https://ift.tt/3niE9VQ A summary of years of experience that might help you save time Photo by Patrick Tomasso on Unsplash Don’t just...
A summary of years of experience that might help you save time

Don’t just learn, experience.
Don’t just read, absorb.
Roy T. Bennett, The Light in the Heart
Introduction
First, a disclaimer: what works for some, does not necessarily work for others. In this article, I expose what worked for me after I spent years reading academic papers, books, and source codes related to Reinforcement Learning.
Some readers might find it, useful others might not, but the important is that by sharing, I believe I might be helping some or a few who are having a hard time entering RL.
This article will not guarantee that you will go out and understand every book or paper on RL, but it will give you a methodology that might (as in my case) alleviate the process of learning.
The article starts with some basic behavior, things that we used to do a lot at school but since the widespread of online learning, it has become less and less a reflex.
Basic reflex: take notes
If you don’t remember what you used to do in school, well, it is time to do it: Take notes.
Although a very obvious and natural thing to do at school, however in the age of online and video learning this basic behavior is often overlooked!
Put a sheet of paper next to you and write down all definitions or important formulas that you encounter while reading or watching. Believe me, you don’t want to pass your time scrolling up and down to remember what was that symbol or what does this term means.
Unless you have a photographic memory, you can bet that you won’t remember definitions a few pages down the road. Even worse, you might not completely understand the definition, so what you see later might contradict your own understanding, and you would need to check it again to make sure you get the intended meaning. For this reason, having this paper next to you will spare you too much time.
You should take a pen and a paper and write down what you understood and don’t simply copy them.
Most importantly don’t copy-paste them into another document because you won’t be doing yourself any favor.
Furthermore, this paper will serve you as a cheat sheet for later usage, when you want to quickly refresh your memory about the algorithm instead of reading tens of pages all over again.
Another basic reflex: practice
One more thing that is very common at school, and is somehow lost at the age of online learning, is practice.
There are plenty of ways to practice, but the one that is the less effective is to adopt the strategy of “fake it until you make it”! What I mean by that is to “unintelligently” copy the code (or download it from Github) and run it, without trying to understand the concept behind it, nor the code itself. It does not really work if you have no idea what you are doing. Not to mention that if you try to sell your skills based on this strategy it will backfire as soon as people notice that you don’t really understand your own solutions! This will weaken their confidence in you. Memorizing the methods or the algorithms is not enough, what is needed is to be able to understand what they are, and why.
If sometimes you have to modify the implementation, you will need to understand the implication, and of course, to be able to interpret the results and know the boundaries of the algorithm.
So practicing involves understanding each component of the algorithm, comprehending the code, then extensively testing and debugging it.
Start with vanilla Reinforcement Learning
Deep RL is appealing, and you might be tempted to directly jump into the water and start swimming. Usually, this is due to some online courses selling you dreams. But this is not the right approach (in my opinion, of course).
Start with tabular methods and keep doing them until they become organic to your thinking. Because there is no meaning in going further if you don’t understand what Q-Learning is and what it represents.
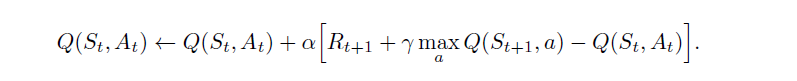
For this matter, check DeepMind’s or David Silver’s Youtube courses. Then, do all the tabular RL first, repeat them as long as necessary.
Handle complexity added by the “Deep”
Adding the neural networks to RL algorithms increases their complexity since there is a new component to feed and train. However, putting aside their technical particularities, they are inserted to accomplish two main tasks.
So one way to reduce the complexity is to think abstractly.
Think of a neural network as a black box with two features:
- If given input it produces output that is not as accurate as you hope, which leads to the next point.
- It can update its inner parameters to “hopefully” make a better (more accurate) output for the same input.
In other words, borrow from the tabular method, the concept of tables, but a very huge one that needs ridiculously gigantic memory. With such fictitious memory, you can fit in all possible (millions or billions) states and actions, so that for each state you map State value and Action values.
But since you already know that this is not possible in reality, replace it with something that takes far less memory but instead gives you less accurate results so for example instead of the expected value 1, you get something like 0.85, 0.90, 1.10, or 1.20
In the example above the approximation is still acceptable, but this is rarely the case. Approximation starts very inaccurately, wild random numbers then become more and more accurate with the iterations.
So when you encounter a neural network in a scientific paper, don’t get bogged down with the details, just imagine it as a black box that can give approximation which (in theory) gets better by the time through the learning process.
Consider this Deep Counter Factual Regret Minimization algorithm.
Directly you might feel unease with the cryptic symbols and expressions related to neural networks.

But you can read them like this:

Such interpretation makes it easier for you to understand and alleviate the complexity embedded in the algorithm. You are now talking about an update (that lots of people, especially developers easily understand) of the Black Box.
Once you understand the algorithm very well, you can implement it and view the Black Box as calls to special functions (coded separately) that do the neural network.
Create graphs
Making graphs and sketches out of the algorithm is one way to reduce complexity and identify its components and their relation to each other. Instead of remembering a whole bunch of lines, you can visualize each component alone and the flow of activity or info that connects it to others.
With this mental (or concrete) representation, it would be easy to derive the code for the algorithm.
Below is the graph of Deep Q-Network algorithm, which you will have a far easier time understanding and memorize it, than a collection of code or pseudo-code.
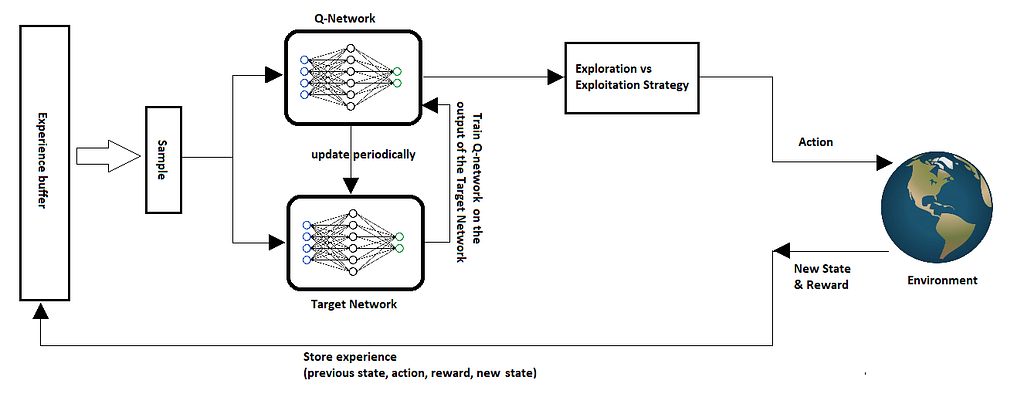
Notice how each component is very clear and dissociated from the others which makes it easy for you to reason about. You can even try to pull one component and replace it with a different, potentially better, one to measure performance.
Rubber duck method

Finally, when you think you are ready, find someone to tell/teach them what you have learned, preferably friends who share with you that passion.
At that moment you can be put to the test if you have really mastered the material or not. Your friends will ask you questions and challenge your knowledge, which will make you think more about what you know and what you understand.
The other method is to tell it to your rubber duck. This method comes from rubber duck debugging and I can assure you that it works. It might surprise you how many times a problem is solved when you tell others including a rubber duck about it since you force yourself to listen to what you are saying. So if you have no one to explain the algorithm to, just explain it to yourself or your duck using a loud voice so that you can hear yourself clearly.
Finally, blog or vlog (video log) about it. It doesn't matter how many times others have done it before you. Put your knowledge out there and try to get feedback and questions on which you can reflect and enhance your understanding. As a matter of fact, you are practicing RL on your own person, by refining and enhancing your understanding of the topic through the feedback you are getting.
Another reason to blog/vlog is that different people have different ways to understand the same subject. So you might have explained it in a way that appeals to some of the readers.
Coding and sharing
At the end of this learning journey, it is better to implement the algorithm and show it to someone. There is no benefit of doing it solely for yourself because (most probably) you won’t go the extra length and effort to make it work or perfect it.
Don’t just download code from GitHub and run it, there is no justification for this. RL algorithms are not huge in terms of line of codes, so take time to write it, test, and debug it, so that you discover all the issues related to it.
Writing the code yourself will make you think of every implementation detail that might very well make your algorithm fail, in case you don’t deal with them appropriately. One of many examples is to forget to normalize the input data of the neural networks.
Don’t expect that this phase will go smoothly even if you think you mastered the algorithm, there might be lots of things that go wrong and that you need to track and fix them one by one. It might take you days to make a small algorithm like DQN work. So stay motivated and don’t despair.
Sharing the code or the implementation will unconsciously push you to take extra care and do your best to make it work. Even if no one sends you negative feedback, but if your code is well done, people will start using it and sharing it among themselves, and eventually, you will have some who will praise you for your work because it solved their problem, which is rewarding by itself. Not to mention that there might be recruiters over there looking for people just like you, who can deliver.
Conclusion
Deep Reinforcement Learning is a tough subject, approaching it is challenging and requires lots of patience, devotion, and motivation to learn. One of the methods to effectively achieve knowledge is by simplifying and isolating complex parts, then keeping the motivation up by implementing and publishing your work.
Tips on How to Learn Deep Reinforcement Learning Effectively was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3qixAok
via RiYo Analytics






No comments