https://ift.tt/byapRWx A beginner-friendly guide to thinking about model selection and hyperparameter tuning When starting a machine learn...
A beginner-friendly guide to thinking about model selection and hyperparameter tuning
When starting a machine learning project, it’s not always easy to know what model to select, especially if you’re new to the field. We’ll tackle a few common considerations you should take when starting a project in this post.
Select a Model with the Correct Prediction Type:
Selecting a machine learning model with the correct output type may sound obvious, but it’s an essential first step in the process. Classification and regression are two of the most popular supervised machine learning prediction types.
Classification
Classification models predict what category should be assigned to a piece of data. Some examples might be figuring out if a photo contains a specific animal or an email belongs in spam.
Regression
Regression models predict a continuous number, such as a quantity or price. A few examples would be predicting house values, an object’s weight, or a product’s sales quantity.

Bias & Variance Selecting & Tuning Models for Your Datasets:
Bias and variance refer to reasons machine learning models make prediction errors. In general, we want to have the lowest bias and variance possible, but in most cases, you can’t decrease one without increasing the other; this is called the bias-variance trade-off.
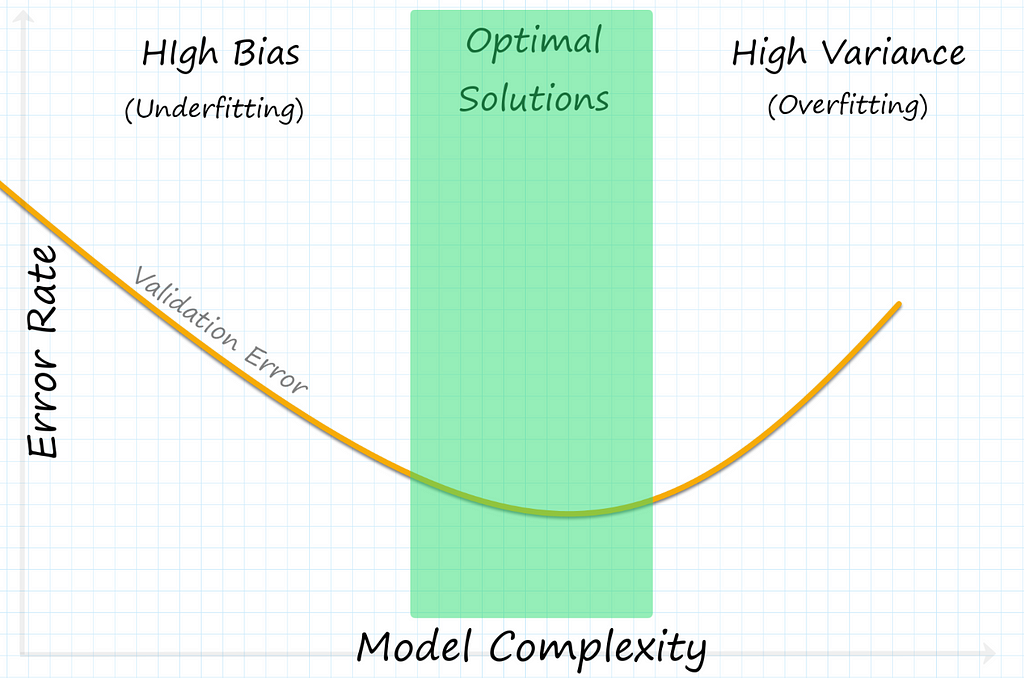
What is High Bias?
High bias, also known as underfitting, means the machine learning model did not learn enough from the dataset. Underfitting happens when a model is not complex enough.
What is High Variance?
High variance, also known as overfitting, means the model focuses too much on specific patterns in the training dataset and does not generalize well on unseen data. Overfitting can happen when models are too complex.
Tuning Models for Bias and Variance
Model hyperparameters adjust the way a model learns from the dataset. Once you select the correct model type for your project, you’ll want to tune the hyperparameters to find the optimal fit for the dataset; this is a significant factor in bias & variance.
For example, selecting a decision tree model with low depth might underfit (high bias). However, we can increase the tree depth hyperparameter to increase the complexity of the model, reducing the bias error.
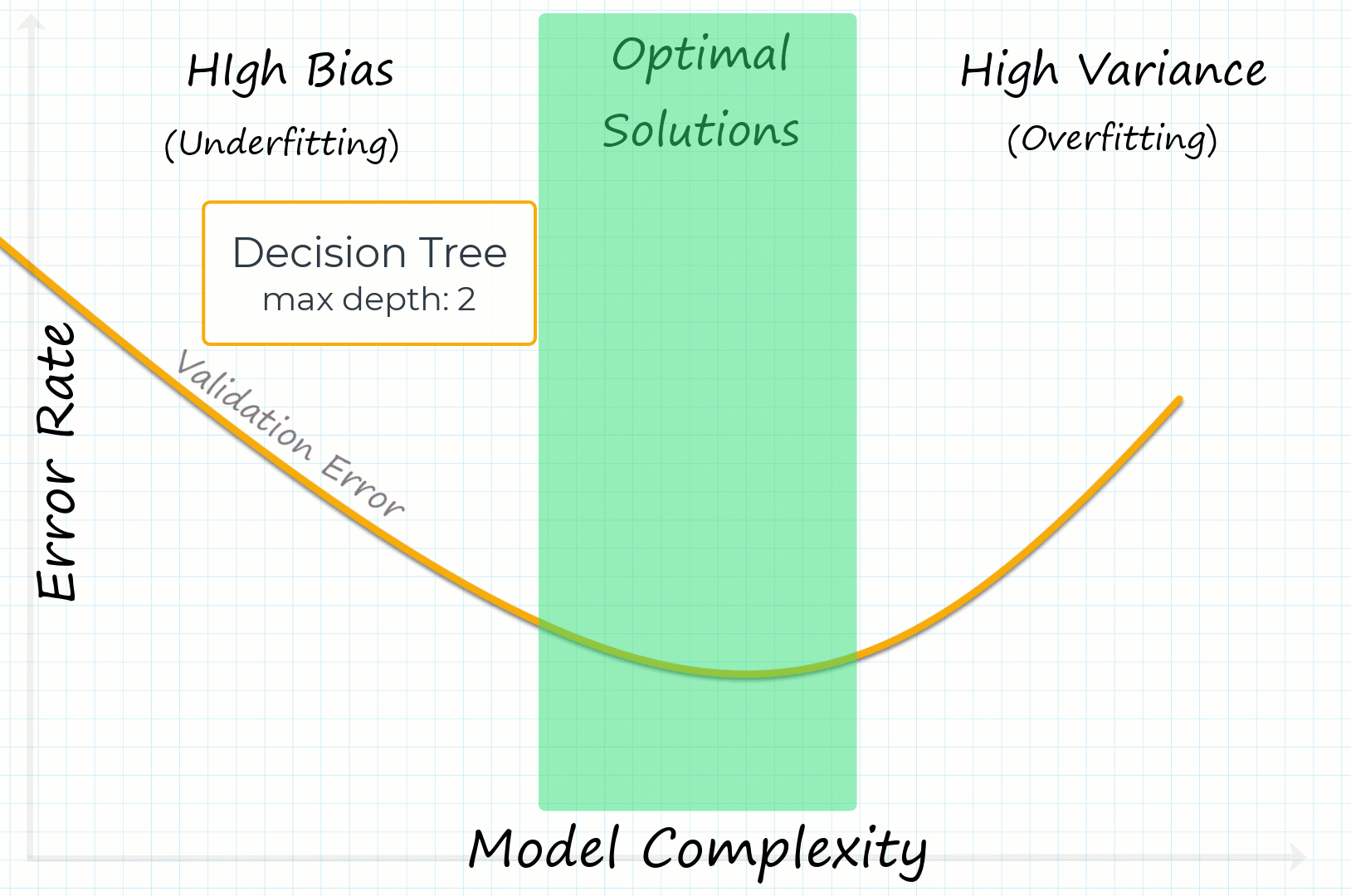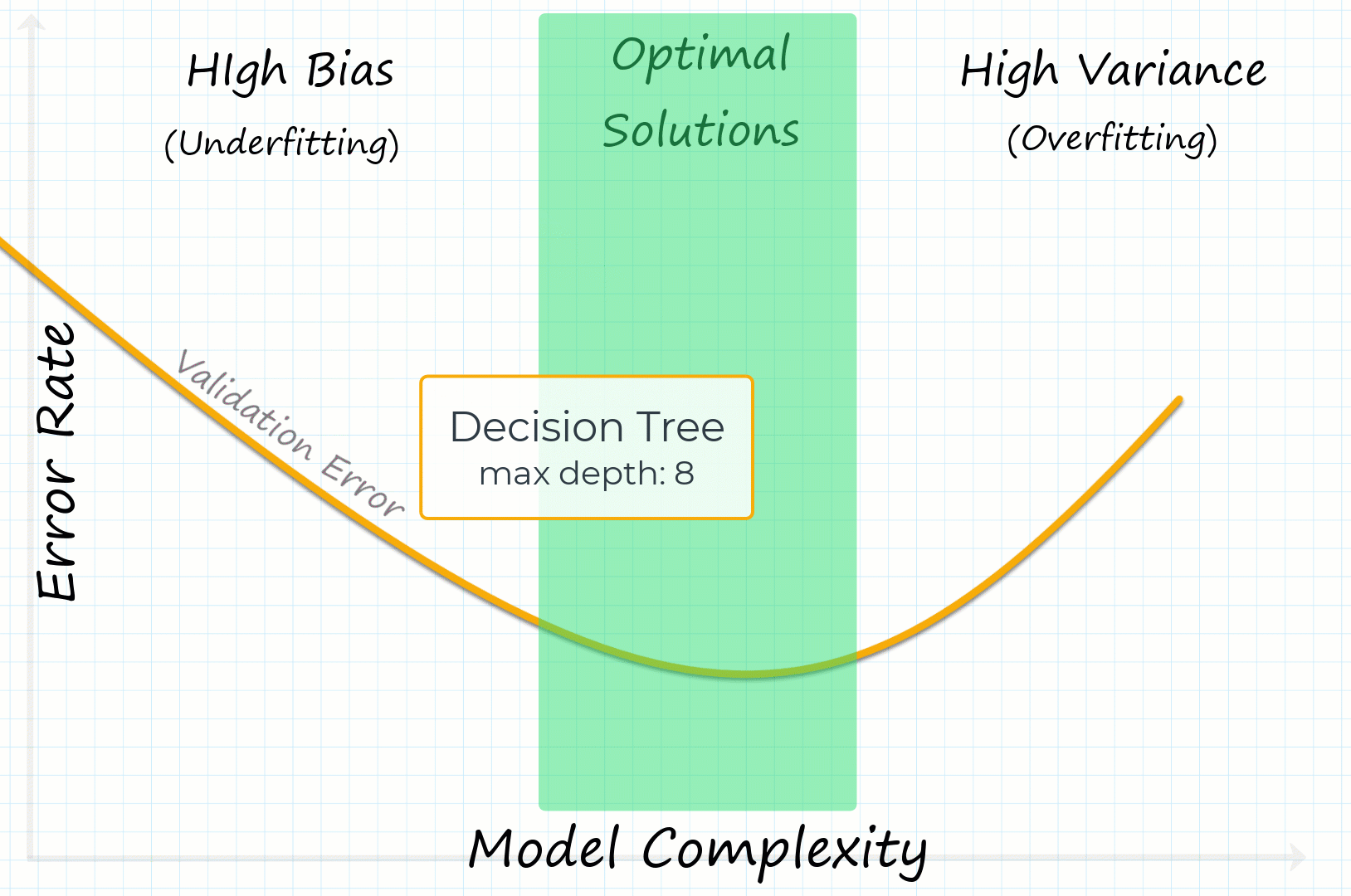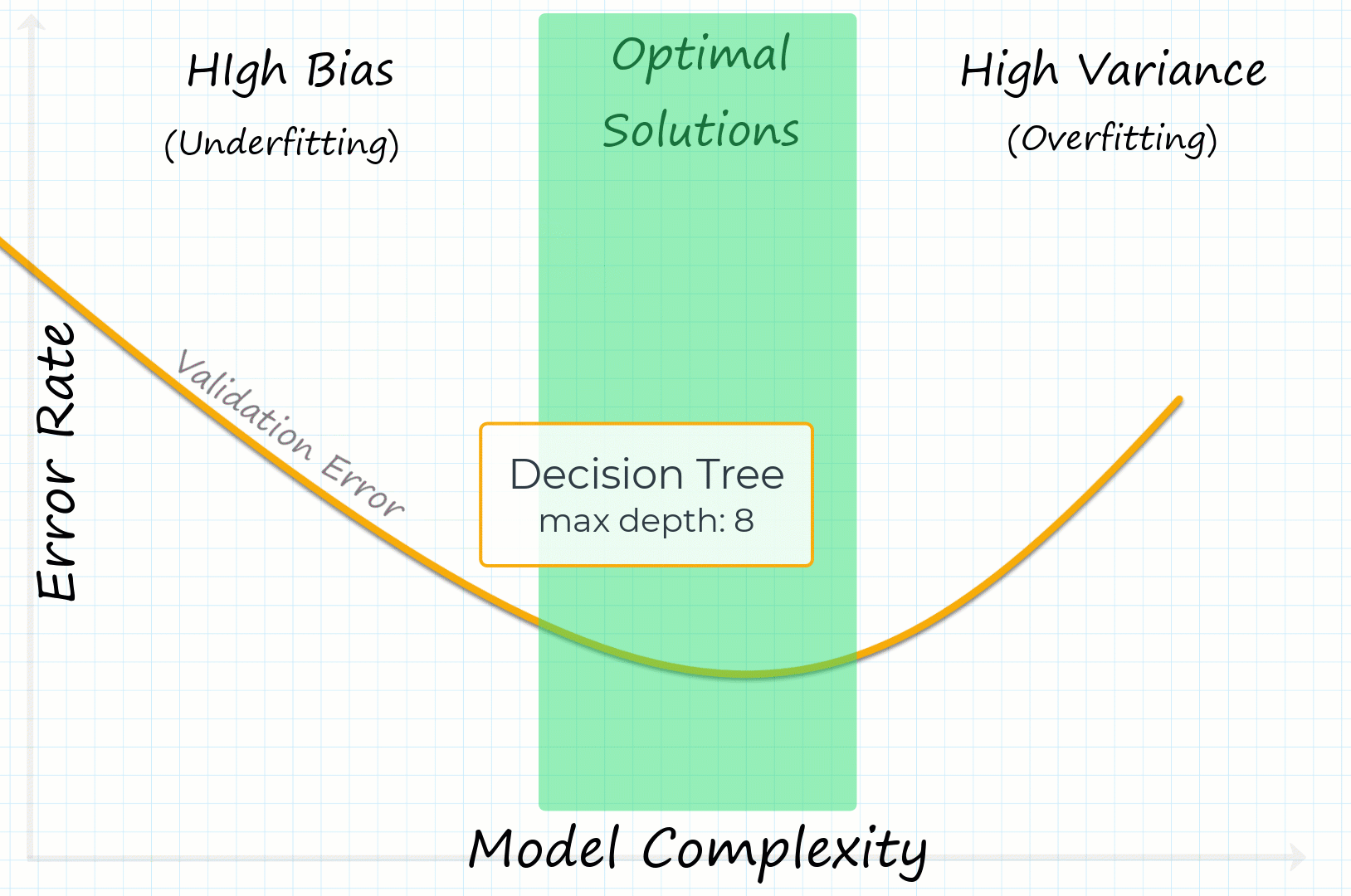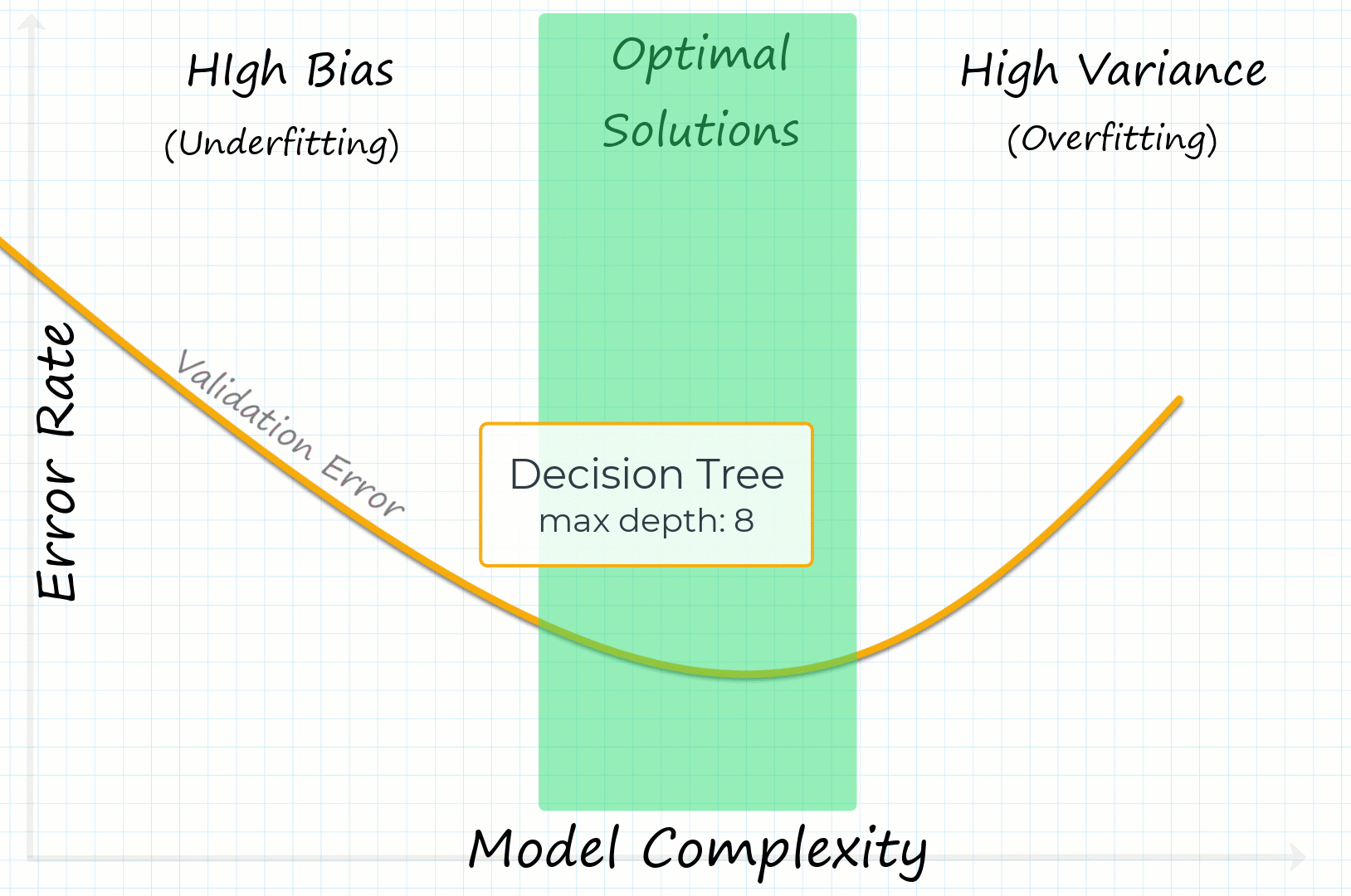
If the model still has a high bias after tuning, you may need to try a more complex model type. Such as switching from linear regression to polynomial regression.
Hands-on Decision Tree Code Example
Decision trees, also known as Classification And Regression Trees (CART), are among the most popular machine learning models for classification and regression problems.
Let’s take a quick look at how we might manually adjust the complexity of a classification tree by using an implementation in scikit-learn.
Note: Before tuning your model, you should also decide whether you want to optimize for precision or recall (this topic is outside the scope of this post).
If you run the code above you, we’ll get an accuracy of about 31% on our test dataset. Now try increasing the ‘max_depth’ hyperparameter to make the model predictions more accurate. What do you think a good depth to stop at is?
Open-source tools such as scikit-learn and Determined AI (for deep learning) have features that can automatically estimate the best hyperparameter values to save time and build better models.
Linear vs. Non-linear models
Linear models tend to have high bias, while non-linear models have high variance. If relatively simple lines can represent the data patterns, you might start with a linear model; otherwise, you will need a more complex model to obtain lower bias.
A Few Commonly Used Types of Linear Models:
- Logistic regression (used for binary classification)
- Linear regression (used for simple regression)
- Polynomial regression (used for regression)
A Few Commonly Used Types of Non-linear Models:
- Decision trees (used for classification & regression)
- K-nearest neighbors (used for classification & regression)
- Neural Networks (used for classification & regression)
We’ll look at implementing these in future posts!
Try Starting Simple to Establish a Baseline and Get a Quick Win!
Start with the simplest model you think may work when in doubt. Even though it may not get to the precision you want for the final project, you’ll have a baseline to compare to as you select and tune new models. Plus, it feels great to get a model already trained on your dataset!
Key Takeaways:
Selecting a model becomes easier as your experience grows, but if you’re new to machine learning, keep these steps in mind when starting your projects.
- Know what outcome you’re looking for from your model.
- If the model is underfitting, adjust the hyperparameters to add complexity or try a more complex model to fit the dataset better. If the model is overfitting, try the opposite to reduce complexity.
- Establish a baseline with any model and feel good about it!
Overcoming Bias & Variance in Machine Learning was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/KIvQHu3
via RiYo Analytics








No comments