https://ift.tt/Od1Tirg6J How to use this fantastic library in your own training scripts PyTorch Image Models (timm) is a library for stat...
How to use this fantastic library in your own training scripts
PyTorch Image Models (timm) is a library for state-of-the-art image classification, containing a collection of image models, optimizers, schedulers, augmentations and much more; it was recently named the top trending library on papers-with-code of 2021!
Whilst there are an increasing number of low and no code solutions which make it easy to get started with applying Deep Learning to computer vision problems, in my current role as part of Microsoft CSE, we frequently engage with customers who wish to pursue custom solutions tailored to their specific problem; utilizing the latest and greatest innovations to exceed the performance level offered by these services. Due to the rate that new architectures and training techniques that are introduced into this rapidly moving field, whether you are a beginner or an expert , it can be difficult to keep up with the latest practices and make it challenging to know where to start when approaching new vision tasks with the intention of reproducing similar results to those presented in academic benchmarks.
Whether I’m training from scratch or finetuning existing models to new tasks, and looking to leverage pre-existing components to speed up my workflow, timm is one of my favourite libraries for computer vision in PyTorch. However, whilst timm contains reference training and validation scripts for reproducing ImageNet training results and has documentation covering the core components in the official documentation and the timmdocs project, due to the sheer number of features that the library provides it can be difficult to know where to get started when applying these in custom use-cases.
The purpose of this guide is to explore timm from a practitioner’s point of view, focusing on how to use some of the features and components included in timm in custom training scripts. The focus is not to explore how or why these concepts work, or how they are implemented in timm; for this, links to the original papers will be provided where appropriate, and I would recommend timmdocs to learn more about timm’s internals. Additionally, this article is by no means exhaustive, the areas selected are based upon my personal experience using this library.
All information here is based on timm==0.5.4 which was recently released at the time of writing.

Table of Contents
Whilst this article can be read in order, it may also be useful as a reference for a particular part of the library. For ease of navigation, a table of contents is presented below.
- Models
- Customizing models
- Feature Extraction
- Exporting to different formats - Data Augmentation
- RandAugment
- CutMix and MixUp - Datasets
- Loading datasets from TorchVision
- Loading datasets from TensorFlow Datasets
- Loading datasets from local folders
- The ImageDataset class - Optimizers
- Usage Example
- Lookahead - Schedulers
- Usage Example
- Adjusting learning rate schedules - Exponential Moving Average model
- Putting it all together!
Tl;dr: If you just want to see some working code that you can use directly, all of the code required to replicate this post is available as a GitHub gist here.
Models
One of the most popular features of timm is its large, and ever-growing collection of model architectures. Many of these models contain pretrained weights — either trained natively in PyTorch, or ported from other libraries such as Jax and TensorFlow — which can be easily downloaded and used.
We can list, and query, the collection available models as demonstrated below:

We can also use the pretrained argument to filter this selection to the models with pretrained weights:

This is still an impressive number! If you are experiencing a little option paralysis at this point, don’t despair! A helpful resource which can be used to explore some of the models available, and understand their performance, is this summary page by Papers with code, which contains benchmarks and links to the original papers for many of the models included in timm.
For simplicity, let’s stick with the familiar, tried and tested, ResNet model family here. We can list the different ResNet variants available by providing a wildcard string, which will be used as a filter based on the model names:
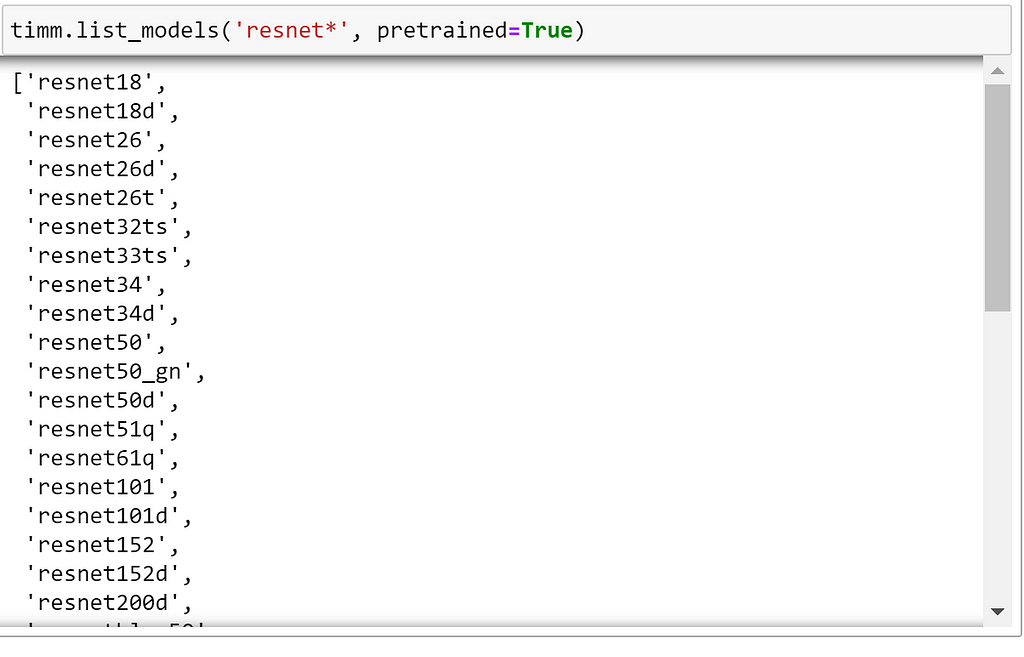
As we can see, there are still a lot of options! Now, let’s explore how we can create a model from this list.
General Usage
The easiest way to create a model is by using create_model; a factory function that can be used to create any model in the timm library.
Let’s demonstrate this by creating a Resnet-D model, as introduced in the Bag of Tricks for Image Classification For Convolutional Neural Networks paper; which is a modification on the ResNet architecture that utilises an average pooling tweak for down-sampling. This was largely an arbitrary choice, and the features that are demonstrated here should work on the majority of models included in timm.
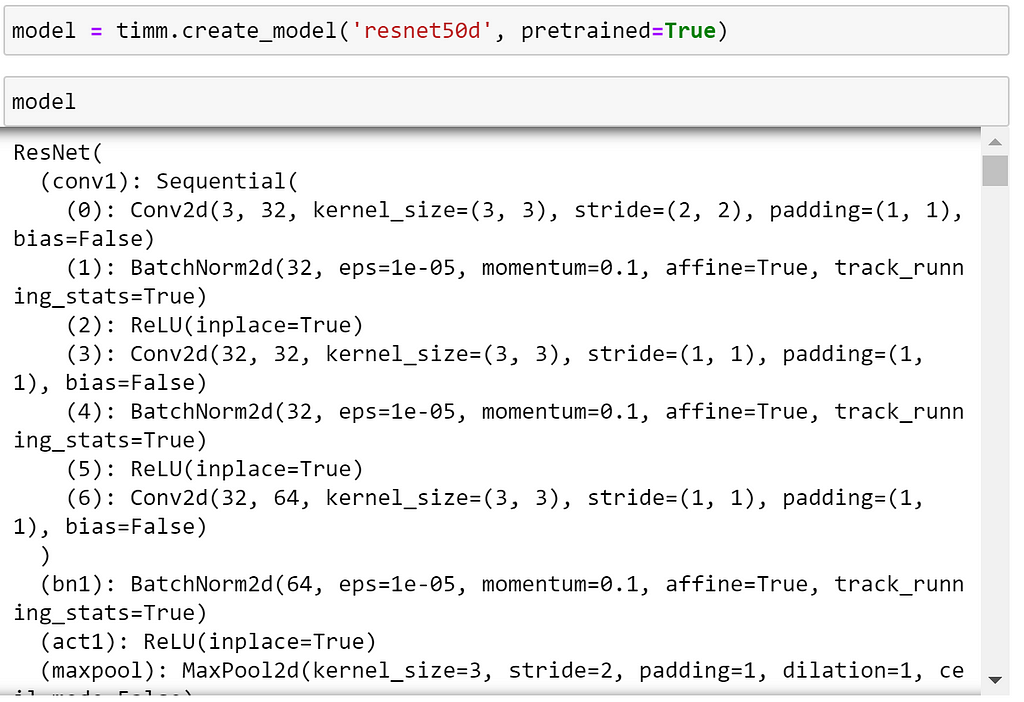
As we can see, this is just a regular PyTorch model.
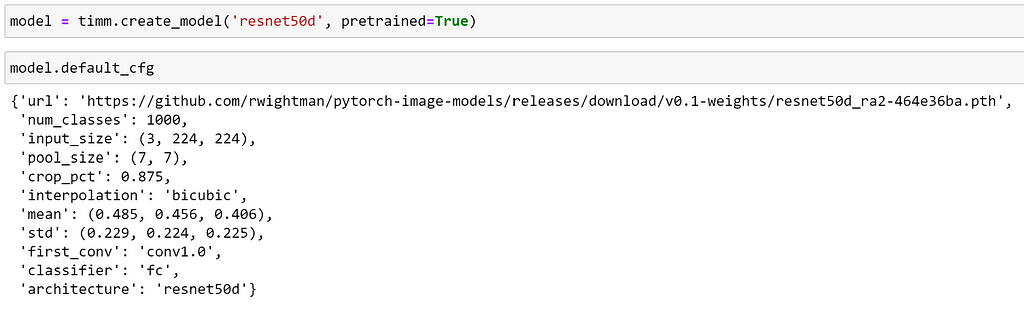
To help us understand more about how to use this model, we can access its config, which contains information such as the statistics that should be used to normalise the input data, the number of output classes and the name of the classification portion of the network.

Pretrained Models for images with varying numbers of input channels
One less well known, but incredibly useful, feature of timm models is that they are able to work on input images with varying numbers of channels, which pose a problem for most other libraries; an excellent explanation of how this works is described here. Intuitively, timm does this by summing the weights of the initial convolutional layer for channels fewer than 3, or intelligently replicating these weights to the desired number of channels otherwise.
We can specify the number of channels for our input images by passing the in_chans argument to create_model.

Using a random tensor to represent a single channel image in this case, we can see that the model has processed the image and returned the expected output shape.
It is important to note that, whilst this has enabled us to use a pretrained model, the input is significantly different to the images that the model was trained on. Because of this, we should not expect the same level of performance, and finetune the model on the new dataset before using on the task!
Customizing Models
In addition to creating models with stock architectures, create_modelalso supports a number of arguments enabling us to customise a model for our task.
The arguments that are supported can depend on the underlying model architecture, with some arguments such as:
- global_pool: determine the type of global pooling to be used before the final classification layers
being model specific. In this case, it is dependent on whether the architecture employs a global pooling layer. Therefore, whilst we will be fine using this with a ResNet-like model, it wouldn’t make sense to use it with ViT, which doesn’t use average pooling.
Whilst some arguments are model specific, arguments such as:
- drop_rate: set the dropout rate for training (Default: `0`)
- num_classes: the number of output neurons corresponding to classes
can be used for almost all models.
Before we explore some of the ways that we can do this, lets examine the default architecture of our current model.
Changing the number of classes
Examining the model config that we saw earlier, we can see that the name of the classification head for our network is fc. We can use this to access the corresponding module directly.

However, this name is likely to change depending on the model architecture used. To provide a consistent interface for different models, timm models have the get_classifier method, which we can use to retrieve the classification head without having to lookup the module name.

As expected, this returns the same linear layer as before.
As this model was pretrained on ImageNet, we can see that the final layer outputs 1000 classes. We can change this with the num_classes argument:

Inspecting the classifier, we can see that timm has replaced the final layer with a new, untrained, linear layer with the desired number of classes; ready to finetune on our dataset!
If we would like to avoid creating the last layer completely, we can set the number of classes equal to 0, which will create a model with the identity function as the final layer; this can be useful for inspecting the output of penultimate layer.

Global pooling options
From our model’s config, we can also see that the pool_size is set, informing us that a global pooling layer is used before the classifier. We can inspect this as follows:

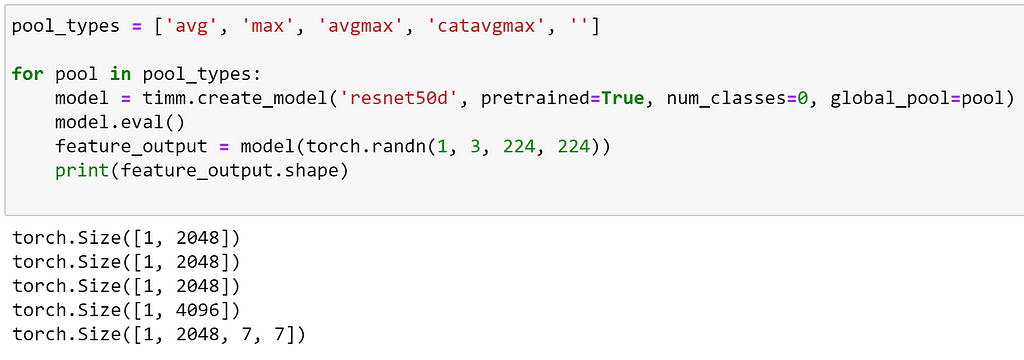
Here, we can see that this returns an instance of SelectAdaptivePool2d, which is a custom layer provided by timm, which supports different pooling and flattening configurations. At the time of writing, the supported pooling options are:
- avg : Average pooling
- max : Max pooling
- avgmax: the sum of average and max pooling, re-scaled by 0.5
- catavgmax: a concatenation of the outputs of average and max pooling along feature dimension. Note that this will double the feature dimension.
- ‘’ : No pooling is used, the pooling layer is replaced by an Identity operation
We can visualise the output shapes of the different pooling options as demonstrated below:
Modifying an existing model
We can also modify the classifier and pooling layers of an existing model, using the reset_classifier method:

Creating a new classification head
Whilst it has been demonstrated that using a single linear layer as our classifier is sufficient to achieve good results, when finetuning models on downstream tasks, I’ve often found that using a slightly larger head can lead to increased performance. Let’s explore how we can modify our ResNet model further.
First, let’s create our ResNet model as before, specifying that we would like 10 classes. As we are using a larger head, let’s use catavgmax for our pooling, so that we provide more information as input to our classifier.

From the existing classifier, we can get the number of input features:

Now, we can replace the final layer with our modified classification head by accessing the classifier directly. Here, the classification head has been chosen somewhat arbitrarily.

Testing the model with a dummy input, we get an output of the expected shape. Now, our modified model is ready to train!

Feature Extraction
timm models also have consistent mechanisms for obtaining various types of intermediate features, which can be useful in order to use an architecture as a feature extractor for a downstream task; such as creating feature pyramids in object detection.
Let’s visualise how this works by using an image from the Oxford pets dataset.

We can convert this into a tensor, and transpose the channels into the format that PyTorch expects:

Once again, let’s create our ResNet-D model:
If we are only interested in the final feature map — that is the output of the final convolutional layer prior to pooling in this case — we can use the forward_features method to bypass the global pooling and classification layers.

We can visualise this below:
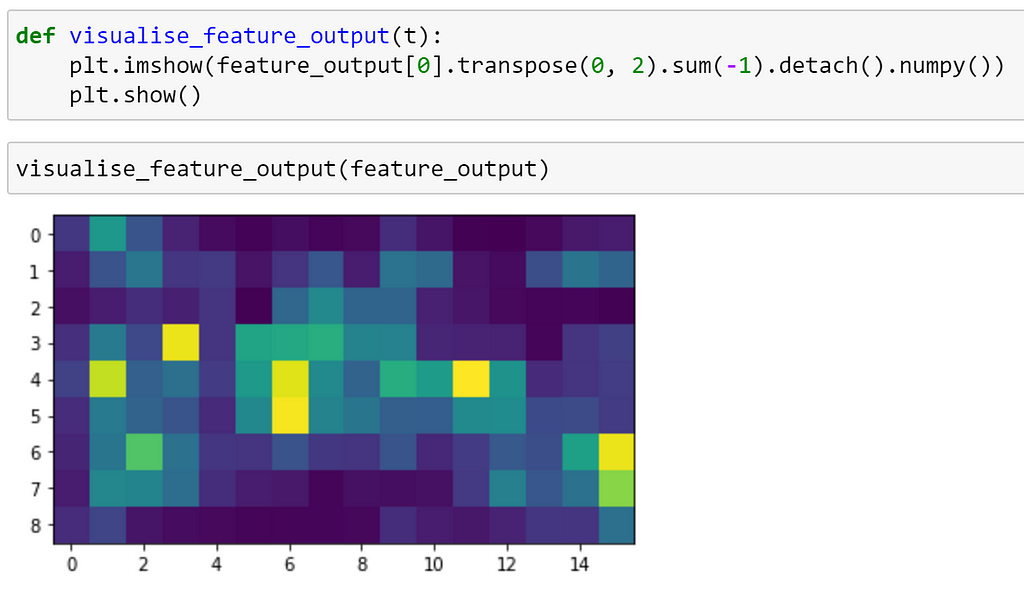
Multiple feature outputs
Whilst the forward features method can be convenient for retrieving the final feature map, timm also provides functionality which enables us to use models as feature backbones that output feature maps for selected levels.
We can specify that we would like to use a model as a feature backbone by using the argument features_only=True when creating a model. By default, 5 strides will be output from most models (not all have that many), with the first starting at 2 (but some start at 1 or 4).
The indices of the feature levels, and number of strides can be modified using the `out_indices` and `output_stride` arguments, as demonstrated in the docs.
Let’s see how this works with our ResNet-D model.

As demonstrated below, we can get more information about the features that are returned, such as the specific module names, the reduction in features and the number of channels:

Now, lets pass an image through our feature extractor and explore the output.
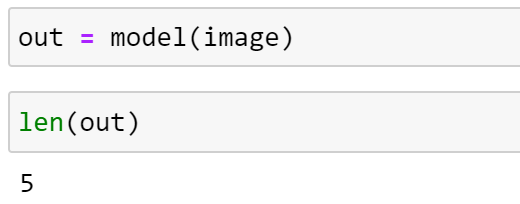
As expected, 5 feature maps have been returned. Inspecting the shape, we can see that the number of channels is consistent with what we expect:

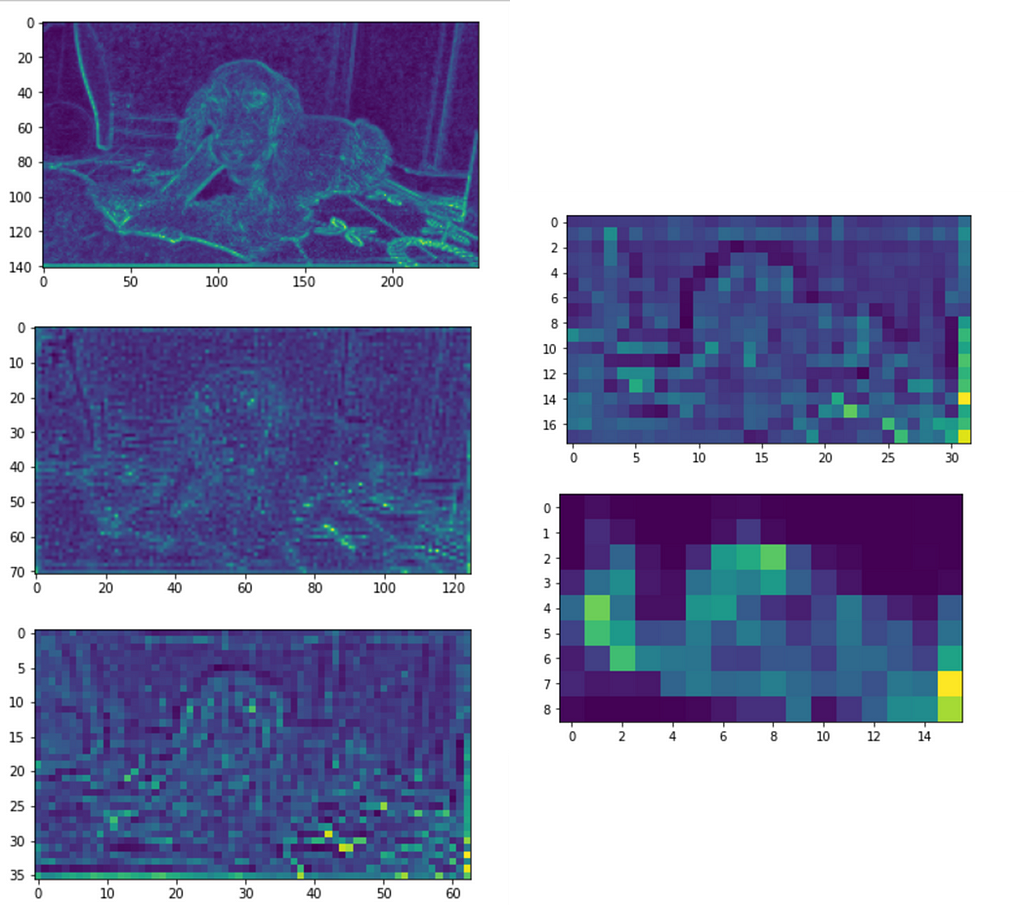
Visualising each feature map, we can see that the image is gradually down-sampled, as we would expect.

Using Torch FX
TorchVision recently released a new utility called FX, which makes it easier to access intermediate transformations of an input during the forward pass of a PyTorch Module. This is done by symbolically tracing the forward method to produce a graph where each node represents a single operation. As nodes are given human-readable names, it is easy specify exactly which nodes we want to access. FX is described in more detail in the docs and in this blog post.
Note: At the time of writing, dynamic control flow can’t yet be represented in terms of a static graph when using FX.
As almost all models in timm are symbolically traceable, we can use FX to manipulate these. Let’s explore how we can use FX to extract features from timm models.
First, let’s import some helper methods from TorchVision:

Now, we recreate our ResNet-D model, with a classification head, and use the exportable argument to ensure that the model is traceable.

Now, we can use the get_graph_nodes method to return the node names in order of execution. As the model is traced twice, in train and eval modes, both sets of node names are returned.
Using FX, can use easily access the output from any node. Let’s select the second activation in layer1.

Using create_feature_extractor, we can ‘cut’ the model at that point, as we can see below:
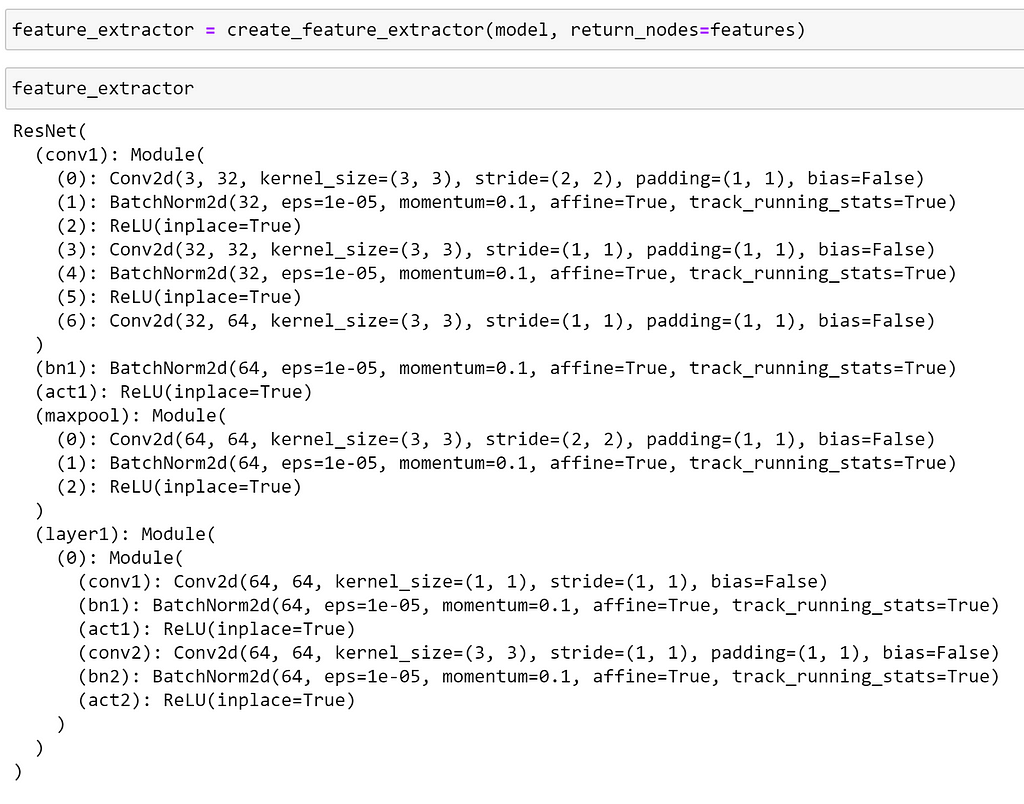
Now, passing an image through our feature extractor this will return a dict of Tensors. We can then visualise this as before:
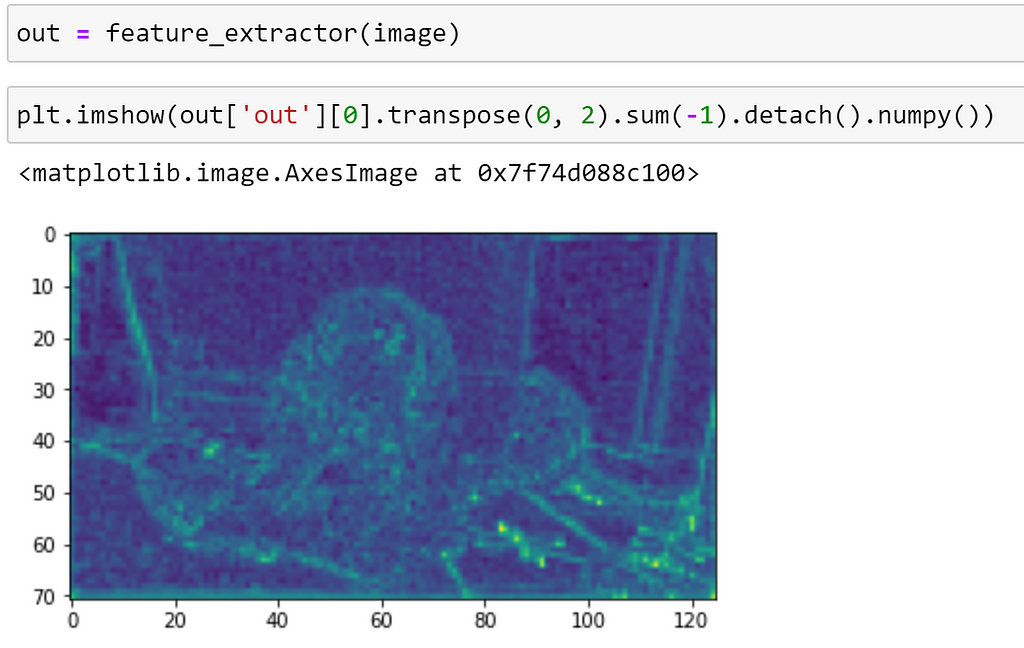
Exporting to different formats
After training, it is often recommended to export your models to an optimized format for inference; PyTorch has multiple options for doing this. As almost all timm models are scriptable and traceable, we can make use of these formats.
Let’s examine some of the options available.
Exporting to TorchScript
TorchScript is a way to create serializable and optimizable models from PyTorch code; any TorchScript program can be saved from a Python process and loaded in a process where there is no Python dependency.
We can convert a model to TorchScript in two different ways:
- Tracing: runs the code, records the operations that happen and constructs a ScriptModule containing those operations. Control flow, or dynamic behaviour such as if/else statements are erased.
- Scripting: uses a script compiler to perform a direct analysis of your Python source code to transform it into TorchScript. This preserves dynamic control flow and is valid for inputs of different sizes.
More about TorchScript can be seen in the docs and in this tutorial.
As most timm models are scriptable, let’s use scripting to export our ResNet-D model. We can set layer config so that model is jit scriptable using the scriptable argument when creating our model.

It is important to call model.eval() before exporting the model, to put the model into inference mode, as operators such as dropout and batchnorm behave differently depending on the mode.
We can now verify that we are able to script and use our model.
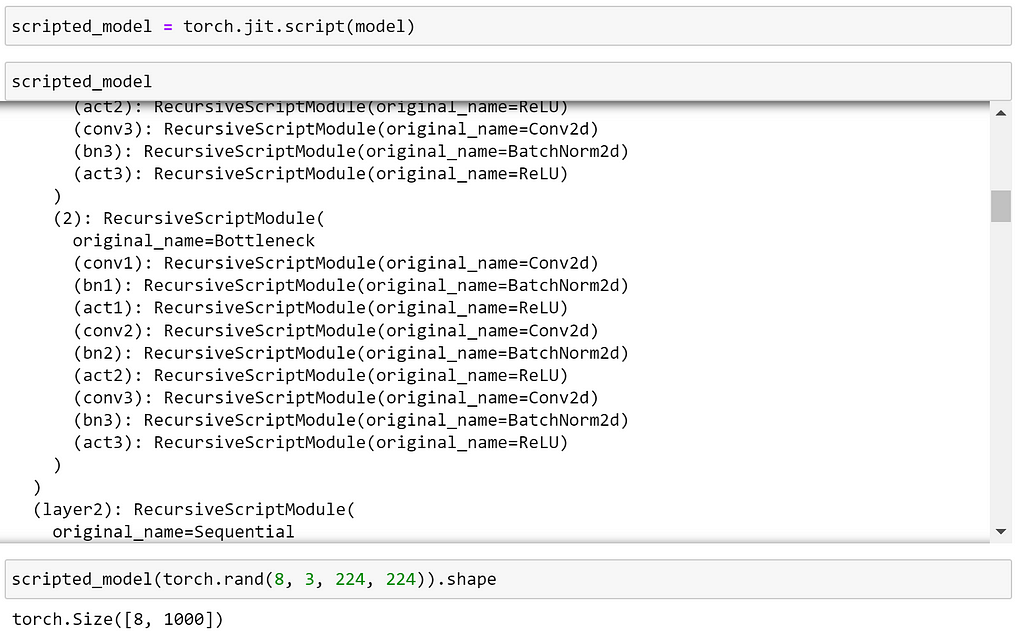
Exporting to ONNX
Open Neural Network eXchange (ONNX) is an open standard format for representing machine learning models.
We can use the torch.onnx module to export timm models to ONNX; enabling them to be consumed by any of the many runtimes that support ONNX. If torch.onnx.export() is called with a Module that is not already a ScriptModule, it first does the equivalent of torch.jit.trace(); which executes the model once with the given args and records all operations that happen during that execution. This means that if the model is dynamic, e.g., changes behaviour depending on input data, the exported model will not capture this dynamic behaviour. Similarly, a trace is likely to be valid only for a specific input size.
More details on ONNX can be found in the docs.
To enable exporting a timm model in ONNX format, we can use the exportable argument when creating the model, to ensure that the model is traceable.

We can now use torch.onnx.export to trace and export our model:

We can now verify that our model is valid using the check_model function.

As we specified that our model should be traceable, we could also have performed the tracing manually as demonstrated below.
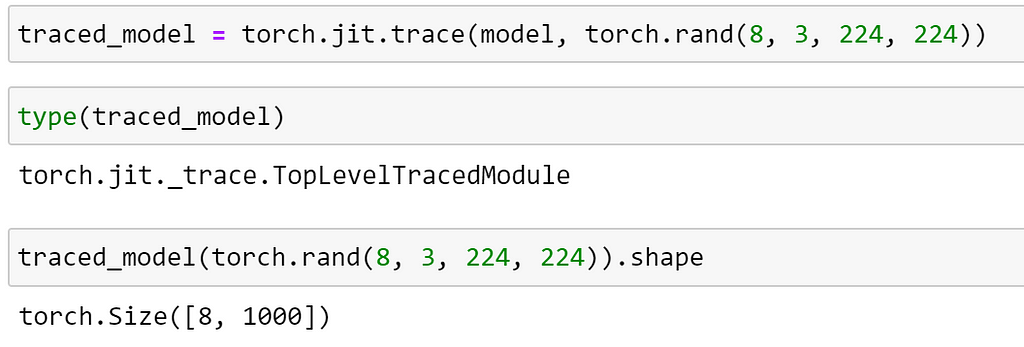
Data Augmentation
timm includes lots of data augmentation transforms, which can be chained together to make augmentation pipelines; similarly to TorchVision, these pipelines expect a PIL image as an input.
The easiest way to get started is by using the create_transform factory function, let’s explore how we can use this below.
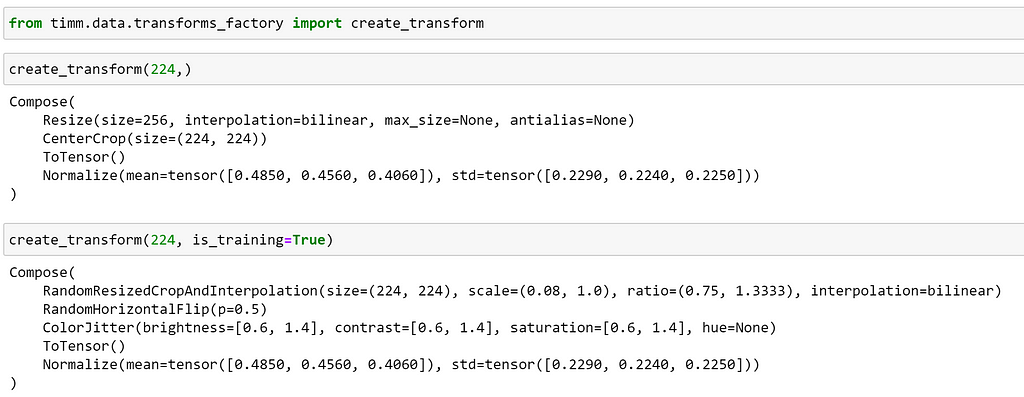
Here, we can see that this has created some basic augmentation pipeline including resizing, normalization and converting an image to a tensor. As we would expect, we can see that additional transformations, such as horizontal flipping and colour jitter, are included when we set is_training=True. The magnitude of these augmentations can be controlled with arguments such as hflip, vflip and color_jitter.
We can also see that the method used to resize the image also varies depending on whether we are training. Whilst a standard Resize and CenterCrop are used during validation, during training, RandomResizedCropAndInterpolation is used, let’s see what it does below. As the implementation of this transform in timm enables us to set different methods of image interpolation; here we are selecting that the interpolation is selected at random.

Running the transformation several times, we can observe that different crops have been taken of the image. Whilst this is beneficial during training, this may make the task harder during evaluation.
Depending on the type of image, this type of transform may result in the subject of the picture being cropped out of the image; we can see an example of this if we look at the second image in the first row! Whilst this shouldn’t be a huge problem if it occurs infrequently, we can avoid this by adjusting the scale parameter:

RandAugment
When starting a new task, it can be difficult to know which augmentations to use, and in which order; with the amount of augmentations now available, the number of combinations is huge!
Often, a good place to start is by using an augmentation pipeline which has demonstrated good performance on other tasks. One such policy is RandAugment, an automated data augmentation method that uniformly samples operations from a set of augmentations — such as equalization, rotation, solarization, color jittering, posterizing, changing contrast, changing brightness, changing sharpness, shearing, and translations — and applies a number of these sequentially; for more info, see the original paper.
However, there are several key differences in the implementation provided in timm, which are best described by timm’s creator Ross Wightman in the appendix of the ResNets Strike Back paper, which I paraphrase below:
The original RandAugment specification has two hyper-parameters, M and N; where M is the distortion magnitude and N is the number of distortions uniformly sampled and applied per-image. The goal of RandAugment was that both M and N be human interpretable.
However, that ended up not being the case for M [in the original implementation]. The scales of several augmentations were backwards or not monotonically increasing over the range such that increasing M does not increase the strength of all augmentations.
In the original implementation, whilst some augmentations go up in strength as M increases, others decrease or are removed entirely, such that each M essentially represents its own policy.
The implementation in timm attempts to improve this situation by adding an ‘increasing’ mode [enabled by default] where all augmentation strengths increase with magnitude.
This makes increasing M more intuitive, as all augmentations should now decrease/increase in strength with corresponding decrease/increase in M.
[Additionally,] timm adds a MSTD parameter, which adds gaussian noise with the specified standard deviation to the M value per distortion application. If MSTD is set to ‘-inf’, M is uniformly sampled from 0-M for each distortion.
Care was taken in timm’s RandAugment to reduce impact on image mean, the normalization parameters can be passed as a parameter such that all augmentations that may introduce border pixels can use the specified mean instead of defaulting to 0 or a hard-coded tuple as in other implementations.
[Lastly,] Cutout is excluded by default to favour separate use of timm’s Random Erasing implementation* which has less
impact on mean and standard deviation of the augmented images.
*The implementation of Random Erasing in timm is explored in detail here.
Now that we understand what RandAugment is, let’s see how we can use it in an augmentation pipeline!
In timm, we define the parameters of our RandAugment policy by using a config string; which consists of multiple sections separated by dashes (-)
The first section defines the specific variant of rand augment (currently only rand is supported). The remaining sections, which can be placed in any order, are:
- m (integer): the magnitude of rand augment
- n (integer): the number of transform ops selected per image, this is optional with default set at 2
- mstd (float): the standard deviation of the magnitude noise applied
- mmax (integer): sets the upper bound for magnitude to something other than the default of 10
- w (integer): the probability weight index (index of a set of weights to influence choice of operation)
- inc (bool — {0, 1}): use augmentations that increase in severity with magnitude, this is optional with the default of 0
For example: - rand-m9-n3-mstd0.5: results in RandAugment with magnitude 9, 3 augmentations per image, mstd 0.5
- rand-mstd1-w0: results in mstd 1.0, weights 0, default magnitude m of 10, and 2 augmentations per image
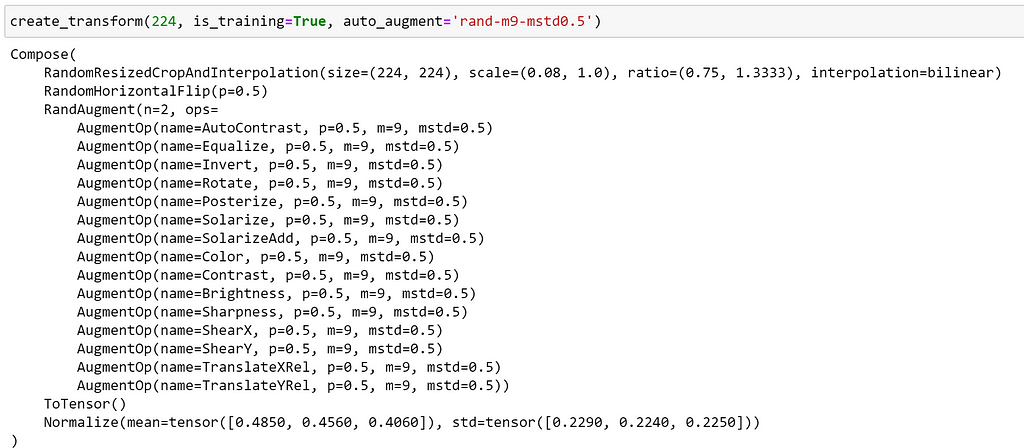
Passing a config string to create_transform, we can see that this is handled by the RandAugment object, and we can see the names of all available ops:
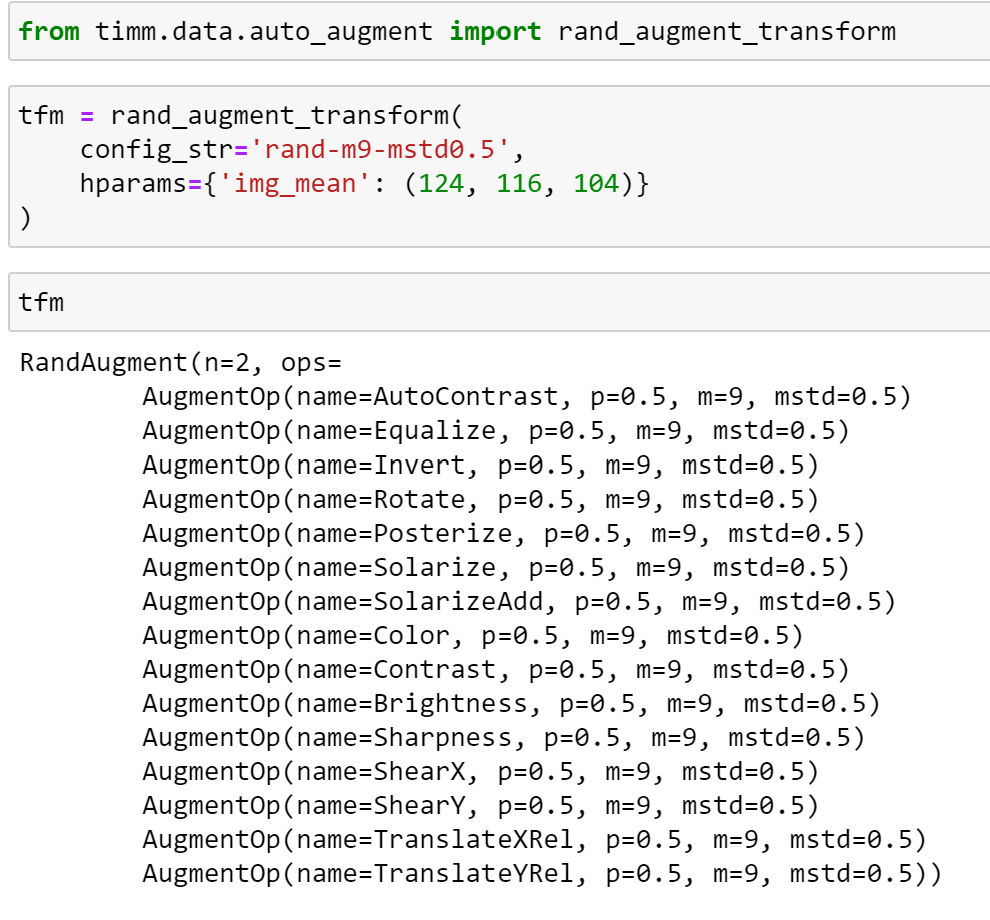
We can also create this object for use in a custom pipeline by using the rand_augment_transform function, as demonstrated below:
Let’s apply this policy to an image to visualise some of the transformations.

From this, we can see that using RandAugment has given us lots of variations of our image!
CutMix and Mixup
timm provides a flexible implementation of the CutMix and Mixup augmentations, using the Mixup class; which handles both augmentations and provides the option of switching between them.
Using Mixup, we can select from variety of different mixing strategies:
- batch: CutMix vs Mixup selection, lambda, and CutMix region sampling are performed per batch
- pair: mixing, lambda, and region sampling are performed on sampled pairs within a batch
- elem: mixing, lambda, and region sampling are performed per image within batch
- half: the same as elementwise but one of each mixing pair is discarded so that each sample is seen once per epoch
Let’s visualise how this works. To do this, we will need to create a DataLoader, iterate through it and apply the augmentations to the batch. Once again, we shall use images from the Pets dataset.
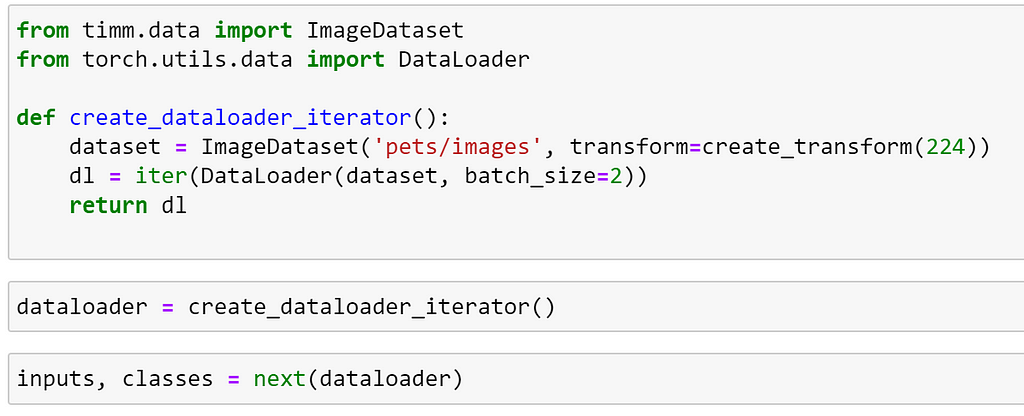
Using helper functions from TorchVision and timmdocs, we can visualise the images in our batch with no augmentation applied:

Now, let’s create our MixUp transform! Mixup supports the following arguments:
- mixup_alpha (float): mixup alpha value, mixup is active if > 0., (default: 1)
- cutmix_alpha (float): cutmix alpha value, cutmix is active if > 0. (default: 0)
- cutmix_minmax (List[float]): cutmix min/max image ratio, cutmix is active and uses this vs alpha if not None.
- prob (float): the probability of applying mixup or cutmix per batch or element (default: 1)
- switch_prob (float): the probability of switching to cutmix instead of mixup when both are active (default: 0.5)
- mode (str): how to apply mixup/cutmix params (default: batch)
- label_smoothing (float): the amount of label smoothing to apply to the mixed target tensor (default: 0.1)
- num_classes (int): the number of classes for the target variable
Let’s define a set of arguments so that we apply either mixup or cutmix to a batch of images, and alternate with the probability of 1, and use these to create our `Mixup` transformation:
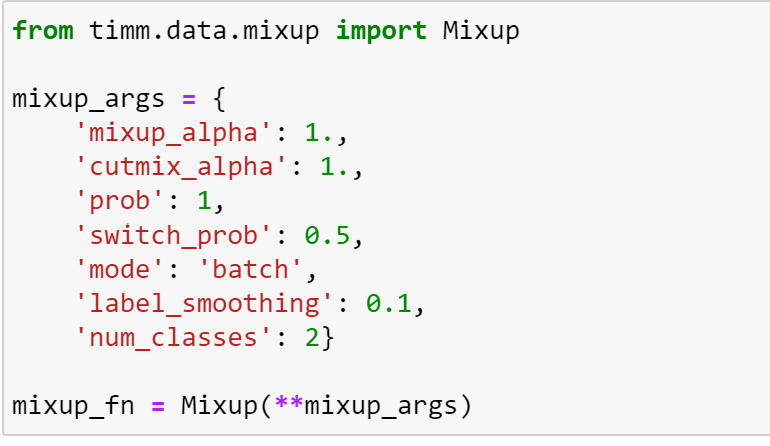
As mixup and cutmix take place on a batch of images, we can place the batch on the GPU before we apply the augmentation to speed things up! Here, we can see that mixup has been applied to this batch of images.


Running the augmentation again, we can see that, this time, CutMix has been applied.

From the labels printed above each other, we can observe that we can also use Mixup for label smoothing!
Datasets
timm provides a number of useful utilities for working with different types of datasets. The easiest way to get started is using the create_dataset function, which will create an appropriate dataset for us.
create_dataset always expects two arguments:
- name: the name of the dataset that we want to load
- root: the root folder of the dataset on the local file system
but has additional keyword arguments that can be used to specify options such as whether we would like to load the training or validation set.

We can also use create_dataset, to load data from several different places:
- datasets available in TorchVision
- datasets available in TensorFlow datasets
- datasets stored in local folders
Let’s explore some of these options.
Loading datasets from TorchVision
To load a dataset included with TorchVision, we simply specify the prefix torch/ before the name of the dataset that we wish to load. If the data doesn’t exist on the file system, we can download this data by setting download=True. Additionally, here we are specifying that we would like to load the training dataset with the split argument.
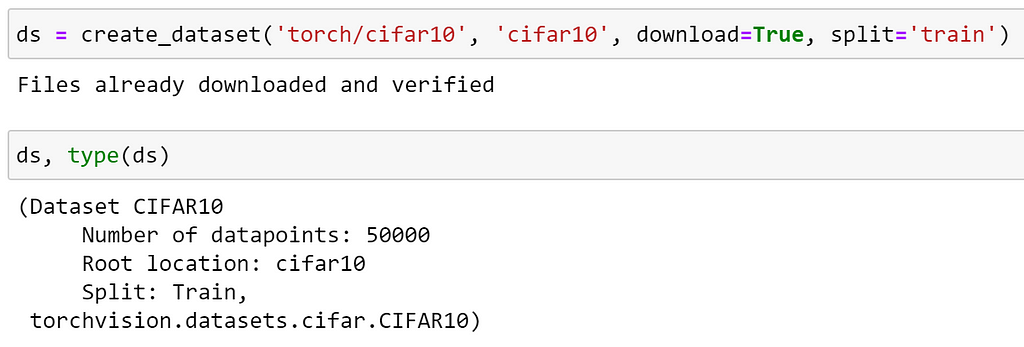
Inspecting the type, we can see that this is a TorchVision dataset. We can access this as usual with an index:

Loading datasets from TensorFlow Datasets
In addition to the datasets that are usually available when using PyTorch through TorchVision, timm also enables us to download and use datasets from TensorFlow datasets; wrapping the underlying tfds object for us.
When loading from TensorFlow datasets, it is recommended that we set a couple of additional arguments, which are not required for local or TorchVision datasets:
- batch_size : this is used to ensure that the batch size divides the total number of samples across all nodes during distributed training
- is_training: if set, the dataset will be shuffled. Note that this is different to setting split
Whilst this wrapper returns decompressed image examples from the TFDS dataset, any augmentations that we require, and batching, is still handled by PyTorch.
In this case, we prefix the name of the dataset with tfds/. A list of the available datasets for image classification can be found here. For this example, we shall arbitrarily select the beans dataset.

We can also see that, for the split argument, we have specified a tfds split string, as described here.
Inspecting our dataset, we can see that the underlying TensorFlow dataset has been wrapped in an IterableImageDataset object. As an iterable dataset, this does not support indexing — see the differences here — so in order to view an image from this dataset, we must first create an iterator.
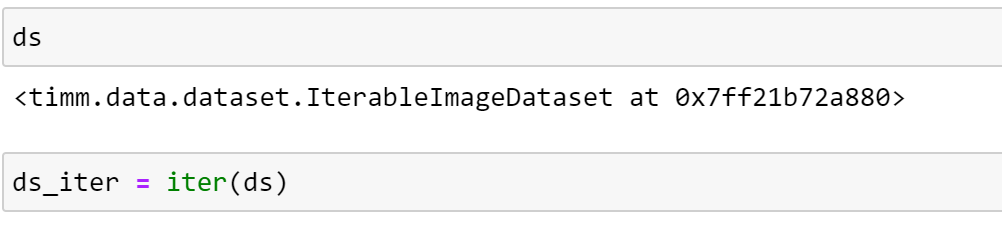
We can now use this iterator to examine our of images and labels sequentially, as we can see below.

We can see that our image has been loaded correctly!
Loading data from local folders
We can also load data from local folders, in these cases we simply use an empty string (`’’`) as the dataset name.
In addition to being able to load from ImageNet style folder hierarchies, create_dataset also lets us extract from one or more tar archives; we can use this to avoid having to untar the archive! As an example, we can try this out on the Imagenette dataset.
Additionally, so far we have been loading raw images, so let’s also use the transform argument to apply some transformations; here, we can quickly create some suitable transforms using the create_transform function that we saw earlier!
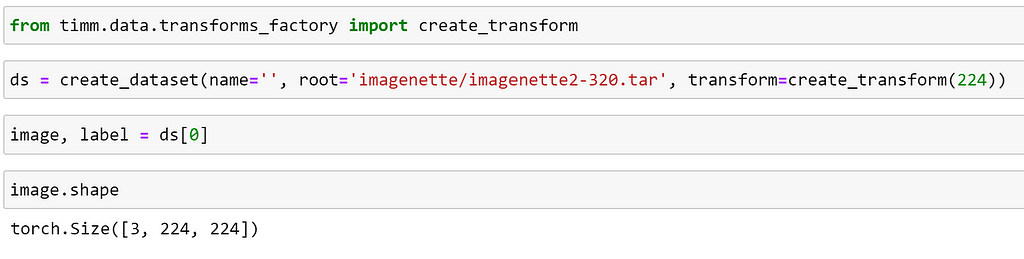
By inspecting the shame of the image, we can see that our transforms have been applied.
The ImageDataset class
As we have seen, the create_dataset function offers a lot of options for handling different types of data. The reason that timm is able to offer such flexibility is by using the existing dataset classes provided in TorchVision where possible, as well as providing some additional implementations — ImageDataset and IterableImageDataset which can be used in a wide range of scenarios.
Essentially, create_dataset simplifies this process for us by selecting an appropriate class, but sometimes we may wish to work directly with the underlying components.
The implementation that I use the most often is ImageDataset, which is similar to torchvision.datasets.ImageFolder, but with some additional functionality. Let’s explore how we can use this to load our decompressed imagenette dataset.
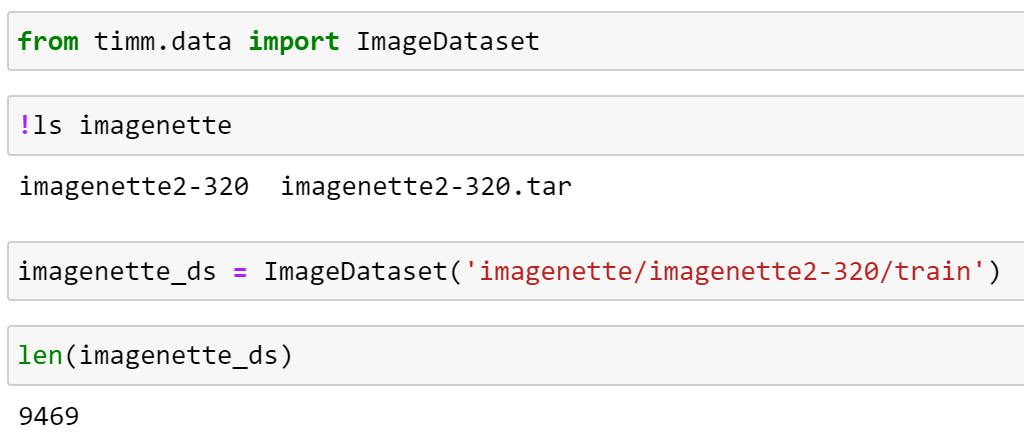
The key to ImageDataset’s flexibility is that the way it indexes and loads samples is abstracted into a Parser object.
Several parser are included with timm, including parsers to read images from folders, tar files and TensorFlow datasets. The parser can be passed to the dataset as an argument, and we can access the parser directly.

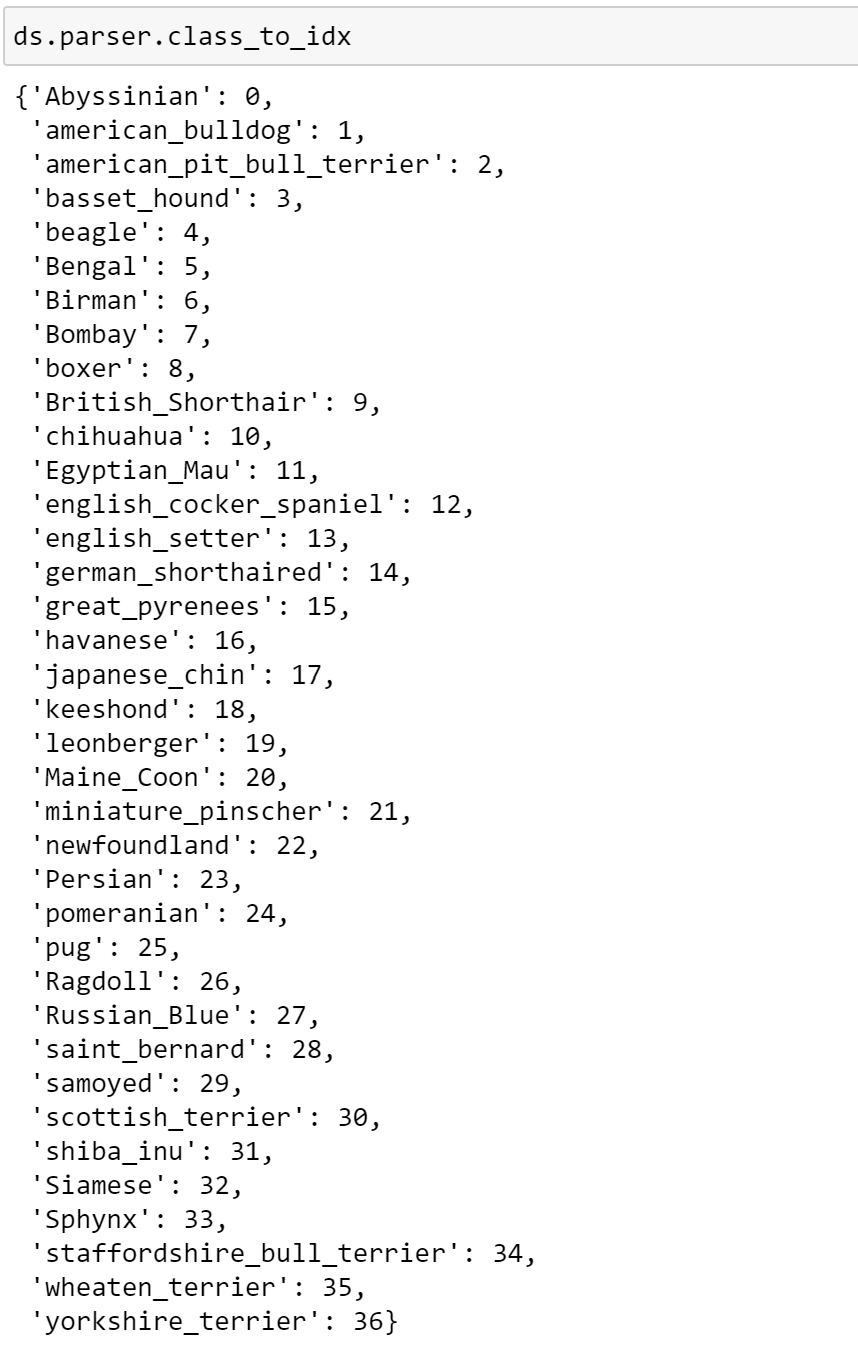
Here, we can see that the default parser is an instance of ParserImageFolder. Parsers also contain useful information such as the class lookup, which we can access as seen below.
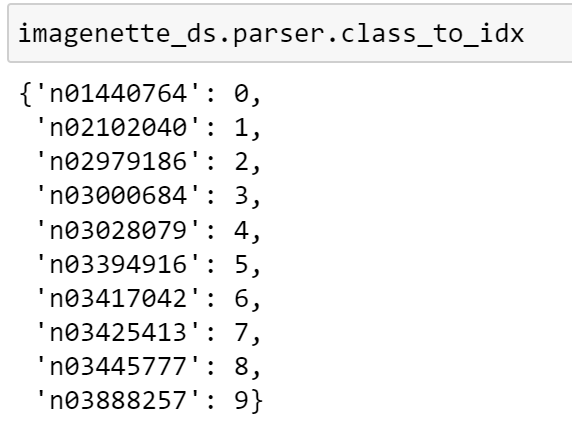
We can see that this parser has converted the raw labels into integers, which can be fed to our model.
Selecting a parser manually — tar example
Therefore, in addition to selecting an appropriate class, create_dataset is also responsible for selecting the correct parser. Once again considering the compressed Imagenette dataset, we can achieve the same result by manually selecting the ParserImageInTarparser and overriding ImageDataset’s default parser.

Inspecting the first sample, we can verify that this has loaded correctly.

Creating a custom Parser
Unfortunately, datasets aren’t always structured like ImageNet; that is, having the following structure:
root/class_1/xx1.jpg
root/class_1/xx2.jpg
root/class_2/xx1.jpg
root/class_2/xx2.jpg
For these datasets, ImageDataset won’t work out of the box. Whilst we can always implement a custom Dataset to handle this, this may be challenging depending on how the data is stored. An alternative option is to write a custom parser to use with ImageDataset.
As an example, let’s consider the Oxford pets dataset, where all images are located in a single folder, and the class name — the name of each breed in this case — is contained in the filename.
In this case, as we are still loading images from a local file system, it is only a slight tweak to ParserImageFolder. Let’s take a look at how that is implemented for inspiration.
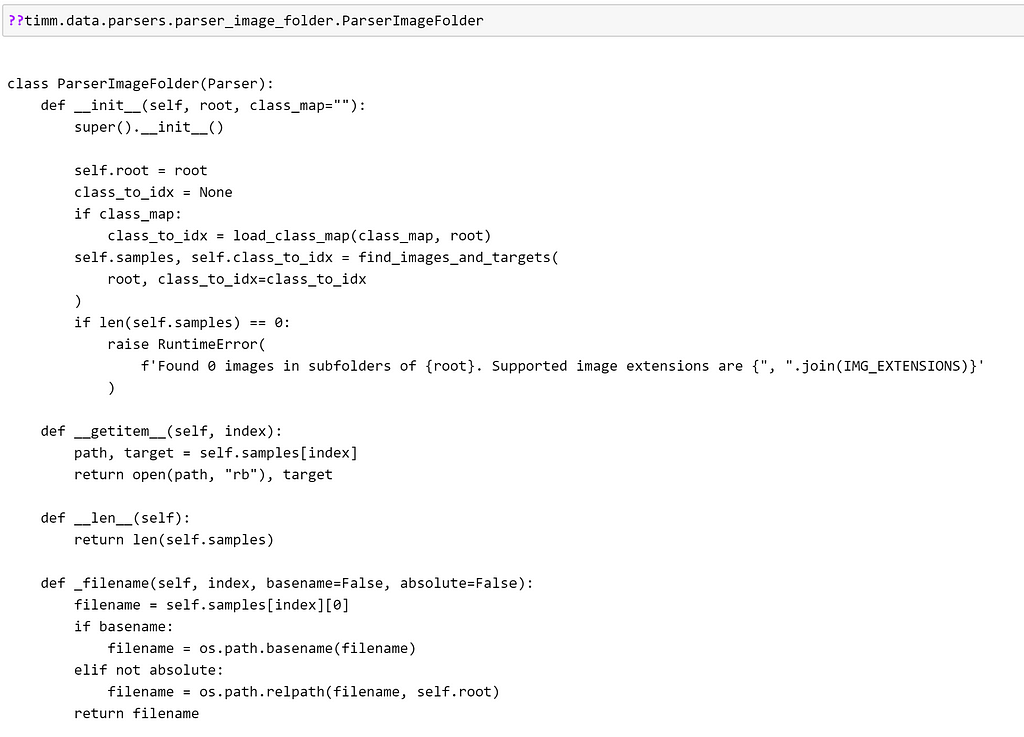
From this, we can see that `ParserImageFolder` does several things:
- creates a mapping for the classes
- implements __len__to return the number of samples
- implements _filename to return the filename of the sample, with options to determine whether it should be an absolute or relative path
- implements __getitem__ to return the sample and target.
Now that we understand the methods that we have to implement, we can create our own implementation based on this! Here, I have used pathlib, from the standard library, to extract the class name and handle our paths; as I find it easier to work with than os.
We can now pass an instance of our parser to ImageDataset, which should enable it to correctly load the pets dataset!

Let’s verify that our parser has worked by inspecting the first sample.

From this, it seems that our parser has worked! Additionally, as with the default parser, we can inspect the class mapping that has been performed.
In this simple example, it would be only slightly more effort to create a custom dataset implementation. However, hopefully this helps to illustrate how easy it is to write a custom parser and make it work with ImageDataset!
Optimizers
timm features a large number of optimizers, some of which are not available as part of PyTorch. As well as making it easy to access familiar optimizers such as SGD, Adam and AdamW, some noteworthy inclusions are:
- AdamP: described in this paper
- RMSPropTF: an implementation of RMSProp based on the original TensorFlow implementation, with other small tweaks discussed here. In my experience, this often results in more stable training than the PyTorch version
- LAMB: a pure pytorch variant of FusedLAMB optimizer from Apex, which is TPU compatible when using PyTorch XLA
- AdaBelief: described in this paper. Guidance on setting the hyperparameters is available here
- MADGRAD: described in this paper
- AdaHessian: an adaptive second order optimizer, described in this paper
The optimizers in timm support the same interface as those in torch.optim, and in most cases can simply be dropped in to a training script with no changes necessary.
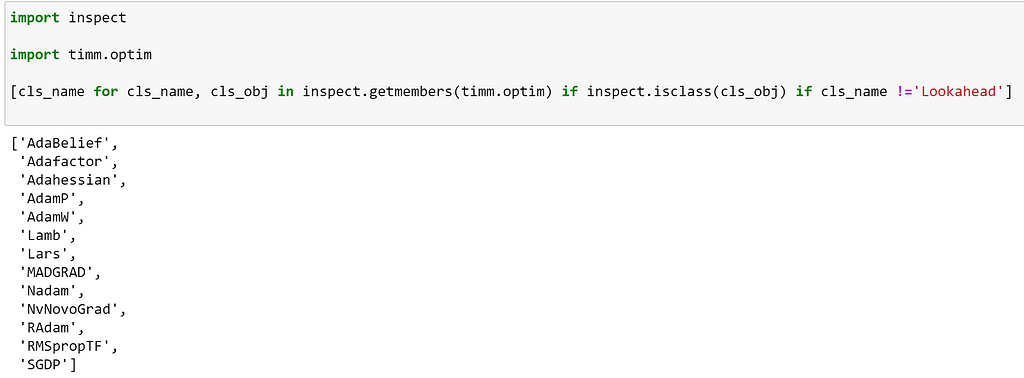
To see all of the optimizers that timm implements, we can inspect the timm.optim module.
The easiest way to create an optimizer is by using the create_optimizer_v2 factory function, which expects the following:
- a model, or set of parameters
- the name of the optimizer
- any arguments to pass to the optimizer
We can use this function to create any of the optimizer implementations included from timm, as well as popular optimizers from torch.optim and the fused optimizers from Apex (if installed).
Let’s take a look at some examples.
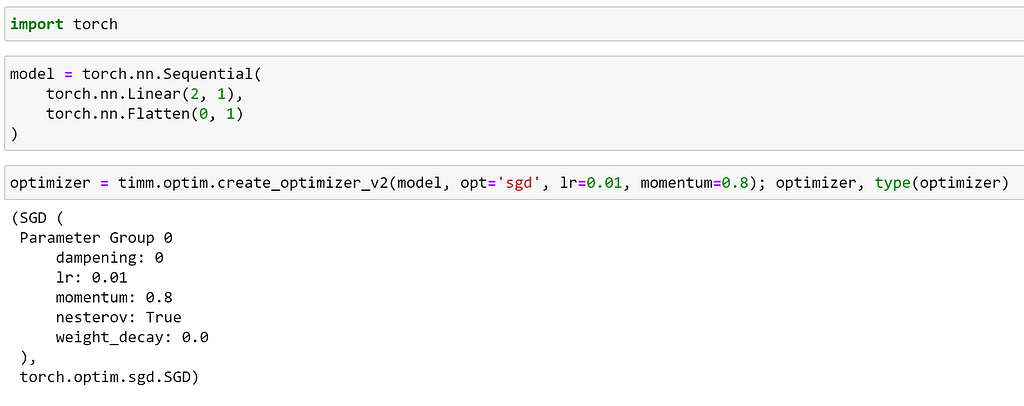
Here, we can see that as timm does not contain an implementation of SGD, it has created our optimizer using the implementation from `torch.optim`.
Let’s try creating one of the optimizers implemented in timm.
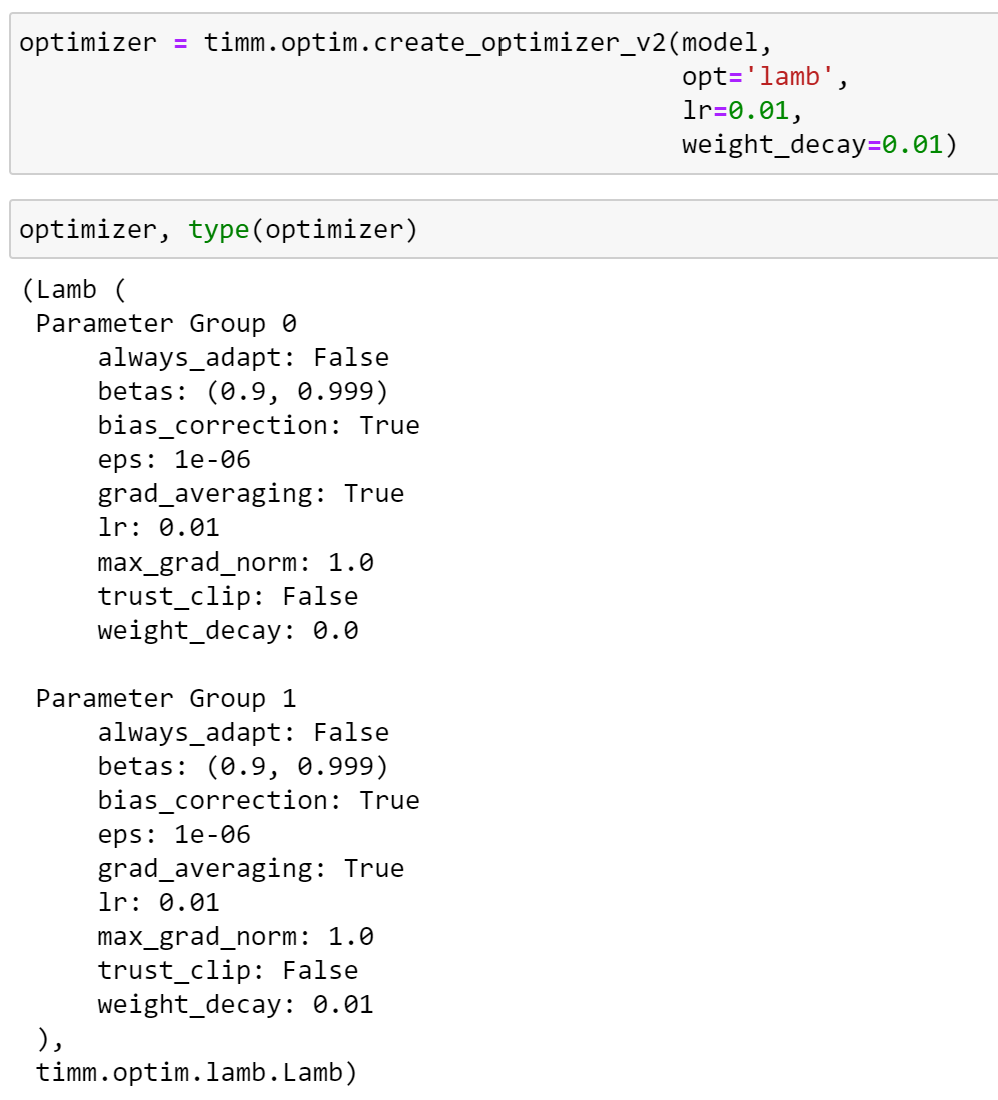
We can verify that timm’s implementation of Lamb has been used, and our weight decay has been applied to parameter group 1.
Creating optimizers manually
Of course, if we prefer not to use create_optimizer_v2, all of these optimizers can be created in the usual way.
optimizer = timm.optim.RMSpropTF(model.parameters(), lr=0.01)
Usage Example
Now, we can use most of these optimizers as demonstrated below:
# replace
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# with
optimizer = timm.optim.AdamP(model.parameters(), lr=0.01)
for epoch in num_epochs:
for batch in training_dataloader:
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()
At the time of writing, the only exception to this is the second order Adahessian optimizer, which requires a small tweak when performing the backward step; similar tweaks are likely to be needed for additional second order optimizers which may be added in future.
This is demonstrated below.
optimizer = timm.optim.Adahessian(model.parameters(), lr=0.01)
is_second_order = (
hasattr(optimizer, "is_second_order") and optimizer.is_second_order
) # True
for epoch in num_epochs:
for batch in training_dataloader:
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward(create_graph=second_order)
optimizer.step()
optimizer.zero_grad()
Lookahead
timm also enables us to apply the lookahead algorithm to an optimizer; introduced here and explained excellently here. Lookahead may improve the learning stability and lowers the variance of its inner optimizer, with negligible computation and memory cost.
We can apply Lookahead to an optimizer by prefixing the optimizer name with lookahead_ .
optimizer = timm.optim.create_optimizer_v2(model.parameters(), opt='lookahead_adam', lr=0.01)
or wrapping by the optimizer instance in timm’s Lookahead class:
timm.optim.Lookahead(optimizer, alpha=0.5, k=6)
When using Lookahead, we need to update our training script to include the following line, to update the slow weights.
optimizer.sync_lookahead()
An example of how this can be used is demonstrated below:
optimizer = timm.optim.AdamP(model.parameters(), lr=0.01)
optimizer = timm.optim.Lookahead(optimizer)
for epoch in num_epochs:
for batch in training_dataloader:
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()
optimizer.sync_lookahead()
Schedulers
At the time of writing, timm contains the following schedulers:
- StepLRScheduler: the learning rate decays every _n_ steps; similar to torch.optim.lr_scheduler.StepLR
- MultiStepLRScheduler: a step scheduler that supports multiple milestones at which to reduce the learning rate; similar to torch.optim.lr_scheduler.MultiStepLR
- PlateauLRScheduler: reduces the learning rate by a specified factor each time a specified metric plateaus; similar to torch.optim.lr_scheduler.ReduceLROnPlateau
- CosineLRScheduler: cosine decay schedule with restarts, as described in this paper; similar to torch.optim.lr_scheduler.CosineAnnealingWarmRestarts
- TanhLRScheduler: hyberbolic-tangent decay schedule with restarts, as described in this paper
- PolyLRScheduler: polynomial decay schedule, as described in this paper
Whilst many of the schedulers implemented in timm have counterparts in PyTorch, the timm versions often have different default hyperparameters as well as providing additional options and flexibility; all timm schedulers warmup epochs, as well as having the option to add random noise to the schedule. Additionally, the CosineLRScheduler and PolyLRScheduler support a decay option known as k-decay as introduced here.
Let’s first explore how we can use a scheduler from timm in a custom training script, before examining some of the options that these schedulers provide.
Usage Example
Unlike the the schedulers included in PyTorch, it is good practice to update timm schedulers twice per epoch:
- the .step_update method should be called after each optimizer update, with the index of the next update; this where we would call .step for a PyTorch scheduler
- the .step method should be called at the end of each epoch, with the index of the next epoch
By explicitly providing the number of updates and the epoch indices, this enables the timm schedulers to remove the confusing `last_epoch` and `-1` behaviour observed in PyTorch schedulers.
An example of how we can use a timm scheduler is presented below:
training_epochs = 300
cooldown_epochs = 10
num_epochs = training_epochs + cooldown_epochs
optimizer = timm.optim.AdamP(my_model.parameters(), lr=0.01)
scheduler = timm.scheduler.CosineLRScheduler(optimizer, t_initial=training_epochs)
for epoch in range(num_epochs):
num_steps_per_epoch = len(train_dataloader)
num_updates = epoch * num_steps_per_epoch
for batch in training_dataloader:
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward()
optimizer.step()
scheduler.step_update(num_updates=num_updates)
optimizer.zero_grad()
scheduler.step(epoch + 1)
Adjusting learning rate schedules
To demonstrate some of the options that timm offers, let’s explore some of the hyperparameters which are available, and how modifying these affects on the learning rate schedule.
Here, we shall focus on the CosineLRScheduler, as this is the scheduler used by default in timm’s training scripts. However, as described above, features such as adding warmup and noise are present in all of the schedulers listed above.
So that we can visualise the learning rate schedule, let’s define a function to create a model and optimizer to use with our scheduler. Note that, as we will only be updating the scheduler, the model is not actually being optimized, but we require an optimizer instance to work with our scheduler, and an optimizer requires a model.
def create_model_and_optimizer():
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
return model, optimizer
Using the `CosineAnnealingWarmRestarts` scheduler from PyTorch
To illustrate timm’s cosine scheduler differs from the one included in PyTorch, let’s first look at how we would use the torch implementation of ConsineAnnealingWarmRestarts.
This class supports the following parameters:
- T_0 (int): Number of iterations for the first restart.
- T_mult (int): A factor that increases T_{i} after a restart. (Default: `1`)
- eta_min (float): Minimum learning rate. (Default: `0.`)
- last_epoch (int) — The index of last epoch. (Default: `-1`)
To set our schedule, we need to define the following: the number of epochs, the number of updates that take place per epoch, and — if we would like to enable restarts — the number of steps at which the learning rate should return to its initial value. As we are not using any data here, we can set these somewhat arbitrarily.
num_epochs=300
num_epoch_repeat = num_epochs//2
num_steps_per_epoch = 10
Note: Here, we have specified that we would like the learning rate to ‘restart’ halfway through the training run. This was selected primarily for visualisation purposes — so that we can understand what a restart looks like for this scheduler — as opposed to this being the recommended way to use this scheduler during a real training run.
Now, let’s create our learning rate scheduler. As T_0 requires the time until the first restart to be specified in terms of the number of iterations — where each iteration is a batch — we calculate this by multiplying the index of the epoch that we would like the restart to occur with the number of steps per epoch. Here, we are also specifying that the learning rate should never drop below `1e-6`.

Now, we can simulate using this scheduler in a training loop. As we are using the PyTorch implementation, we only need to call step after each optimizer update, which is once per batch. Here, we are recording the value of the learning rate after each step, so that we can visualise how the value of the learning rate was adjusted over the whole training run.
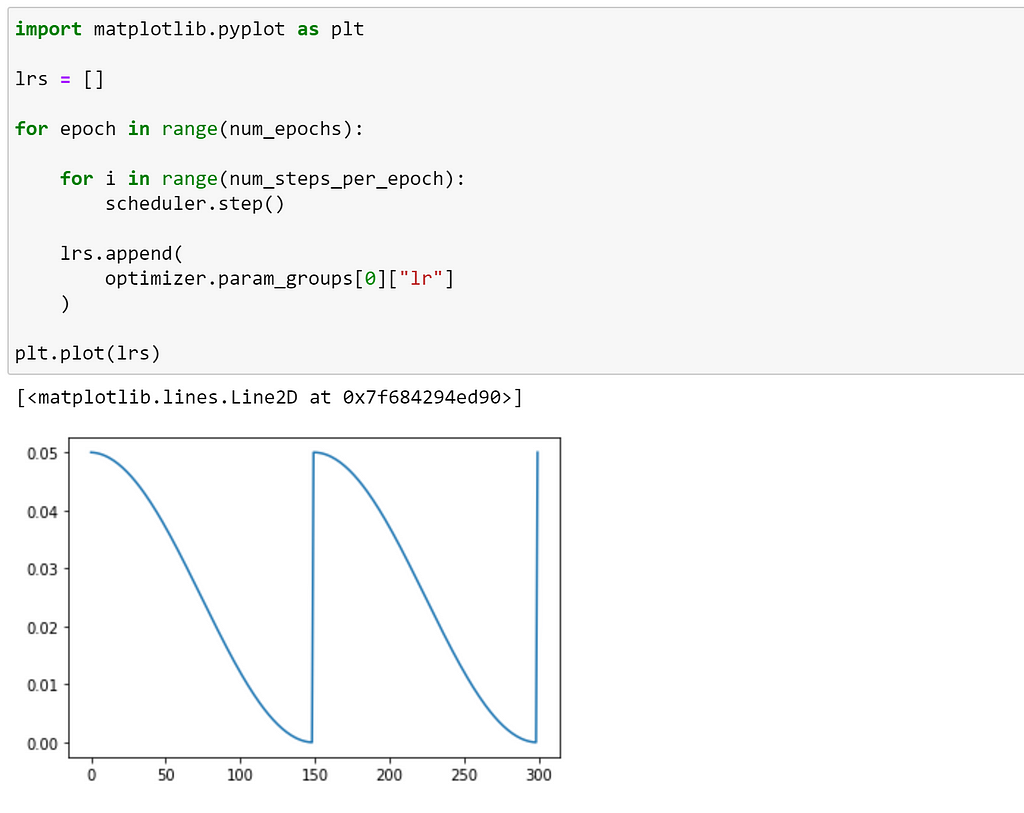
From this plot, we can see that the learning rate decayed until epoch 150, at which it was reset to its initial value before decaying again; just as we expected.
Using the `CosineLRScheduler` scheduler from timm
Now that we understand how to use PyTorch’s cosine scheduler, let’s explore how this compares with the implementation included in timm, and the additional options that are offered. To begin, let’s replicate the previous plot using timm’s implementation of a cosine learning rate scheduler — CosineLRScheduler.
Some of arguments that we will need to do this are similar to those that we have seen before:
- t_initial (int): Number of iterations for the first restart, this is equivalent to `T_0` in torch’s implementation
- lr_min (float): Minimum learning rate, this is equivalent to eta_min in torch’s implementation (Default: `0.`)
- cycle_mul (float): A factor that increases T_{i} after a restart, this is equivalent to T_mult in torch’s implementation (Default: `1`)
However, to observe behaviour consistent with Torch, we will also need to set:
- cycle_limit (int): Limit the number of restarts in a cycle (Default: `1`)
- t_in_epochs (bool): Whether the number iterations is given in terms of epochs rather than the number of batch updates (Default: `True`)
First, let’s define the same schedule as before.
num_epochs=300
num_epoch_repeat = num_epochs/2
num_steps_per_epoch = 10
Now, we can create our scheduler instance. Here, we are expressing the number of iterations in terms of the number of update steps, and increasing the cycle limit to more than our desired number of restarts; so that the parameters are the same as we used with torch’s implementation earlier.

Now, let’s define a new function to simulate using a timm scheduler in a training run and record the updates to the learning rate.
def plot_lrs_for_timm_scheduler(scheduler):
lrs = []
for epoch in range(num_epochs):
num_updates = epoch * num_steps_per_epoch
for i in range(num_steps_per_epoch):
num_updates += 1
scheduler.step_update(num_updates=num_updates)
scheduler.step(epoch + 1)
lrs.append(optimizer.param_groups[0]["lr"])
plt.plot(lrs)
We can now use this to plot our learning rate schedule!
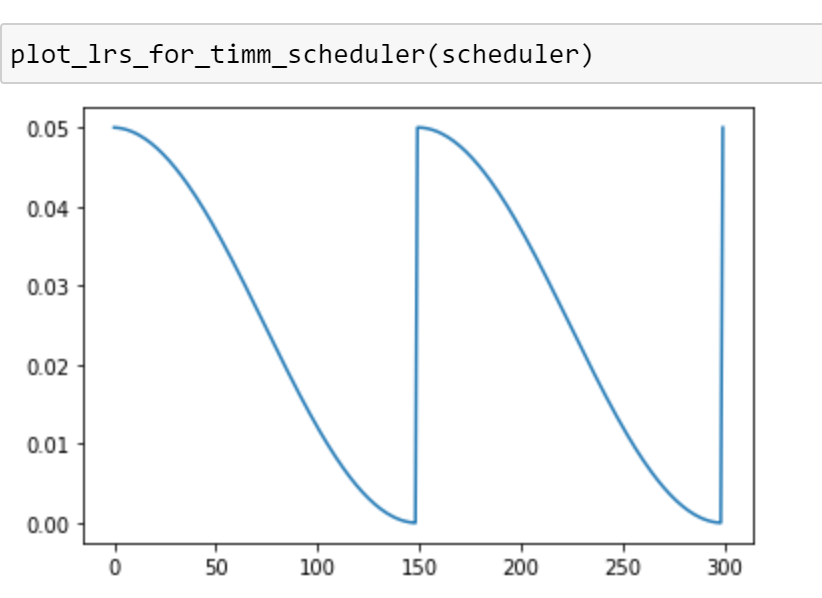
As expected, our graph looks identical to the one we saw earlier.
Now that we have replicated the behaviour that we saw in torch, let’s look at some of the additional features that timm offers in more detail.
Until now, we have expressed the number of iterations in terms of optimizer updates; which required us to calculate the number of iterations for the first repeat using num_epoch_repeat * num_steps_per_epoch However, by specifying our iterations in terms of epochs — which is the default in timm — we can avoid having to do this calculation. Using the default setting, we can simply pass the index of the epoch at which we would like the first restart to occur, as demonstrated below.
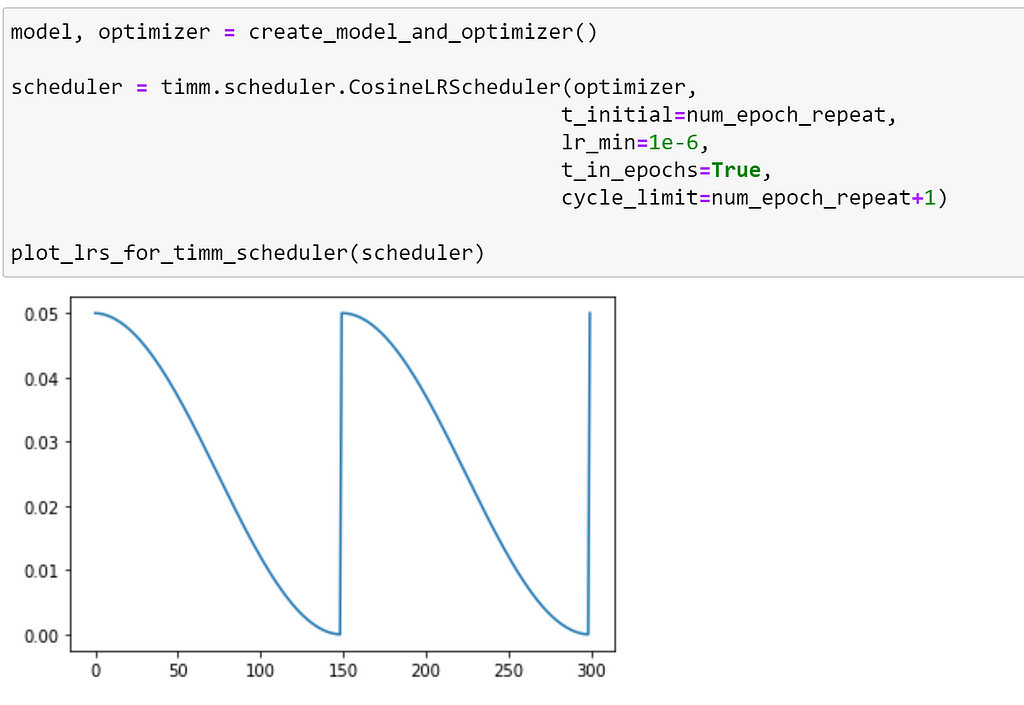
We can see that our schedule is unchanged, we have just expressed our arguments slightly differently.
Adding warm up and noise
Another feature of all timm optimizers, is that they support adding warm up and noise to a learning rate schedule. We can specify the number of warm up epochs, and the initial learning rate to be used during the warm up, with the warmup_t and warmup_lr_init arguments. Let’s see how our schedule changes if we specify that we would like 20 warm up epochs.
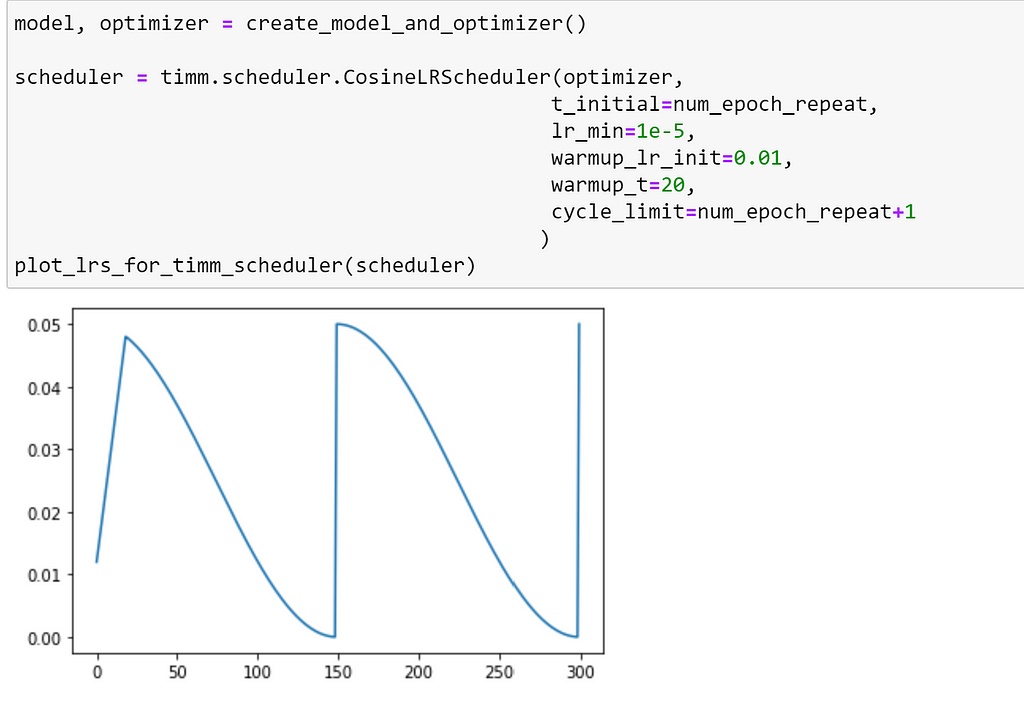
Here, we can see that this has resulted in a more gradual increase to our minimum learning rate, rather than starting at that point as we saw before.
We can also add noise to a range of epochs, using the noise_range_t and noise_pct arguments. Let’s add a small amount of noise to the first 150 epochs:
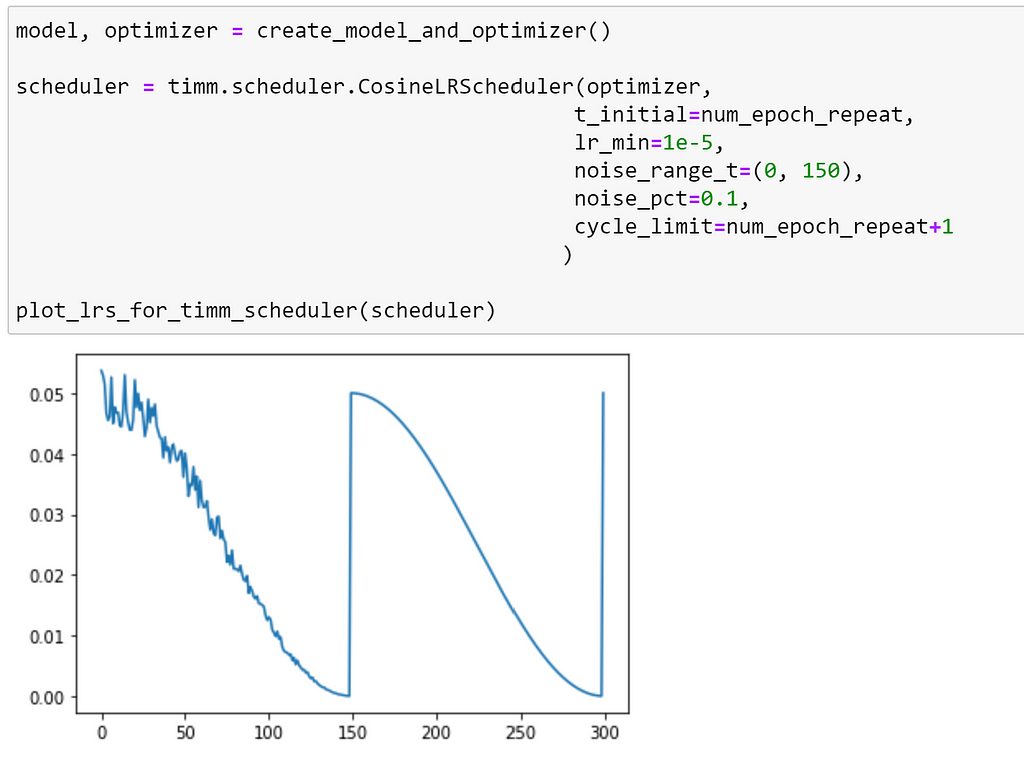
We can see that, up until epoch 150, the added noise affects our schedule so that learning rate does not decrease in a smooth curve. We can make this more extreme by increasing noise_pct.
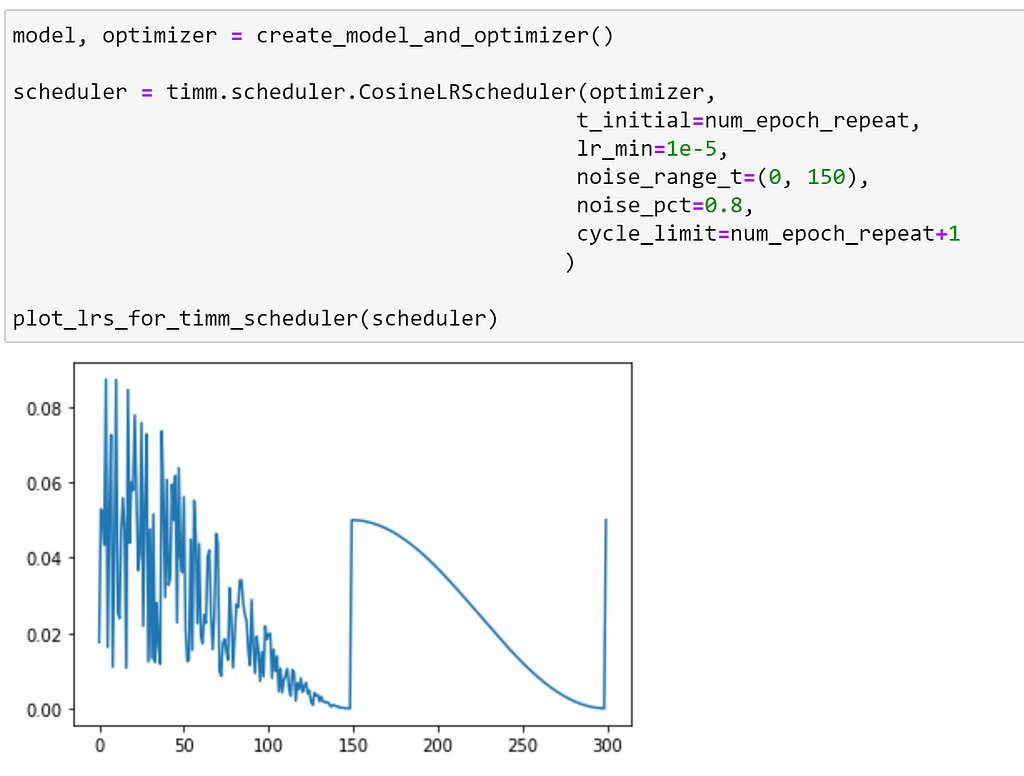
Additional options for `CosineLRScheduler`
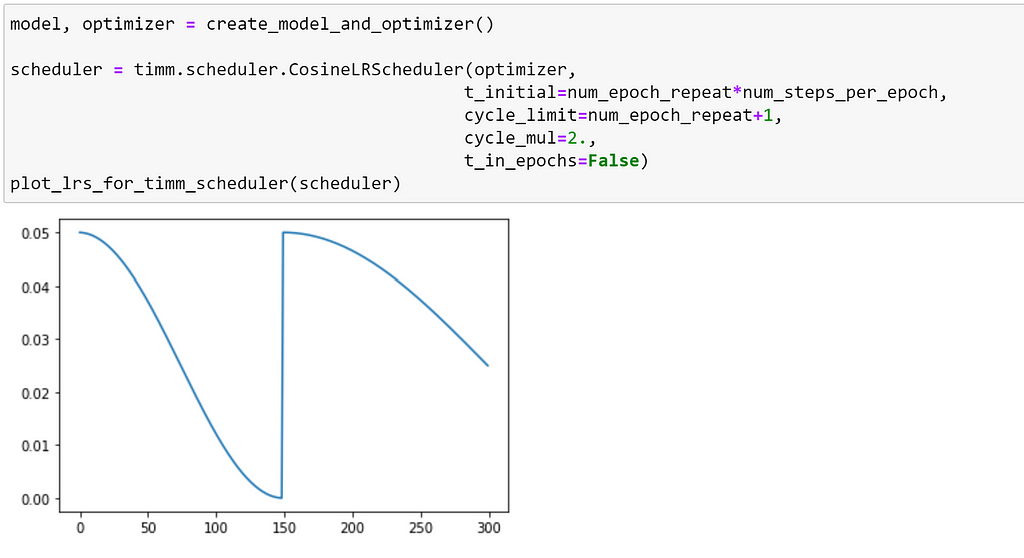
Whilst warm up and noise can be used with any scheduler, there are some additional features which are specific to CosineLRScheduler. Let’s explore how these affect our learning rate cycle.
We can use cycle_mul, to increase the time until the next restart, as seen below.
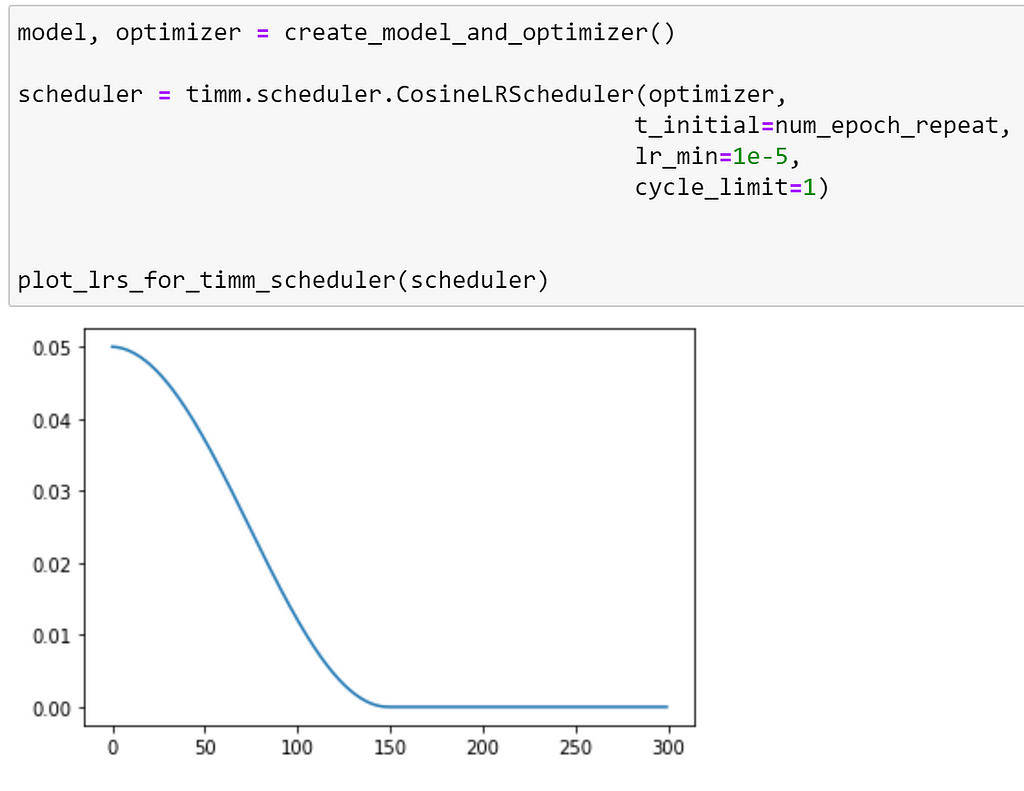
Additionally, timm provides the option to limit the number of restarts with cycle_limit. By default, this is set to `1`, which results in the following schedule.
CosineLRScheduler also supports different types of decay. We can use cycle_decay to reduce (or increase) the value of the learning rate that will be set during each successive restart.
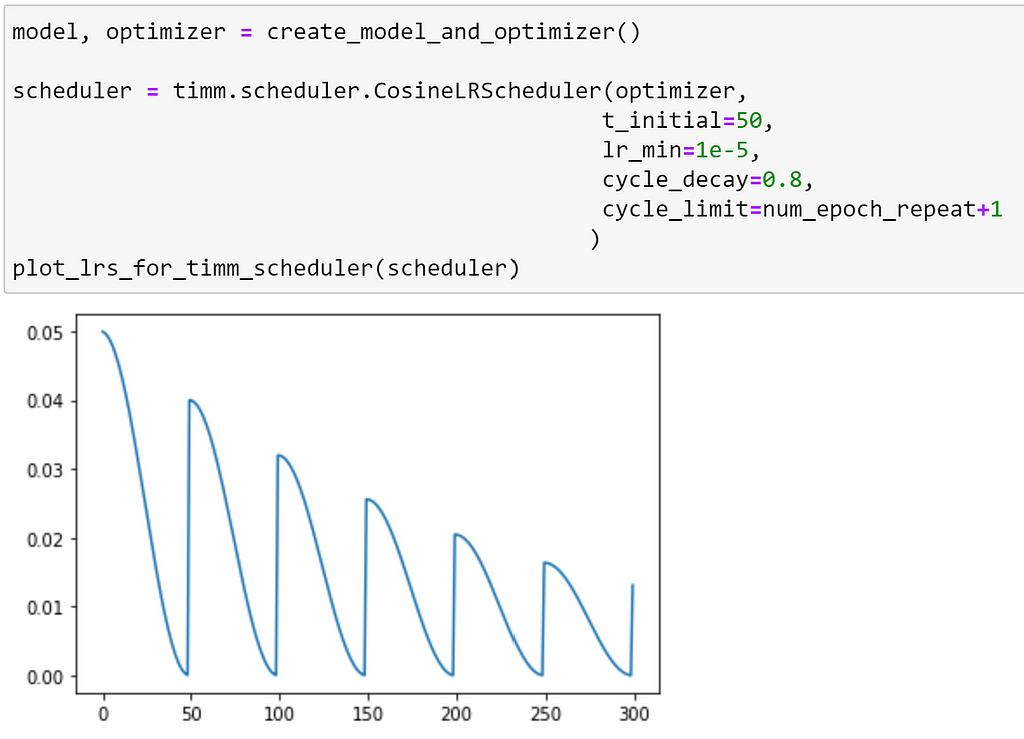
Note: here we have increased the frequency of the number of restarts to better illustrate the decay.
To control the curve itself, we can use the k_decay argument, for which the rate of change of the learning rate is changed by its k-th order derivative, as explained in this paper.
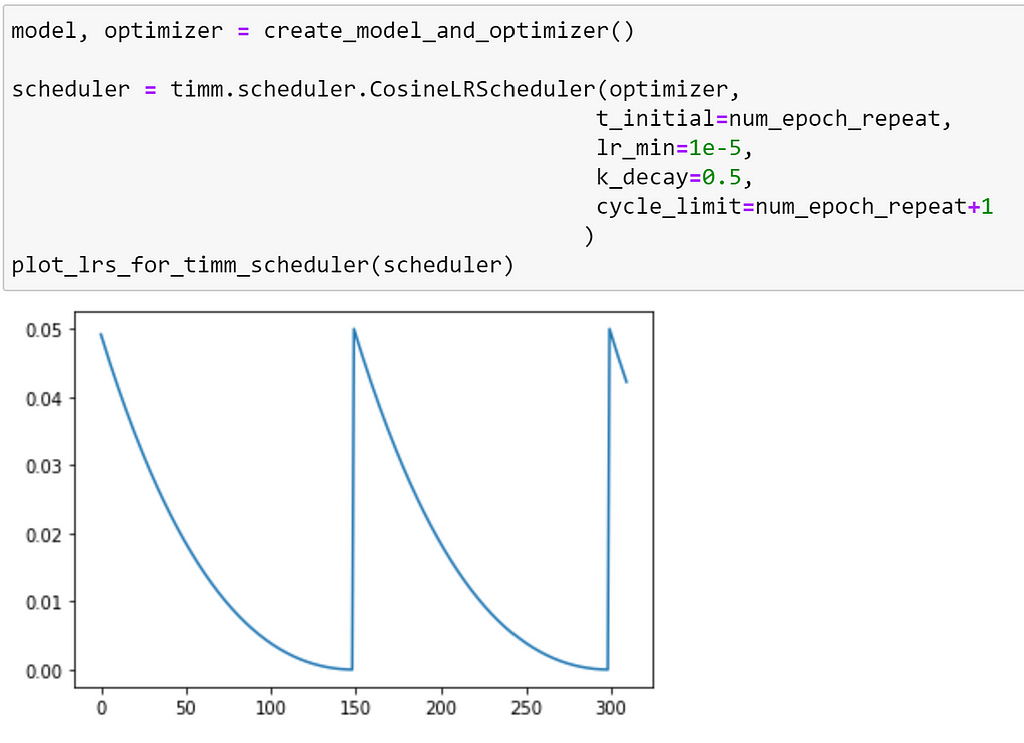
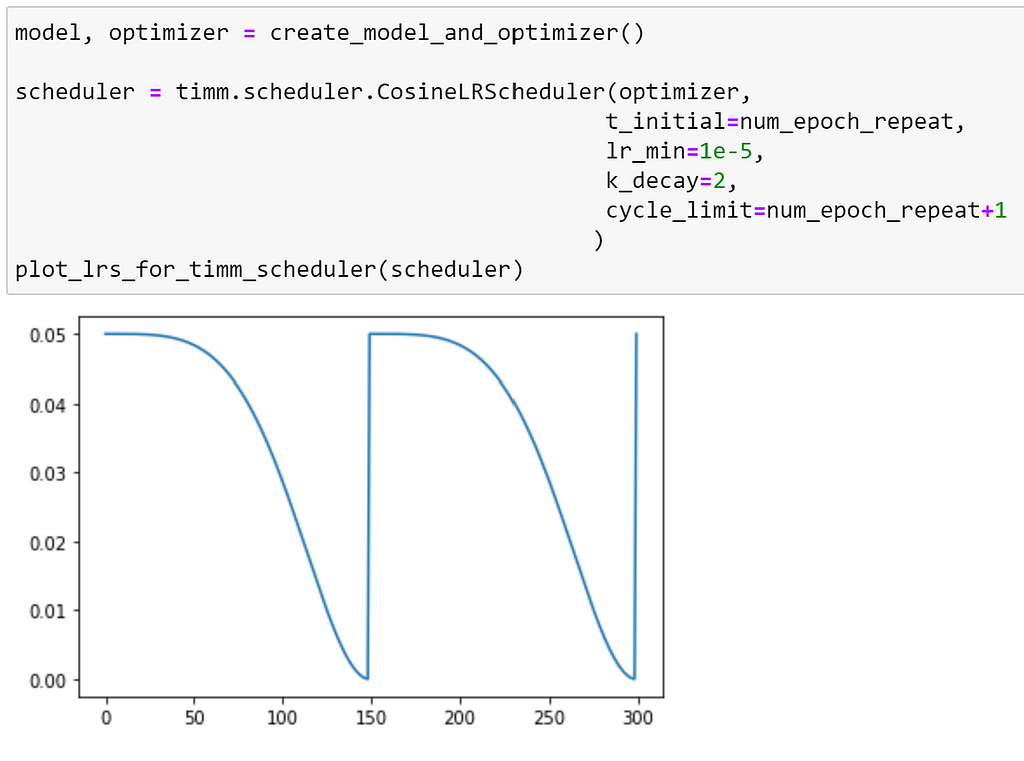
This option provides even more control over the annealing performed by this scheduler!
Default settings in timm’s training script
If we set this scheduler using the default settings from timm’s training script, we observe the following schedule.
Note: in the training script, training continues for an additional 10 epochs without further modifications to the learning rate as a ‘cool down’.
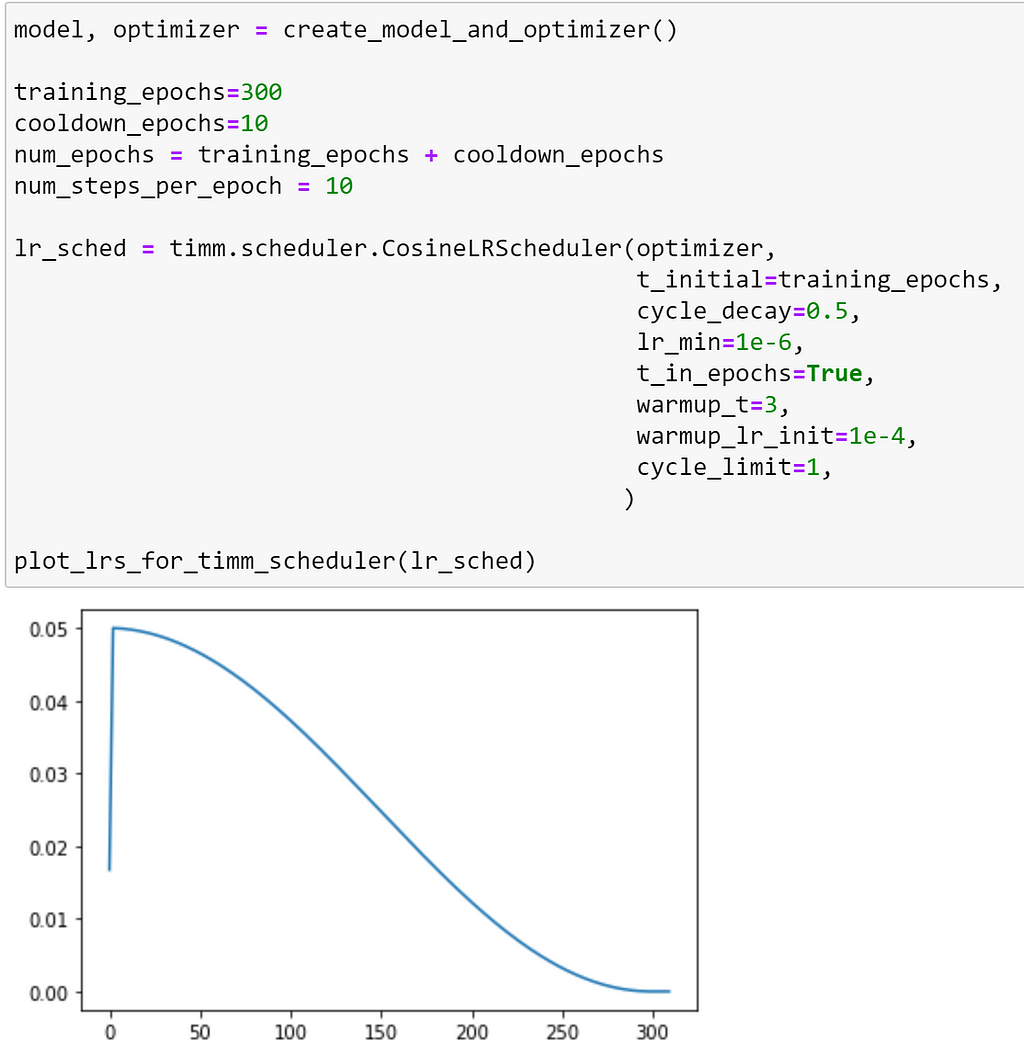
As we can see, there are no restarts at all with the default settings!
Other learning rate schedules
Whilst my favourite of the schedulers included with timm is CosineLRScheduler, it may be helpful to visualise the schedules of some of the other schedulers, that have no counterpart in PyTorch. Both of these schedulers are similar to the cosine scheduler in the sense that the learning rate is reset after a specified number epochs — assuming a cycle limit is not set — but the annealing is done slightly differently.
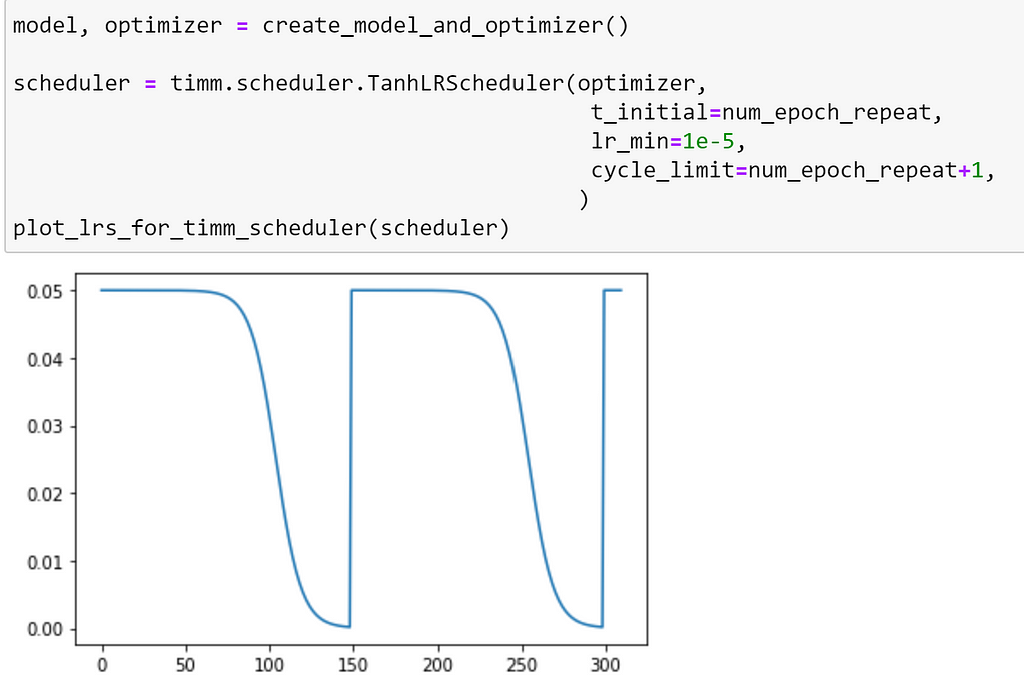
For the TanhLRScheduler, annealing is performed using the hyperbolic-tangent function, as demonstrated below.
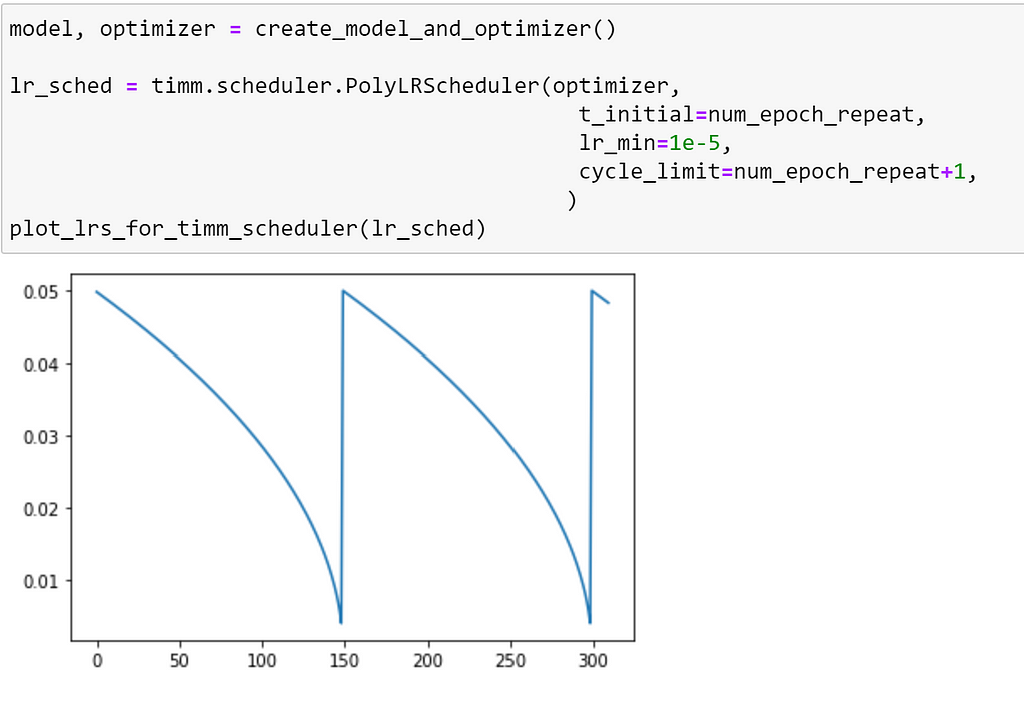
timm also provides PolyLRScheduler, which uses a polynomial decay:
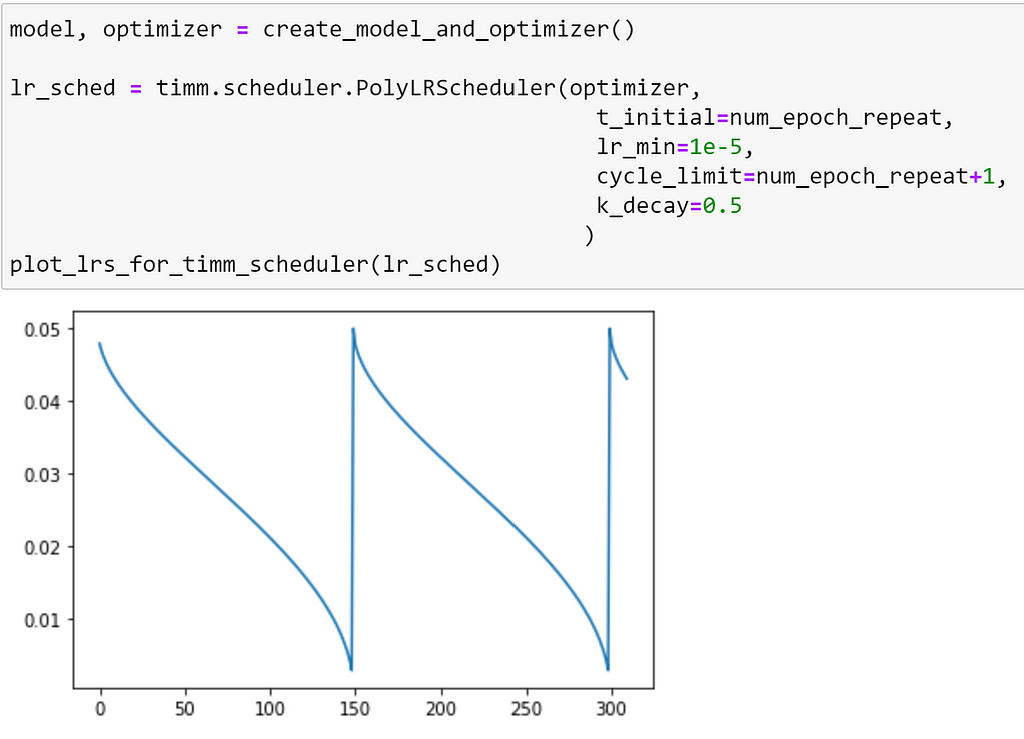
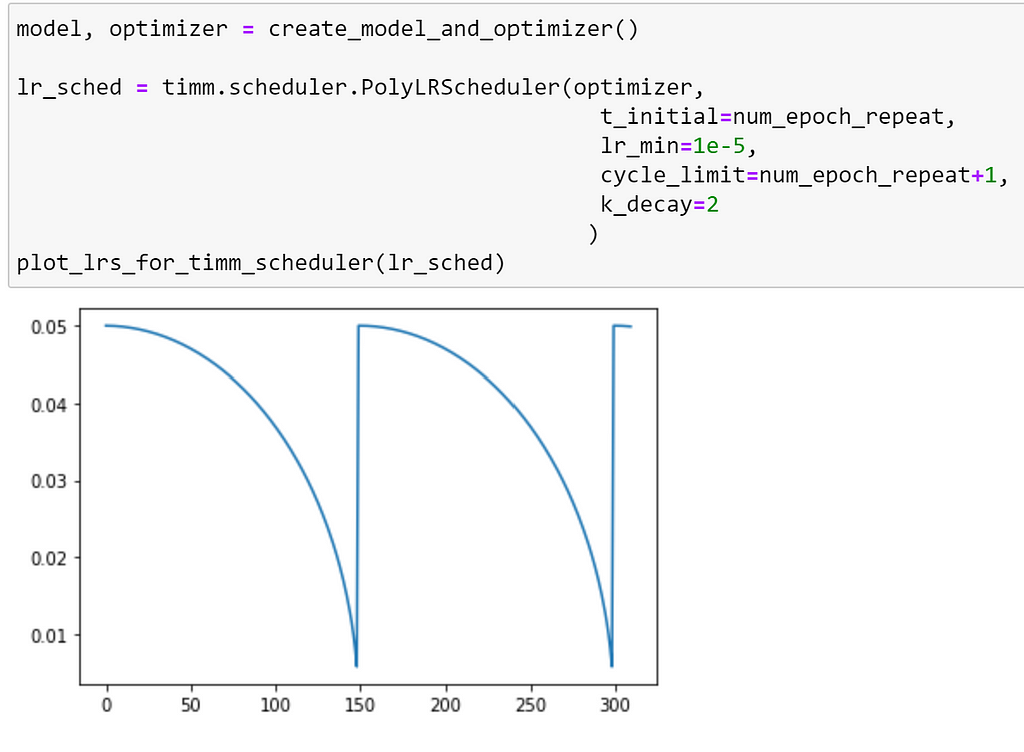
Similarly to CosineLRScheduler, the PolyLRScheduler scheduler also supports the k_decay argument, as demonstrated below:
Exponential Moving Average Model
When training a model, it can be beneficial to set the values for the model weights by taking a moving average of the parameters that were observed across the entire training run, as opposed to using the parameters obtained after the last incremental update. In practice, this is often done by maintaining an EMA model, which is a copy of the model that we are training. However, rather than updating all of the parameters of this model after every update step, we set these parameters using a linear combination of the existing parameter values and the updated values. This is done using the following formula:
updated_EMA_model_weights =
decay * EMA_model_weights + (1. — decay) * updated_model_weights
where the _decay_ is a parameter that we set. For example, if we set decay=0.99, we have:
updated_EMA_model_weights =
0.99 * EMA_model_weights + 0.01 * updated_model_weights
which we can see is keeping 99% of the existing state and only 1% of the new state!
To understand why this may be beneficial, let’s consider the case that our model, in an early stage of training, performs exceptionally poorly on a batch of data. This may result in a large update update to our parameters, overcompensating for the high loss obtained, which will be detrimental for the upcoming batches. By only incorporating only a small percentage of the latest parameters, large updates will be ‘smoothed’, and have less of an overall impact on the model’s weights.
Sometimes, these averaged parameters can sometimes produce significantly better results during evaluation, and this technique has been employed in several training schemes for popular models such as training MNASNet, MobileNet-V3 and EfficientNet; using the implementation included in TensorFlow. Using the ModelEmaV2 module implemented in timm, we can replicate this behaviour, and apply the same practice to our own training scripts.
The implementation of ModelEmaV2 expects the following arguments:
- model: the subclass of nn.Module that we are training. This is the model that will be updated in our training loop as normal
- decay: (float) the amount of decay to use, which determines how much of the previous state will be maintained. The TensorFlow documentation suggests that reasonable values for decay are close to 1.0, typically in the multiple-nines range: 0.999, 0.9999, etc. (Default: `0.9999`)
- device: the device that should be used to evaluate the EMA model. If this is not set, the EMA model will be created on the same device that is being used for the model.
Let’s explore how we can incorporate this in a training loop.
model = create_model().to(gpu_device)
ema_model = ModelEmaV2(model, decay=0.9998)
for epoch in num_epochs:
for batch in training_dataloader:
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()
model_ema.update(model)
for batch in validation_dataloader:
inputs, targets = batch
outputs = model(inputs)
validation_loss = loss_function(outputs, targets)
ema_model_outputs = model_ema.module(inputs)
ema_model_validation_loss = loss_function(ema_model_outputs, targets)
As we can see, to update the parameters of the EMA model, we need to call .update after each parameter update. As the EMA model has different parameters to the one being trained, we must evaluate this separately.
It is important to note that this class is sensitive to where it is initialised. During distributed training, it should be applied before before the conversion to SyncBatchNorm takes place and before the DistributedDataParallel wrapper is used!
Additionally, when saving the EMA model, the keys inside the state_dict will be the same as those for the model being trained, so a different checkpoint should be used!
Putting it all together!
Whilst the pseudocode snippets throughout this article illustrate how each component can be used in a training loop individually, let’s explore an example where we use many different components at once!
Here, we shall look at training a model on Imagenette. Note that, as Imagenette is a subset of Imagenet, if we use a pretrained model we are cheating slightly, as only the new classification head will be initialised with random weights; therefore, in this example, we shall train from scratch.
Note: The purpose of this example is to demonstrate how multiple components from timm can be used together. As such, the features selected — and the hyperparameters used — have been selected somewhat arbitrarily; so the performance could probably be improved with some careful tuning!
To remove the boilerplate that we usually see in PyTorch training loops, such as iterating through the DataLoaders and moving data between devices, we shall use PyTorch-accelerated to handle our training; this enables us to focus only on the differences that are required when using timm components.
If you are unfamiliar with PyTorch-accelerated and would like to learn more about it before diving into this article, please check out the introductory blog post or the docs; alternatively, it’s very simple and a lack of knowledge in this area should not impair your understanding of the content explored here!
In PyTorch-accelerated, the training loop is handled by the `Trainer` class; where we can override specific methods to change the behaviour at certain steps. In pseudocode, the execution of a training run inside of the PyTorch-accelerated Trainer can be depicted as:
train_dl = create_train_dataloader()
eval_dl = create_eval_dataloader()
scheduler = create_scheduler()
training_run_start()
on_training_run_start()
for epoch in num_epochs:
train_epoch_start()
on_train_epoch_start()
for batch in train_dl:
on_train_step_start()
batch_output = calculate_train_batch_loss(batch)
on_train_step_end(batch, batch_output)
backward_step(batch_output["loss"])
optimizer_step()
scheduler_step()
optimizer_zero_grad()
train_epoch_end()
on_train_epoch_end()
eval_epoch_start()
on_eval_epoch_start()
for batch in eval_dl:
on_eval_step_start()
batch_output = calculate_eval_batch_loss(batch)
on_eval_step_end(batch, batch_output)
eval_epoch_end()
on_eval_epoch_end()
training_run_epoch_end()
on_training_run_epoch_end()
training_run_end()
on_training_run_end()
More details about how the Trainer works can be found in the documentation.
We can subclass the default trainer, and use this in a training script, as demonstrated below:
Using this training script on Imagenette using 2 GPUs, following the instructions here, I obtained the following metrics:
- accuracy: 0.89
- ema_model_accuracy: 0.85
after 34 epochs; which isn’t bad considering that the hyperparameters haven’t been tuned!
Conclusion
Hopefully that has provided a somewhat comprehensive overview of some of the features included in timm, and how these can be applied in custom training scripts.
Finally, I’d like to take a moment to acknowledge the sheer amount of effort that has been put into creating this awesome library by Ross Wightman, the creator of timm. Ross’s dedication to providing implementations of state-of-the-art computer vision models that are easily accessible to the whole data science community is second to none. If you haven’t already, go and add stars!
All of the code required to replicate this post is available as a GitHub gist here.
Chris Hughes is on LinkedIn.
References
- rwightman/pytorch-image-models: PyTorch image models, scripts, pretrained weights — ResNet, ResNeXT, EfficientNet, EfficientNetV2, NFNet, Vision Transformer, MixNet, MobileNet-V3/V2, RegNet, DPN, CSPNet, and more (github.com)
- Papers with Code 2021 : A Year in Review | by elvis | PapersWithCode | Dec, 2021 | Medium
- ImageNet (image-net.org)
- Pytorch Image Models (rwightman.github.io)
- Pytorch Image Models (timm) | timmdocs (fastai.github.io)
- PyTorch Image Models | Papers With Code
- [1812.01187] Bag of Tricks for Image Classification with Convolutional Neural Networks (arxiv.org)
- [2010.11929v2] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (arxiv.org)
- Feature Pyramid Networks for Object Detection | IEEE Conference Publication | IEEE Xplore
- Visual Geometry Group — University of Oxford
- torchvision — Torchvision 0.11.0 documentation (pytorch.org)
- torch.fx — PyTorch 1.10.1 documentation
- Feature Extraction in TorchVision using Torch FX | PyTorch
- TorchScript — PyTorch 1.10.1 documentation
- Introduction to TorchScript — PyTorch Tutorials 1.10.1+cu102 documentation
- ONNX | Home
- torch.onnx — PyTorch master documentation
- [1909.13719] RandAugment: Practical automated data augmentation with a reduced search space (arxiv.org)
- [2110.00476v1] ResNet strikes back: An improved training procedure in timm (arxiv.org)
- [1905.04899] CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features (arxiv.org)
- [1710.09412] mixup: Beyond Empirical Risk Minimization (arxiv.org)
- torchvision.datasets — Torchvision 0.11.0 documentation (pytorch.org)
- TensorFlow Datasets
- torch.utils.data — PyTorch 1.10.1 documentation
- pathlib — Object-oriented filesystem paths — Python 3.10.2 documentation
- torch.optim — PyTorch 1.10.1 documentation
- [2006.08217] AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights (arxiv.org)
- lecture_slides_lec6.pdf (toronto.edu)
- Apex (A PyTorch Extension) — Apex 0.1.0 documentation (nvidia.github.io)
- [2010.07468] AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients (arxiv.org)
- juntang-zhuang/Adabelief-Optimizer: Repository for NeurIPS 2020 Spotlight “AdaBelief Optimizer: Adapting stepsizes by the belief in observed gradients” (github.com)
- [2101.11075] Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization (arxiv.org)
- [2006.00719] ADAHESSIAN: An Adaptive Second Order Optimizer for Machine Learning (arxiv.org)
- [1907.08610] Lookahead Optimizer: k steps forward, 1 step back (arxiv.org)
- Lookahead Optimizer: k steps forward, 1 step back | Michael Zhang — YouTube
- torch.optim — PyTorch 1.10.1 documentation
- [1806.01593] Stochastic Gradient Descent with Hyperbolic-Tangent Decay on Classification (arxiv.org)
- [2004.05909] k-decay: A New Method For Learning Rate Schedule (arxiv.org)
- [1807.11626v3] MnasNet: Platform-Aware Neural Architecture Search for Mobile (arxiv.org)
- [1905.11946v5] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (arxiv.org)
- [1905.02244v5] Searching for MobileNetV3 (arxiv.org)
- tf.train.ExponentialMovingAverage | TensorFlow Core v2.7.0
- Introducing PyTorch-accelerated | by Chris Hughes | Nov, 2021 | Towards Data Science
- Welcome to pytorch-accelerated’s documentation! — pytorch-accelerated 0.1.3 documentation
Getting Started with PyTorch Image Models (timm): a practitioner’s guide was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/xXYIaKCm9
via RiYo Analytics







ليست هناك تعليقات