https://ift.tt/34yCXas Behavioral testing for recSys with RecList Introduction Recommender systems (RSs) are all around us, helping us na...
Behavioral testing for recSys with RecList
Introduction
Recommender systems (RSs) are all around us, helping us navigate the paradox of choice of contemporary life: what is the next song I should be listening to? What is the next movie I should watch? Or, more subtly, what is the next piece of news I should consume?
RSs represent one of the most ubiquitous types of Machine Learning systems and all its power in personalizing the digital life of billions of people, and a constant reminder of our responsibilities as users, practitioners, legislators: by nudging you to read a story about Hollywood celebrities vs. climate change, we are making it more likely for you to spend your time on Brad Pitt’s life, with all that it entails.
As even one bad prediction may cause great reputation damage or erode our trust, building more robust RSs is an important topic, and we certainly won’t build a more robust system if we can’t better test the ones we have.
Unfortunately, RSs tend to “fail silently”, as in the example below, taken from a LinkedIn post joking about the (yet, not that close) Singularity:
What that means is that in a typical cycle, an ML system gets trained with some data, benchmarked on a held-out set through some accuracy metrics and, if the chosen KPI is acceptable, deployed in the wild. Since these systems are all stochastic in nature — and in many cases, very complex, non-linear objects — the straightforward analogy between ML and software development breaks down: having a high accuracy on the test set won’t, by itself, prevent unreasonable inferences like the one above.
In this blog post, we introduce RecList, a new open source library for scaling up behavioral testing in real-world recommendation systems. While a scholarly introduction is available as a research paper, we wish to provide here a more practical perspective, geared towards all stakeholders of modern RSs: ML engineering, product managers and, of course, final users.
Clone the repo, buckle up, and please support us with a star on Github!
What is behavioral testing, anyway?
The idea of “behavioral testing” for ML is not new: as NLP aficionados may have noticed, RecList is paying its homage to Checklist, Microsoft-led effort from 2020 to establish behavioral tests for NLP. In traditional tests, we have “point-wise” estimates (e.g. NDCG, Mean Reciprocal Rank) that quantify generalization capabilities over a held-out dataset. Behavioral tests are instead input-output pairs: the model is evaluated by comparing its output with the desired result. For example, in sentiment analysis, we wish that predictions stay consistent when swapping synonyms:

When building a “Similar things you may like” carousel, we want products that are similar across all the relevant dimensions, as suggesting a 10x more expensive item to a shopper browsing low-cost polos results in a suboptimal experience:

The fundamental insight of Checklist is not so much that “behavioral testing is cool” (duh!), but that:
- Behavioral tests can be run in a black box fashion, decoupling testing from the inner working of models: we can therefore compare models without source code as long as they expose a standard prediction interface;
- Behavioral tests are expensive to build as one-by-one pairs, but we can help scale them up with a combination of domain knowledge, ML tricks and extensible libraries.
If you will, RecList is a “Checklist for recommender systems”.
The principles behind RecList
We identify three key recommendation-specific principles to inspire our library:
Invariant properties: complementary and similar items satisfy different logical relations. While similar items are interchangeable, complementary ones may have a natural ordering: it is a great idea to suggest HDMI cables to shoppers buying an expensive TV, but it is a terrible idea to recommend TVs to people buying cables. We operationalize these insights by joining predictions with metadata: for example, we can use price and taxonomies to check for asymmetry constraints.

Not all mistakes are equally bad: if the ground truth item for a movie recommendation is “When Harry met Sally”, hit-or-miss metrics won’t be able to distinguish between a model suggesting “Terminator” and a model proposing “You’ve got mail”. In other words, while both are “wrong”, they are not wrong in the same way: one is a reasonable mistake, the other is a terrible suggestion, quite disruptive for the user experience.

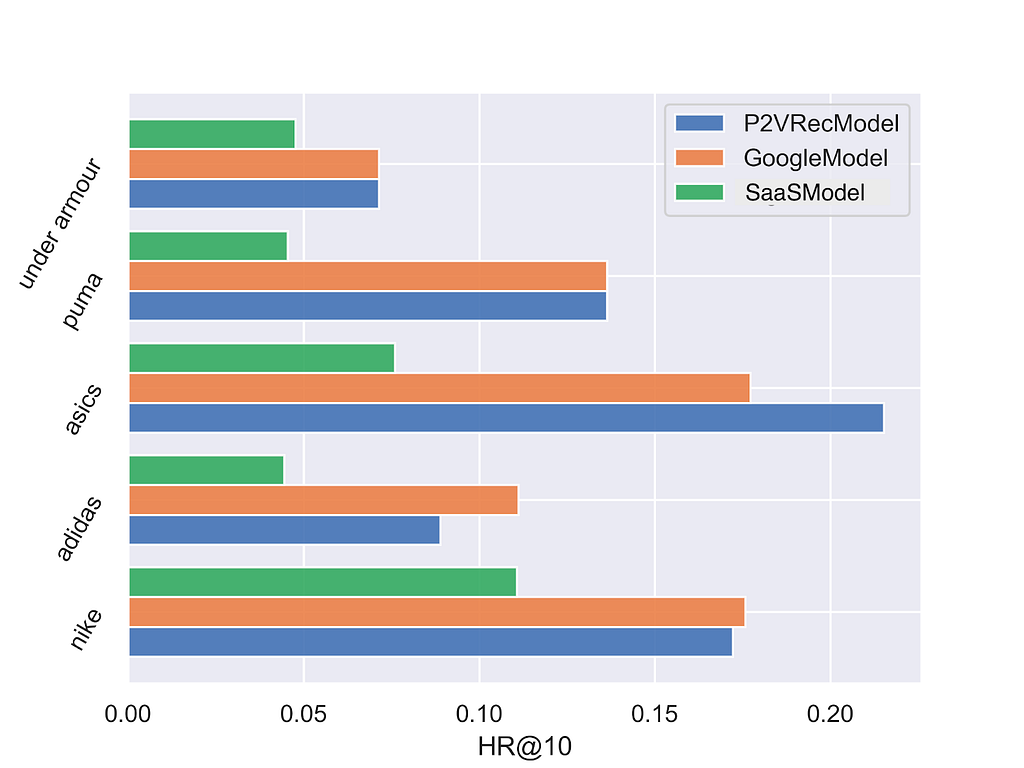
Not all inputs are the same: we may tolerate a small decrease in overall accuracy if a subset of users we care about is happier; for example if I’m promoting the latest Nike shoes with my marketing campaign, the shopping experience on Nike product pages should particularly well curated. Since item consumption is typically a power-law, a marginal improvement over high-frequency items may produce KPIs improvements, “hiding” severe degradation for a niche: if a movie recommender gets a bit better on Marvel blockbusters, but it becomes terrible for Italian users, we should be able to notice, and have relevant tests to make principled and explicit trade-offs. Aside from some horizontal use cases (e.g. cold-start items), the most interesting slices are often context-dependent, which is an important guiding principle for our library.
Enough words: a primer on RecList
A RecList — we use the Italic to denote the Python abstraction instead of the package as a whole — is simply a collection of tests. Any class inheriting the right abstraction can contain as many tests as desired, specified through decorators in a Pythonic style (reminiscent of flows in Metaflow). For example, the class below has only one test, a routine from our library running quantitative checks (coverage, popularity bias etc.):
Since behavioral tests typically vary with the use case (complementary recommendations are different from similar items) and the dataset, an instance of RecList would be something like the CoveoCartRecList, i.e. a set of tests for complementary recommendations over the Coveo dataset for e-commerce research.
Given the modular design, getting started on a new list is very fast: the library comes with many pre-made tests, which you can mix-and-match with arbitrary code for custom checks, making it easy to re-use business logic consistently.
The easiest way to get to understand how RecLists are used is going through one of the ready-made examples, or run the provided Colab notebook in your browser:
Let’s break it down:
- Lines 1–3 contain imports from the library
- Line 8 is fetching the Coveo Dataset. Hint: you can swap your dataset here for your private data.
- Lines 12–13 instantiate a baseline model from the library, and train it with the train split. Hint: you can train your own model (or bring a pre-trained model) and replace the baseline here. As long as your model is wrapped around the RecModel abstraction, everything downstream will work just as well.
- Lines 17–20 instantiate the RecList, in this case a ready-made list designed for this dataset and use case. As expected, the class takes as input the target dataset and the model to be tested. Hint: you can specify your own collection of tests here.
- Line 22 runs behavioral tests.
That’s it! Picking and combining abstractions like Lego blocks — either re-using components or creating new building blocks yourself — allow for an endless set of possibilities:
- pick a use case (similar products, complementary, etc.);
- pick a dataset;
- train a model;
- build / modify / pick a RecList:

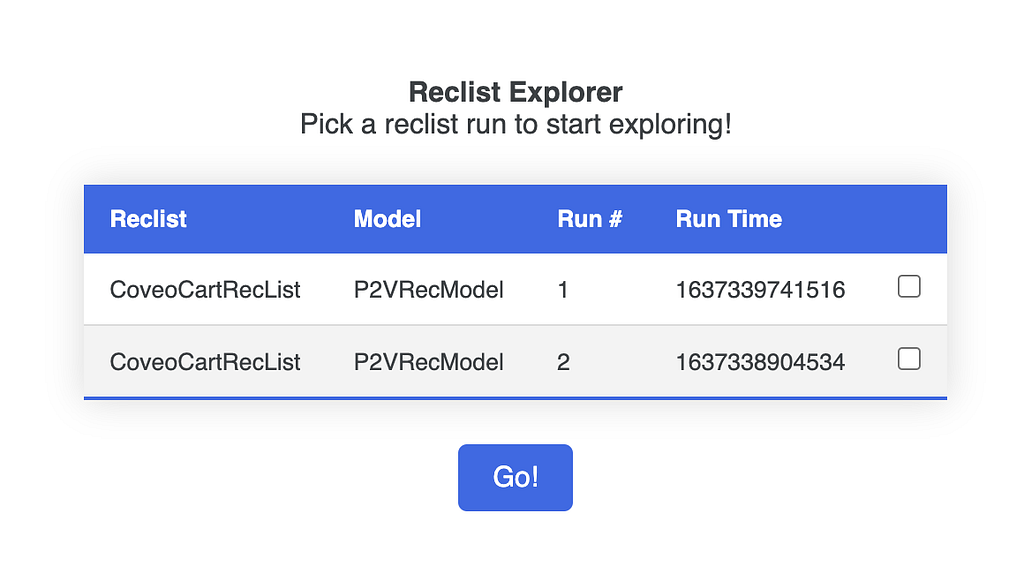
When you run any RecList, the library dumps the results into a versioned local folder; a small web app is also provided to visualize and compare the runs:
How should I use RecList?
While we developed RecList out of the very practical necessities involved in scaling RSs to hundreds of organizations across many industries, we also believe this methodology to be widely applicable in error analysis and thorough evaluation of new research models. In particular, we encourage you to think about two main use cases:
- As an experimentation tool for research: while developing a new model, you may want to compare it against quantitative and behavioral baselines to get better insights on error patterns and its relative strength and weaknesses. Reclist allows you to easily do that, and comes with ready-made connectors to popular research datasets;
- As a CI/CD check for production: after training a model, you typically run a quantitative benchmark on a test set to ensure some accuracy level before deployment. With RecList, you can supplement your pipeline with behavioral tests as well, and decide which flags to raise / what to do when results are not what is expected.
RecList is a free library, which we wish to extend and improve significantly this year: our alpha version already supports plug-and-play tests for common use cases, but we are actively looking for feedback, adoption and new contributors (see the section at the end for helping out!); which also means: the API is still pretty unstable as we iterate, but we will hopefully release a beta soon.
We believe that behavioral testing needs to continuously evolve as our understanding of recommender systems improves, and their limitations, capabilities and reach change.
By open sourcing RecList we hope to help the field go beyond “leaderboard chasing”, and to empower practitioners with better tools for analysis, debugging, and decision-making.
What can you do to help?
If you liked this post, please consider helping out! How? Some ideas, in ascending order of effort:
- 1 min: support us by adding a star to RecList on Github!
- 1 hour: read the paper, the README, run the tutorial: what feedback can you give us?
- 1 week: discuss it with your team: how would you use it in your company? What POC can you run with it?
- More: actively contribute to the project: get in touch!
BONUS: Developing within a community
While we are pretty well-versed in industry-academia collaborations, RecList is our first community-sourced scholarly work. The alpha version was brought to you with love by five people — Patrick, Federico, Chloe, Brian and myself — in five cities — Montreal, Milan, San Francisco, Seoul, NYC — across 4 time zones. Out of a total of 5(5–1)/2=10 possible in-person matches among the authors, only 1 actually ever happened (you win a free version of RecList if you guess which one!).
While it is too early to say how successful this model will be for our team going forward, our “Extended Mind” development has been so far fun above our expectations.
Acknowledgements
We wish to thank Andrea Polonioli, Ciro Greco and Jean-Francis Roy for constant support in this project (and many others as well). Furthermore thanks to Matthew Tamsett, Jonathan Davies, Kevin No for detailed feedback on a preliminary draft of this work.
Last but not least, thank to Chip, for creating the amazing Discord that kickstarted the RecList community.
NDCG Is Not All You Need was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
from Towards Data Science - Medium https://ift.tt/3GAtPAx
via RiYo Analytics






No comments