https://ift.tt/r5AUvPx Authors: Chen Xi , Mengyong Lee , Santosh Yadaw Photo by National Cancer Institute via Unsplash In this article...
Authors: Chen Xi, Mengyong Lee, Santosh Yadaw
In this article, we will discuss the challenges and techniques for deploying a Semantics Segmentation algorithm on edge device. In particular, we will go through the technical challenges faced when working on our project, an Automatic Wound Segmentation model deployed onto iOS devices.
We will first briefly go through the project background, followed by the technical challenges we faced and the methods to overcome these challenges.
Technical Challenge 1 — Small and Imbalance Dataset
- Data Augmentation
- Transfer Learning
- Choosing the Right Metrics
- Custom Loss Function
Technical Challenge 2— Edge Deployment
- Performance vs Size Tradeoff
- Quantisation
Technical Challenge 3 — Creating a Flexible Retraining Pipeline
- Experiment Tracking — WandB
- Configuration Management — Hydra
- Hyper-parameter Search — Bayesian Optimisation
Project Background
Today, 9.3% of the adults in the world live with diabetes. Of all adults with diabetes, 25% them will develop diabetic foot ulcers in their lifetime. When left unchecked, diabetic foot ulcers may deteriorate, causing severe damages to tissues and bones which may require surgical removal (amputation) of a toe, foot, or part of a leg. 85% of major amputations today are preceded by diabetic foot ulcers. With proper wound care and intervention, it is possible to prevent and heal diabetic foot ulcers.
Currently, assessments of diabetic foot ulcers are done manually through a skilled physician. A patient who suspects that he/she has a diabetic foot ulcer would have to travel to a hospital, where a skilled physician would observe the wounds and manually measure and classify the wound. The process is not only time consuming, it is also inaccurate and patients have to bear with pain and infection risks when wounds are measured using rulers and probes.
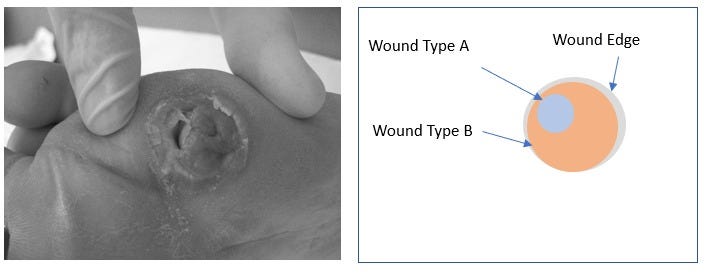
Technique — Semantics Segmentation
The Computer Vision technique used in this problem is known as Semantics Segmentation. This technique is commonly used in autonomous navigation. Segmentation is considered to be one of the hardest tasks in the Computer Vision field as we have to classify each pixel of the image according to the classes. Fortunately for us, there has been incredible research in this space in the past few years. In the PASCAL VOC benchmark for semantics segmentation, (https://paperswithcode.com/sota/semantic-segmentation-on-pascal-voc-2012), we can find many open sourced models that are fairly accurate on street images and objects. While there have been many open-sourced semantics segmentation models that we can try, none of them were trained on similar images to ours (medical images).

Technical Challenges
In this project. we had to solve numerous technical challenges, namely 1. Small and Imbalanced dataset, 2. Edge Deployment, and 3. Creating a Flexible Retraining Pipeline. In the upcoming sections of the article, we will discuss these challenges in detail and how we overcame them.
Technical Challenge 1 — Small and Imbalanced Dataset
The first technical challenge we face is having a small dataset that is imbalanced. In the medical domain, data collection and annotations are very expensive. On data collection, due to the sensitive nature of the data (personal data), there are very few images of diabetic foot ulcers online and collecting them typically requires user permission. On data annotations, identification of wounds is typically done by a skilled physician. The data has to be manually annotated on an image annotation tool (such as CVAT) and checked for consistency by physicians.
Thankfully, we worked with a client company that understands the importance of data to an AI project. Our client collaborated with multiple hospitals and nursing homes in Singapore to collect images of diabetic foot ulcers and even purchased data from other hospitals in the region. To annotate the data, the company put together an annotation task force consisting of doctors and trained professionals who annotated the images with a high level of consistency.
Even with the herculean effort by our client, the dataset size is still small compared to what is typically used to train a semantic segmentation algorithm. Furthermore, we are also facing an imbalanced dataset problem. Of all the wound images, more than 90% of the pixels in the images are skin or background. The remaining wound pixels are split unevenly into more than 7 classes, with each wound class having around 0.2% to 2.7% of all pixel counts.
We will discuss some of our methods in overcoming the challenge of small and imbalance data.
1. Data Augmentation
The first tactic to overcome the small data size challenge is to artificially increase the dataset size through augmentation. Data Augmentation is the technique to increase the size and diversity of the training dataset artificially by performing geometric (rotation, flipping, cropping) and photometric (changing contrast, brightness, blurring etc) transformations on the existing data. This helps to combat overfitting thereby enabling our model to generalise better.
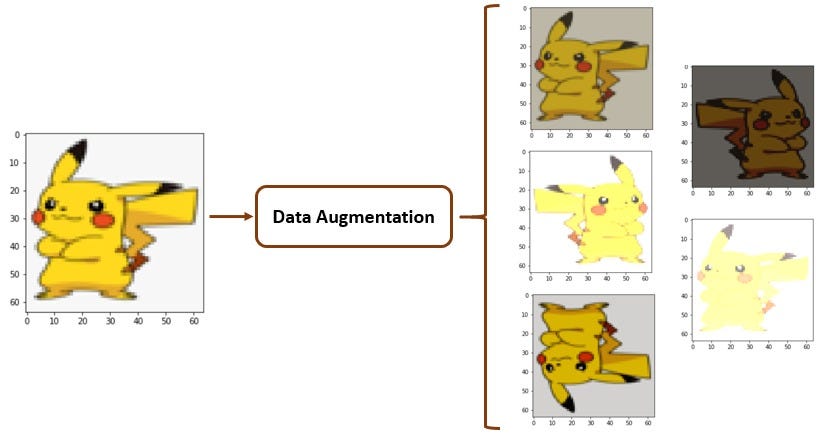
We also used augmentation to get around other specific limitations of the dataset. An example where we got creative with augmentation is on skin colour. As the data images are collected from Singapore hospitals, most of the diabetic wound images are from Chinese patients and do not contain too many images with darker or lighter skin tones. This deteriorates the model’s performance for both lighter and darker skin tones patients. To overcome this issue, we created augmentation to specifically change the skin tone of the images to generate greater image diversity and create a fairer AI model.
2. Transfer Learning
The second tactic we used to overcome a small dataset was to use Transfer Learning — the idea of using pre-trained model parameters to initialise the parameters of our model that we are going to train. Doing so enables us to take advantage of using pre-trained lower level features that have been trained using a larger dataset and learning the higher level features from our own dataset. This results in not only faster training time but also helps to overcome the issue of having a small dataset with minimal drop in performance.
However, it has to be cautioned that Transfer Learning is only effective when the dataset used to train the pre-trained parameters are somewhat similar to our dataset thereby allowing the low level features learnt to be transferable to learning the higher level features in our own dataset. To achieve the best transfer learning outcome, we experimented with freezing different layers of the weights and customising different learning rates on different layers. For our case, our models performed relatively better when trained using pre-trained weights than training from scratch.
3. Choosing the right metrics
As more than 90% of the pixels are skin/background class, using a simple metric such as accuracy would give an unreasonably high number just by classifying all pixels as skin/background class. In addition, for medical diagnostic purposes, some wound classes are more important than others in determining the severity of the diabetic foot ulcers. To get around this issue, we used class-specific weighted metrics such as IOU and F1 to determine model accuracy.
Discussion with the clients on performance metrics is crucial. Different stakeholders bring different perspectives to the table. For instance, while the management team requested for the model to run below a certain latency, the medical advisors preferred the model to give several wound classes higher priority and the engineers needed the model to be below a certain file size in order to fit the entire app into the iOS app store. Eventually, we settled on a set of metrics to measure, including class-specific weighted metrics such as IOU and F1, and metrics relating to inference speed on quantised model, and file size.
4. Custom Loss function
A standard loss function such as cross entropy loss minimises the overall prediction error during model training. However, in a case of an imbalance dataset, cross entropy loss often places higher emphasis on the majority class. Ideally, we would like to have a loss function which gives greater emphasis on the minority classes and also one that we can flexibly change to tune its performance towards optimising a certain wound class. Some of the loss function worth trying is Categorical Focal Loss, Focal Tversky Loss, Sensitivity Specificity Loss, and Sparse Categorical Focal Loss with Custom Weights. We ended up with a variant of Focal Loss which penalises the model heavier for misclassification of certain minority classes.
In this project, we have tried many different loss functions in order to produce a loss function that we are satisfied with. From experimenting with loss functions, we were able to increase the accuracy in the prediction for smaller, but more crucial wound classes substantially.
Technical Challenge 2 — Edge Deployment
Having overcome the issues of a small and imbalanced dataset, the next challenge that awaited us was edge deployment. For the model to be deployed for medical diagnosis, the model has to be regulated and approved by a healthcare statutory board. In addition, due to the wound images being personal data, all the images have to be kept locally during deployment. These two factors made cloud deployment unlikely and pushed us towards edge deployment.
1. Performance vs Size tradeoff
One of the characteristics of edge deployment is the limitation on the size of the model. As our model needs to be deployed in an app in iOS, the model size has to be small enough such that it can be hosted on the Apple App Store.
Generally, the performance of an AI model is directly correlated to the size of the model, the bigger the size, the more accurate it is. Most state of the art algorithms on the PASCAL VOC performance benchmark are too large to fit on an edge device. Hence, we have to get creative in order to achieve a good Performance vs Size tradeoff.
To reduce the size of the model while achieving good performance, we swapped the backbones of the state of the art models to smaller, more mobile-friendly backbones such as MobileNet or EfficientNet. From there, we were able to tune the alpha — the width of the network to reduce the size of our model. After which, we performed quantisation and pruning to further reduce the size of the model which we will discuss in the next section.
2. Quantisation
Quantisation is a conversion technique that can reduce model size while also improving CPU and hardware accelerator latency. Most deep learning frameworks such as Tensorflow support quantisation natively and it is pretty straightforward to quantise a model in Tensorflow. The challenge for quantisation is in choosing the right quantisation technique that can produce the fastest inference speed given a certain hardware, while retaining its accuracy.
We experimented with many quantisation techniques, from quantisation aware training to post-training quantisation, to dynamic range, full integer, and float16 quantisation. The leanings we took away from the experiments is that quantisation theories might not always be fully aligned with actual deployment observation. For instance, while int8 quantisation was supposed to produce the fastest inference speed on iPhone with machine learning accelerator chip, it did not perform as fast as float16 quantisation when we deployed to iPhone 12. Also, techniques such as pruning did not work on all architectures, and using weight clustering would only decrease the model size after compression, not the tflite model size, which was not useful to our use case.
Technical Challenge 3 — Creating a Flexible Retraining Pipeline
In addition to producing a model that performs reasonably well, we also need to build a retaining pipeline so that our client can continuously collect more data and improve the model after the initial deployment. Hence, one of our priority is for the source code to be easy to read, properly documented, and experimentation can be efficient and easily tracked. To achieve this, we implemented a few tools.
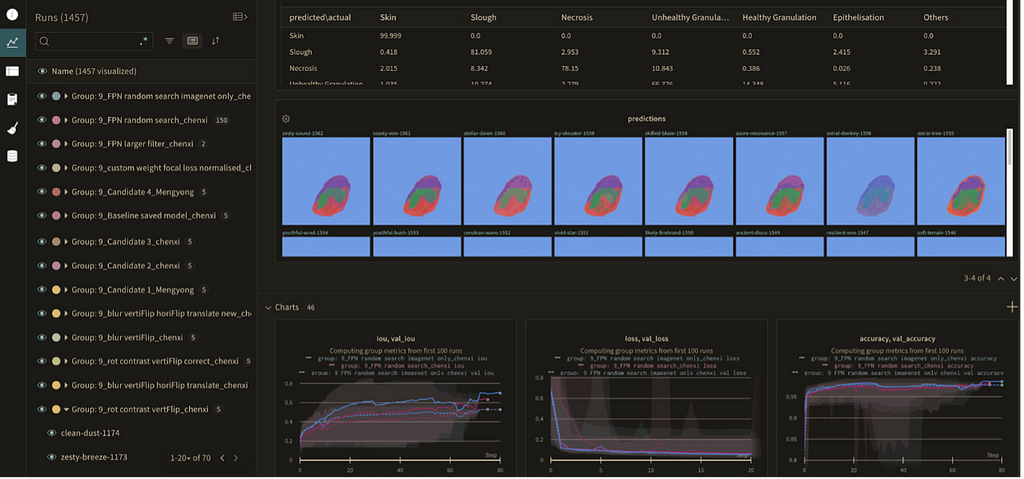
1. Experiment Tracking — WandB
We found having an experiment tracking platform very useful when working on a deep learning project. In our case, we opted for WandB as it is visually appealing, easy to use, and has a free version that we can hand over to our client after the project. Given the high number of parameters we have to tune, throughout the course of the project we ran more than a thousand experiments. Without an experiment tracking platform, it would be impossible to keep track of experiments that we had run and to compare different runs.
2. Configuration Management — Hydra
The amount of configurable parameters in a deep learning project is huge, there are configurable parameters in almost every part of the training pipeline, from data pipelines, to augmentations, model architectures, loss functions, and all the way down to the nitty gritty such as tuning the patience for early stopping. To manage the vast number of parameters, we kept all our configurations away from the source code to increase efficiency and minimise mistakes.
The way we organise our configuration is to use the Hydra library. Hydra is a framework used for elegantly configuring complex applications. It allows us to easily swap in and change configurations. For instance, as we are trying out different loss functions, we simply keep each loss function in a config file, and swap out a config file when we are trying a different loss function.
3. Hyper-parameter Search — Bayesian Optimisation
Lastly, deep learning experimentation requires iterating over a large search space of many parameters each of different magnitude. Grid search proves to be rather inefficient at doing at. Bayesian optimisation uses Bayes Theorem to direct the search in order to find the minimum or maximum of an objective function. This allows us to search a wider parameter space with way fewer runs, which speeds up our experiments tremendously.
Conclusion
After more than half a year of building the code base and intense experimentation, we were able to create a fairly accurate computer vision model that is able to classify and segment diabetic foot ulcer images.
In the upcoming months, the client company will be deploying the model for testing. Along with actual deployment, they will be able to collect more data in a feedback loop and continuously improve the data quality and quantity and continuously improve the model. With this, we hope this algorithm will help improve and save lives.
We would like to thank AI Singapore, our managers and mentors for giving us this opportunity to work on this project. Of all the key takeaways and lessons learnt, we feel the most important factor in determining the success of an AI project is management support and leadership. As such, we are truly thankful to the client company for their support and faith in us to make this project possible.
Thank you for your time reading. We wish you all the best in your AI project!
AI Engineers: Chen Xi, Mengyong Lee, Santosh Yadaw
Project Technical Mentor:: Poon Shu Han Daryl
Project Manager: Yeow Di Qiang, Ng Kim Hock
About the Authors
Chen Xi — Chen Xi graduated from NUS with a degree in statistics. He have always been keen on numbers and happy to be able to apply his technical competencies on AI solutions.
Mengyong Lee — Prior to starting his journey in Software Engineering and Artificial Intelligence, Mengyong was a project manager managing projects across regions. Today, he builds scalable production ML systems, with a focus on Computer Vision. He is most interested in the application aspect of AI.
Santosh Yadaw — Santosh graduated back in 2017 with a degree in physics from NTU. Prior to joining AI Singapore’s Apprenticeship Programme, he was working as a senior engineer in a government statutory board where he managed complex defence projects. A tinkering engineer at heart, Santosh is keen on building sustainable AI powered applications that can help to bring positive and meaningful impact.
Building a Semantics Segmentation Computer Vision Algorithm for Deployment on the Edge was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/LUx51EBcl
via RiYo Analytics






{kind=link}
{kind=link}
ليست هناك تعليقات