https://ift.tt/ZLeFftE How shape detection drives classification Each cortical column contains both place cells and grid cells used to cl...
How shape detection drives classification
In April of 2021, the renowned technologist, entrepreneur, and brain theorist Jeff Hawkins published his new book A Thousand Brains. This book described Jeff’s A Thousand Brains Theory of the architecture of the human neocortex. In this blog, I will review this architecture and discuss its implications on the long-term architecture of Enterprise-scale Knowledge Graphs (EKGs).
This article is part of a series of articles on how EKGs are becoming part of organizations’ Central Nervous System (CNS). Like our own CNS, EKG can quickly react to signals in the environment and get the proper notifications to the right people at the right time.
The central observation here is that our brains have evolved to help us move through the world. EKGs don’t move in the world themselves, but they need to track the motion of customers, products, and ideas through our organizations, and they need to notify the right people when this motion needs correction.
Background on Jeff Hawkins

For the past 15 years, Jeff Hawkins has been one of the most influential thinkers in AI. Jeff’s 2007 book, On Intelligence, was one of the first books to lay out an overall architecture of the human brain, focusing on the layered structure of the neocortex. Jeff strongly feels that you can’t understand AI without understanding the human brain. He has also helped us understand that the hardest part of AI is almost always the challenge of knowledge representation. Machine Learning has made considerable strides in the last ten years to train neural networks, but its strength is seeing patterns in data, not understanding the world around us. After reading Jeff’s books, you will realize that if we don’t know how to represent the results of a classification in computer memory and how to generalize, we are not solving the real problems of AI. We can recognize items, but we don’t understand the item’s relevance in the context of the other items around our classified items.
My favorite quote of Jeff Hawkins is the following:
“The key to artificial intelligence has always been the representation.”
This viewpoint, which I have shared since my graduate school work in AI in the 1980s, is why I have focused on RDF, NoSQL, and now EKGs.
Key Aspects of the Thousand Brains Architecture
Although I will not cover all the aspects of the Thousand Brains theory in this blog, I want to point out some critical theory elements that might help us focus on our EKG architectures. To be clear, EKGs are not like our brains any more than planes are like birds, or submarines are like fish. We use brains to understand intelligence and how our EKGs can be more intelligent. EKGs are brain-inspired, but the architecture of a modern EKG is radically different from human brains.
The Thousand Brains Theory attempts to understand the high-level structure of the human neocortex. The theory postulates the following key points:
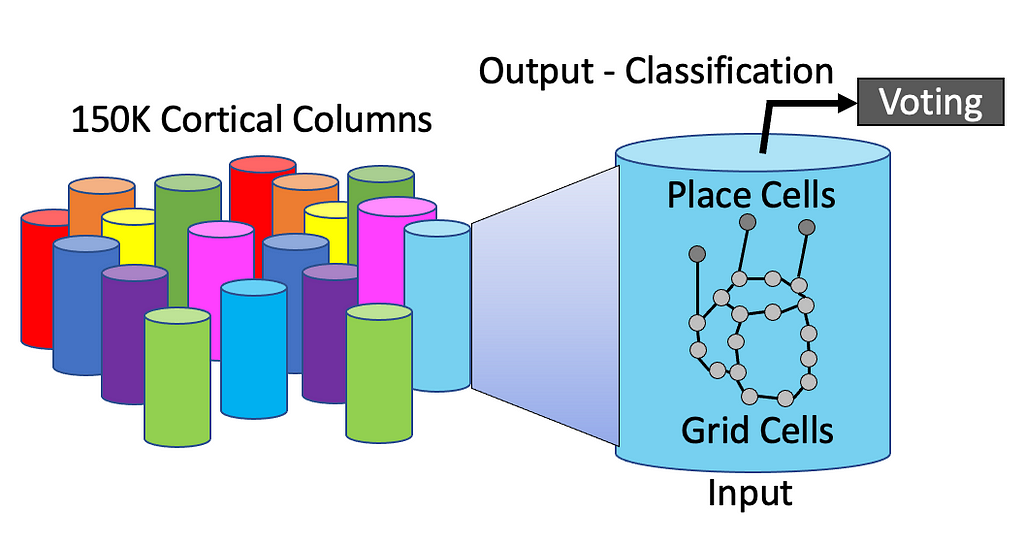
- The human neocortex is composed of around 150,000 cortical columns. Each column contains hundreds of millions of neurons that read input signals and generate higher-level classifications of the inputs. Cortical columns are also, in turn, composed of mini-columns, each having hundreds of neurons.
- Each column comprises two types of cells: grid cells and place cells. These cells evolved from early animals to help them navigate around their world.
- Grid cells and place cells work together to classify inputs by recognizing the shape and structure of inputs. Cortical columns are neural networks that constantly evolve to transform input data into useful representational structures.
- The output of classification is a linkage to one or more reference frames. You can image reference frames as abstract wireframe drawings that describe the structure of items in our world. Understanding what reference frames are and how they are connected to other things is a central question in intelligence.
- The classification process is highly distributed across many cortical columns. Each cortical column works with other columns to “vote” on their beliefs and how the input should be classified. Learning is essentially the process of continually tuning the weights on these voting systems.
One of the key aspects of the Thousand Brains structure is how grid cells and place cells work. Here is a quick description of these cells
Grid Cells
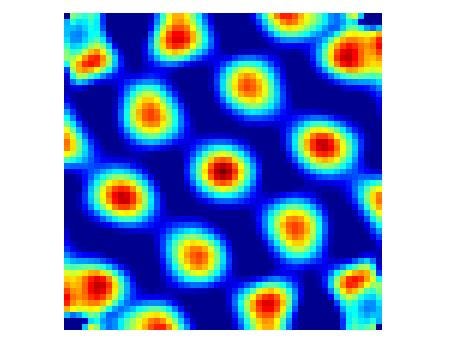
Grid cells are cells that help you find your relative location in the world. They evolved when cells first started to move around in their environment. Since plants don’t move around much, they didn’t evolve these brain structures. Moving animals needed to develop a sense of where they were in relation to their resources. They needed to move toward their food and away from hostile conditions, including their enemies. Grid cells connect to make “maps” or models of the world around us. They connect to specific items in their world through another cell called place cells.
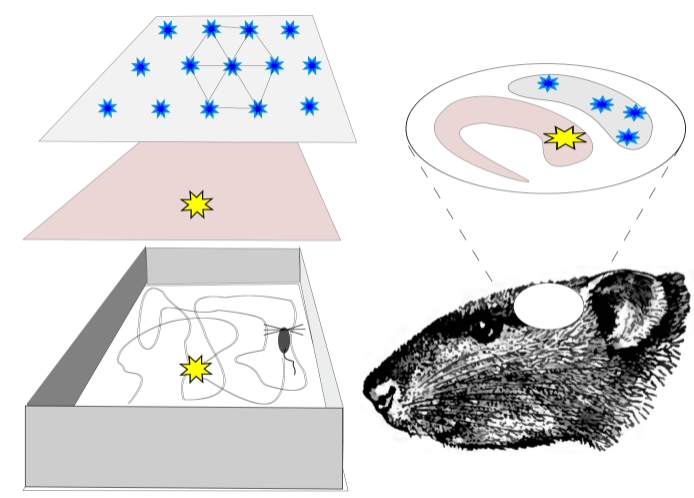
Place cells are cells that fire when you are at a specific location in your environment. They connect the maps of your world to things in your world. They might signal, “hey, there is food here” or “danger lurks at this place.”
These primitive cells work together to tell animals where they were in a fixed static map of their world. If their world changed, they would need to build a new map.
How Our Brains Evolved to Use Efficient Dynamic Maps
Building a new map next to an old map is pretty straightforward. You need to link the old map to the new map. Our brains jump between maps whenever we walk through a door from one room to the next. But what if your environment has structures in the old map and new map that were similar? For example, what if the old map and the new map had a similar food source, such as a plant that you could eat? Animals naturally evolved ways to minimize the work they needed to do to build new maps by reconnecting parts of new maps to old maps.
In computer science, we often call this trick “Composability.” Can we take a lot of duplicate-but-similar business rules and relink them together in the upper level of an ontology so that there is less duplication? Composability makes it easier for our ontologists to maintain these rules.
But before the brain could link similar structures together, it had to master something complicated. It has to learn how to recognize that shapes are similar and could be linked together. Distinct shapes are merged to be one more abstract shape. The generalization of these shapes is a reference frame. We use reference frames to learn how to generalize. And our brains “learn” by linking similar items together to keep their brains efficient. Very few animals have mastered this trick, which is the hallmark of intelligence. It is the representation of abstraction that is key to intelligence.
Animals might start by recognizing fixed items in their maps and connecting them to the same abstract item representations. But what if the items move around? The brain now needs to recognize items even if they have different structures around them. The item recognizers need to become context-aware. If they are vision cells, they classify the item even with different lighting and orientation. When graphs need to look for the invariant structure, we call these queries isomorphic queries.
When I think of isomorphic queries, I think of queries that recognize the abstract shape of things and can compare these shapes to a known database of shapes. This is analogous to how reference frames work. They are fixed libraries of structures to which we can create links in our brains.
Now let’s inventory the pieces that we use to build our EKGs and look for similarities between the functions in the Thousand Brains Theory.
Vertices, Embeddings, and Rules
When we build an EKG, we don’t have a concept of a cortical column stored within the EKG. Since cortical columns have been replicated from early brain structures to help animals navigate their environment, this is no surprise. However, EKGs are evolving quickly, and we see many diverse types of subgraphs with specialized functions.
Like neurons, we have vertices and edges that we use to traverse our EKG. Vertices with their attributes also have evolved from their humble origins of punchcards that filled flat files with their columns. Along the way, the relationships between our vertices, called edges, also evolved their attributes.
Along with the knowledge about our key business entities (customers, touchpoints, products, servers, etc.), we can also store knowledge about how similar items are related in our graphs. These “similarity” vectors are called embeddings. Although they are new, embeddings can be used in similar ways that cortical columns are used. Embeddings are the key to fast similarity, classification, and recommendation. Classification asks the question — how is this item similar to other things we have seen in the past? We can take any new item, find its embedding and do a distance calculation to labeled items in our graph. The key is to use parallel compute hardware like FPGAs to do these calculations in near-real-time (under 50 milliseconds).
Once we have new data classified, we can add attributes, create new links, and execute functions that notify the right people at the right time.
Although there are many other conclusions of the Thousand Brains theory, I want to focus on how this theory might impact how we build EKGs and how machine learning needs to be integrated into EKGs for use to reach the level of intelligence we need in our enterprise databases.
We want to pause and think about the types of queries that we run over our enterprise knowledge graphs. There are many subtypes of queries:
- Queries that find items in our graphs (e.g., breadth-first search, depth-first search).
- Queries that look for paths between items (pathfinding).
- Queries that look for clusters of items (centrality).
- Queries that look for similar items (similar products in a product graph, similar items in an interest graph, similar patients in a healthcare graph).
- Queries that look for similar shapes (isomorphic queries) and compare them with reference patterns (reference frames).
- Queries that execute deterministic business rules in structures such as graph-based decision trees. This is where ontologies come in handy.
Note that these algorithms can and do work together. You might write a depth-first search that looks for items connected to similar shapes. You can then find a path between the two shapes. You can also link similar shapes together with a new link.
How Place and Grid Cells Became Classifiers
Jeff and his team were asking how grid and place cells, which have been in animals’ brains for hundreds of millions of years, evolve to solve complex problems like image recognition, sound recognition, and danger prediction? Jeff’s theory is that these cells can be repurposed to recognize the structure of things that move around our world. We can identify the structure of emotions, thoughts, sounds, words, theories, and any ideas composed of other previously unrelated ideas. And these structures have become increasingly abstract as we evolved.
All 150,000 of the cortical columns in our brains are essentially classifier circuits. They all read from their inputs and send signals to their outputs, and indicate what reference frames should be considered for the voting process. Although we thought of these as strict hierarchies in the past, we now know that signals move both up and down the abstraction hierarchies to help us focus our attention on areas that we need to as the classification of an item comes into focus.
The Implication for EKGs as our Companies’ Central Nervous System
In my prior blogs, I discussed how EKGs are slowly evolving to take on additional tasks that allow business users to react to changes quickly. Any vertices or edges that are added, updated, or deleted could trigger rules that are also implemented as decision trees within the graph. There is no longer any need to move millions of bytes of data into an external rule engine. Everything can execute as fast pointer hops within our EKG.
The Thousand Brains theory has helped me understand how our EKGs will evolve in the next few years. Visualizing how animals evolved place and grid cells also helped me visualize EKG evolution.
The secret to cost-effective knowledge graphs is to continuously scan for new patterns in our graphs to help us do what cortical columns do: continually see what changes have happened and leverage shared rules within our graphs to reclassify and enrich our information. These rules also need to be continually scanned to look for patterns that increase the composability of our rules. Rules need to evolve to continually be more efficient, use less power and be more compact. For more on how modern rules work in EKGs, see my blog on Rules for Knowledge Graph Rules.
The Role of Graph Machine Learning
The challenge we face is that as the number of rules in our pattern-recognition decision trees grows, they become more complex and harder to manage. This is where machine learning will become ever more critical. Graph-Machine-Learning libraries like the popular PyTorch Geometric have only been around for a few years and are often driven by small teams. They are not yet easy to integrate into our production billion-vertex graphs without moving a lot of data around.
My firm belief is that as these libraries mature and become coded in open standards such as GQL, all enterprise-scale distributed graph database vendors will provide them as part of their out-of-the-box solution.
The Role Testing and Humans-In-The-Loop
Before we jump off the deep end of having machine learning automatically be shuffling our ontologies and decision-tree rules around, we want to emphasize that for machine-learning driven processes, explainability, interpretability, transparency, and human-managed regression testing are critical values for quality control in our knowledge graphs. Ontologies can quickly become unstable, especially when high-level ontology structures are changed. Fortunately, machine learning can also classify the impact of ontology changes and even recommend new regression tests.
Conclusion
The Thousand Brains theory has triggered a giant leap in my ability to visualize the evolution of EKGs. There are still many unknowns. Getting low-cost full custom ASICs optimized for graph traversal is still uncertain. Although I am still hoping this hardware will give us another 1,000x performance improvement over the current state-of-the-art distributed graph databases, there may still be many areas the software and hardware will need to be tuned. Let me close by saying 2022 could be a very good year for EKGs.
A Thousand Brains and the EKG was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/CBYwJ9I
via RiYo Analytics







{kind=link}
{kind=link}
No comments