https://ift.tt/mO2vQMP How I Built a Haiku Generator to Run on Blockchain In this post, I’ll describe my creation of Bitku, a haiku gener...
How I Built a Haiku Generator to Run on Blockchain
In this post, I’ll describe my creation of Bitku, a haiku generator that runs completely on the blockchain. I started with the goal of creating generative art that is truly blockchain-native — art that is generated and stored on-chain. I’ll describe the existing landscape of generative art NFTs and where it falls short. Then I’ll walk through the process of training and deploying the first¹ production machine learning model to run on a blockchain.

Existing Generative NFTs
There’s a growing trend of generative art NFTs — art that is created by an algorithm and “minted” to create a unique representation of that art on a blockchain so that ownership can be proven. There are several existing approaches to generative NFTs:
Art Blocks is one of the largest platforms for generative NFTs. The artists create a script (often using p5js) that can take a number and turn it into a piece of art. Each number will produce a different output. This script is saved as text on the Ethereum blockchain. When you mint an NFT on Art Blocks, the transaction stores a random seed at your Ethereum address. To view the art, your computer pulls the script off the blockchain, pulls your seed, and then your computer runs the script on that seed. All of the computation happens on the computers viewing the art; the blockchain is simply a ledger to keep track of the script and who owns which seeds.
Another approach is to generate art on demand, but by calling an API outside of the blockchain. This is known as an oracle. Oracles are often used for accessing outside data feeds, such as exchange rates for a finance application. But they can also be used for calling an API that generates text using GPT-3, or a pixel art tree that represents your blockchain carbon emissions. In this case, the art is generated by a black box and you don’t know how you got the result that you did. The result is also stored off-chain, so the blockchain provides you no guarantee of immutability.
And yet another is to simply generate art ahead of time. For example, using Processing to generate 100 random jpg images, and then minting those images as NFTs on OpenSea. These images would be stored outside of the blockchain using something like IPFS and the NFT on the blockchain would link to that image.
There are truly amazing artists producing stunning and novel pieces of art as NFTs. I have no criticism of the quality of the art. But from a technical perspective, I find these approaches unsatisfying because they all share one thing in common: They offload the computational complexity of generating art off of the blockchain and onto some other computer, whether it be your computer, an API in the cloud, or the artist’s computer. The NFTs are merely used as proof of ownership and are not integral to the art itself.
What isn’t done — for very good reasons that I’ll explain in a moment — is run generative code on the blockchain itself.
Given how bad of an idea it is, this is exactly what I set out to do.

The Idea
What I set out to do is create generative art that lives completely on the blockchain with zero outside dependencies. For as long as the blockchain exists, anyone should be able to know definitively what that piece of art is and how it was generated.
To satisfy the first requirement we need to store the art itself on the blockchain, and to satisfy the second we need to run the generation process on the blockchain.
Why This is a Bad Idea
Blockchains, by their nature, have time and space limitations. Blockchains work by duplicating computation and storage on many computers.
Taking Ethereum for example, there are thousands of full nodes across the world, each of which will execute the transaction, plus hundreds of thousands of miners, some of which will execute the transaction. Trying to run a complex process with lots of computation just isn’t feasible or environmentally responsible.
This cost is reflected in the gas requirements for executing transactions. The Ethereum yellow paper outlines the costs for different operations, such as computation, and storing or loading bytes. It would cost 640 million gas to store 1MB, which is roughly 64 ETH or $170,000 at today’s gas price and exchange rate. That’s just storage and doesn’t factor in the cost of computation.
With these constraints in mind, it was clear that it wouldn’t be feasible to store visual art on the blockchain. Haiku, which I’ve previously experimented with, seemed like the perfect fit: they’re text — and short text at that.
With a goal in mind, the next question was how to generate haiku on the blockchain. The project I linked to above uses a recurrent deep learning model which is 140MB on disk and computationally expensive to run.

Markov Chain Models
Enter Markov chains: They’re much less powerful than the state-of-the-art deep learning models — the text they generate is much less realistic. But they’re small and well understood.
Markov chains model a series of events in which the probability of the next event depends on the current state. In our case, that could mean that to generate the next word in a sentence we would consider the current word.
The graph below shows a Markov chain trained on the first sentence of The Mouse, the Bird, and the Sausage.
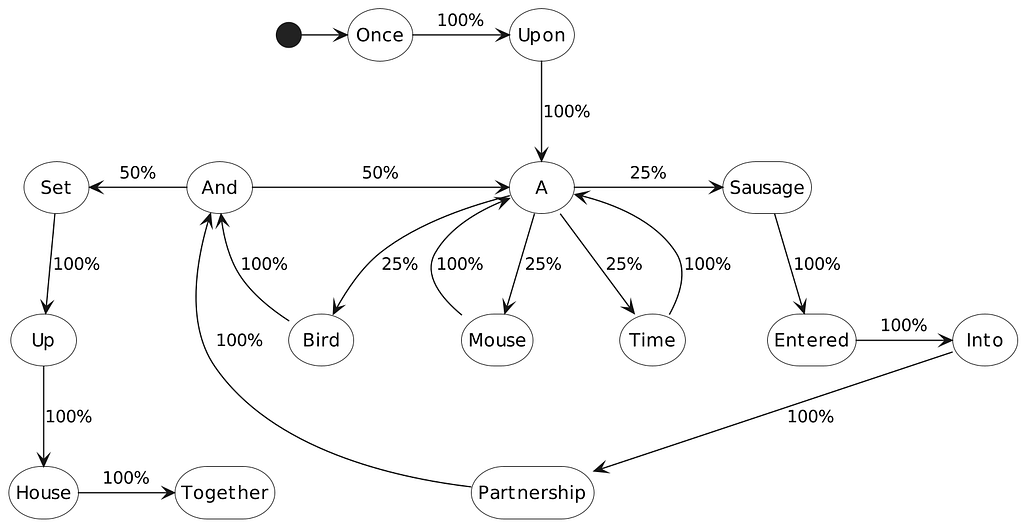
Each word is connected to other words by the probability of that word following the previous one. To generate text from this, if we started at “once,” 100% of the time we would choose the word “upon” and from there we would always choose “a.” At that point, we have several words that could follow. Each time we generate a sentence containing “a” we could end up with a different word after: “a bird” or “a sausage.”
These probabilities come from the training process. Training is done by processing a collection of text (known as a corpus) and noting each of the transitions between words.
In this case, “upon” always follows “once” so it has a 100% probability of following it in our model. While four words come after “a”, each an equal number of times, so they each have an equal 25% chance.
This gets much more complicated as the corpus grows, but the idea is the same: The frequency with which the word pair occurs in the corpus will give the model the probability of generating that pair.

Building a Blockchain Haiku Generator
At this point, I’d solidified my goals and requirements: Build a Markov model that can generate and store haiku on the blockchain. Time to build it!
The Flow Blockchain
My first step was to pick a blockchain to work with. While Ethereum is the obvious choice due to the popularity and maturity of the ecosystem, due to the constraints mentioned above it was clear I needed to look elsewhere. I focused my search on proof of stake (PoS) blockchains to minimize the environmental impact of the computation I’d need.
After considering a few options, I landed on Flow. Flow is a relative newcomer, best known for NBA Top Shot, but with a growing ecosystem of apps. Flow uses a PoS consensus algorithm that is divided across several different types of nodes. The result is that execution happens on a relatively small number of computers compared to most blockchains. It’s hard to estimate the computation/energy/carbon impact of running complex transactions on the Flow blockchain, as transactions are currently all charged a flat rate equivalent to less than a hundredth of a penny, but for sure it’s orders of magnitude lower than using a blockchain such as Ethereum.
What pushed me towards Flow over other PoS blockchains is its programming language, Cadence, and the developer ecosystem. Cadence has a simple and easy-to-understand interface for programming smart contracts, especially for someone new to smart contract programming, such as myself. There are good tutorials with an online playground for getting started and clear API reference docs. Flow and Cadence are still under active development, so I did encounter some places where documentation was out of date, and some parts of the developer ecosystem are still early — such as the JavaScript libraries — but overall I had a good experience developing on Flow.
Building a Haiku-Generating Markov Model
In the example above, the state of the Markov model was only the current word. When the current word is “upon” the next word will be “a.” From “a” there are four equal choices. One possible output from this model is:
once upon a sausage entered into partnership and a mouse a mouse a mouse…
It’s easy to see how we could generate nonsensical results. Picking a good next word requires much more context about the sentence. But the state doesn’t have to be just the current word. For this project I trained a Markov model in which the state consists of the current word, the previous word, and the line number. This is far from perfect, but is much improved over the current-word-only case while being simple enough to fit the constraints.
The training corpus came from several sources. There isn’t a lot of haiku training data, so much of this model was trained on other poetry or prose sentences that were restructured to have a haiku-like appearance. In all, I had several hundred megabytes of training data.
I processed each “haiku” to catalog the transitions from the state (line number, the current word, and the previous word) to the next word. After this step, I had about 6.5 million transitions.
The following example shows these transitions from the current word (the) to each word that followed “the” and how many times it happened.
the, world, 644
the, night, 474
…
the, sudden, 2
the, change, 1
With this, you can calculate the probabilities of going from one state to a word. If these four were the only four words that followed “the” in our corpus, “the world” happens 57.4% of the time, “the night” happens 42.3% of the time, and “the change” happens less than 0.1% of the time. This means that when I use this model to generate haiku, 57.4% of the time when the current word is “the” the next word generated will be “world” while it will be “change” only very rarely.
Creating a Markov model is as simple as calculating these probabilities for every transition in the training data. I created three distinct Markov models from this set of transitions:
- The first model uses the line number, the current word, and the previous word to generate the next word.
- The second model uses the line number and only the current word to generate the next word. This model is a fallback for when the current state doesn’t exist in the first model. For example, this is the case when we’re at the beginning of the haiku and we don’t have two words yet, or if an uncommon word pair is generated such as “the change.”
- The last model specifically models the ends of haiku. An issue that I’ve encountered before while generating haiku is that, because haiku are size-constrained (only a limited number of lines and syllables), you will often be left with an incomplete thought at the end of the poem. I address this by building a model of states that come at the end of haiku in the training data. If that state is encountered near the end of generating a poem, we’ll take that option and end the poem instead of trying to keep generating.
The full code for processing the training data and building the models can be found here.
Porting to Flow
With the models trained, I then had to make the models run on the Flow blockchain. This entailed taking my Python code and porting it to a Cadence smart contract. Cadence is a “resource-oriented” programming language that made it very easy to do all of the blockchainy parts safely and securely — minting NFTs, storing them in the correct account, and exchanging funds. But while Cadence is Turing complete, it’s much more constrained than a language like Python, which made porting the haiku generating code more of a challenge.
Shrinking my Model
But the biggest challenge was in finding a model representation supported by Cadence that was small enough to store on the blockchain. My practical limit was between 1–2MB for each of the three models, coming from Flow’s 4MB transaction size limit.
To go from hundreds of MB of training data and 6.5 million state transitions to just several MB, I did the following:
- Prune the dictionary of words to only the 1,000 most common words. The size of the final model grows exponentially as the number of words in the dictionary increases due to the myriad interconnections between the new word and the other words. I found 1,000 to be a good balance between the model size and the variety of generated haiku.
- Prune infrequent transitions between the remaining words. This too comes at the cost of reducing output variety. Taking the example from above: even though “the” and “change” are included in the 1,000-word dictionary, “the change” isn’t included as a state transition. This not only saves space, but it helps prevent grammatically-incorrect transitions. While “the change” could be correct when “change” is a noun as in “give me the change,” usually “change” is a verb. The model doesn’t know which part of speech a word was used as, so “change” will usually be interpreted as a verb and followed by words such as “my” and “your”.
- Compress the words into smaller representations. My compression scheme was to replace words with unique alphanumeric codes, giving the shortest codes to the most common words.
Getting to the exact number of words and threshold for infrequent transitions was an iterative process as I created models and tested them on Flow. Flow/Cadence is also very much still in its early stages, and new versions of the Cadence runtime forced me to adjust the size of my models several times.
Here is a snippet from the dictionary for reversing the compression:
{
"a":"END",
"b":"START",
"c":"\n",
"d":"the",
"e":"I",
"f":"to",
"g":"and",
"h":"a",
"i":"of",
…,
"pg":"walking",
"ph":"lonely",
"pi":"thousand"
}
“START” and “END” are the symbols I used to mark the beginning and end of the haiku. After that, “\n” (newline) is the most common, followed by “the” and “I.” “Thousand” is, coincidentally, the least frequent of the 1,000 words in the dictionary, and as you can see, can be compressed to just two characters (“pi”).
Here is what the model looks like:
{
"d":{
0:{"c":8,"aw":9,…,"i6":34,"d7":35},
1:{"c":7,"bB":8,…,"gm":46,"aj":47},
2:{"cP":1,"bG":2,…,"k9":51,"mc":52}
}
}
This is the model of words that follow the word “d”, which translates to “the.” There are three dictionaries within, one for each of the three lines of the haiku. For the first line, the most common word to follow “the” is “c” (“\n”), the second is “aw” (“only”) and the last is “d7” (“lord”). The maximum number is 35, so to generate a word following “the” on the first line of the haiku, pick a random number between 1 and 35 and select the first word whose value is less than or equal to that number. A 5 would translate to “\n” while a 9 would be “only.” Translated into percentages, for this specific case, it means that about 23% of the time a line break follows “the” while each other word has a 3% chance.
Porting the Generation Code to Cadence
With models sorted out and compatible with Cadence, the next step was to use them to generate haiku.
The basic idea is to take a random word from the model and then use that word to randomly pick the next one. During generation, if there are 5 or more syllables on the first line or 7 or more on the second line, then a line break is inserted as the next “word.” And on the last line if there are 4 or more syllables then we try to pull from the ending-specific model described above.
While I’ve been talking about picking “random” words, we actually want a pseudorandom word — something that appears random but behaves in a repeatable fashion. One of the benefits we get from building this on the blockchain is a clear provenance of the haiku. We can know not only the ownership history as we would with other NFTs, but also exactly how it was generated. Assuming we have the seed, we can always go back, trace the code, and understand what happened to produce any given haiku.
In this case, I seeded the pseudorandom number generator with the ID of the block and ID of the haiku (each haiku is tagged with a unique sequential ID). Because the block ID is included in the seed, you never know* what the haiku will be before you mint it.
* It might be possible to know which block your transaction will be included in ahead of time if you’re fast enough, but in practice it’s unpredictable.
The full code for the smart contracts, including the models and the generation code, can be found here.
Results
On to the fun part — the results. I’ve already included some of them throughout this article. Here are a few more of my favorites:



Yes, that last one is just two words. As I mentioned before, one of the great things about using blockchain is that you can figure out exactly what happened, given the random number seed. (I’ll leave that as an exercise to the reader; here is the transaction that produced haiku #221.)
You can read more about the project, as well as find all of the source code at: https://github.com/docmarionum1/bitku
If you want to read more about generating haiku, you can read about using deep learning, and about generating haiku from job descriptions.
Jeremy Neiman can be found doing equally pointless things on his website: http://jeremyneiman.com/
Thanks to Abigail Pope-Brooks for editing and feedback.
All images in this article were created by the author unless noted otherwise.
[1] Appendix: State of Machine Learning in the Blockchain
As far as I can tell, Bitku is the first implementation of machine learning running on a production blockchain.
I could find only one other instance of source code that implements machine learning in smart contracts: Microsoft Research’s Decentralized & Collaborative AI on Blockchain (also known as Sharing Updatable Models (SUM) on Blockchain).
This is an interesting project whose main focus is determining how to leverage blockchain to democratize training models and access to them for predictions. The gist is that they provide an incentive mechanism for providing data to models, implement ML models that are easy to update (such as a nearest centroid classifier) so that transaction costs are low, and then allow access to predictions for free because reading from blockchains is free.
The project was implemented on Ethereum and shown to work using a local emulator. I can’t find any indication that it was deployed to mainnet and it would be cost-prohibitive to use now. But I could see this approach working on a PoS blockchain.
Outside of that, I couldn’t find any implementations of ML on a blockchain.
- There is a paper that proposes a scheme for using blockchain to incentive creating effective models (think Kaggle but on blockchain) but it’s just theory as far as I can tell.
- There is research into blockchains specifically made to facilitate machine learning, such as the proposed LearningChain, but that’s a whole different beast — it uses blockchain to coordinate and secure distributed machine learning — it doesn’t run machine learning in a smart contract.
Machine Learning on the Blockchain was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/kvmqwYX
via RiYo Analytics







ليست هناك تعليقات