https://ift.tt/nETqp3INH PROBABILITY, BAYESIAN STATISTICS Evaluate & Compare models with Bayesian metrics, determine right parameters ...
PROBABILITY, BAYESIAN STATISTICS
Evaluate & Compare models with Bayesian metrics, determine right parameters with an introduction to Bayesian Modelling approach

How does the Bayesian approach differ from others ? It is based on beliefs. Beliefs about the the system we are interested in. In this article, we will explore about how to utilize this concept in model building and measuring its performance.
Pre-condition about Bayesian Model Comparison
A Machine Learning or statistical model goes through several phases of development life-cycle. One of them is measuring its accuracy. Few situations as described below create challenges there:
- Many times we don’t have sufficient training data. On top of it, keeping of a fraction of that as validation dataset may hamper the model accuracy due to data-shortage.
- For models with a problem of high training time, taking a cross-validation approach will increase it more.
- For unsupervised learning, a direct technique may not exist there to check the accuracy as the learning itself is not based on labeled dataset.
Bayesian Model comparison methods try to mitigate above problems. Not only these help to check the accuracy but also to build a model incrementally. These methods mostly work on the training data itself to handle the data shortage. But, remember, these are not exactly same as computing training accuracy on training dataset as you know. Like any other statistical technique, they try to give an approximated & alternative idea about the accuracy rather than being completely foolproof. To understand things more clearly, we will begin with a short description about Bayesian approach of model building.
Bayesian Approach of model building
We need to look at the general statement of a statistical model from a Bayesian perspective. It has two major terms : prior & posterior. A prior is the our belief about the data. It may come from the domain knowledge or previous knowledge about the system we are interested in. Non-Bayesian or frequentist approach doesn’t consider “prior” in its computation. And the “posterior” is the output we expect from the model. “Posteriors” are continuously updated and finally reach to a conclusion.
Let’s assume that a model is represented by probability distributions (in reality, it could be far more complex than a single distribution), parameter θ, random variables x as attribute and y as output. Distribution of y has θ as parameter. By Bayesian approach probability of y can be given by:
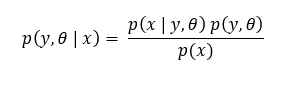
If θ is constant then joint distribution p(y,θ) will only depend on y. For example, a Normal distribution is defined by two parameters µ & σ and is denoted by N(µ, σ). If µ = 5 & σ = 10 then the distribution is simply N(5,10). Parameters are constant here. Frequentist approach doesn’t have concept of prior and it always treats parameters as constant. But what if they are not ?
Bayesian approach comes there. Parameters are also Random Variables in Bayesian settings. That means mean (µ) or standard deviation (σ) can vary for Normal Distribution. “Priors” are initial assumptions about these parameters. In the above equation p(y,θ) is a prior with the assumption about θ & y both. Basically p(y,θ) can be derived fully with only assumptions about only θ.
p(y,θ) and p(y,θ | x) are known as “prior predictive distribution” and “posterior predictive distribution” respectively. p(y,θ) can be further decomposed like below:
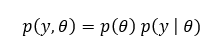
Now, it should be clear to you. Make some initial guess about θ & from there get p(θ). Practically θ can be quite complex and can represent a vector of parameters instead of a single one.
All that said, what is our objective now ? Definitely finding a good estimate of θ and with that determining predictive distribution of y. Once p(y,θ) is obtained we can get either a MAP (Maximum A Priori) i.e. Mode or a Mean of the distribution as an output. We can get it like below:
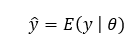
Due to these idea of priors Bayesian method offers automatic regularization and mitigates overfitting problem unlike Frequentist methods.
Maximum Likelihood Estimation (MLE) vs Bayesian Estimation
Frequentist approach uses MLE to get an estimate of θ as it does not have concept of prior & posterior. It simply maximizes likelihood function p(x | y, θ). Optimal Value of θ is given as point estimate. Different maximization techniques are there which are out of scope of this discussion.
Bayesian approach takes an iterative procedure to determine θ. It is a distribution estimate rather than a point estimate. It starts with a initial prior, computes posterior, uses the posterior estimate of θ as prior again and continues the iteration. It stops when there is no significant change in θ is observed. Iteration happens through the entire training dataset.
That’s the different at high-level between the two. Interested readers can go through in detail in a Bayesian Statistics book. Perception building for Bayesian methods takes time and of course lot of patience.
Model Evaluation
Now, let’s jump into the model evaluation & comparison part. Remember as said earlier, generally Bayesian approach of model evaluation don’t need validation dataset. We can approximate the model performance while building it itself.
Theoretically, computing the log of the posterior predictive densities of all data points gives an overall estimate of model performance. A higher value indicate better model. Let’s discuss some metrics.
Expected Log Predictive Density (ELPD)
It is a theoretical metric given by the following:
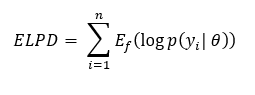
where there are n number of data points. f is the data generating distribution of the unseen data. There are two problems with it.
First, in practical situation knowing the right value of θ may not be possible if the model works as black-box to you. We don’t even know how θ influences the model from inside.
Second, we will not know f as we don’t use validation dataset.
So in practice, we can instead use a marginal distribution of p(y | θ) like below:
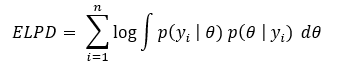
But, first problem is still not solved. We still have unknown θ. Simulation is the answer there. We can use different values of θ and do a posterior simulation. Any probabilistic programming language has support for posterior simulation. It leads to following expression for numerically computing ELPD:
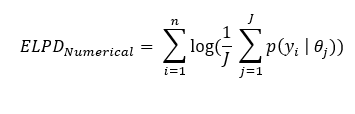
This is doable in any programming language. Remember that these n data points come from training dataset.
Information Criteria — AIC & WAIC
Measures of predictive accuracy discussed above are referred as Information Criteria. Due to convenience it is multiplied by 2 and negated. But, there is a problem. This metric suffers from overfitting as we don’t use validation dataset. One way to mitigate it is to adjust it with number of parameters used in the model for frequentist settings.
Akaike Information Criteria (AIC) is a adjusted metric for Non-Bayesian or frequentist metric. It uses MLE as point estimate. It is defined as:
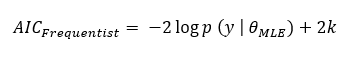
where k is the number of parameter. Lower value of AIC indicates better model.
Watanabe-Akaike Information Criteria (WAIC)
It is a Bayesian counterpart of AIC. It is defined theoretically as:
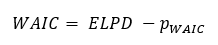
pWAIC is the correction term to avoid overfitting as discussed earlier. Theoretically pWAIC is given as:
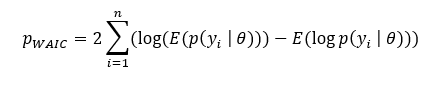
As discussed earlier numerically using simulations we can decode those expressions as we don’t know θ. The same expression then becomes:
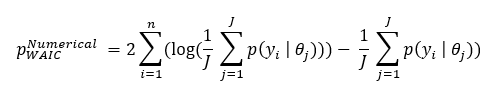
Asymptotically pWAIC converges to the number of parameters used in the model.
Ultimately WAIC becomes a Bayesian equivalent of AIC. Like AIC a lower value for WAIC indicates a better model.
Again, remember the difference: AIC conditions on a point estimate but WAIC averages over a posterior distribution.
This Bayesian Model evaluation method also helps to incrementally build the model for specific unsupervised learning use cases. It may also help in hypermeter tuning.
You really need solid fundamentals in probability & estimation methods to grasp all these concepts fully.
Note: Recently my book named “Survival Analysis with Python” from CRC Press has been published.
Link:
Bayesian Approach and Model Evaluation was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/4YgXbOJKq
via RiYo Analytics







No comments