https://ift.tt/FBWx0iRT5 Ace the System Design Interview — Distributed ID Generator 1. Introduction When you upload an image to Instagram...
Ace the System Design Interview — Distributed ID Generator
1. Introduction
When you upload an image to Instagram or make a transaction on your favorite brokerage app, the backend system assigns a unique ID (UID) to the newly created object. This ID is typically used as the primary key in some database tables and can be used to retrieve the object efficiently. I guess you know where I'm going — how do we generate UIDs?
Well, you definitely know about auto-increment primary keys in SQL. The problem of relying on this feature is obvious — it only works on a single-machine database since it involves locking and thus is not scalable. What if I need millions of UIDs per second for applications such as Slack, AWS, Youtube? In this article, I want to share with you my design of large-scale UID generators.
1.1 Requirements
When it comes to UID generation, it is essential to distinguish the two types of UIDs. Firstly, there is the random UID with no obvious semantic meanings. Secondly, there is the sequential UID with inherent information like ordering.

Random UID exfiltrates no meaningful information, thus giving it out to human is safer (client and human are different! client is code, and it would try to guess others’ URL). Given a random UID, it is hard to guess the IDs of other objects, thus offering some privacy. Videos on Youtube or links on TinyUrl are encoded this way. For instance, if I created a tinyUrl and get tinyurl.com/2p8u9m2d, it's hard for me to guess other newly created URLs (in fact, tinyurl.com/2p8u9m3d or tinyurl.com/2p8u9m2c does not exist).
Sequential UID has its own merits. Its inherent meaning helps applications organize data. For instance, it makes sense to give out sequential UIDs to chat messages in Slack/images in Instagram because we want to preserve item ordering. In addition, if the UIDs are not exposed to humans, it's totally fine to use sequential UIDs even though the inherent order is not used.
In this article, I will focus on sequential UIDs because most million-WPS-level applications do not give out UIDs to humans. Below are the core functional requirements of the system:
- Capable of generating ten million sequential UIDs per second
- UIDs must preserve some level of ordering information
- capable of adjusting generation rate based on consumption
Needless to say, the system should be scalable and highly available.
2. High-level Design
Normally in a system design interview, I'd start with access patterns and database schema. However, our system does not need any database support, which I'll show you in a bit. The whole system is almost stateless; if a generator crashes, it's OK to reboot another one and start fresh.
2.1 API Design
Our UID generator has only a single purpose — serving fresh UIDs to whoever needs them. Hence, it only needs the following client-facing RPC interface:
get_uid_batch(batch_size: int) -> List[int64]
To minimize communication overheads, the client fetches a batch of UIDs every ~100ms and caches the UIDs in memory. The local UIDs are lost if the client crashes, which is perfectly fine since we have plenty to waste.
2.2 High-level Architecture
- Since the application is tasked to generate millions of UIDs every second, we need many computers working concurrently to meet the demand.
- We need some kind of cluster manager that monitors node health and workload. If the demand exceeds supply, the manager will add more workers.
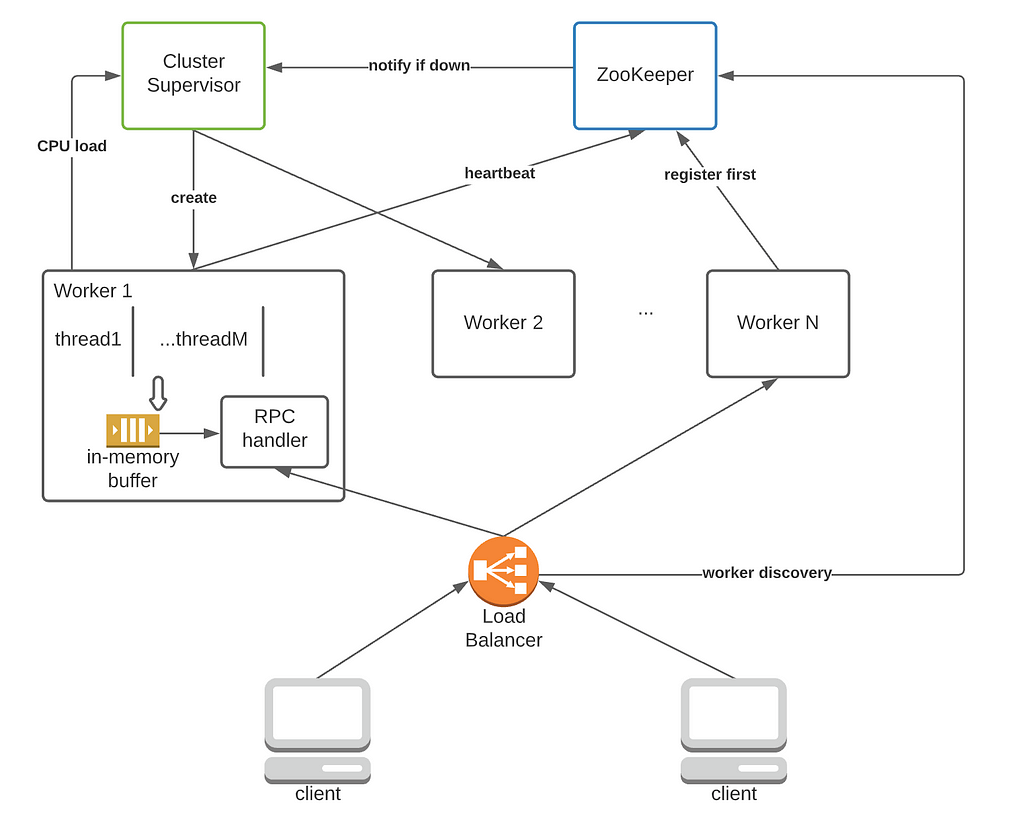
2.3 Control Logic
- Starts up a ZooKeeper service and a cluster supervisor. In practice, the supervisor can be replaced by build-in features of software such as Kubernetes that auto-scales containers.
- The cluster supervisor creates N workers by default.
- When a worker is created, it registers with ZooKeeper and obtains a unique worker ID (simple integers, e.g., from 0 to 256).
- Each worker corresponds to an ephemeral znode on ZooKeeper. When a worker dies, its znode will be deleted, and ZooKeeper will notify the supervisor.
- All workers regularly send their CPU load to the cluster manager. The manager removes/adds workers to meet the consumption rate best.
3. Details
3.1 UID Decomposition
So far, our discussion has focused on high-level features such as API and architecture. In this section, we need to finalize the UID format. How long should it be? What information does it capture?
UID Length
The UID length is determined by the application and its storage needs. We assume that the external service consumes up to 10 million UIDs per second. Let's examine how long it takes to exhaust UIDs with different lengths:
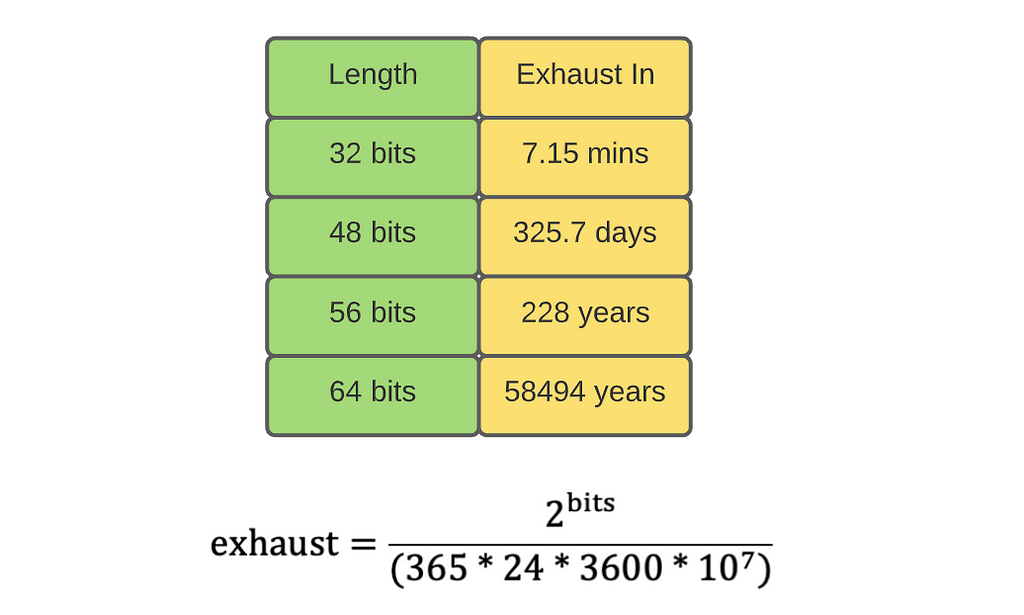
Obviously, we need at least 56 bits so that the application never runs out of fresh UIDs during its life span.
UID Timestamp
We want the UID to be sortable, so a part of it must be some sort of timestamp. For our application, it's enough to keep the timestamp at millisecond granularity. A good starting point is the UNIX timestamp. However, it has 64 bits, too long for our application. To get around this issue, we could establish a custom epoch (instead of the epoch UNIX timestamp uses, 1970/1/1 0:0:0) and count the number of milliseconds passed.

So, how many bits should be used to store the timestamp? Figure 5 shows the overflow time of different timestamp sizes:
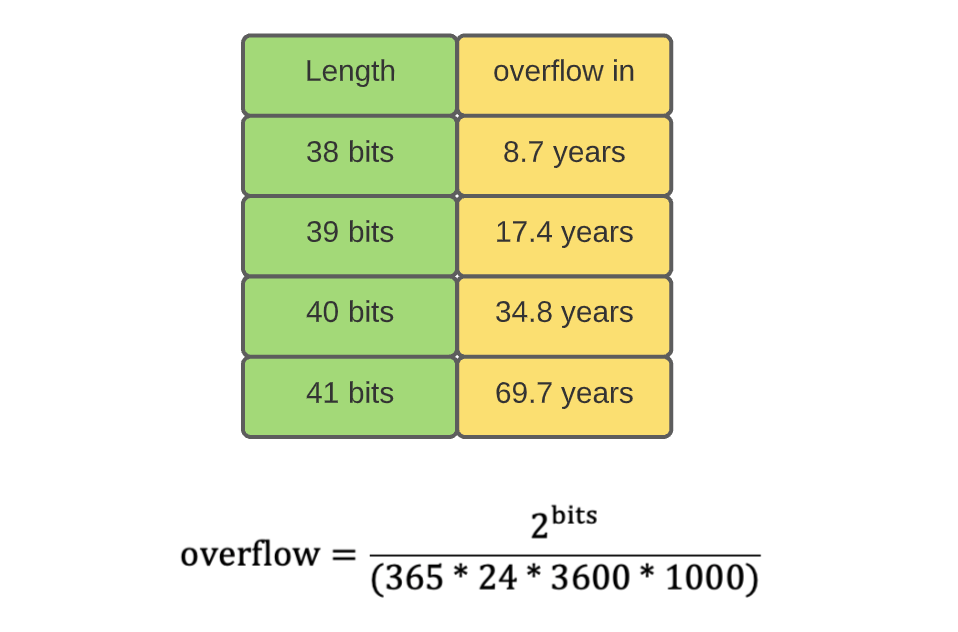
Assuming the project life span is 20 years, we are safe with 40 bits.
UID Additional Information
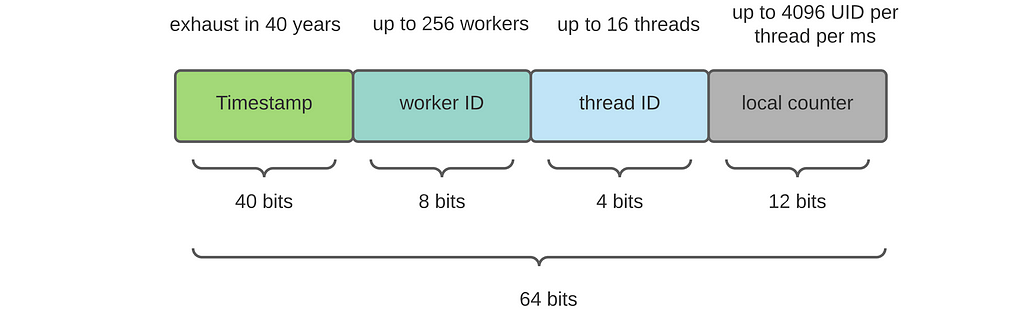
It's tempting to stop here and be done with our UID design. However, no matter how precise the timestamp is, there's nothing in place that prevents UID collisions. It is possible that two computers generate two UIDs with identical timestamps. To distinguish UIDs generated simultaneously, we must throw in new information. Below is my proposal, based on popular designs (Twitter Snowflake)used in practice:
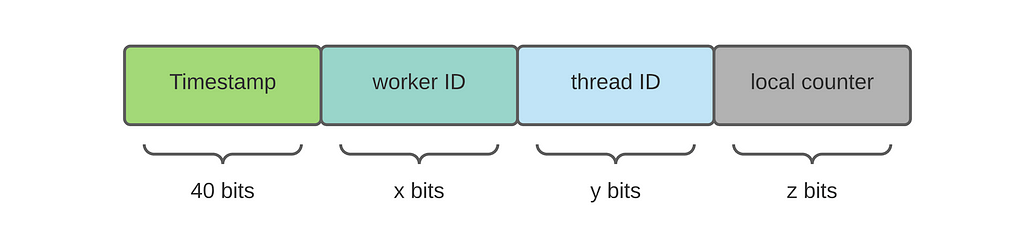
- Worker ID: we can use the unique worker ID assigned to each computer for distinction. The number of bits is determined by the maximum number of workers in the cluster.
- Thread ID: To maximize throughput, multi-threading is used to leverage the parallelism offered by modern multi-core CPU machines. Why not process ID? Inter-process communication is more expensive, we want to put all generated ID into a shared in-memory buffer that can be accessed by the RPC thread.
- Local counter: even on a 20-year-old computer, a single thread can generate two timestamps in one millisecond. Hence, we need a local counter that further distinguishes two UIDs. When the counter is full, the thread goes to sleep throughout the current millisecond.
I did a simple experiment on my laptop, a 2019 MacBook pro with six cores. Here's the throughput I achieved (code here):
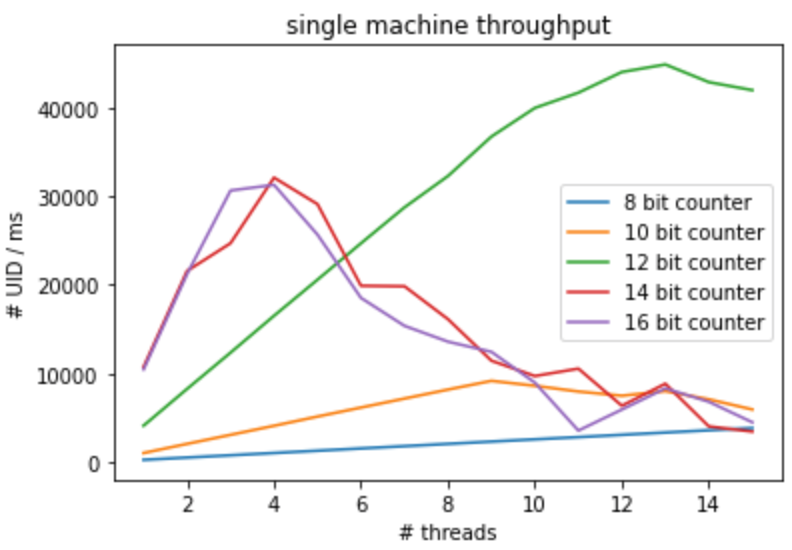
Without running an RPC server and other heavy stuff, my laptop can achieve ~40K UIDs per million seconds. The throughput in an ideal sandbox is surprisingly high, and I assume the performance only degrades in practice. With an educated guess, assume a computer can generate 5K UIDs/ms. To achieve 10million UIDs/s, we need a shy of two computers. Of course, in practice, we might need a lot more.
Now, put everything together, the peak performance (for my laptop) is achieved with 13 threads (4 bits), each with 12 bits of the local counter. Excluding the worker ID, we need at least 56 bits in our UIDs. Hence, it's a good idea to use 64 bits UIDs.
3.2 Why not queues
Some of you might be wondering if it's a good idea to use a dedicated queue to decouple external services from this ID generation system. A possible architecture looks like this:
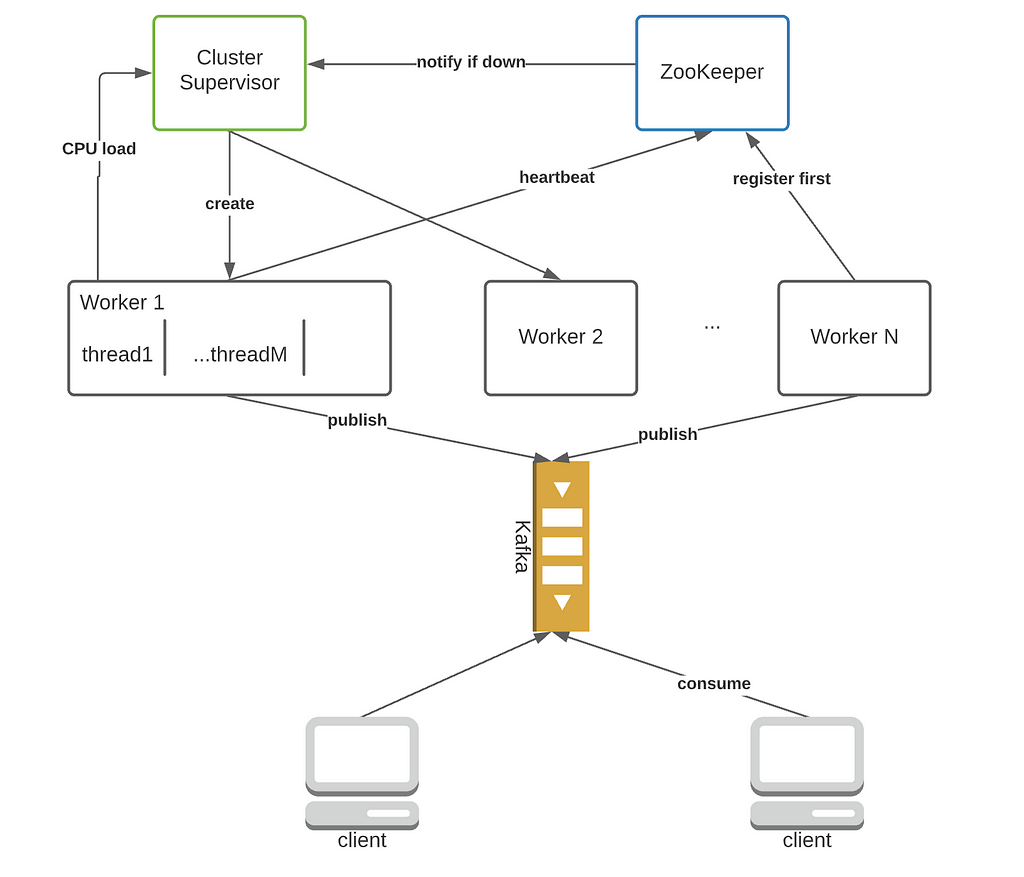
Middleware service like Kafka offers nice features such as decoupling, buffering, retries, and a simple interface. However, none of these features are needed in this application. We don't need to buffer excess UIDs since they can be discarded. The system has the simplest RPC interface I can imagine, which makes Kafka's interface look like rocket science. With Kafka, the number of consumers is limited by the number of partitions, which is inconvenient.
Among all reasons against queue, here's the most important one that convinced me RPC is better. Some queues don't disclose the number of messages buffered, making it impossible for our service to ramp up/decrease capacity when the demand goes up/down. With RPCs, it is much easier for the cluster supervisor to monitor the overall workloads. If no one uses UIDs, some workers will be terminated to save money.
4. Summary
In this post, we designed a distributed sequential UID generator with insane throughput. We dived deep into the technical tradeoffs between various approaches. In an interview, there's no best answer. All solutions have merits and flaws; our job is to evaluate each of them and make the most reasonable tradeoffs given the constraints given by the interviewers.
Also, happy year of the Tiger to everyone who celebrates lunar new year!
Ace the System Design Interview — Distributed ID Generator was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/9re87XGQS
via RiYo Analytics






No comments