https://ift.tt/Ay5UaCL Utilize UK Gazette API capabilities to construct a knowledge graph and analyze it in Neo4j I love constructing know...
Utilize UK Gazette API capabilities to construct a knowledge graph and analyze it in Neo4j
I love constructing knowledge graphs from various sources. I’ve wanted to create a government knowledge graph for some time now but was struggling to find any data that is easily accessible and doesn’t require me to spend weeks developing a data pipeline. At first, I thought I would have to use OCR and NLP techniques to extract valuable information from public records, but luckily I stumbled upon UK Gazette. The UK Gazette is a website that holds the United Kingdom’s official public record information. All the content on the website and via its APIs is available under the Open Government License v3.0. This means that while the endpoint returns personal information such as names of related people, I will exclude that information in this post. Since they offer the public record information through an API endpoint, we don’t have to use any scraping tool to extract the information. Even more impressive is that you can export the data in linked data format (RDF). Linked data is a format to represent structured data which is interlinked and essentially represents a graph as you are dealing with nodes and relationships.
For example, we can look at an example notice that contains a road traffic act notice. If we click on the linked data view of the notice, we can examine the data structure. I omitted the notice screenshots in this post due to uncertainty of the license rights, but all the data is available on the official public record website.
We can take the linked data information about the give road traffic act notice and construct a knowledge graph.
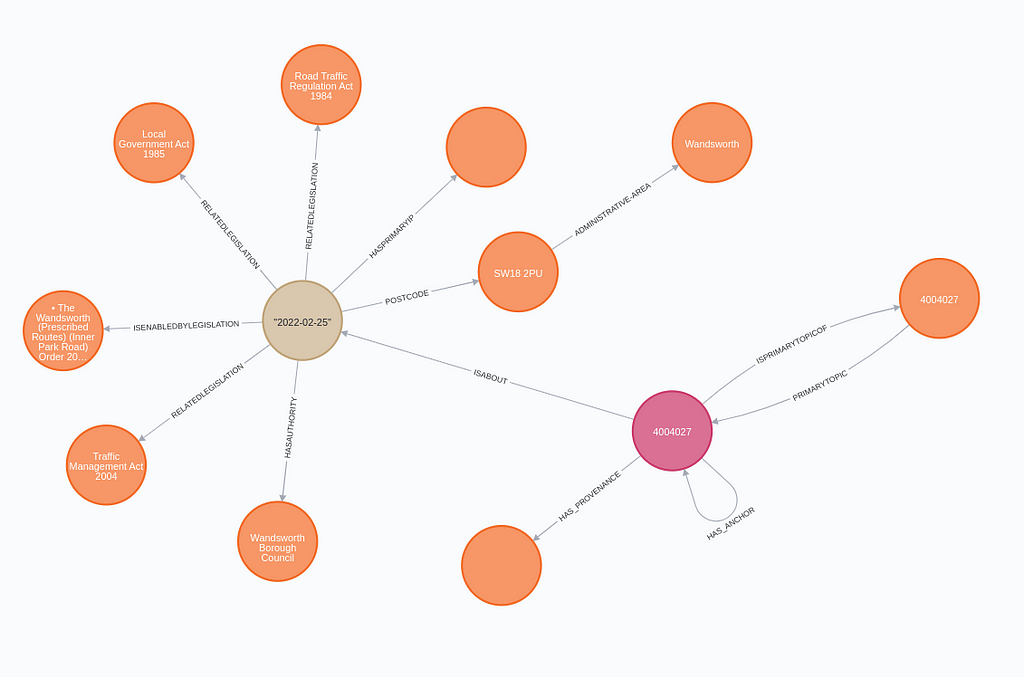
Since the linked data structure (RDF) already contains information about nodes and relationships, we don’t have to define a graph schema manually.
Most graph databases use either the RDF (Resource Description Framework) or the LPG (Labeled-property graph) model under the hood. If you are using an RDF graph database, the structure of the linked data information will be identical to the graph model in the database. However, as you might know from my previous posts, I like to use Neo4j, which utilizes an LPG graph model. I won’t go much into the difference between the two models here. If you want to learn more about the difference between the RDF and LPG models, I would point you to the presentation by Jesús Barrasa.
Since the linked data structure is frequently used to transmit data, the folks at Neo4j have made it easy to import or export data in the linked data format by using the Neosemantics library. In this post, we will be using the Neo4j database in combination with the Neosemantics library to store the linked data information fetched from the UK Gazette’s API.
As always, if you want to follow along, I have prepared a Colab notebook.
Environment setup
To follow along, you need to have a running instance of the Neo4j database with the Neosemantics library installed.
One option is to use the Neo4j Sandbox environment, a free cloud instance of the Neo4j database with the Neosemantics library pre-installed. If you want to use the Neo4j Sandbox environment, start a blank project that comes with an empty database.
On the other hand, you could also use a local environment of Neo4j. If you opt for a local version, I recommend using the Neo4j Desktop application, a database management application that has a simple interface for adding plugins with a single click.
Setting up connection to Neo4j instance
Before we begin, we have to establish connection with Neo4j from the notebook environment. If you are using the Sandbox instance, you can copy details from the Connection Details tab.
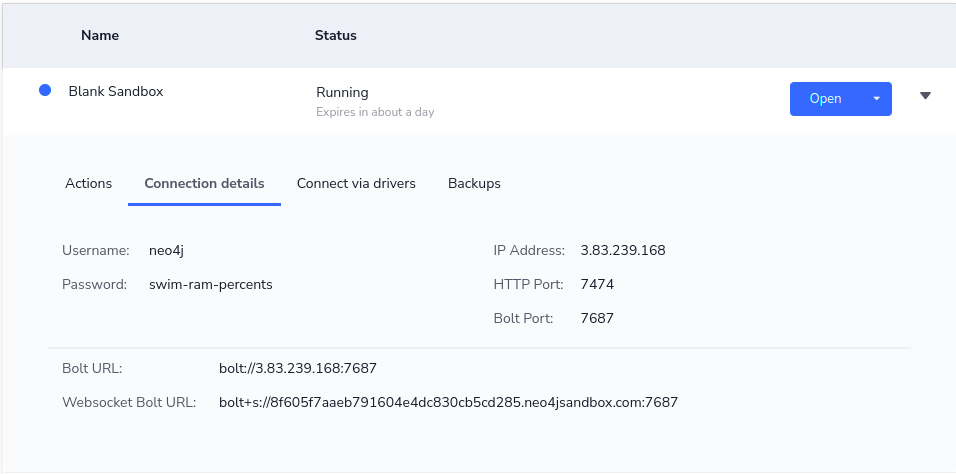
Now you can simply input your connection details in the code:
Configuring Neosemantics library
It is required to define a unique constraint on the Resource nodes for the Neosemantics library to work. You can define the unique constraint using the following Cypher statement.
CREATE CONSTRAINT n10s_unique_uri IF NOT EXISTS ON (r:Resource)
ASSERT r.uri IS UNIQUE
Next, we need to define the Neosemantics configuration. We have a couple of options to specify how we want the RDF data to be imported as an LPG graph. We’ll keep most of the configuration default and only set the handleVocabUri and applyNeo4jNaming parameters. Again, you can inspect the documentation for the complete reference of configuration options.
Use the following Cypher statement to define the Neosemantics configuration.
CALL n10s.graphconfig.init({
handleVocabUris: 'MAP',
applyNeo4jNaming: true
})
Construct a knowledge graph of UK public record
We will utilize the UK Gazette API to search for notices. The Notice Feed API is publicly available and doesn’t require any authorization. However, you need to pretend you are a browser for it to work for some reason. I have no idea the reason behind this, but I spent 30 minutes of my life trying to make it work. The documentation of the API is available on GitHub.
The main two parameters to filter notices via the API are the category code and notice type. The category code is the higher-level filter, while the notice type allows you to select only a subsection of a category. The complete list of category codes and notice types is available on the following website. There is a broad selection of notices you can choose from, ranging from State and Parliament to Companies regulation and more.
As mentioned, we can download the linked data format information for each notice. A nice thing about the Neosemantics library is that it can fetch data from local files as well as simple APIs. The workflow will be the following.
- Use the Notice Feed API to find relevant notice ids
- Use the Neosemantics to extract RDF information about specified notice ids and store it in Neo4j
The following Cypher statement is used to import information in RDF/XML structure from UK Gazette API.
The Cypher statement expects the data parameter to contain a list of links where the RDF/XML information about the notices is available. The Neosemantics library supports other RDF serialization formats as well, such as JSON-LD and others, if you might be wondering.
Lastly, we will define the function that will take in the category code and notice type parameters and store the information about notices in the Neo4j database.
We get 100 notice ids from each request to the Notice Feed API. I’ve included the pagination feature in the function if you want to import more. As you might see from the code, we make a request to the notice feed and construct a list of links where the RDF/XML information about notices is stored. Next, we input that list as the parameter to the Cypher statement, where the Neosemantics library will iterate over all the links and store the information in Neo4j. It’s about as simple as it gets.
Now we can go ahead and import the last 1000 notices under the state category code. If you look at the notice code reference, you can see that the state notices fall under the category code value of 11.
The graph schema of the imported graph is complex and not easy to visualize so we will skip that. I didn’t spend much time apprehending the whole graph structure, but I prepared a couple of sample Cypher statements that could get us started.
For example, we can examine the last five receivers of any awards.
MATCH (award)<-[:ISAWARDED]-(t:AwardandHonourThing)-[:HASAWARDEE]->(person)-[:HASEMPLOYMENT]->(employment)-[:ISMEMBEROFORGANISATION]->(organization)
RETURN award.label AS award,
t.relatedDate AS relatedDate,
person.name AS person,
employment.jobTitle AS jobTitle,
organization.name AS organization
ORDER BY relatedDate DESC
LIMIT 5
Results
I’ve learned that one can also be appointed as the commander in the Order of the British Empire.
MATCH (n:CommanderOrderOfTheBritishEmpire)<-[:ISAPPOINTEDAS]-(notice)-[:HASAPPOINTEE]->(appointee),
(notice)-[:HASAUTHORITY]->(authority)
RETURN n.label AS award,
notice.relatedDate AS date,
appointee.name AS appointee,
authority.label AS authority
ORDER BY date DESC
LIMIT 5
Results
To steer away from awards, we can also inspect which notices that are related to various legislation.
MATCH (provenance)<-[:HAS_PROVENANCE]-(n:Notice)-[:ISABOUT]->(l:Legislation:NotifiableThing)-[:RELATEDLEGISLATION]->(related)
RETURN n.hasNoticeID AS noticeID,
n.uri AS noticeURI,
l.relatedDate AS date,
provenance.uri AS provenance,
collect(related.label) AS relatedLegislations
ORDER BY date DESC
LIMIT 5
Results
The nice thing about our knowledge graph is that it contains all the data references to the Gazette website. This allows us to verify and also find more information if needed. In addition, through my data exploration, I’ve noticed that not all information is parsed from notices as a lot of information is hard to structure as a graph automatically. More on that later.
Suppose you are like me and get quickly bored by state information. In that case, you could fetch more business-related information such as companies buying back their own stock, company directors being disqualified, or partnership dissolutions.
I’ve spent 30 minutes figuring out how to properly use notice types and category code parameters to filter notice feeds. You must include the category code parameter when you want to filter by notice type. Otherwise, the filtering won’t work as expected.
We don’t have to worry about creating separate graphs or databases for additional notice feeds. The graph schema is already defined in the RDF/XML data structure, and you can import all the notice types into a single Neo4j instance.
Now you can examine which partnerships have dissolved.
MATCH (n:PartnershipDissolutionNotice)-[:ISABOUT]->(notifiableThing)-[:HASCOMPANY]->(partnership),
(notifiableThing)-[:ISENABLEDBYLEGISLATION]->(enabledby)
RETURN n.hasNoticeID AS noticeID,
notifiableThing.relatedDate AS date,
notifiableThing.uri AS noticeURI,
enabledby.label AS enablingLegislation,
partnership.name AS partnership
ORDER BY date DESC
LIMIT 5
Results
Another interesting information is about which companies have or intend to buyback their own shares.
MATCH (legislation)<-[:RELATEDLEGISLATION]-(n:RedemptionOrPurchase)-[:HASCOMPANY]->(company)
RETURN n.relatedDate AS date,
company.name AS company,
company.uri AS companyURI,
collect(legislation.label) AS relatedLegislations,
n.uri AS noticeURI
ORDER BY date DESC
LIMIT 5
Results
Taking in to the next level
As mentioned before, there are some example where not all information is extracted from notices in a linked data structure. One such example are the members change in partnership. We have the information about the partnership in which the membership changed, but not exactly what has changed. All the data we can retrieve is the following:
MATCH (notice)-[:ISABOUT]->(n:PartnershipChangeInMembers)-[:HASCOMPANY]->(company)
RETURN notice.hasNoticeID AS noticeID,
notice.uri AS noticeURI,
n.relatedDate AS date,
company.name AS company
ORDER BY date DESC
LIMIT 5
Results
For example, if we inspect the first notice on the website we can observe that the actual changes of members are not available in the linked data format. I think that the reason for missing information about membership changes is that there are too many variations of the membership change notice to capture them all in a structured way.
It seems like all the roads lead to Rome, or in our case, when dealing with text, you will possibly have to utilize NLP techniques. So I’ve added a simple example of using SpaCy to extract organizations and person entities from notices.
The text of notices is not stored in our knowledge graph, so we have to utilize the UK Gazette API to retrieve it. I’ve used BeatifulSoup to extract the text from the XML response and then run it through SpaCy’s NLP pipeline to detect organizations and person mentions. The code doesn’t store the entities back to Neo4j. I’ve just wanted to give you a simple example of how you could start utilizing NLP capabilities to extract more information.
We can now detect entities for a couple of changes in members of partnership notices.
The results are the following:
Extracting entities for 3996989
Pursuant to section 10 of the Limited Partnerships Act 1907, notice is hereby given in respect of IIF UK 1 LP, a limited partnership registered in England with registered number LP012764 (the “Partnership”), that:
1. FCA Pension Plan Trustee Limited as trustee of the FCA Pension Plan was admitted as a new limited partner of the Partnership.
Entities
--------------------
IIF UK 1 LP ORG
LP012764 ORG
the FCA Pension Plan ORG
The NLP pipeline doesn’t extract specific changes, but at least it’s a start since you can’t create a rule-based difference extraction due to having a non-standard structure of the text. If you run the extraction, you can observe that the notices are wildly different in text structure and information. I’ve omitted other examples as they contain personal information.
Conclusion
The UK Gazette APIs offer a wealth of official information that you can use to examine state, businesses, or personal insolvencies. These are just a few example use-cases from the top of my mind. Using the Neosemantics library, you can easily import the retrieved linked data format into Neo4j, where it can be processed and analyzed. If you have some NLP capabilities, you can also potentially enrich the knowledge graph.
Let me know if you find some exciting use-cases or have developed an NLP pipeline that extracts additional information from the text.
As always, the code is available on GitHub.
Represent United Kingdom’s public record as a knowledge graph was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/H6uqKpS
via RiYo Analytics









No comments