https://ift.tt/cVn0MtF How I used batch normalization to get a 20% improvement on my eye-tracker during inference Photo by Diego PH on ...
How I used batch normalization to get a 20% improvement on my eye-tracker during inference

Batch normalization is essential for every modern deep learning algorithm. Normalizing output features before passing them on to the next layer stabilizes the training of large neural networks. Of course, that’s not news to anyone interested in deep learning. But did you know that, for some use cases, batch normalization significantly improves testing and inference as well?
In this article, I want to present a successful experiment that I tried while building a deep learning algorithm for eye-tracking. Perhaps this is a well-known technique, but I haven’t seen it anywhere myself. Feel free to provide examples if you have some.
When using model.train() instead of model.eval() for evaluation, I improved my score on the test dataset by 20%. My colleagues got the same result when running similar experiments. But for this to make any sense, let me explain what I wanted to build.
Warning: My use-cases analyze the faces and eyes of people. I collected data from 30 people, so it fails to represent everyone. Consequently, I would get worse performance for individuals with a different skin- or eye color. Since this was just an experiment for my entertainment, I didn’t address challenges related to biased datasets. However, if I want to take this further, inclusion would be on top of my mind. That means both collecting data representing as many as possible, and, if necessary, considering that information when sampling training data.
Explaining the use case

My goal was to create an algorithm for webcam-based eye-tracking. In other words, I want to take a picture with the webcam and predict the user’s point of attention on the screen. There are already open-source source alternatives, but I wanted to see if deep learning could remove some of the issues with current solutions:
- Calibration — The solutions I’ve tested require calibration to work correctly. You must look at the screen and follow a moving object, usually without moving your head.
- Fixed eye-position — After calibration, it’s critical that you don’t move the position of your eyes. That’s a challenge if you’re participating in some survey where you need to watch a longer video.
- Sensitive — Apart from the position of your eyes, they’re also susceptible to other changes. Some examples are lighting and distance to the monitor.
The idea is that a deep learning algorithm learns more complex patterns and could be less sensitive to head movement and other changes in the webcam images. How to remove calibration is less obvious, but I had some ideas.
Challenges with deep learning
Many eye-trackers must work in real-time and run locally. That’s difficult to achieve with deep learning since the algorithms require more computation than traditional methods.
Collecting training data
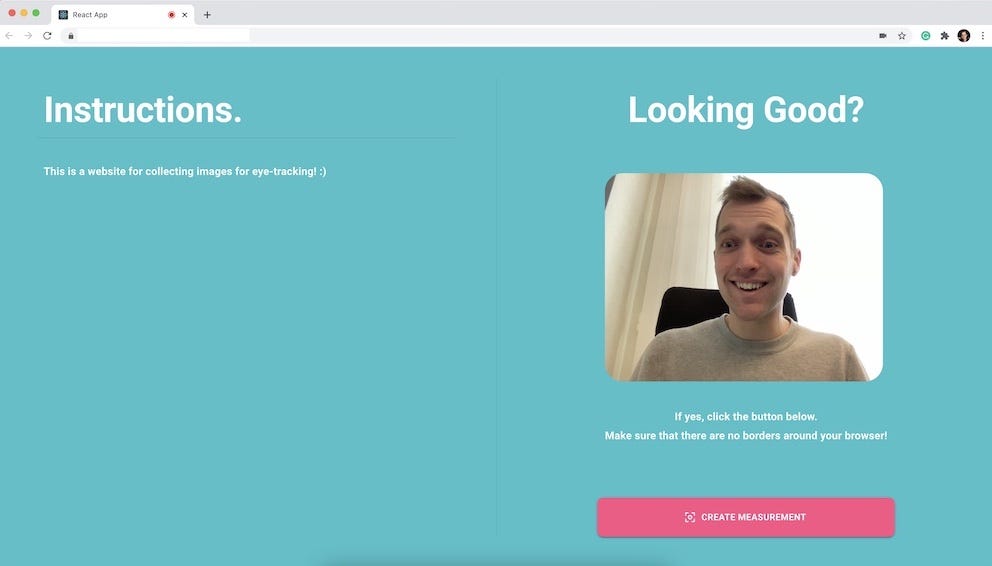
To train a deep learning algorithm for eye-tracking, I needed to collect training data. That’s why my first step was to build a react application and ask my friends to contribute.
Measurements
When someone logged in to my application, I asked that person to create what I called a “Measurement”. It’s a simple process that works as follows:
- First, I make sure that the application is in full-screen mode and ask the user to ensure that there are no borders around the browser.
- Next, I generate a dot in a random location on the screen.
- The user looks at the dot and hits space.
- I take a photo with the webcam, which I save together with the coordinates for the dot. I divide the coordinates by the size of the screen.
- I repeat steps 2–5 one hundred times.
So, one measurement contains 100 pictures taken with the user’s webcam combined with the associated dot coordinates. The dots have different colors and sizes during the measurement, but I don’t know if that matters. Probably not.
Additional instructions
I instructed participants to behave as they usually do when sitting at their computers. I didn’t want them to sit completely still and encouraged both head and eye movement as well as facial expressions. That way I can train an algorithm that is less sensitive to movement.

Also, I wanted people to make more significant changes from one measurement to another. For example, switching locations, changing clothes, adding accessories, etc. Like I did in the images below!

Most eye-trackers only look at the eyes, but I wanted my algorithm to analyze the entire image. There’s certainly a lot of unnecessary information, but that’s easy for the algorithm to figure out on its own.
Amount of data and variation
In total, I collected 2–5 measurements from 30 people. That’s somewhere around 12,000 images in total. Not a lot for a deep learning algorithm, but it’s enough to start experimenting.
Setting aside data for validation
One common mistake among novice machine learning engineers is to split the dataset in a way that doesn’t represent reality. A lousy approach would be splitting the 12,000 images at random into train, validation, and test. It yields fantastic results on paper but horrible results in production.
Instead, I divided the dataset by person to know how well the algorithm works when someone unfamiliar appears. I also set aside some measurements from the people in training to measure performance for familiar people.
Pre-processing of images
The only changes I made to the input images during training were to turn them into squares by cropping away some information on the sides. It’s easy for the algorithm to learn that the background is irrelevant since it doesn’t change much during a measurement.
About batch normalization

Most of you know everything there is to know about batch normalization, but I’ll provide a short explanation for context. Feel free to skip this part if you don’t need it.
Purpose of batch normalization
When you train a deep learning algorithm, you give it “batches” of data points. For my eye-tracker, that means several images of people looking at their screen together with coordinates for the associated dot.
Batch normalization takes the output from one layer in your algorithm and normalizes them before passing it on to the next layer. It leads to more stable training. If you want to learn more about batch normalization, here’s a fantastic article on Towards Data Science:
Batch Norm Explained Visually — How it works, and why neural networks need it
Training vs. Validation
What’s important to understand here is that each batch normalization layer calculates the mean and variance for every batch of data points during training.
There are also two parameters for each batch normalization layer where they store the moving average for both mean and variance. Then, when it’s time for validation, we use the stored values instead of performing the calculation.
In PyTorch, model.eval() and model.train() change the behavior of layers like batch normalization and dropout.
Time for the novelty!

For each experiment, I used a simple U-net architecture with a Efficientnet backbone. That’s just one line of code with a popular repository like segmentation_models. The only thing I changed from the baseline and my most successful solution was the training process.
About the baseline
Whenever you work on a machine learning use case, you need a baseline algorithm for comparison. I trained my standard U-Net in the simplest way possible. For each batch, I selected 32 random images from random measurements. The algorithm won’t learn anything resembling calibration with that approach, but it’s a logical start.
After training, the baseline performed surprisingly well. It had an average error of 9.5% which is similar to the open-source alternatives I tried earlier. The error is the distance between the prediction and the correct coordinate expressed as a percentage of the screen size.
Approaches that didn’t work
Next, I started thinking about how to incorporate calibration into the algorithm. Here are two approaches that didn’t work so well for me:
- Giving the algorithm several images at once from one measurement by stacking them in the channel dimension.
- Training a recurrent algorithm that looks at a sequence of images and considers previous information from the measurement.
I didn’t spend that much energy and time on any of them. Perhaps, one of them would work with more effort. But my next experiment was more straightforward.
Time for batch normalization
Instead of constructing data points with additional information, I wanted to use batch normalization as a mechanism to capture the relationship between images from the same measurement. To test my idea, I changed two things:
- Training batches — For each training batch, I only added images from a single measurement. Each measurement has 100 images and I selected 32 of them at random.
- Evaluation — During the evaluation, I kept the algorithm in training mode which means that batch normalization continues to calculate mean and variance instead of using the stored averages.
The idea was that if each batch only contained images from one measurement and person, batch normalization could work as a form of calibration. Normalizing features between layers should then help the algorithm to extract information such as eye position, head movement, etc.
If I ran model.eval() and measured the algorithm on my test data, it didn’t work at all. However, if kept it in training mode, my distance error was an astonishing 7.2% for the test set with unfamiliar people, and 6.0% for unfamiliar measurements. The results for the baseline were 9.5% and 8.4%.
What if you only have one image
It doesn’t work if you only have one image during inference since batch normalization can’t calculate mean and variance. However, one approach is to store moving averages for specific users besides the rest of the weights. And, sometimes, you can save a webcam recording and run the algorithm over all frames.
More training data
The best way to improve the solution is to add more training data. I only had measurements from 30 people, but it’s easy to collect more.
Summary
I used batch normalization as a mechanism to capture the relationship between images from the same domain — both during training and validation.
If you have ideas of other use-cases where the same approach could work, leave a comment.
Thanks for reading! :)
A Novel Way to Use Batch Normalization was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/SlBnrI3
via RiYo Analytics






ليست هناك تعليقات