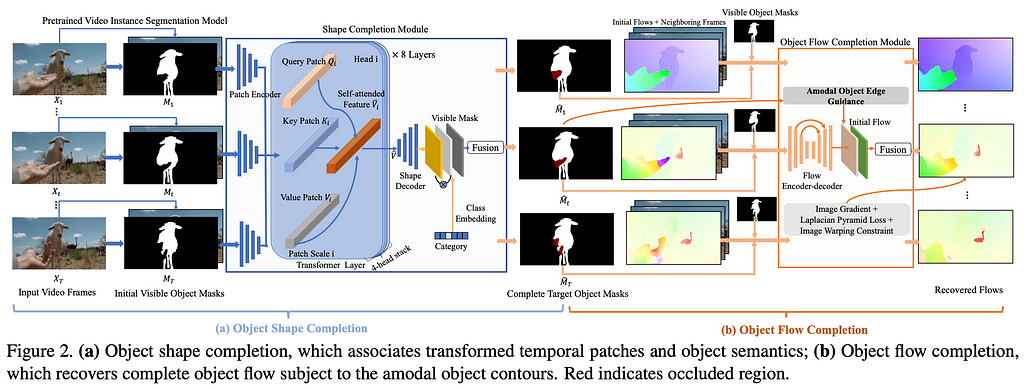
VOIN is based on the assumption that knowledge about the shape of the occluded by the mask object can boost the performance of the algorithm.
The model consists of three modules — (i) transformer-based shape completion module that learns to infer complete object shapes from visible mask regions; (ii) occlusion-aware flow completion module to capture moving objects and propagate content across even temporally distant frames, by enforcing flow consistency; (iii) flow-guided video object inpainting
In the shape completion module, object contour guides flow prediction process. Flow smoothness is enforced within the complete object region (flow gradients are typically small except along distinct object motion boundaries).
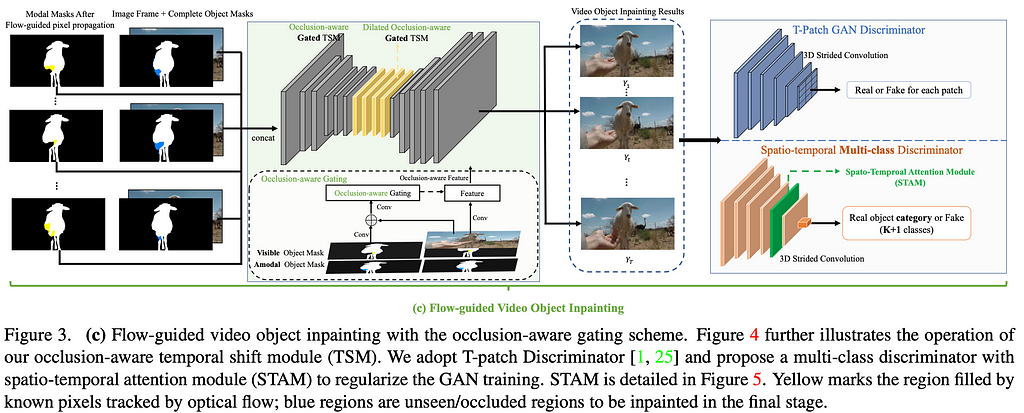
To fill in remaining pixels, authors train an occlusion-aware gated generator to inpaint occluded regions of videos objects. The model adopts residual Temporal Shift Module (TSM) as building blocks, which shift partial channels along temporal dimension to perform joint spatiotemporal feature learning.
The model is trained with two discriminators — one for perceptual quality and temporal consistency and another for object semantics. To regularize the flow completion network, L1 flow loss, image gradient loss, Laplacian Pyramid loss and warping loss of hallucinated content are employed. The shape completion module is trained with binary cross entropy and dice losses.
Along with the methods author provide a new dataset YouTube-VOI — containing 5,305 videos, a 65-category label set including common objects such as people, animals and vehicles, with over 2 million occluded and visible masks for moving video objects
Generative models
Standard image generative models, such as 2D CNN based Generative Adversarial Networks (GANs), despite their success in image inpainting, do not work as well for video inpainting. Primarily reason for that is the inability to account for temporal relationships between pixels. Thus either 3D CNNs or Vision Transformers are used. As the best performing models of this type are based on transformers, I focus on them. As a recap on visual transformers check out this blog.
One of the big drawback of transformers, however, is a very high memory requirements in attention layers, limiting their input size. Various models tackle this problem differently.
Learning Joint Spatial-Temporal Transformations for Video Inpainting, 2020 (STTN)
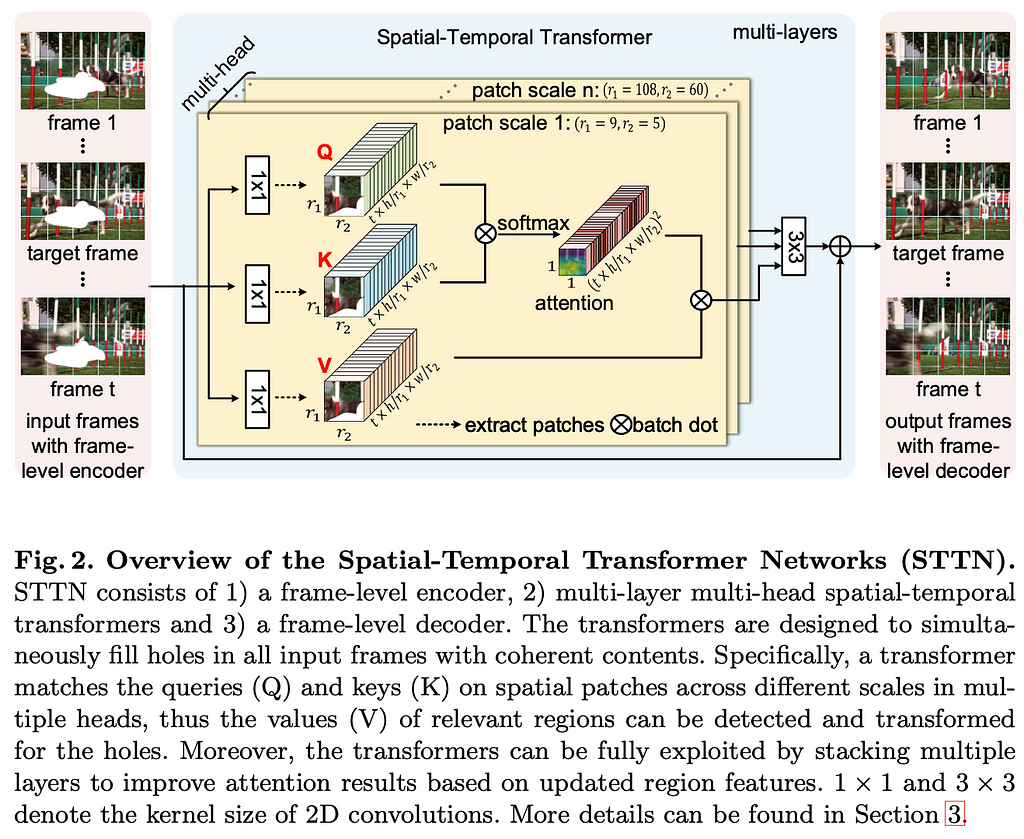
Design of the model is based on the multi-scale multi-head transformers. STTN takes as input a window of frames centered around the target frame and frames uniformly sampled from the rest of the video. Instead of processing full frames, the model uses patches of different scales.
STTN consists of three components — frame-level encoder, multi-layer multi-head spatial-temporal transformers, and frame-level decoder. The frame-level encoder is a CNN, that encodes deep features for each frame. Similarly, the frame-level decoder decodes features back to frames.
Spatial-temporal transformers are the core component, learning joint spatial-temporal transformations for all missing regions. Different heads of the transformer calculate similarities on spatial patches across different scales. The transformer runs the “Embedding-Matching-Attending” algorithm. In the embedding step features, extracted with encoders or former layer transformers, are mapped to query and memory (key-value). In matching step region affinities are calculated by matching queries and keys among spatial patches that are extracted from all the frames. In the attending step relevant regions are detected and transformed for missing regions with an output calculated by a weighted summation from relevant patches.
The model is trained with L1 and adversarial losses.
Decoupled spatial transformers for video Inpainting, 2021 (DSTT)
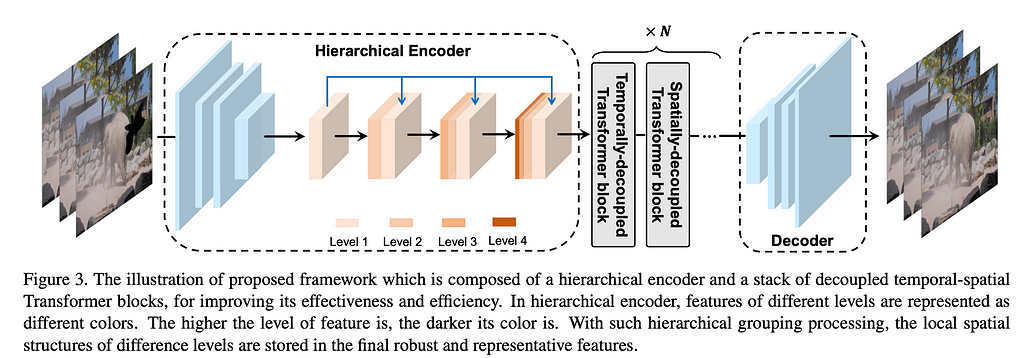
DSTT is architecture different from STTN, in that it processes spatial and temporal features separately. The method is based on several architectural blocks — stacked feature encoder (Convolutional Neural Network), one spatially decoupled and one temporarily decoupled transformer and a decoder.
The hierarchical feature encoder is a stack of convolutional layers with bottom features appended to the deeper layers, thus propagating low level details from layer to layer.
Aggregated features for a single frame are then split into patches and passed through the spatially decoupled transformer. Temporarily decoupled transformer uses feature patches of several sequential frames at the same spatial location as input embeddings. The output is then aggregated and passed through the decoder.
The model is trained with L1 and adversarial losses.
FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting, (2021)
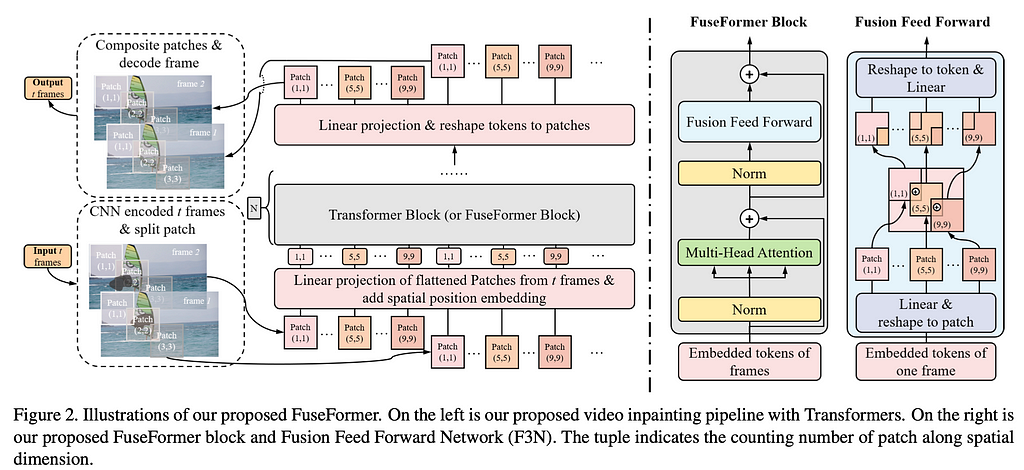
The paper is proposed by the same group that worked on DSTT. The work, however, does not mention DSTT and contrasts itself only with STTN. Instead of introducing CNN based feature extractor based on patches at various scales before the transformer, authors rely on a single scale architecture of originally proposed Vision Transformers (ViT).
The new model introduces two modifications to the original ViT — patch soft split and soft patch composition, and a FuseFormer block. All of which, as the paper claims boost the performance of the baseline model.
The soft split module, breaks images into patches with overlapping regions and correspondingly, soft composite combines these overlapped patches back to images.
A Fusion Feed Forward Network (F3N) replaces the two-layer MLPs in the standard Transformer model. In F3N, between the two fully-connected layers, each 1D token is reshaped back to 2D patch with its original spatial shape and then softly composited to be a whole image. The overlapping features of pixel at overlapping regions would sum up the corresponding value from all neighbouring patches for further fine-grained feature fusion. Then patches are softly split and flattened into 1D vectors, which are fed to the second MLP.
The model is trained on a combination of L1 and Adversarial losses.
Benchmarking — how to compare the models
The difficulty of evaluating generative models for videos is in finding a good benchmark that would test for: spatial quality, temporal consistency and realism. Video inpainting is a particularly challenging task to evaluate, as it depends on multiple factors, such as camera motion, object motion and mask size and all of these should be tracked in evaluating the performance.
The best judge of the performance of these methods would be a human observer. However, conducting experiments with human participants is expensive and time-consuming. I talked in great details about the challenges and ways of improving current data collection methods in the two articles: Deep Image Quality Assessment and Active sampling for pairwise comparisons.
A substitute of the human observer are objective quality metrics. A recent paper with a catchy name: The devil is in the details: a diagnostic evaluation benchmark for video inpainting compares the state of the art methods on a new exhaustive benchmark dataset covering plethora combinations of various scenarios for video inpainting:
- Mask size small/big
- Mask shape changing slow/fast
- Mask displacement speed slow/fast
- Background motion high/low
- Camera motion high/low
The benchmark includes nine image quality metrics including typical for image quality and realism FID, LPIPS, PSNR and FSIM as well as those taking into account temporal consistency — VFID, PVCS and warping error.
Summary
Creating a fully functioning application for video-inpainting is a huge engineering challenge. Although there are some very impressive results, all of the methods can still produce noticeable artifacts while getting the to real-time speeds is a huge engineering effort.
Another phenomenon, that needs to be tackled are parts of the frame that are associated with the inpainted object, such as shadows or reflections, which are sometimes hard to spot, but nevertheless need to be removed as well. One of the methods dealing with such problems would be a recent Omnimate paper, produced by Google, Oxford and Weizmann institute of Science.
However, as always, great progress comes with technology mis-use. And one of the most obvious cases for video inpainting are deep fakes. Which, in the modern world based on constant streams of information could seriously harm individual lifes and societies at larger scales. Just imagine forged evidence in the court or mis-information on social media, where sources are often not checked. That is why there are papers that look into remedying the problem by developing methods for inpainted region detection, like that one.
In this article I have talked about the following papers in deep video inpainting listing works that are:
Copy and paste: Deep Video Inpainting, 2019, (code); Copy and paste networks for deep video Inpainting, 2019, (code); Deep Flow Guided Image Inpainting (DFC-Net), 2019, (code); Flow-edge Guided Video Completion (FGVC), 2020, (code); Occlusion-Aware Video Object Inpainting (VOIN), 2021 (project-page).
Generative: Learning Joint Spatial-Temporal Transformations for Video Inpainting (STTN), 2020, (code); Decoupled spatial transformers for video Inpainting (DSTT), 2021, (code); FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting, 2021, (code).
I hope you liked this article and if so, let’s keep track of the field together — share it with a friend!
To read more on machine learning and image processing press subscribe!
Have I missed anything? Do not hesitate to leave a note, comment or message me directly!
Deep Video Inpainting was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/hMRs4nk
via RiYo Analytics






No comments