https://ift.tt/3eHhmi8 Using a targeted TF-IDF Topic Modeling method is useful for creating customizable topics that overcome the limitatio...
Using a targeted TF-IDF Topic Modeling method is useful for creating customizable topics that overcome the limitations of unsupervised Topic modeling.

TL;DR:
- Retrieved OpenAPI data from Yelp Open Dataset
- Perform Targeted TF-IDF (Term Frequency — Inverse Document Frequency) Topic Modeling of Reviews
- Apply Sentiment Analysis to Reviews
- Build Linear Regression models to analyze relationship between Topic sentiments and Restaurant Reviews
I. Background
Yelp Review data is a popular dataset for learning sentiment analysis and basic natural language processing (NLP) techniques. There are a lot of great projects that have been done utilizing this data. For my project, I’m going to show a modified method of TF-IDF topic modeling that works to create targeted topic modeling of Yelp reviews for restaurant businesses. This is a simple method of doing topic modeling that overcomes the problem of having little to no control over your topic-word distributions. I’ll also show some regression analysis that is possible with the features created from targeted topic modeling.
II. Dataset
Yelp Fusion API is the official free API for accessing Yelp related data without manual scraping. The learning curve for using this API is fairly low, and the documentation is well supported and up to date. It is useful for targeting certain businesses that you are interested in. However, there are limitations to using the API. Namely, there is a maximum pull of three reviews per restaurant, which limits our ability to use Yelp Fusion API.
Yelp Open Dataset is a useful dataset that is publicly available for access to the public. If we don’t care as much about the specific business, the Yelp Open Dataset is a good alternative to the Yelp Fusion API, and it has enough businesses and reviews to carry out the study. We will be using the Yelp business dataset and the Yelp review dataset in the ensuing sections.
The business and review datasets can be loaded with simple functions. The review dataset is very large, so it needs to be loaded chunk-wise.
III. Topic Modeling
Yelp data lends itself quite naturally to Topic Modeling to break down the reviews into specific categories. However, the issue with basic Topic Modeling methods is that it is largely an unguided, unsupervised technique. This type of topic modeling is useful for understanding your documents better, but the topics themselves are often not well suited for further analysis or modeling. For example, when running an LDA Model, our top 10 topics correspond primarily to cuisine types (burgers, tacos, Thai food etc). For a Vietnamese restaurant, most of these topics have no relevance to their restaurant, so this type of topic modeling will not be useful for further analysis.
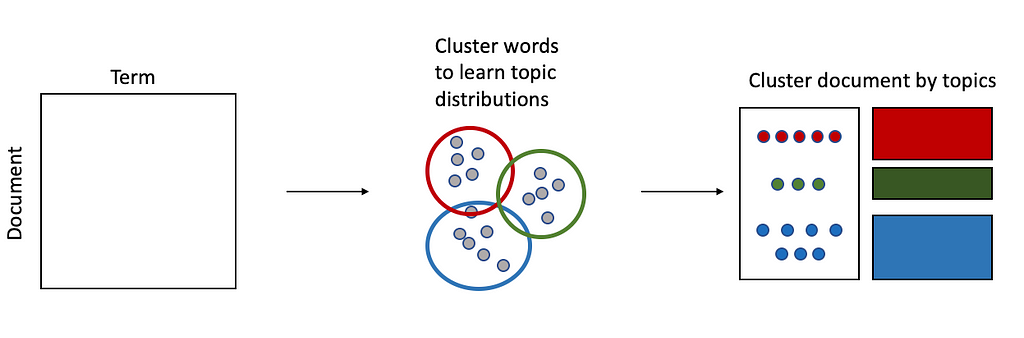
To overcome this, it is more effective to predefine the topic-word distribution beforehand, then predict the topic distribution of the reviews. By doing this, we have more control over the features that are relevant to the business.
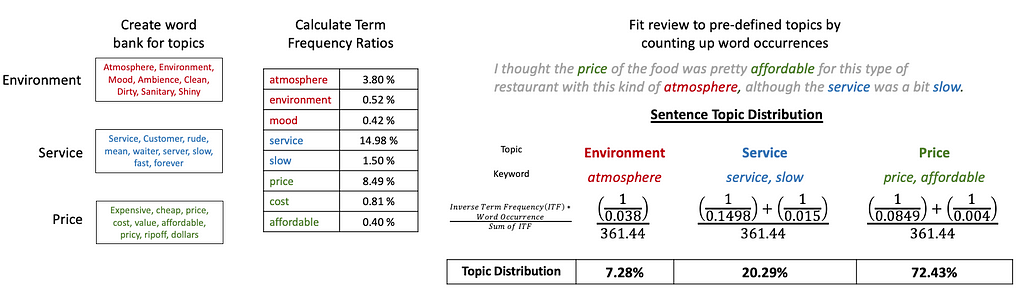
For targeted TF-IDF topic modeling, there are three main steps:
- Create pre-defined topics by creating word banks for each topic
- Calculate the term frequency for each word in the word bank
- Fit each sentence in each review by counting up word occurrences in each topic word bank
The beauty of this design is that the topics can be customizable, and domain knowledge can be leveraged to define each topic. For our study, we are going to define three topics: Environment, Service, Price. Using these three topics, the modeling function can be written as follows:
These topics are chosen because they are features that a restaurant can improve on. They can change the atmosphere of the place, improve the service, or look into ways of repricing their menu. After the topic distribution of each model is predicted, we also use the Flair package to perform Sentiment Analysis on each sentence.
IV. Regression
To further use the results from targeted topic modeling, let’s regress them individually on the Average Rating of the Restaurant (1–5 Stars).
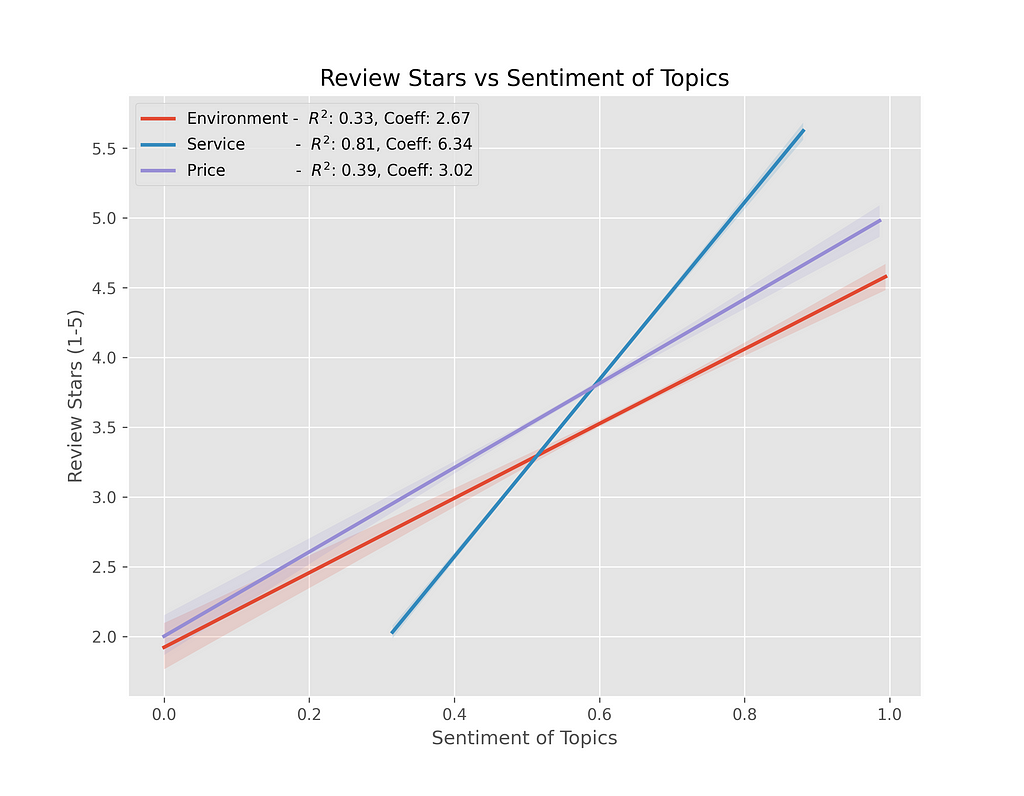
The sentiment of Service comments has the strongest effect on the average rating of the restaurant, followed by Price then Environment. Based on these results, it’s easy to see that Yelp users reviews are heavily influenced by their experience with the service of the restaurant. So improving this aspect of the restaurant operations is the strongest way to improve your Yelp Ratings, and help attract future customers.

This is also evident by analyzing the reviews of a low rated — 2.22 star restaurant and a high rated — 4.67 star restaurant. For these restaurants, the contrast in sentiment for sentences in the Service category were extremely stark and highly impacted their review of the restaurant.
V. Conclusion
This method of topic modeling is very versatile, and can be easily applied to different datasets with text data. It’s a helpful tool to have when you have known topics that you’d like to fit to the data. There still is a lot of further engineering that can be done to improve the performance of this model, and I’m looking forward to future developments!
All code and notebooks can be found on my github page here. Thank you for reading along, hope it was helpful! Any feedback greatly appreciated as well.
You can also find my other articles here:
Neural Network Collaborative Filtering with Amazon Book Reviews
Simple method of targeted TF-IDF topic modeling using Yelp Open DataSet was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3pJdeUU
via RiYo Analytics






No comments